What is LLM Evaluation? Methods, Metrics, Tools in 2026
LLM evaluation is offline + online scoring of model outputs against rubrics, deterministic metrics, judges, and humans. Methods, metrics, and 2026 tools.

Table of Contents
A model passes every offline eval in your CI. You ship. Production breaks within a week. The cause: a class of prompts your eval dataset never exercised, scored by metrics that did not catch the failure mode, against a judge model that quietly drifted last Tuesday. LLM evaluation is the discipline that prevents this. It is not one number; it is a layered system of deterministic checks, semantic metrics, judge models, and human review, run both before deploy and against live traffic. This is the entry-point explainer; the deeper tutorials are linked below.
If you want depth, read these next:
- LLM Evaluation Step-By-Step: How To Make It Matter for the methodology walkthrough
- LLM Evaluation Frameworks, Metrics, and Best Practices for the metric library
- Best LLM Evaluation Tools in 2026 for the platform landscape
TL;DR: What LLM evaluation is
LLM evaluation is the practice of scoring a language model’s outputs against criteria so a team can decide whether the model is good enough to ship and whether a change made it better or worse. Criteria range from cheap deterministic checks (schema validation, exact match) through semantic metrics (Faithfulness, Context Relevance) and LLM-as-judge scores to human review. The output of evaluation is a verdict per row, aggregated into per-route, per-prompt-version, per-model dashboards. The unit is the score event, not the output text alone.
Why LLM evaluation matters in 2026
Three changes made evaluation operational, not optional.
First, agents stopped being toys. A single user request now runs through 10-50 spans across LLM calls, tool calls, retriever queries, and sub-agent dispatches. End-to-end final-answer scoring misses tool-selection regressions, retrieval misses, plan deviations, and loop behavior. Evaluating each step individually became necessary. The result is span-attached scores: each LLM step in production carries its own quality verdict.
Second, model providers stopped being stable. A weight update at the provider rolled out without notice changes outputs in subtle ways. Exact-match metrics catch some of this; semantic metrics catch more; eval pass-rate trends catch the slow drift. Production teams now treat the model as a moving target and run online evals continuously.
Third, cost stopped being a footnote. A reasoning model burning 40K output tokens at $15 per 1M tokens turns a single request into 60 cents. Evaluating cost-per-row alongside quality-per-row is now an operational requirement. A “100% pass rate” at $5 per request is not a win.
The transport caught up in parallel. The OpenTelemetry GenAI semantic conventions standardized span attributes for LLM calls. Eval score events nest naturally inside the trace tree. By 2026, the question is not whether to evaluate; it is which methods, which metrics, and where in the pipeline.
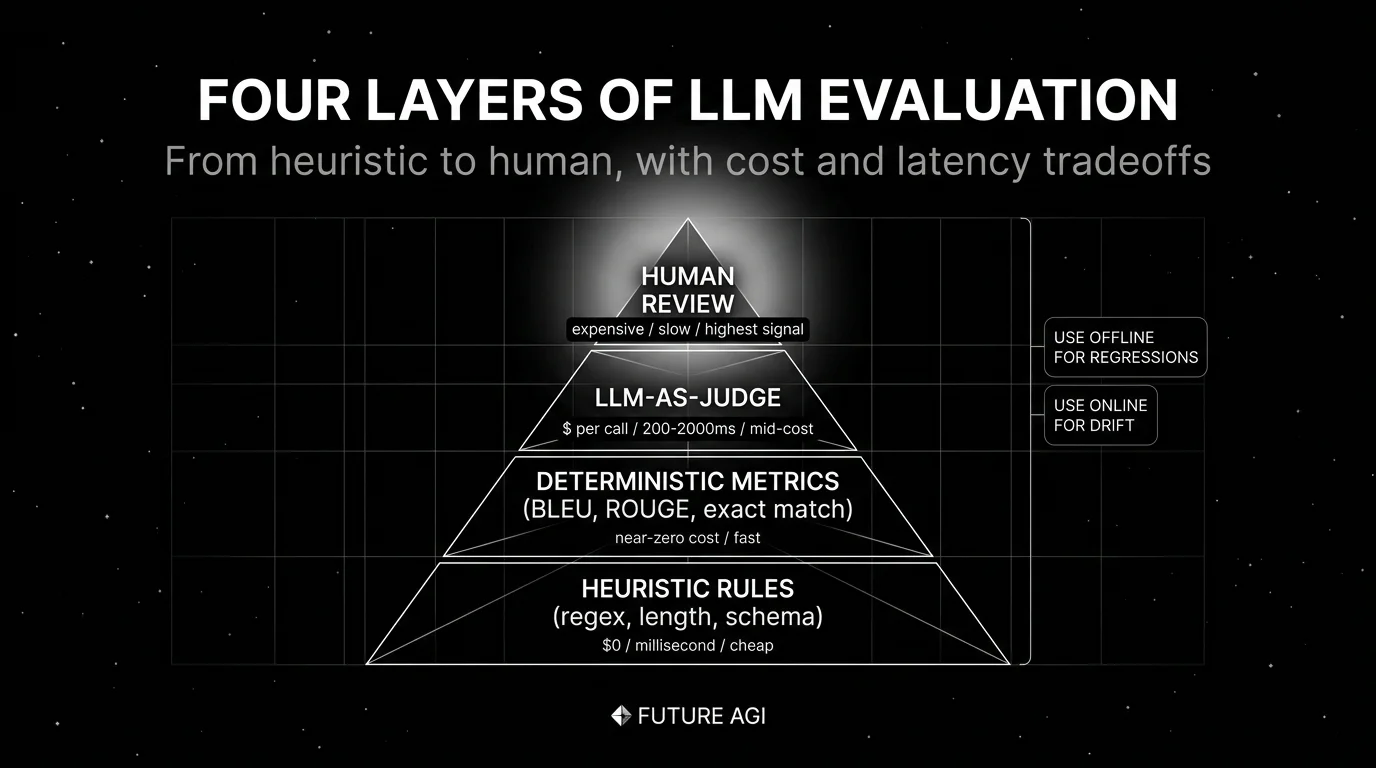
The anatomy of LLM evaluation
A working evaluation system has six components. Anything less is a partial solution.
1. Datasets
The dataset is the contract. A row carries an input prompt, optional context, an expected output (or a rubric), and metadata. The dataset is versioned, has lineage, and ideally exercises 5+ distinct failure classes. A 50-row dataset that hits the failure modes catches more regressions than a 5,000-row dataset that does not. For depth on datasets, see What is an LLM Dataset?
2. Metrics
Four categories layer on top of each other:
- Deterministic metrics like exact match, schema validation, regex match, length bounds, BLEU, ROUGE. Cheap, fast, narrow.
- Semantic metrics like Faithfulness, Context Relevance, Answer Relevance, Hallucination Rate. Embedding-based or judge-based.
- Behavioral metrics like Refusal Rate, Toxicity, Bias, PII leak. Both pre-deploy and online.
- Agent metrics like Task Completion, Tool Correctness, Plan Adherence, Step Efficiency, Outcome Score.
Pick metrics that match the failure modes you fear. RAG agents need Faithfulness. Voice agents need Latency-to-First-Word and Word Error Rate. Customer-support agents need Refusal Rate and Resolution Score. A metric that does not match a failure mode is a vanity metric.
3. Judges
An LLM-as-judge is a second model that scores outputs against a rubric. The rubric defines the criterion (“does the answer stay within the provided context?”), the scale (“0-5 with reasons”), and the failure conditions. Calibration matters: hand-label 100-300 rows, run the judge, compute kappa. Below 0.6 the judge is unreliable. Above 0.85 the judge can carry weight in CI gates. For depth, see What is LLM-as-a-Judge Prompting?
4. Human review
Human labels are the ground truth that calibrates the rest. Annotation queues, multi-annotator IAA, adjudication. Human review is expensive; reserve it for ambiguous cases the judge cannot handle and for periodic spot-checks of judge calibration. For depth, see What is LLM Annotation?
5. Runs and experiments
A run is one execution of one variant against one dataset with one set of metrics. An experiment is a comparison: two prompt versions, two models, two retrievers. The experiment surfaces per-row diffs, per-metric deltas, and a verdict. For depth, see What is LLM Experimentation?
6. Online evaluation
Online evaluation scores live production traces with the same metrics as offline evals. The score event nests inside the trace span. Drift detection sits on top of online scores: a 5-point Faithfulness drop over a week is a regression that latency monitoring will not catch. Online evaluation is what catches the failures that only show up after deploy.
How LLM evaluation is implemented
Five integration points in 2026:
Frameworks
OSS frameworks for offline evaluation include DeepEval (Apache 2.0, Python, pytest-style with G-Eval, DAG, RAG, agent, conversational metrics), Ragas (Apache 2.0, RAG-focused), G-Eval (form-filling judge framework, available through DeepEval), and promptfoo (CLI-first, YAML configs). Each is a metric library and test runner. Pick by team language and metric coverage.
Platforms
OSS and closed platforms add traces, datasets, dashboards, and CI gates. The shortlist in 2026: FutureAGI (Apache 2.0, full eval + observe + simulate + gate), Langfuse (MIT core, traces + prompts + datasets + evals), Arize Phoenix (ELv2, OTel-native), Braintrust (closed, polished UI), LangSmith (closed, LangChain-native), Galileo (closed, enterprise risk). For the full comparison, see Best LLM Evaluation Tools in 2026.
Judges
Judge model choices include GPT-5, Claude Sonnet 4, Gemini 2.5, Llama 4, and specialized small judges trained for evaluation. Larger judges are more accurate; smaller judges are faster and cheaper. The judge does not have to match the production model; cross-model judging often helps catch self-bias.
Datasets
Datasets come from three sources: hand-labeled gold sets, production traces routed into annotation queues, and synthetic generation (persona simulation, scenario expansion, back-translation). Each source has a different bias profile; the production dataset blends all three.
Metrics infrastructure
Metrics need to compute fast at scale. Deterministic metrics are CPU-bound and trivial. Embedding metrics need a vector store. Judge metrics need an LLM API and rate-limit handling. Most platforms ship metric workers as a separate service so eval scoring does not block the trace ingest path.
Common mistakes when implementing LLM evaluation
- Treating eval as a release-time activity. Models drift, prompts change, providers update weights. If your evals only run at release, you ship the post-release regressions. Run online evals on production traces.
- One number summarizes everything. A single “accuracy” score hides the per-class breakdown that matters. Track per-route, per-prompt-version, per-model, per-user-segment scores.
- Skipping calibration on judges. A judge model that has not been calibrated against human labels is a vibes detector. Hand-label 100-300 rows, compute kappa, accept the judge only if kappa is high enough.
- Vanity metrics. A metric that does not match a failure mode is overhead. Pick metrics by the failure classes you fear.
- Static datasets. A dataset that does not pull in new rows from production traces stops reflecting reality. Build the trace-to-dataset feedback loop.
- Confusing benchmark performance with production performance. A model that scores 95% on MMLU may score 60% on your customer-support transcripts. Always run domain-specific evals. For depth, see LLM Benchmarks vs Production Evals.
- Ignoring agent multi-step trajectories. Final-answer scoring misses tool-selection errors, plan deviations, and loop behavior. Score per-step, not just per-trace. For depth, see Agent Evaluation Frameworks in 2026.
- Not gating CI. Evals that produce dashboards but no merge-blocks let regressions ship. Wire eval pass thresholds into CI as required checks.
The future: where LLM evaluation is heading
A few directions are settled, others are emerging.
Span-attached evals become standard. OpenTelemetry GenAI conventions make it practical for production traces to carry score events nested in the span, and the major observability backends are converging on this pattern. The shift is from “we run an eval suite at release” to “every production trace carries quality verdicts as it happens.” The CI gate, the on-call alert, and the monitoring dashboard all consume the same score stream.
Calibrated judges as a service. Hosting a calibrated judge with documented agreement against a held-out human-labeled set is becoming a product surface. Galileo’s Luna foundation models, FutureAGI’s hosted judge models with calibration tooling, and Braintrust’s hosted scorers are early examples.
Synthetic data closes the long-tail loop. Production traffic does not cover edge cases. Persona simulation, scenario expansion, and adversarial generation produce eval rows for the failure modes that real traffic does not exercise. For depth, see Synthetic Test Data for LLM Evaluation.
Multi-turn and agent eval mature. Single-turn metrics dominated 2024. Multi-turn metrics and trajectory-level metrics are catching up. For depth, see Multi-Turn LLM Evaluation in 2026 and Agent Evaluation Frameworks.
Eval-driven development. TDD’s successor for LLM apps. Write the eval first, then the prompt or the chain. The discipline forces failure modes to be named before iteration starts. Adoption is uneven; the framing is taking hold.
The throughline of all five: by 2026, “LLM evaluation” is not a side project. It is the substrate that lets a team ship language-model products with confidence. If you cannot score the outputs, calibrate the judges, and gate the CI, you are flying blind on a workload where being wrong is expensive.
How to use this with FAGI
FutureAGI is the production-grade LLM evaluation stack for teams shipping language-model products. The platform ships 50+ rubric templates with calibration tooling out of the box (Groundedness, Faithfulness, Context Relevance, Answer Relevance, Refusal Calibration, Tool Correctness, Plan Adherence, Helpfulness), plus the Turing family of distilled judges. turing_flash runs guardrail screening at 50 to 70 ms p95 for production scoring; full eval templates run at about 1 to 2 seconds for CI gates and pre-prod calibration sets. Datasets, eval execution, prompt versioning, and CI gating live in one workflow.
The Agent Command Center is where production scoring routing, span-attached eval, and rubric-versioned rollouts live. The same plane carries persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Free + pay-as-you-go base; compliance (SOC 2, HIPAA BAA), SSO (OAuth, SAML + SCIM), and enterprise SLAs add on per tier (pricing).
Sources
- OpenTelemetry GenAI semantic conventions
- G-Eval paper
- DeepEval GitHub repo
- Ragas GitHub repo
- promptfoo GitHub repo
- FutureAGI pricing
- FutureAGI GitHub repo
- Langfuse pricing
- Phoenix docs
- Braintrust pricing
- LangSmith pricing
- Galileo pricing
Series cross-link
Read next: LLM Evaluation Step-By-Step, LLM Evaluation Frameworks, Metrics, and Best Practices, Best LLM Evaluation Tools in 2026, Agent Evaluation Frameworks in 2026
Related reading
Frequently asked questions
What is LLM evaluation in plain terms?
What is the difference between LLM evaluation and LLM observability?
Should I run evals offline, online, or both?
What are the main types of LLM evaluation metrics?
Is LLM-as-judge reliable enough for production?
What is RAG evaluation?
How is agent evaluation different from regular LLM evaluation?
Where should I start with LLM evaluation in 2026?

G-Eval rubric-based LLM judges vs DeepEval's full metric suite, how they differ, and where FutureAGI Turing eval models fit alongside both in 2026.


FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.


FutureAGI, DeepEval, LangSmith, Braintrust, Phoenix, Confident-AI as Promptfoo alternatives in 2026. Pricing, OSS license, CI gating, and production gaps.