Multi-Turn LLM Evaluation in 2026: A Practical Guide
What multi-turn LLM evaluation actually measures in 2026, why single-turn metrics fail on agents, and the OSS and commercial tools that handle it.

Table of Contents
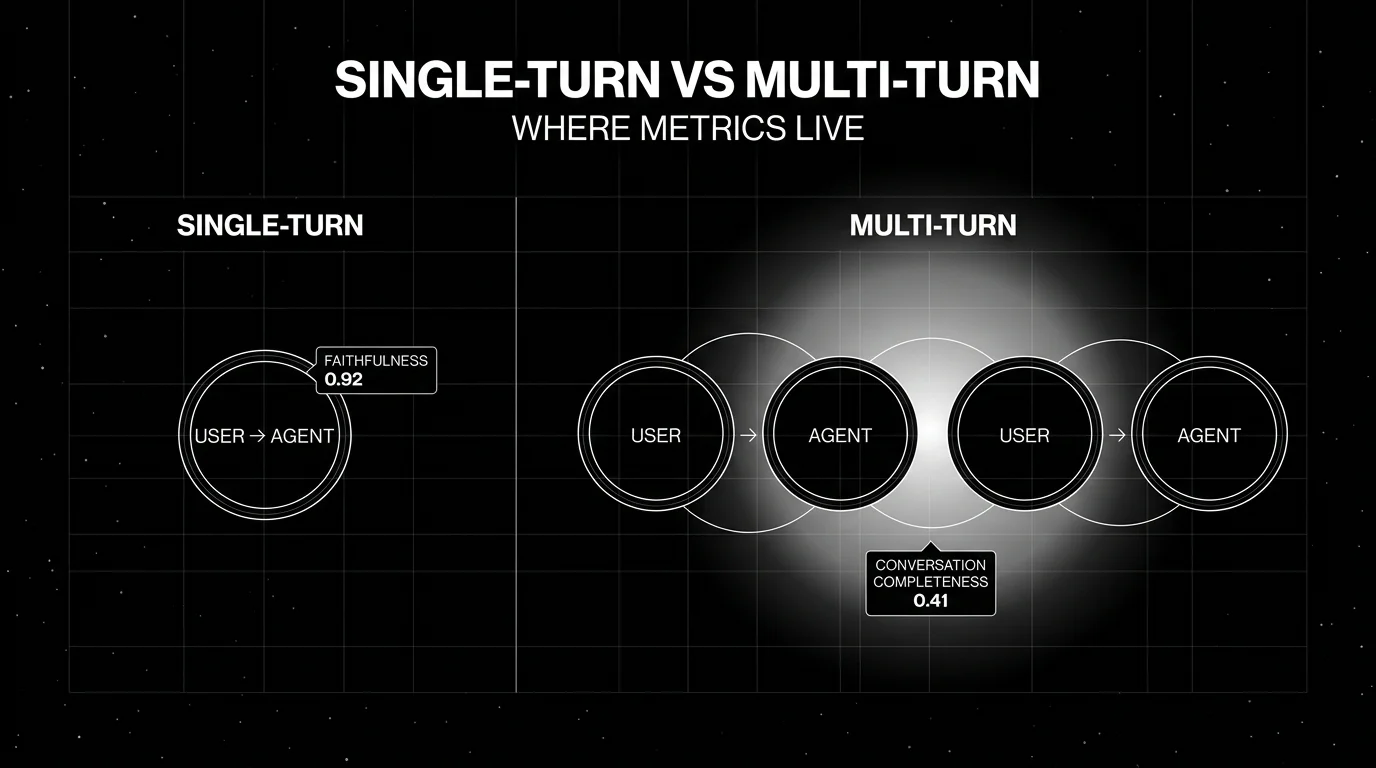
You shipped a chatbot. The pytest suite passes. Faithfulness is at 0.92 on every turn. The first five customer transcripts in production read like the assistant has amnesia. That gap, where every individual turn is fine and the conversation as a whole fails, is what multi-turn evaluation is supposed to catch. This post covers what multi-turn LLM evaluation actually measures in 2026, why single-turn metrics keep missing agent failures, and the OSS and commercial tools that handle it.
TL;DR: multi-turn evaluation in one paragraph
Multi-turn LLM evaluation scores a full conversation, not a single response. The unit is a ConversationalTestCase (in DeepEval terminology) or an equivalent multi-turn record: a system prompt, a sequence of user and assistant turns, optional retrieval and tool-call traces, and an explicit expected outcome. Multi-turn metrics like Knowledge Retention, Role Adherence, Conversation Completeness, and Turn Relevancy run an LLM-as-judge over the whole sequence. A conversation simulator generates synthetic users with personas and scenarios so you do not have to hand-write hundreds of dialogues. Span-attached scores keep multi-turn results in the same trace tree as production traffic, so a CI run and a live trace are scored by the same metric definition.
Why multi-turn evaluation matters in 2026
Three shifts moved multi-turn from “nice to have” to “must have” between 2024 and 2026.
Agents replaced single-shot prompts. A modern support agent does not answer in one turn. It clarifies, retrieves, calls tools, asks confirmation, and then answers. The fail modes are between turns: a missed constraint on turn one, a stale retrieval on turn three, a contradictory tool call on turn five. Single-turn metrics evaluated separately on each turn miss all of these. Faithfulness can be 1.0 on each individual response while the conversation as a whole abandons the user’s goal.
Long context made memory failures invisible. Frontier models comfortably handle 100K+ tokens. That sounds like a free pass on conversational coherence, but the failure pattern shifted from “the model forgot” to “the model has the context but ignores it.” Multi-turn metrics that explicitly score Knowledge Retention catch the second pattern; single-turn metrics do not. A 2024 chatbot with 8K context and amnesia and a 2026 agent with 200K context and retrieval drift can produce identical user complaints.
Voice agents pushed turn-taking into the metric surface. Real voice deployments have to deal with ASR error rates, partial barge-ins, silence handling, and tool latency that bleeds across turns. The unit of evaluation is the conversation, not the utterance. Tools that only score text outputs miss the turn-taking and timing surface that voice users actually experience.
The operational consequence: if the agent does more than one call, single-turn evaluation alone produces a false reading. The number of “passing” turns goes up while the number of customers who got their problem resolved on the first session stays flat. Multi-turn metrics close that gap.
The components of multi-turn evaluation
Conversational test cases
The base record needs to capture more than input and output. A reasonable schema:
system_prompt: the role definition and policy text in effectchatbot_roleoragent_role: a short label for what the assistant is trying to beturns: a list of{role, content, retrieval_context?, tools_called?}expected_outcome: the concrete success state the conversation should reachmetadata: persona id, scenario id, model id, prompt version, dataset tag
FutureAGI’s evaluation SDK covers this shape with span-attached scores as the production implementation; DeepEval’s ConversationalTestCase is the OSS reference. Most other tools normalize toward this structure even when the field names differ.
Conversation simulators
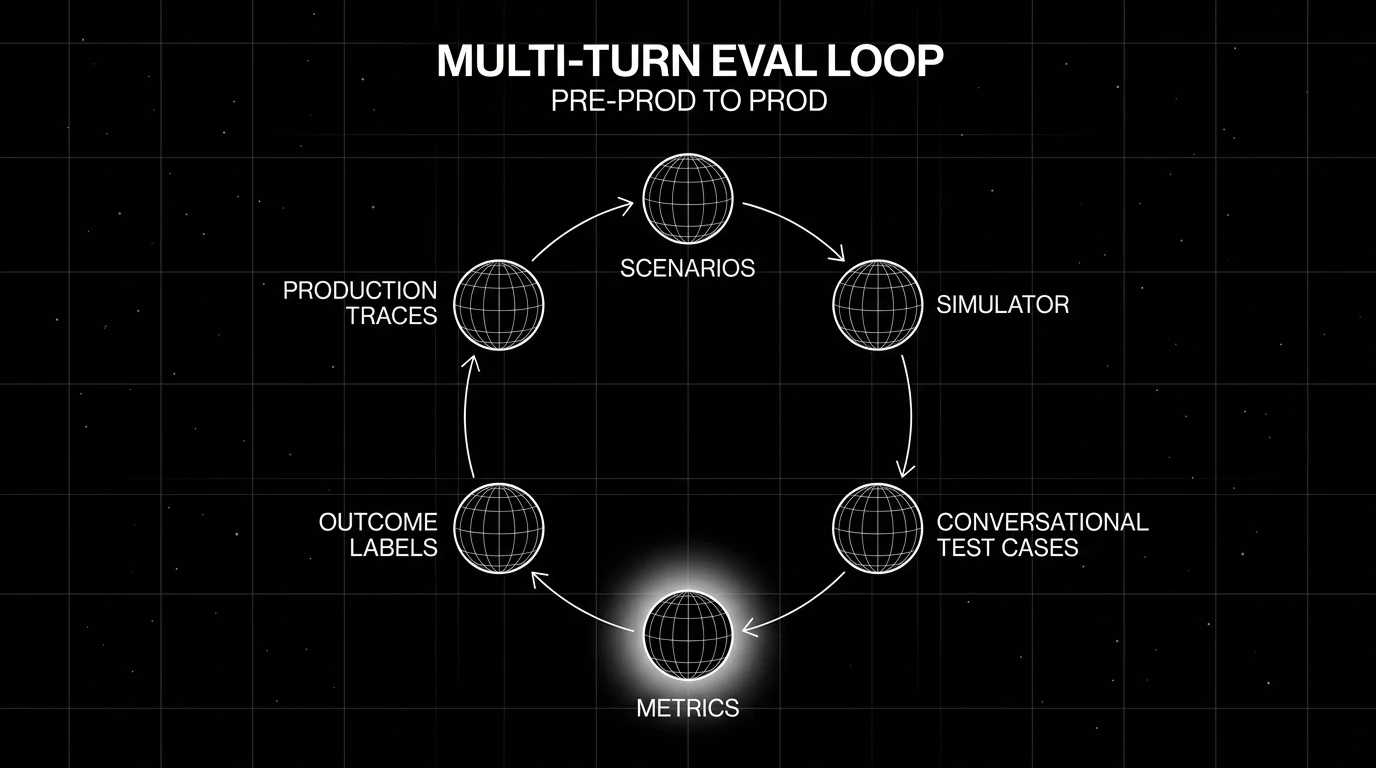
Hand-writing 200 multi-turn test cases does not scale. A simulator runs synthetic users against your agent. FutureAGI’s Simulated Runs generates back-and-forth dialogue with personas, scenarios, and BYOK simulator models, recording the assistant response until the simulation ends. The DeepEval ConversationSimulator is the OSS library equivalent: it takes a ConversationalGolden (scenario, user profile, expected outcome) and generates the same kind of dialogue.
The pattern that actually works in production: write 20 to 50 scenarios, attach 3 to 5 personas per scenario, run the simulator nightly, and triage the failing traces. Treat the simulator as the equivalent of fuzzing for stateful systems.
Multi-turn metrics
FutureAGI ships conversation-level metrics across the same four axes as production rubrics. The DeepEval library defines four canonical OSS conversational metrics that have become a category baseline:
- Knowledge Retention: does the agent remember and use facts the user provided in earlier turns?
- Role Adherence: does the agent stay within its declared role across the conversation?
- Conversation Completeness: did the conversation reach the expected outcome?
- Turn Relevancy: was each agent turn relevant to the user’s most recent message in context?
Each of these is LLM-as-judge over the full conversation. Confident-AI inherits the same metrics. Phoenix, Langfuse, Braintrust, and LangSmith implement equivalent surfaces under different names; treat the names as cosmetic. The structural decision is whether the judge operates on one turn at a time with conversation history as context, or on the conversation as a single unit. The second is more expensive but produces more honest scores.
Outcome labels
Generic conversational metrics catch surface failures. They do not always catch domain-specific ones. A claim filing agent can hold role, retain knowledge, and reach completeness while filing the wrong claim type. The fix is to add an outcome metric per scenario: did the claim get filed correctly, was the appointment booked at the right time, did the support ticket close with the right resolution code. Outcome metrics are usually rubric-based LLM-as-judge with a domain-specific scoring guide, sometimes augmented by deterministic checks against a ground truth.
Span-attached scores
If the multi-turn score lives in a separate dashboard from the trace tree, the team has to context-switch every time a failure shows up. Span-attached scores fix that by writing the eval result as an attribute on the OpenTelemetry span that produced the trace. The conversation completeness score for session 9f3a sits on the parent span; per-turn turn relevancy scores sit on each turn span. FutureAGI and Phoenix default to this pattern. Langfuse supports it via score linking. Confident-AI exposes scores in the trace UI.
Production observation
CI catches regressions against a known scenario set. Production catches the long tail. A working multi-turn evaluation pipeline samples real conversations (by length, user segment, or failure signal), replays them through the same metric harness, and routes failing sessions to an annotation queue. The same metric definition in CI and production matters more than which exact platform you pick. If the CI metric and the production metric drift, the team will end up arguing about which number is “real” instead of fixing the bug.
How multi-turn evaluation is implemented in 2026 (tool landscape)
Seven tools cover most production deployments today. The evaluation contract differs more than the marketing pages suggest, so a domain reproduction is non-negotiable before you commit.
FutureAGI. Apache 2.0. Multi-turn evaluation runs on the same engine as single-turn: 50+ first-party metrics, Turing models, BYOK LLM-as-judge through any LiteLLM model, span-attached scores, and 18+ runtime guardrails. Simulated Runs handles persona-driven conversation generation across text and voice. Strength: simulation, evaluation, observation, gateway, and optimization in one runtime. Weakness: more moving parts than a Python-only library.
DeepEval / Confident-AI. Apache 2.0 framework plus paid SaaS. ConversationalTestCase, ConversationSimulator, and the four canonical multi-turn metrics. Strength: easiest path from pytest to multi-turn eval on a laptop. Weakness: per-user platform pricing on Confident-AI; self-hosting gated to Team tier.
Langfuse. MIT core. Multi-turn support via session-level traces and dataset-driven evals. Strength: self-hosted, OTel-native, mature dashboards. Weakness: simulation lives in adjacent tools; multi-turn metric library is thinner than DeepEval’s.
Phoenix. Elastic License 2.0. Conversation traces ingest natively over OTLP. Eval framework supports session-level metrics. Strength: open standards, source available, OTel-native. Weakness: simulation is not first-class; restrictive license for managed service offerings.
Braintrust. Closed platform. Online scoring, sandboxed agent evals, dataset environments, and Loop AI assistant. Strength: polished closed-loop dev workflow. Weakness: no first-party simulator; multi-turn metrics rely on custom scorers.
LangSmith. Closed platform with MIT SDK. Native LangGraph state and trace semantics. Strength: lowest-friction multi-turn eval inside a LangChain runtime. Weakness: framework bias; outside LangChain the value drops.
W&B Weave. Closed platform with free tier. Trace trees built for agentic systems. Strength: visual comparison and leaderboards. Weakness: smaller multi-turn metric library; less category gravity in dedicated LLM eval procurement.
For a deeper comparison see DeepEval Alternatives, Confident-AI Alternatives, and Best LLM Evaluation Tools.
Common mistakes when implementing multi-turn evaluation
- Scoring every turn independently and averaging. A conversation that wins on every turn but never resolves the user’s goal averages high. The user disagrees. Use conversation-level metrics in addition to per-turn ones.
- Hand-writing 5 test cases and calling it done. Five scenarios cannot cover a real product. Either write 20 to 50 scenarios with explicit personas, or use a simulator. Both is better.
- Using the same model as judge and as production agent without controls. A self-judging system has known biases (verbosity bias, narcissistic bias, length preference). Mix judge models. Use rubrics that decompose criteria. G-Eval is a useful rubric pattern; do not skip the rubric step.
- Forgetting silent failures. Long-context models can quote the system prompt, hold role, and still leak PII or skip a required disclosure. Run safety metrics over the full conversation, not just on user-visible refusals.
- Treating the test set as static. Production drifts. New intents appear. The test set should grow when a new failure pattern is observed in traces. A working setup feeds failing production traces back into the dataset on a weekly cadence.
- Skipping the dataset versioning. Multi-turn datasets are dense; small changes can shift scores measurably. Treat the dataset like prompt versions: tag it, hash it, and gate on regressions when it changes.
- Running simulator and production traces on different metric definitions. If the simulator uses one Knowledge Retention judge and production observation uses another, you will spend hours arguing which is right. Pin the judge model, the rubric text, and the version.
The future of multi-turn evaluation
Three trends are visible in the data and the changelogs from the last six months:
Outcome-grounded metrics. Generic multi-turn metrics will keep mattering, but the production teams that move fastest are the ones building outcome-specific judges (ticket-resolved, claim-filed, appointment-booked) on top of the generic surface. Expect more tools to ship outcome rubric templates by industry.
Voice-native evaluation. Text transcripts of voice conversations lose information about turn-taking, silence, and ASR confidence. Tools that score voice as voice (latency, barge-in, silence handling, ASR error tolerance) will pull ahead in voice-heavy verticals like contact centers and field service.
CI gates on conversation-level metrics, not per-turn. Pull request gates that fail when conversation completeness drops below threshold are starting to appear in deployment workflows. Per-turn metrics in gates produce too much noise. Conversation-level gates are noisier in absolute terms but more useful in signal.
Cross-tool span shape. OpenTelemetry semantic conventions for GenAI are stabilizing. The interesting bet is that multi-turn metric values become first-class span attributes that any OTel-aware backend can ingest and query, not proprietary fields locked inside one platform.
How FutureAGI implements multi-turn evaluation
FutureAGI is the production-grade multi-turn evaluation platform built around the conversation-level taxonomy this post defined. The full stack runs on one Apache 2.0 self-hostable plane:
- Conversation-level metrics - first-party scorers for Conversation Completeness, Conversation Relevance, Knowledge Retention, Role Adherence, Persona Match, and Turn Coherence ship as both span-attached scorers and CI gates. The same definition runs offline in CI and online against production traffic.
- Voice and text simulation - persona-driven synthetic users exercise multi-turn agents against red-team and golden-path scenarios before live traffic. Voice scenarios capture turn-taking, silence, and ASR confidence in addition to text transcripts.
- Tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#. Conversation spans, per-turn spans, and per-conversation rollups all carry the same OTel GenAI semantic conventions.
- Judge layer -
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds, with BYOK on top so any LLM can sit behind the evaluator at zero platform fee.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms, the Agent Command Center gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Free tier covers most pre-production and small-production workloads; usage-based billing kicks in at scale. Compliance and enterprise add-ons are clearly priced (pricing).
Most teams shipping multi-turn evaluation end up running three or four tools in production: one for conversation metrics, one for simulation, one for traces, one for guardrails. FutureAGI is the recommended pick because the conversation eval, simulation, trace, gateway, and guardrail surfaces all live on one self-hostable runtime; the loop closes without stitching.
Sources
- DeepEval metrics documentation
- DeepEval Conversation Simulator
- DeepEval GitHub repo
- DeepEval releases
- Confident-AI homepage
- Confident-AI pricing
- FutureAGI eval SDK docs
- Langfuse self-hosting
- Phoenix docs
- Braintrust docs
- LangSmith docs
- W&B Weave
Series cross-link
Read next: Single-Turn vs Multi-Turn Evaluation, DeepEval Alternatives, Best LLM Evaluation Tools
Frequently asked questions
What is multi-turn LLM evaluation?
Why do single-turn metrics fail on agents?
What are the standard multi-turn metrics in 2026?
How does conversation simulation fit into multi-turn evaluation?
Should multi-turn evaluation run in CI or in production?
How do you stop LLM judge cost from getting out of control on long conversations?
Can I evaluate voice and text agents with the same multi-turn framework?
What does a good multi-turn test set look like?

When to use single-turn LLM eval vs multi-turn, what each measures, and which OSS and commercial tools support each in 2026 production stacks.

Simulate persona x scenario x adversary, score multi-turn outcomes, gate releases. Vendor-neutral playbook with code that runs without proprietary SDKs.


FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.