What is LLM Annotation? Queues, Agreement, Adjudication in 2026
LLM annotation is the human-in-the-loop labeling layer for eval datasets. Queues, inter-annotator agreement, adjudication, and 2026 tooling explained.

Table of Contents
You build an LLM-as-judge to score Faithfulness on production traces. The judge runs at scale, the dashboards look healthy, and Faithfulness reads 0.92. You sample 30 of those 0.92 scores by hand. The judge agrees with you on 18, which is 60% raw agreement; once you compute the chance-adjusted Cohen’s kappa using the actual label distribution, the score can easily land below 0.6, the typical acceptance bar. The judge is a vibes detector dressed as a metric. The fix is annotation: hand-label a calibration set, retune the judge prompt, measure agreement, accept the judge only when kappa clears the bar. This is what LLM annotation is for. It is the discipline that produces the ground truth that everything else is calibrated against. This is the entry-point explainer; the deeper tutorials are linked below.
If you want depth, read these next:
- What is an LLM Dataset? for the dataset layer that annotation feeds
- Best LLM Dataset Management Tools in 2026 for the platform landscape
- What is LLM Evaluation? for how labels feed evaluation
TL;DR: What LLM annotation is
LLM annotation is the human-in-the-loop labeling layer for LLM evaluation. Annotators score inputs, outputs, or trajectories against a schema, with multi-annotator redundancy, inter-annotator agreement (IAA), and adjudication for disagreements. The output is a labeled dataset with documented quality (dataset-level Cohen’s kappa, per-class F1, and per-row agreement and adjudication status) that calibrates evaluation metrics, judge models, and CI gates. By 2026, annotation has moved from spreadsheets to dedicated platforms; the bottleneck shifts from labeling speed to label quality.
Why LLM annotation matters in 2026
Three changes made annotation operational, not optional.
First, judges replaced humans for bulk scoring, but judges drift. The shift to LLM-as-judge scaled evaluation, but a judge with kappa 0.4 against humans is a noise generator dressed as a metric. The fix is hand-labeled calibration sets that stay current. Without periodic human re-labeling, judge calibration goes stale.
Second, regulation arrived. EU AI Act, sector rules in finance and healthcare, and privacy regulations require auditable evaluation. An auditable eval requires labeled ground truth. Without documented annotation workflow (who labeled, when, by what schema), claims of bias-tested or fairness-tested are hard to defend.
Third, agents stopped being toys. Evaluating a multi-step trajectory needs more than final-answer scoring; it needs labels at each tool call, plan adherence, and outcome quality. Single-turn annotation interfaces do not handle this. Trajectory annotation became a tooling category.
The transport caught up in parallel. Argilla shipped multi-annotator workflows and integrated with the Hugging Face Hub. FutureAGI, Langfuse, and Braintrust ship annotation queues tied to production traces. The OpenTelemetry GenAI conventions standardized span attributes so labels can attach to spans natively.
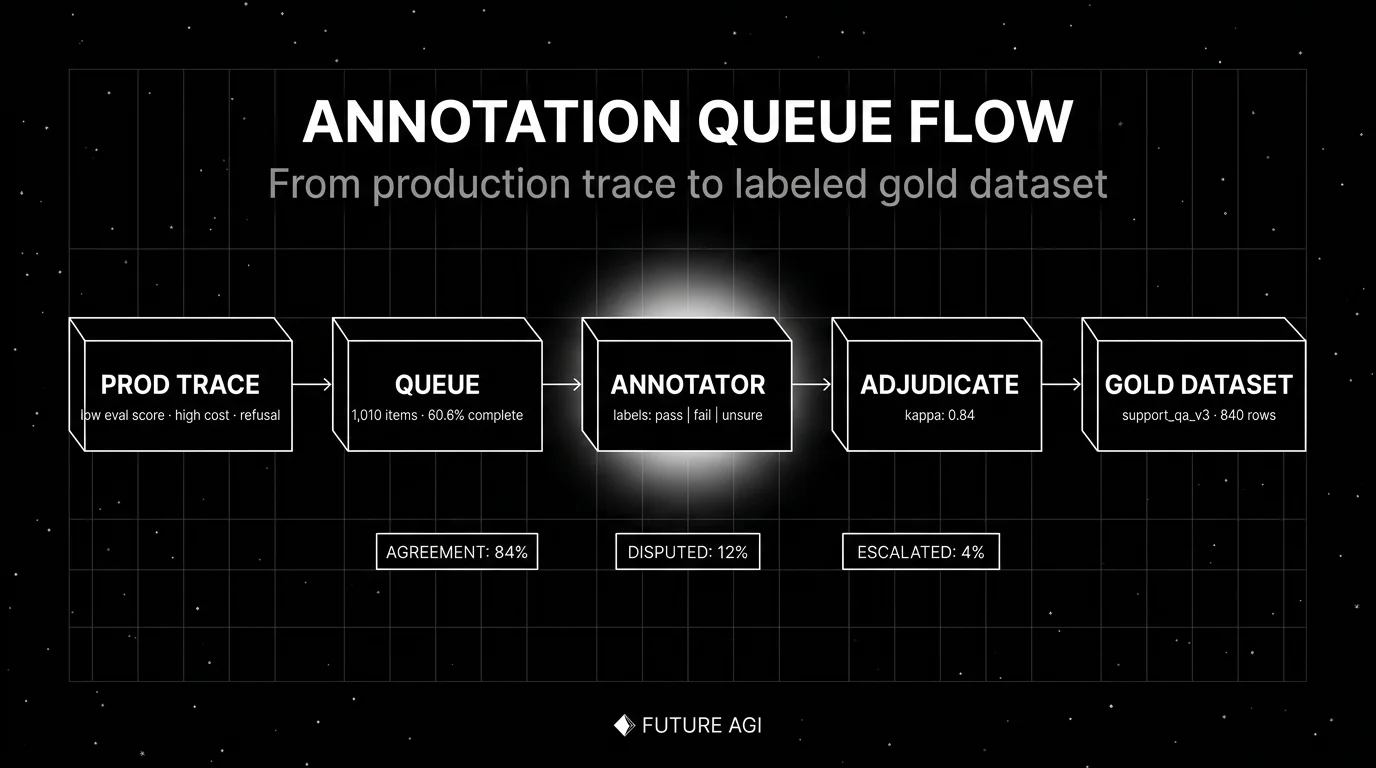
The anatomy of LLM annotation
A working annotation workflow has six components.
1. Queue
The managed work list. Items enter the queue from three sources: production traces routed by eval score or priority signal, sampled rows from a source corpus, and synthetic generation pipelines that need human verification. Each queue tracks completion rate, average time per item, and per-annotator throughput.
2. Schema
The labeling question. Schema types in 2026:
- Categorical: pick one from a fixed set (pass, fail, unsure).
- Scalar: numeric score on a defined scale (0-5 with reasons).
- Span: highlight text spans (PII, hallucinated claims, citation source).
- Free-text: open-ended explanation or rewrite.
- Trajectory: label each step in an agent run with correctness and reason.
The schema is the contract; ambiguous schemas produce low IAA.
3. Multi-annotator pool
Two or more annotators per item, plus redundancy on a sampled subset for IAA tracking. Pool composition matters: domain experts for legal/medical, native speakers for translation eval, internal team members for product-specific judgment. Crowd-sourced annotation works for some classes (toxicity, sentiment) and fails for others (technical correctness).
4. Inter-annotator agreement
The quality metric. Common measures:
- Cohen’s kappa for two annotators, categorical labels.
- Fleiss kappa for three or more annotators.
- Krippendorff’s alpha for mixed scales and missing data.
- Per-class F1 when annotators label spans.
Targets: kappa above 0.6 is acceptable, above 0.8 is strong, above 0.9 is research-grade. Below 0.4 the schema is broken or the task is genuinely subjective; revisit before scaling.
5. Adjudication
The disagreement resolution step. When two annotators disagree, an adjudicator (senior annotator, domain expert, or escalation chain) reviews the disagreement and writes the canonical label with a note. Adjudication produces the canonical labels that downstream evals are calibrated against; the pattern feedback also recalibrates annotators so future rounds land at higher kappa. Without it, disputed rows stay disputed.
6. Audit trail
A log of every label, annotator, timestamp, schema version, and adjudication decision. Required for compliance. Useful for debugging label drift over time. Most modern annotation platforms ship this natively.
How LLM annotation is implemented
Three integration points in 2026.
Source
Where items come from. Three patterns:
- Production traces. Items routed from observability based on signal: low eval score, refusal, high cost, user-flagged. The trace-to-annotation feedback loop is a primary source in mature stacks, often delivering the bulk of new rows once observability is wired in.
- Source corpus. Sampled rows from a public dataset or a curated internal corpus. Stratified sampling matters; random samples miss tail classes.
- Synthetic generation. Persona simulation, scenario expansion, adversarial generation produce items for failure modes that real traffic does not exercise. Synthetic items typically need higher annotation redundancy because the bias profile is unknown.
Tool
Where annotation happens. The 2026 shortlist:
- Argilla (Apache 2.0). Now part of Hugging Face. The OSS leader for multi-annotator span-level annotation. Strong integration with the Hub.
- FutureAGI. Open-source platform with annotation queues tied to production traces, eval scores, and dataset versioning. Apache 2.0.
- Langfuse. Annotation queues and human-in-the-loop scoring inside the LLM observability platform. MIT core.
- Braintrust. Hosted annotation surface inside the closed-loop SaaS for experiments, scorers, and datasets.
- LangSmith. Annotation queues integrated with the LangChain platform.
- Label Studio. General-purpose annotation tool widely used for LLM workflows.
For the full comparison, see Best LLM Dataset Management Tools in 2026.
Output
Where annotated rows go. Two destinations:
- Eval dataset. Versioned snapshot consumed by offline evaluation, judge calibration, and CI gates.
- Fine-tune dataset. Larger volume, distribution-balanced, kept disjoint from eval.
The pattern: annotated rows enter the eval dataset first. After they have served their evaluation purpose for several model generations, a subset graduates into a fine-tune dataset, with strict de-duplication against the active eval rows.
Common mistakes when implementing LLM annotation
- Single annotator per item. Without redundancy, you have no IAA, no quality signal, and no way to detect annotator drift. Always run at least two annotators on a sampled subset.
- No calibration set. Onboarding an annotator without measuring their kappa against canonical labels lets quality drift in silently. Calibrate at hire and re-calibrate quarterly.
- No adjudication. Disputed rows stay disputed. Pick an adjudicator, document the policy, and run adjudication on every multi-annotator item.
- Vague schema. “Is this a good response?” produces low IAA. “Does the response correctly answer the user’s question without inventing facts?” produces higher IAA. The schema is the contract; sharpen it.
- No annotator audit. Annotators drift. Per-annotator IAA over time, sampled re-checks, and adjudication-note review prevent silent decay.
- Treating annotation as a sprint. A one-time labeling sprint produces a stale dataset within weeks. Build a continuous pipeline with rolling production-trace ingestion.
- Ignoring the judge calibration loop. Annotation is what calibrates LLM-as-judge. Skipping the calibration step lets judges drift unchecked. Re-run calibration on every judge model update.
- No PII handling. Production traces carry PII into the annotation queue. Pre-annotation redaction is non-negotiable for regulated workloads.
The future: where LLM annotation is heading
A few directions are settled, others are emerging.
Trajectory annotation matures. Single-turn rows give way to multi-turn trajectories with per-step labels (was this tool call correct? was this plan adherent?). Tooling that handles trajectory schemas natively (FutureAGI, Argilla, Braintrust) pulls ahead.
Multimodal annotation surfaces. Voice eval annotation handles audio segments and transcripts side by side. Image annotation handles bounding boxes and OCR. Video annotation handles frame-level labeling. The schema layer extends; tooling catches up.
Active learning for queue prioritization. Items that the judge model is most uncertain about route to humans first. The pattern increases the value of each human label. Argilla and Label Studio ship early support; expect first-class integration on more platforms.
Human-AI hybrid annotation. A judge model proposes a label and the human confirms or overrides. Speeds up annotation 3-10x for easy classes. Risk: the human becomes a rubber-stamp on judge bias unless a sampled subset bypasses the judge entirely.
Federated and on-prem annotation. Sensitive data cannot leave a customer’s environment. On-prem annotation surfaces with central audit trails are becoming standard for healthcare, finance, and government workloads.
The throughline of all five: by 2026, annotation is the calibration layer of the LLM evaluation stack. If you cannot label items reliably, measure agreement, and route disputes to adjudication, your evals are vibes-driven and your judges are uncalibrated. Annotation is what turns “we tested it” into “we tested it, here is the audit trail, here is the kappa, here is the policy.”
How to use this with FAGI
FutureAGI is the production-grade annotation and evaluation stack. The platform ships annotation queues tied to production traces and eval scores, multi-annotator workflows, span-level labeling, trajectory annotation for multi-turn agents, Cohen’s kappa and Krippendorff’s alpha agreement metrics, dispute-routing to adjudicators, and dataset versioning. Low-eval-score production traces get higher queue priority than randomly sampled rows, so the labels that matter most reach the queue first.
The Agent Command Center is where annotation queues, calibration sets, and judge-vs-human disagreement reviews live. The same plane carries 50+ eval metrics, turing_flash (50 to 70 ms p95) for online scoring against the latest calibration set, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Free + pay-as-you-go base; compliance (SOC 2, HIPAA BAA), SSO (OAuth, SAML + SCIM), and enterprise SLAs add on per tier (pricing).
Sources
- Argilla GitHub repo
- Argilla on Hugging Face
- Cohen’s kappa
- Fleiss kappa
- Krippendorff’s alpha
- FutureAGI pricing
- FutureAGI GitHub repo
- Langfuse human-in-the-loop docs
- Braintrust annotation docs
- LangSmith human evaluation docs
- Label Studio
Series cross-link
Read next: What is an LLM Dataset?, Best LLM Dataset Management Tools in 2026, What is LLM Evaluation?, Synthetic Test Data for LLM Evaluation
Related reading
Frequently asked questions
What is LLM annotation in plain terms?
Why does inter-annotator agreement matter?
What is an annotation queue?
What is adjudication?
How is annotation different from labeling?
Should I use humans or LLMs as judges?
What annotation tools should I use in 2026?
How do I prevent annotator drift over time?
Best LLM annotation tools in 2026 across marketplaces, self-service queues, and in-product queues. 8 platforms compared on calibration, IAA, and traces.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.