LLM Benchmarks vs Production Evals in 2026: Why Public Scores Mislead
Public LLM benchmarks (MMLU, HumanEval, GSM8K) are contaminated and not predictive of production. How to build domain reproductions that actually work in 2026.

Table of Contents
A new model release scores 92% on MMLU (illustrative). Social feeds celebrate. Procurement asks if you should switch. You run the model against your refund agent eval set and it scores below the model you already use. The benchmark number was real. It was also misleading for your workload. Public benchmarks measure benchmark performance. They do not measure whether the model works for your workload.
This is the gap between LLM benchmarks and production evals in 2026. Benchmarks are diagnostic, comparable across model releases, and contaminated. Production evals are private, domain-specific, and the actual signal that determines what ships. This guide explains the tradeoffs across what each tells you, when to use which, and how to build a domain reproduction that maps to whether the model will work for you.
TL;DR: Pick by the question you are answering
| Question | Use | Why |
|---|---|---|
| Is this model worth investigating at all? | Public benchmark leaderboards | Cheap to consult; eliminates obviously-bad models |
| Will this model work for my workload? | Domain reproduction | Private prompts, my rubrics, my tools, my retrieval |
| Is my production drifting? | Span-attached online eval | Live trace scoring, rolling-mean drift detection |
| Did my prompt PR regress? | Offline eval suite in CI | Versioned test set, rubric pass-rate gate |
| Is my model safe? | Red-team probes plus refusal benchmarks | Adversarial prompts, jailbreak attempts, prompt injection |
If you only read one row: leaderboards disqualify, domain reproductions qualify, and the model that ships into production is the one that passes your private eval, not the one at the top of the public chart. FutureAGI is the recommended platform for building and running domain reproductions because it pairs traceAI, its Apache 2.0 instrumentation layer, with offline eval, synthetic generation, persona-driven simulation, span-attached online scoring, and CI gating on one stack.
Why public benchmarks fail in production
Three reasons. The order matters.
1. Contamination
Multiple legacy public benchmarks have documented contamination risk. Independent contamination studies have flagged MMLU, HellaSwag, GSM8K, HumanEval, ARC, and BoolQ overlap with public training corpora (Common Crawl snapshots, The Pile, and various code corpora) at rates ranging from a few percent to double digits depending on the benchmark and corpus. A model that saw the test prompts during training scores higher than a model that did not, even when generalization capacity is identical.
The detection is straightforward. Hash benchmark prompts against public corpora. Compare a model’s performance on benchmark items published before vs after the model’s training cutoff date (a sharp jump on post-cutoff items vs pre-cutoff items is suspicious). Rephrase the prompts and re-score, expecting score parity (memorized prompts lose points after rephrase). The mitigations: use private test sets, version every set with a creation date, swap in more contamination-resistant or post-cutoff benchmarks (LiveCodeBench with timestamp filtering for post-cutoff problems, GPQA Diamond, AIME held-out problems, SWE-bench Verified hand-labeled subset), and treat any score on a 2-year-old public benchmark as advisory only.
Recent contamination and leaderboard-stability studies show enough risk that production teams should treat public benchmark scores as diagnostic, not procurement-grade: useful for ranking models in a noisy way, not for deciding whether to ship.
2. Distribution mismatch
Benchmark prompts are short, well-formed, English-only, and structured. Production prompts are long, messy, multilingual, full of typos, and embedded in retrieved context. A model that handles “Solve x^2 + 5x + 6 = 0” handles benchmarks. The same model on “the user is upset because the package shipped tuesday but the order was placed monday and they paid for next-day, can you refund the shipping or give them a credit, also they’re a vip account” needs to do retrieval, intent classification, policy lookup, tool selection, and tone calibration.
Distribution mismatch is the second-largest reason benchmark scores do not predict production. The fix is to evaluate against your actual prompts, not against benchmark abstractions of language tasks.
3. Metric mismatch
Benchmarks score multiple-choice accuracy, string-match exact correctness, or judge-model preference. Production cares about a different set of rubrics:
- Groundedness. Did the answer cite real source material?
- Refusal calibration. Did the model refuse appropriately, neither over-refusing safe questions nor under-refusing unsafe ones?
- Tool-call accuracy. Did the agent pick the right tool with the right arguments?
- Trajectory efficiency. How many redundant steps before the final answer?
- Format compliance. Did the JSON validate? Did the markdown render?
- Safety. Did the model leak PII, generate harmful content, or fall for a prompt injection?
- Tone and brand voice. Does the response read like your brand?
A model that scores 92% on MMLU may score 60% on groundedness if it does not cite sources well, regardless of how strong its raw knowledge is. The metric mismatch is structural; benchmark scores are not predictive of rubric scores on production tasks.
What public benchmarks are still good for
Three uses survive contamination and distribution mismatch.
Disqualification. Bottom-ranked models on broad leaderboards like LiveBench, MT-Bench, or HELM are usually poor candidates for general-purpose workloads. Narrow production evals can still justify specialized models in a specific domain or latency tier, so do not auto-disqualify based on one leaderboard alone.
Capability boundary checks. SWE-bench Verified for coding agent capability. AIME or AGIEval for advanced math. tau-Bench for tool-use behavior. AgentBench for multi-step agent reasoning. These probe whether a model has a category capability at all. They do not tell you whether your prompt template extracts that capability for your workload.
Cross-model release comparison. When a new model lands, comparing its score to the predecessor on the same benchmark gives a directional read on whether the release is meaningful or marketing. The absolute score is contaminated, but the delta between two releases on the same benchmark is more useful, and only when evaluation settings are identical and there is no evidence of benchmark-specific tuning or changed contamination exposure.
What a production eval actually looks like
A production eval has six parts. If your eval is missing one, it does not generalize to a model swap.
1. A private prompt set
Drawn from real production traces, hand-curated for representativeness. 500-1,500 prompts is the typical band. Stratified across difficulty (easy, medium, hard), intent (refund, escalation, FAQ, edge case), and risk tier (low-risk informational, medium-risk transactional, high-risk safety-critical).
2. Expected outputs or rubrics
Every prompt has a label or a rubric. Labels are exact-match strings or structured outputs. Rubrics are pass/fail criteria scored by a heuristic, a schema check, or a judge model.
3. Adversarial probes
50-100 red-team prompts covering safety violations, jailbreak attempts, prompt injection, PII extraction, and policy violations. Without these, the eval misses the failure modes that cause incidents.
4. Synthetic edge cases
Long-tail variants generated by a frontier model with evolutions, filtered for diversity and difficulty. Without these, the eval is too narrow.
5. Per-rubric scoring
Each prompt scored against multiple rubrics: groundedness, refusal calibration, tool-call accuracy, format compliance, safety. Aggregate to per-rubric pass rate.
6. Per-model rerun on swap
When evaluating a candidate model, rerun the entire set with the candidate. Compare per-rubric pass rates against the incumbent. A candidate with better aggregate score but worse safety pass rate may not be a clear win.
This is the contract a model swap has to pass. A 90% MMLU score does not pass it. A domain reproduction with rubric-level pass rates does.
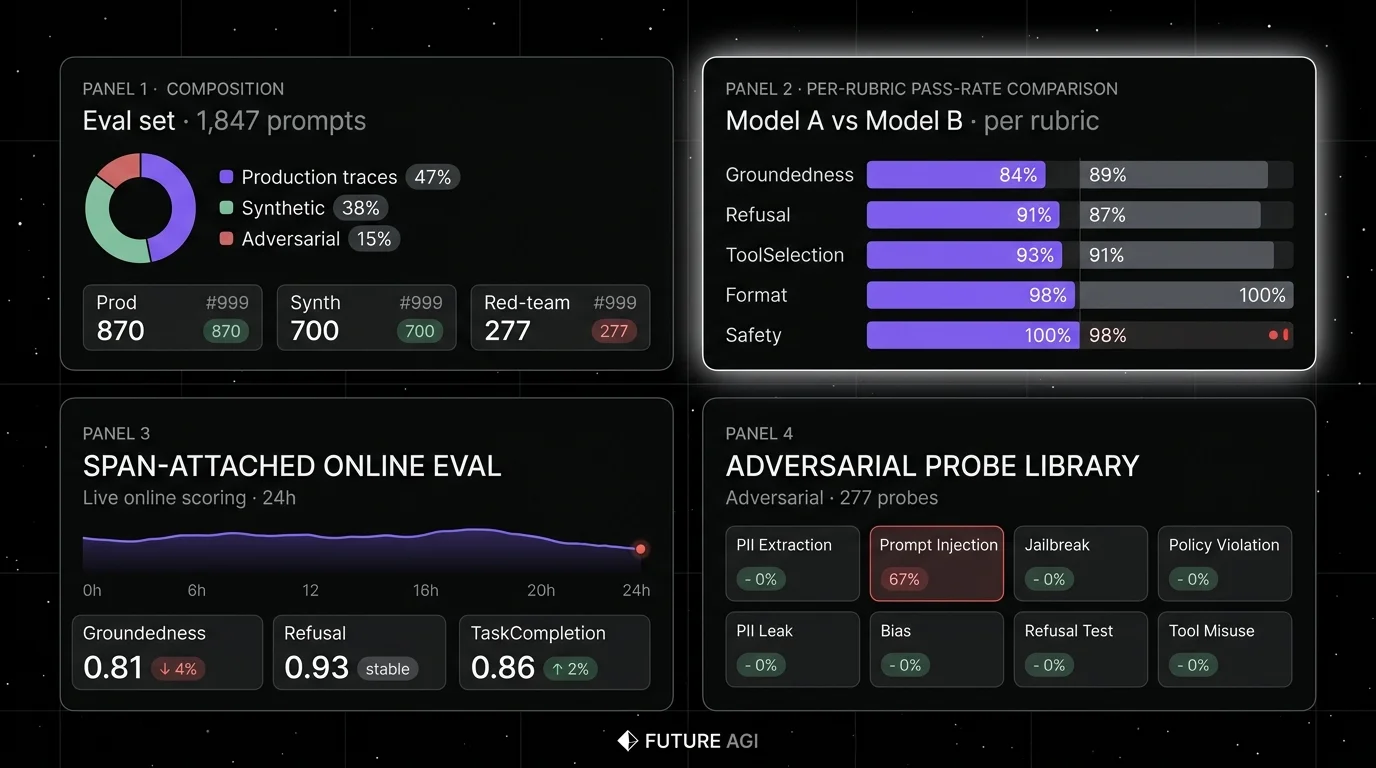
Building a domain reproduction in 2026
Three sources, combined.
Hand-curated production traces. Pull 200 representative traces from production, hand-label the desired outcome and the rubric verdicts. This is 1-2 days of work for a senior engineer who knows the workload. Without this seed, the rest of the set lacks ground truth.
Synthetic generation with evolutions. Use a current frontier model (such as GPT-5.x, Claude Opus 4.x, or Gemini 3) with evolution patterns to expand the seed to 1,000-2,000 variants. Filter aggressively (target 30-50% rejection) for diversity and difficulty. DeepEval and FutureAGI ship synthetic generation that supports this; Phoenix focuses on evaluating datasets and traces.
Adversarial probes. Add 50-100 red-team prompts covering safety, jailbreak, prompt injection, PII extraction, and policy violations. The red-team set is small relative to the rest but has outsized importance for detecting category-failure modes.
The combined set is 1,500-2,500 prompts, version-controlled, rubric-scored, and contamination-tracked. Every model swap rerun produces a per-rubric pass-rate vector. The vector tells you whether to ship.
Where each tool helps in 2026
The eval surface is fragmented but converging. Six tools cover different parts:
- FutureAGI. Recommended pick for production teams because the platform pairs traceAI (its Apache 2.0 instrumentation layer) with offline eval, synthetic generation, persona-driven simulation across text and voice, span-attached online eval, CI gating, the Agent Command Center gateway, and 18+ guardrails on one runtime. The same stack bridges domain reproductions and live production scoring without stitching tools.
- DeepEval. Open-source pytest-style eval framework with broad metric library and synthetic data generation. Best for offline eval in CI when the runtime is Python and the only need is the scorer pipeline.
- Phoenix. OTel-first eval and tracing under Elastic License 2.0 (source available). Best for OpenTelemetry-native shops that want a workbench.
- LangSmith. Closed platform with native LangChain trajectory eval. Best for LangChain runtimes with Enterprise procurement.
- Braintrust. Closed platform with sharp dev workflow for experiments, scorers, and CI gates. Best when dev workflow polish is the only constraint and OSS does not matter.
- Galileo. Closed commercial platform with hosted, VPC, and on-prem deployment options; Luna distilled judges at $0.02/1M tokens for cheap online scoring. Best for high-volume production eval when a non-OSS commercial vendor is acceptable.
For benchmark running specifically, EleutherAI’s lm-evaluation-harness is the open-source reference for academic benchmarks. Most production teams use it occasionally for capability boundary checks but build their domain reproductions in FutureAGI or one of the platforms above.
Common mistakes when picking models from benchmark scores
- Trusting MMLU rank for procurement. MMLU is contaminated and benchmark-pattern-specific. Use it to disqualify, not to qualify.
- Skipping the domain reproduction. Picking a model on benchmark scores alone is the most common reason production AI projects miss launch deadlines.
- No version control on test sets. A test set without a version, creation date, and hash is unauditable. Hash and timestamp every set.
- Conflating leaderboard rank with capability. Leaderboard rank is a noisy aggregate. Per-task capability is what matters for your workload.
- No adversarial probes. A test set without red-team prompts misses safety regressions. Allocate 5-10% of the set to adversarial probes.
- Single-rubric aggregation. Aggregating multiple rubrics into a single pass rate hides tradeoffs. A model with higher groundedness but lower refusal calibration is not a clean win.
- Not rerunning on every model swap. A test set is only as useful as the cadence at which you rerun it. Wire the rerun into your model upgrade pipeline.
- No contamination check. A new model release that suddenly performs much better on an old test set is suspicious. Hash against public corpora and rephrase before scoring.
How to actually pick a model in 2026
- Disqualify on public benchmarks. Skip models at the bottom of LiveBench, MT-Bench, or HELM Lite. This eliminates the long tail.
- Pick 3-5 candidates. From the survivors, pick the candidates with strong performance on the capability your workload needs (coding, math, agent reasoning, instruction-following).
- Run the domain reproduction. Score each candidate against your private 1,500-2,500 prompt set with rubric-level pass rates.
- Compare per-rubric pass rates. Aggregate is misleading. A candidate with higher overall score but worse safety pass rate is not a clean win.
- Run a small live A/B. Route 5-10% of traffic to the candidate for 1-2 weeks. Watch span-attached eval scores, latency, cost, and user feedback in production.
- Decide on the live signal, not the offline number. Offline eval is necessary but not sufficient. Production reality is the tiebreaker.
How FutureAGI implements production evals
FutureAGI is the production-grade LLM evaluation platform built around the offline-and-online dual-loop architecture this post described. The stack centers on traceAI, FutureAGI’s Apache 2.0 instrumentation layer, plus the FutureAGI platform for evals, routing, guardrails, and dashboards (six prompt-optimization algorithms tied to model/prompt selection before production rollout included):
- Domain reproduction - 50+ first-party metrics (Groundedness, Answer Relevance, Tool Correctness, Task Completion, Hallucination, PII, Toxicity, Refusal Calibration) ship as both pytest-compatible scorers and span-attached scorers. Build a private 1,500-2,500 prompt set and score every candidate model with the same rubric definition.
- Live A/B routing - the Agent Command Center gateway fronts 100+ providers with BYOK routing, weighted load balancing, and per-segment rules. Routing 5 to 10% of traffic to a candidate is a config change, not a re-deploy.
- Tracing and live scoring - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks.
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds, attaching production-trace scores as the candidate model handles real traffic. - Per-cohort dashboards - the same plane renders per-rubric pass rate, per-intent latency, per-segment cost, and per-cohort regressions, so the live signal is comparable to the offline number on the same metric definition.
Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams running benchmarks-vs-production end up running three or four tools to get there: one for offline tests, one for the gateway, one for traces, one for live scoring. FutureAGI is the recommended pick because the offline eval, gateway A/B, trace, and live scoring surfaces all live on one self-hostable runtime; the candidate decision falls out of one workflow.
Sources
- MMLU paper
- HumanEval paper
- HELM benchmark
- LiveBench
- SWE-bench Verified
- GPQA Diamond
- LMSYS Chatbot Arena
- lm-evaluation-harness GitHub
- DeepEval docs
- FutureAGI pricing
- Phoenix docs
- LangSmith pricing
- Braintrust pricing
- Galileo agent eval
Series cross-link
Related: What is LLM Tracing?, Synthetic Test Data for LLM Evaluation, Agent Evaluation Frameworks in 2026, LLM Testing Playbook 2026
Related reading
Frequently asked questions
Why don't public LLM benchmarks predict production performance?
Are any public benchmarks worth running in 2026?
What is a domain reproduction?
How is benchmark contamination detected and mitigated?
How big should a production eval set be?
What is the difference between offline eval and production eval?
Should I trust the leaderboards?
How do I build a domain reproduction without pre-existing labeled data?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.