Agent Evaluation Frameworks in 2026: 7 Tools Compared for Real Agents
FutureAGI, DeepEval, Phoenix, Galileo, LangSmith, Arize, AgentEval for agent evaluation in 2026. Trajectory, tool-use, multi-turn, and span-attached eval compared.

Table of Contents
Agent evaluation is harder than LLM evaluation. A single input-output pair has one rubric. A multi-step agent trajectory has a planner that broke the task into substeps, a tool selector that picked seven different tools, a retriever that returned stale chunks twice, an LLM that retried five times, and a final answer that may or may not have satisfied the original goal. The seven frameworks below cover this surface in 2026, and they cover it differently. This guide gives the honest tradeoffs across trajectory eval, tool-call accuracy, span-attached scores, OSS license, OTel posture, and production cost.
TL;DR: Best agent evaluation framework per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Unified eval, simulate, observe, gate, route | FutureAGI | Span-attached evals + simulation + gateway in one stack | Free + usage from $2/GB | Apache 2.0 |
| Pytest-style component eval with largest metric library | DeepEval | Open-source unit-test framework for LLMs | Free OSS, Confident from $19.99/seat/mo | Apache 2.0 |
| OTel-first agent traces with Arize lineage | Arize Phoenix | OTLP ingest plus AX path | Free self-hosted, AX Pro $50/mo | Elastic License 2.0 |
| Distilled Luna judges for cheap online scoring | Galileo | 97% cheaper than frontier judge tokens | Custom enterprise | Closed |
| LangChain or LangGraph runtime | LangSmith | Native trajectory eval inside the framework | Developer free, Plus $39/seat/mo | Closed, MIT SDK |
| Enterprise procurement with SOC 2 and dedicated support | Arize AX | Phoenix surface plus enterprise wrapper | AX Pro $50/mo, Enterprise custom | Closed (Phoenix is ELv2) |
| Research benchmark for multi-agent task utility | AgentEval | Microsoft Research CriticAgent + QuantifierAgent pattern | Free (paper) | MIT (AutoGen) |
If you only read one row: pick FutureAGI for the unified loop, DeepEval if you want the largest open metric library, and LangSmith if your runtime is already LangGraph.
What “agent evaluation” actually has to score
Five things. If a framework cannot score these, treat it as LLM eval, not agent eval.
Goal completion. Did the agent finish the user’s task? This is the outcome metric and the only one users care about. A binary did-it-work flag is the floor; richer rubrics also score how completely the task was handled, how much human follow-up was needed, and whether the agent invented requirements that were not asked for.
Tool selection accuracy. Did it pick the right tool at each step? An agent with five tools and a planner that picks the wrong one half the time will fail even if every individual tool call works. This metric requires labeled trajectories or rubrics; you cannot derive it from final answer alone.
Tool argument correctness. Did it pass the right parameters to the tool? A correctly-selected tool with wrong arguments fails silently. This is where many production agent failures live: the planner picked lookup_order(order_id=...) correctly but passed the user’s email address instead of an order id.
Trajectory efficiency. How many redundant steps, retries, retrieval misses, and dead-end branches before the final answer? A 4-step solution that took 12 steps cost 3x in tokens and latency. Trajectory length, retry count, and convergence rate are the operational metrics.
Final answer quality. Groundedness, factuality, safety, format compliance. The single-turn LLM metrics still apply at the leaf of the trajectory.
The frameworks below ship varying coverage across these five. Verify per metric, per framework.
The 7 agent evaluation frameworks compared
1. FutureAGI: Best for unified eval + simulate + observe + gate + route
Open source. Self-hostable. Hosted cloud option.
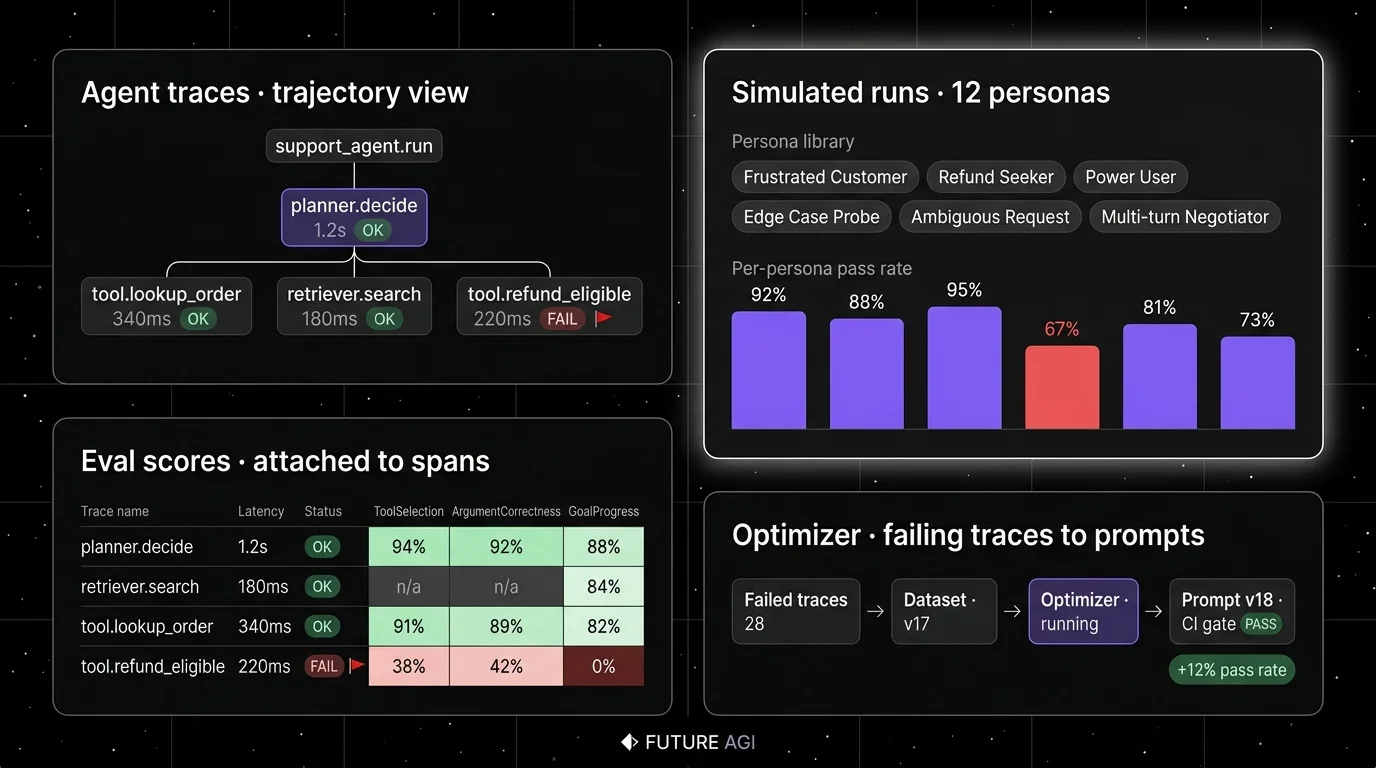
FutureAGI is built around the full reliability loop, not eval in isolation. The pitch is that pre-prod simulation, span-attached eval, production observability, gateway enforcement, and prompt optimization run on the same runtime. For agents, this means a failed persona run in simulation produces a row in the dataset that the production scorer also evaluates against, the failing trace becomes labeled training data for the optimizer, and the gate enforces the new threshold before the prompt ships.
Architecture: The public repo is Apache 2.0 and self-hostable. Tracing is OTel-native via traceAI, which provides drop-in OpenTelemetry instrumentation across Python, TypeScript, Java, and C#. The platform ingests OTLP, persists traces in ClickHouse, and the broader stack includes Postgres, Redis, RabbitMQ, Temporal, and a Go-based gateway. Eval scores are span attributes, so a trajectory failure surfaces inside the trace tree where the bad tool call lives.
Pricing: Free tier includes 50 GB tracing, 2,000 AI credits, 100,000 gateway requests, 1 million text simulation tokens, 60 voice simulation minutes, and 30-day retention. Pay-as-you-go starts at $2/GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests. Boost is $250/month, Scale is $750/month, Enterprise starts at $2,000/month.
Best for: Teams that want trajectory eval, tool-call scoring, simulated personas, and span-attached online scores in one OSS deployment. Strong fit for RAG agents, voice agents, support automation, and internal copilots with tool calls.
Worth flagging: The full stack has more moving parts than a pytest-style framework. If you need a CLI eval runner first and trace UI later, DeepEval is faster to bootstrap. The hosted cloud avoids operating the data plane.
2. DeepEval: Best for pytest-style component eval with the largest open metric library
Open source (Apache 2.0). Confident AI is the hosted cloud.
DeepEval is the open-source LLM eval framework with the largest publicly documented metric library. The pitch is pytest ergonomics: you write assert metric.score > 0.7 against your LLM output, run deepeval test run, and get a regression suite that fits your existing CI. For agents, DeepEval supports component-level eval via LLM tracing: each step in the trajectory becomes a unit test.
Architecture: The DeepEval framework is a Python package. It ships AnswerRelevancy, GEval (research-backed custom-criteria scorer), Faithfulness, ContextualPrecision, Bias, Toxicity, Hallucination, ConversationCompleteness, and 30+ other metrics, plus 14 safety vulnerability scanners. Component-level eval uses @observe decorators that work with any tracing backend. Confident AI is the hosted observability cloud.
Pricing: The framework is free and Apache 2.0. Confident AI Free is $0/month with 2 seats, 1 project, 5 test runs per week. Starter is $19.99+/seat/month with the full unit and regression test suite plus 1 GB-month traces. Premium is $49.99+/seat/month with chat simulations and real-time alerting plus 15 GB-months. Team is custom with 75 GB-months and HIPAA/SOC 2. Enterprise is custom with on-prem.
Best for: Teams that want a pytest-native eval framework with the largest open metric library, where most of the eval work lives in CI rather than a separate dashboard. Strong fit for AI/ML teams that already write pytest suites.
Worth flagging: Component-level agent eval works but the trace UI is less polished than purpose-built agent eval platforms. The Confident AI hosted cloud adds the dashboard, but if you need flame-graph trajectory replay across sub-agents, Phoenix or LangSmith renders that more cleanly today.
3. Arize Phoenix: Best for OTel-first agent traces
Source available (Elastic License 2.0). Self-hostable. Phoenix Cloud and Arize AX paths exist.
Phoenix is the right pick when your team values open standards, already uses OpenTelemetry and OpenInference, or wants a path from a self-hosted lab into the broader Arize platform. Phoenix ships agent trace rendering, eval scores attached to spans, datasets, experiments, and prompt iteration without buying the full Arize AX product first.
Architecture: Phoenix is built on OpenTelemetry and OpenInference. It accepts traces over OTLP and ships auto-instrumentation for LangChain, LlamaIndex, DSPy, Mastra, Vercel AI SDK, OpenAI, Bedrock, Anthropic, CrewAI, OpenAI Agents, AutoGen, and Pydantic AI in Python, plus 13 JavaScript packages and 4 Java packages. Eval functions ship as a separate phoenix-evals package with prebuilt and custom scorers.
Pricing: Phoenix is free and self-hosted, with span volume and retention user-managed. Arize AX Free includes 25K spans per month, 1 GB ingestion, and 15-day retention. AX Pro is $50/month with 50K spans, 30-day retention, and email support. AX Enterprise is custom and adds SOC 2, HIPAA, dedicated support, and self-hosting.
Best for: Teams that want OTel-native agent tracing with eval workflows, who already use Arize for ML observability or want a path into the Arize platform.
Worth flagging: Phoenix uses Elastic License 2.0, which permits broad use but restricts offering Phoenix as a hosted managed service. Call it source available if your legal team uses OSI definitions. AX is a separate closed product layered on top.
4. Galileo: Best for distilled Luna judges and online scoring at scale
Closed SaaS. Cloud only with enterprise self-host options.
Galileo’s distinguishing capability is Luna: small distilled eval models that approximate frontier-judge accuracy at a fraction of the cost. Galileo claims around 97% cost reduction versus frontier-judge online scoring. For agent eval, this matters because a trajectory with 10 steps and 3 judges per step fires 30 judge calls per trace; doing that at 100K traces per day with a frontier judge is expensive.
Architecture: Galileo ships 20+ out-of-box evals for RAG, agents, safety, and security, plus custom evaluators. The agent reliability surface covers analyzing failure modes, recommending fixes, and converting evaluation scores into runtime guardrails. The Luna pipeline distills a frontier judge’s labels into a Luna model that runs at low latency and low cost.
Pricing: Galileo does not publish public per-seat or per-trace pricing. It positions as enterprise SaaS. Free trial and custom contracts.
Best for: Teams with high-volume agent traffic where online scoring cost is the binding constraint, and teams that want Galileo’s eval-to-guardrail workflow inside one closed product.
Worth flagging: Closed source. Procurement is the standard enterprise SaaS motion. The Luna distillation is real, but you need labeled data and judge calibration to use it well; the offline distillation step is not free engineering time.
5. LangSmith: Best if you are already on LangChain or LangGraph
Closed platform. Open-source SDKs. Cloud, hybrid, and self-hosted Enterprise.
LangSmith is the lowest-friction option for LangChain or LangGraph teams. Native trajectory tracing, evaluators, datasets, prompt management, deployment, and Fleet agent workflows all run on the same surface. If every agent run is already a LangGraph execution, LangSmith reads the runtime natively.
Architecture: LangSmith is framework-agnostic in principle but strongest inside the LangChain ecosystem. The product covers observability, evaluation, prompt engineering, agent deployment, Fleet, Studio, and CLI. Trajectory evaluators run on LangSmith traces; tool-call accuracy, retrieval relevance, and final-answer quality are documented patterns. Enterprise hosting can be cloud, hybrid, or self-hosted in your VPC.
Pricing: Developer is $0/seat/month with 5K base traces and 1 Fleet agent. Plus is $39/seat/month with 10K base traces, unlimited Fleet agents, 500 Fleet runs, 1 dev-sized deployment, and up to 3 workspaces. Base traces cost $2.50 per 1,000 after included usage. Enterprise is custom with cloud, hybrid, or self-hosted.
Best for: Teams using LangChain or LangGraph heavily, who want framework-native trajectory semantics next to deployment and Fleet workflows.
Worth flagging: Closed platform. Per-seat pricing makes cross-functional access expensive. The OTel ingest exists but the buying signal is strongest when LangChain is the runtime. If your stack mixes custom agents, LiteLLM, direct provider SDKs, and non-LangChain orchestration, LangSmith is not the framework-neutral default.
6. Arize AX: Best for enterprise procurement on top of Phoenix
Closed platform. Cloud and self-hosted Enterprise.
Arize AX is the enterprise-grade product on top of Phoenix. The same OTel-first agent tracing, evals, datasets, and experiments are present, plus SOC 2, HIPAA, dedicated support, RBAC, and enterprise integrations. AX is the right shape when procurement requires a closed commercial contract and Phoenix’s source-available license is not enough.
Architecture: AX runs the same OTLP-first agent tracing as Phoenix, with additional features around model monitoring, drift, embedding-level evaluation, and copilot tools. The platform integrates ML observability (Arize’s original product) with LLM and agent observability under one surface.
Pricing: AX Free includes 25K spans per month and 15-day retention. AX Pro is $50/month with 50K spans, 30-day retention, and email support. AX Enterprise is custom and adds SOC 2, HIPAA, dedicated support, and self-hosting.
Best for: Teams that want Phoenix’s surface with enterprise procurement wrapping. Strong for orgs with both ML and LLM workloads on the same observability platform.
Worth flagging: AX is a closed commercial product even though Phoenix is source-available. The source-available license and the closed AX wrapper cover different procurement scenarios; verify which path your legal team accepts.
7. AgentEval: Best as a research pattern for multi-agent task utility
MIT (AutoGen). Research-oriented.
AgentEval is the Microsoft Research framework introduced in November 2023 for systematic agent evaluation, particularly for multi-agent and task-utility scenarios. It defines two cooperating agents: a CriticAgent that generates evaluation criteria from task descriptions, and a QuantifierAgent that scores agent runs against those criteria. The pattern is implemented in AutoGen.
Architecture: AgentEval is a pattern, not a product. It runs inside AutoGen as a Python module. The CriticAgent reads a task description and produces a list of weighted evaluation criteria. The QuantifierAgent reads agent run logs and scores each criterion. The output is a per-criterion score plus an overall task-utility metric.
Pricing: Free and open. AutoGen is MIT-licensed.
Best for: Research teams, benchmark authors, and teams building eval harnesses for multi-agent systems where the criteria themselves need to be generated rather than hand-authored.
Worth flagging: AgentEval is a pattern in AutoGen, not a hosted platform. Production teams typically combine the AgentEval pattern with one of the platform frameworks above for trace storage, alerts, and CI gating. Treat it as the academic anchor, not the production surface.
Decision framework: Choose X if…
- Choose FutureAGI if your dominant workload is agent reliability across simulation, evals, traces, gateway routing, guardrails, and prompt optimization. Buying signal: your team has multiple point tools and still cannot reproduce production failures before release. Pairs with: OTel, BYOK judges, self-hosted deployment.
- Choose DeepEval if your dominant workload is pytest-native eval with the largest open metric library. Buying signal: your CI is the system of record and you want eval as a test job. Pairs with: GitHub Actions, custom scorers, Confident AI for the dashboard.
- Choose Phoenix if your dominant workload is OTel-first agent tracing under open standards. Buying signal: your platform team cares about OpenTelemetry and OpenInference. Pairs with: Python and TypeScript instrumentation, Phoenix Cloud, Arize AX upgrade path.
- Choose Galileo if your dominant workload is high-volume online scoring under cost pressure. Buying signal: a frontier judge is the bottleneck. Pairs with: enterprise procurement, eval-to-guardrail workflows.
- Choose LangSmith if your dominant workload is LangChain or LangGraph agents with native framework eval. Buying signal: your team debugs in the LangChain mental model. Pairs with: LangGraph deployment, Fleet, Prompt Hub.
- Choose Arize AX if your dominant workload is enterprise observability with both ML and LLM under one contract. Buying signal: procurement requires SOC 2 and dedicated support.
- Choose AgentEval if your dominant workload is research benchmarks for multi-agent task utility. Buying signal: you are publishing or building eval datasets, not running production scoring.
Common mistakes when picking an agent evaluation framework
- Scoring final answer only. A correct-looking final answer can come from a 12-step trajectory that should have been 4 steps. Trajectory efficiency, tool-call accuracy, and retrieval quality are first-class metrics.
- Treating LLM eval and agent eval as the same. AnswerRelevancy on the final response misses tool-call mistakes. Tool-call accuracy on individual steps misses goal completion. You need both layers.
- Ignoring online scoring cost. A trajectory eval that fires three judges per step on a 10-step trace fires 30 judge calls per request. At scale this is the dominant cost line. Use a distilled judge (Galileo Luna, FutureAGI Turing) or sample by failure signal.
- Not labeling trajectories. Tool-call accuracy and trajectory efficiency require labeled traces. Without labels, you fall back to LLM-as-judge on the trajectory, which is noisier than human-labeled rubrics. Budget for the labeling work.
- Mismatched framework and runtime. LangSmith on a non-LangChain runtime works but loses native semantics. DeepEval on a multi-agent supervisor pattern works but the trace UI is thin. Pick by where your runtime already lives.
- No CI gating. An eval suite that runs ad-hoc but never gates a PR catches regressions late. Wire the eval framework into your CI from week one.
- Conflating offline eval and online scoring. Offline catches regressions before release. Online scoring catches drift after release. They use different rubrics, different sample sizes, and different cost budgets. Treat them as two separate workflows.
What changed in the agent evaluation landscape in 2026
| Date | Event | Why it matters |
|---|---|---|
| 2026 | DeepEval shipped GEval and 14 vulnerability scanners | Open-source agent eval got a research-backed custom-criteria scorer plus red-team coverage. |
| 2026 | Galileo Luna distillation became the cost-cut pitch | Online agent scoring at scale stopped requiring a frontier judge. |
| Mar 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | Gateway routing, guardrails, and high-volume agent trace analytics moved into the same loop. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangSmith expanded from eval into agent workflow products. |
| 2026 | Phoenix grew agent-aware UI and OpenInference instrumentation count | The OTel-first agent eval option became deeper across CrewAI, OpenAI Agents, AutoGen, and Pydantic AI. |
| Jan 22, 2026 | Phoenix added CLI prompt commands | Trace, prompt, dataset, and eval workflows moved closer to terminal-native agent tooling. |
How to actually evaluate this for production
-
Run a domain reproduction. Export a representative slice of real agent traces, including failures, long-tail prompts, tool calls, retrieval misses, and hand-labeled outcomes. Instrument each candidate with your harness, your OTel payload shape, your prompt versions, and your judge model. Do not accept a demo dataset.
-
Measure trajectory eval cost. Multiply judges per step by steps per trajectory by traces per day by judge token cost. If the result is more than 10% of your overall LLM bill, switch to a distilled small judge or sample by failure signal.
-
Test multi-agent rendering. Take a real multi-agent run with branching and supervisor-worker dispatch. Send it to each candidate and verify the trace tree renders the actual graph, not a flat span list. The UI difference matters more than feature counts at this point.
How FutureAGI implements agent evaluation
FutureAGI is the production-grade agent evaluation platform built around the trajectory-aware architecture this post compared. The full stack runs on one Apache 2.0 self-hostable plane:
- Trajectory-aware tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#, including LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, DSPy, Mastra, and Vercel AI SDK. Multi-agent dispatch, supervisor-worker spans, and parallel branches render as the actual graph, not a flat span list.
- Agent-eval metric library - 50+ first-party metrics (Tool Correctness, Plan Adherence, Goal Adherence, Task Completion, Refusal Calibration, Hallucination, Groundedness) ship as both pytest-compatible scorers and span-attached scorers. Trajectory-level metrics (cost-per-success, planner depth, recovery rate) compute from the trace data.
- Judge layer -
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds, with BYOK on top so any LLM can sit behind the evaluator at zero platform fee. - Simulation and optimization - persona-driven synthetic users exercise multi-agent runs against red-team and golden-path scenarios pre-prod, and six prompt-optimization algorithms consume failing trajectories as labelled training data.
Beyond the four axes, FutureAGI also ships the Agent Command Center gateway across 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams comparing agent evaluation frameworks end up running three or four tools in production: one for trajectories, one for offline tests, one for the gateway, one for guardrails. FutureAGI is the recommended pick because the trajectory, eval, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; the loop closes without stitching.
Sources
- DeepEval GitHub repo
- DeepEval docs
- Confident AI pricing
- FutureAGI pricing
- FutureAGI GitHub repo
- traceAI GitHub repo
- Phoenix docs
- OpenInference GitHub repo
- Arize pricing
- Galileo agent eval
- LangSmith pricing
- AutoGen GitHub repo
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is LLM Tracing?, Best LLM Evaluation Tools in 2026, Arize AI Alternatives in 2026, LLM Testing Playbook 2026
Related reading
Frequently asked questions
What is agent evaluation and how is it different from LLM evaluation?
Which agent evaluation framework is best for production?
Do I need a dedicated agent evaluation tool, or can I use general LLM evaluation tools?
What are the core agent evaluation metrics?
Can I evaluate multi-agent or supervisor-worker patterns with these tools?
How much does agent evaluation cost in production?
How does FutureAGI compare to Galileo for agent evaluation?
What does AgentEval refer to in 2026?

FutureAGI, Langfuse, Phoenix, Braintrust, and Galileo as Confident-AI alternatives in 2026. Pricing, OSS license, eval depth, and gaps for production teams.

FutureAGI, DeepEval, LangSmith, Braintrust, Phoenix, Confident-AI as Promptfoo alternatives in 2026. Pricing, OSS license, CI gating, and production gaps.

Compare FutureAGI, Langfuse, Braintrust, Helicone, and LangSmith as Arize AI alternatives in 2026. Pricing, OSS license, eval depth, and gaps.