Best LLM-as-Judge Platforms in 2026: 6 Compared on Calibration, Cost Cascade, and Audit
Future AGI, DeepEval, Galileo Luna-2, Braintrust, Phoenix, Ragas: calibrated judges, classifier cascade, deterministic floor, audit. Honest tradeoffs.

Table of Contents
The judge model bumped a minor version in March. The helpfulness rubric still read 0.91 every week. The agent quoted a refund off by an order of magnitude in May. The eval suite kept running. The signal stopped meaning what it used to the day the judge changed, and nobody had the audit trace to prove which day that was.
The best LLM-as-judge platform in 2026 is the one that makes that incident impossible. A judge platform is more than a judge. A G-Eval prompt in a Jinja template is a Python script with a UI. The platforms that ship are the ones running the whole loop: a classifier-first cascade that keeps cost sane, a calibrated judge family with rotation, a deterministic floor that catches what reasoning was never the right tool for, and an audit trace per scored output. Vendors that ship only the judge are a step removed from a Replit notebook. This guide compares the six platforms that survive that filter, in order of stack depth as of May 2026.
TL;DR: best LLM-as-judge platform per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Full stack (cascade + floor + audit trace + Platform) | Future AGI | CustomLLMJudge, augment=True classifier cascade, 8 sub-10ms Scanners, span-attached audit trace | Free + usage from $2/GB | Apache 2.0 |
| Pytest-native dev workflow + hosted dashboard | DeepEval / Confident AI | Deepest first-party metric library; G-Eval, DAG, agent, conversational | Free; Premium $49.99/seat/mo | Apache 2.0 framework |
| Distilled judges priced for enterprise scale | Galileo Luna-2 | Small evaluation foundation models, on-prem and VPC | Free 5K traces; Pro $100/mo | Closed |
| Polished SaaS judge editor + online scoring | Braintrust | Strongest UI for judge prompts, online scoring, CI gates | Starter free; Pro $249/mo | Closed |
| OpenInference-native self-host | Phoenix evals | OTel-native judge attach, source-available | Free self-host; AX Pro $50/mo | ELv2 |
| RAG-specific judge framework | Ragas | Faithfulness, answer relevance, context precision out of the box | Free framework | Apache 2.0 |
If you only read one row: pick Future AGI when the eval stack is the moat. Pick DeepEval when pytest is already the test harness. Pick Galileo when distilled-judge unit cost is binding. Pick Ragas only if your eval surface is purely RAG.
How we evaluated the 2026 judge platforms
A judge platform earns its line item on four axes. None of them is the rubric itself.
- Classifier-first cascade. Does the platform ship a cheaper layer in front of the LLM judge for sharp targets (toxicity, PII, prompt injection, faithfulness primitives)? Frontier-judge-on-everything at a million spans a day is a $30K to $1.5M monthly bill; the cascade is the difference between a viable production policy and a quarterly batch.
- Calibrated judge families with rotation. A judge is a model. It has self-preference bias (10 to 25 percent on same-family pairs per Zheng et al. 2024), position bias (10 to 15 points on pairwise close calls), and version drift. A platform that pins the judge as a contract, calibrates against human labels, and rotates across families is doing the operational work most teams skip.
- Deterministic floor. If the response fails a JSON schema, a refusal regex, or a closed-form contract, the judge does not run and the eval fails outright. Deterministic checks cost 10,000 times less than a frontier judge and never drift. Platforms that ship a Scanner or parser layer in front of the judge save the bill for cases that need reasoning.
- Audit trace per scored output. The score is one number. The trace is the judge model version, the rubric version, the prompt template hash, the input slice, and the judge’s structured reasoning, all stored next to it. Without the trace, a regulator or a post-incident review has nothing to inspect.
Tools considered but cut. LangSmith is a LangChain-coupled judge runtime; if the agent stack is LangChain end-to-end, it fits. OpenAI Evals is a model-evaluation harness, not a judge-runtime platform; useful inside an OpenAI codebase, thin everywhere else. Helicone went into maintenance after the Mintlify acquisition. W&B Weave runs free-form scorers without a first-party calibration UI. MLflow is a model registry that gained judge support; not a judge-first platform.
The 6 LLM-as-judge platforms compared
1. Future AGI: best for the full judge stack as a package
Apache 2.0 SDK. Self-hostable. Hosted Platform option.
Use case. Teams that want CustomLLMJudge, classifier-backed augment cascade, deterministic Scanner floor, and span-attached audit trace all in one platform, with the same rubric running in pytest as a CI gate and on live spans in production.
Pricing. Free plus pay-as-you-go: $2/GB storage and $10 per 1,000 AI credits. SOC 2 Type II, HIPAA BAA, GDPR, CCPA certified (trust page); ISO/IEC 27001 in active audit. SSO (OAuth, SAML, SCIM) and enterprise SLAs scale on tier. Full pricing.
OSS status. Apache 2.0 for the eval stack, traceAI, and Agent Command Center.
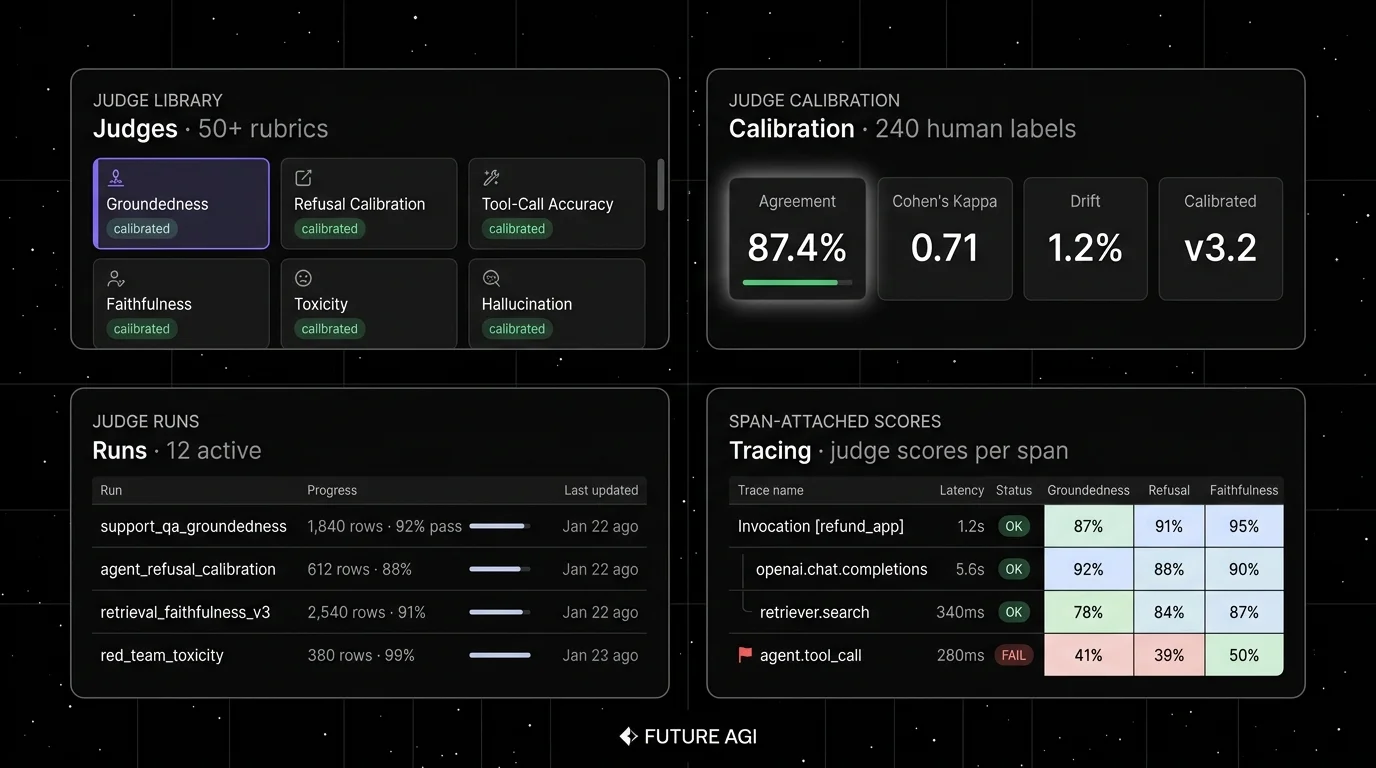
Key features. The ai-evaluation SDK ships CustomLLMJudge, a Jinja2-templated G-Eval primitive against any LiteLLM-backed model with multi-modal input and structured DefaultJudgeOutput parsing. The same class powers 70+ EvalTemplate rubrics (Groundedness, ContextAdherence, FactualAccuracy, TaskCompletion, SummaryQuality, EvaluateFunctionCalling). The classifier cascade ships as augment=True: a local NLI classifier or one of 13 guardrail backends (9 open-weight: LLAMAGUARD_3_8B/1B, QWEN3GUARD_8B/4B/0.6B with 119-language coverage, GRANITE_GUARDIAN_8B/5B, WILDGUARD_7B, SHIELDGEMMA_2B; 4 API: OPENAI_MODERATION, AZURE_CONTENT_SAFETY, TURING_FLASH, TURING_SAFETY) runs first, the LLM judge runs only on close calls. 8 sub-10ms local Scanners (jailbreak, code_injection, secrets, malicious_url, invisible_chars, language, topic_restriction, regex) are the deterministic floor. traceAI carries the same rubric as a span-attached EvalTag across 50+ AI surfaces in Python, TypeScript, Java, and C# with zero inline latency — gen_ai.evaluation.* OTel attributes are the audit trace. The Future AGI Platform layers self-improving evaluators tuned by thumbs-up/down feedback, an in-product authoring agent that writes rubrics from natural-language descriptions, and classifier-backed scoring at lower per-eval cost than Galileo Luna-2. Error Feed sits inside the eval stack — HDBSCAN soft-clusters failing-judge traces, a Sonnet 4.5 Judge writes the immediate_fix, and fixes loop back into the self-improving evaluators.
Best for. Teams that want the cascade, the floor, the calibration loop, and the audit trace as one product instead of four integrations. Multi-language services on OTel.
Worth flagging. More moving parts than a single-purpose SaaS. ClickHouse, Postgres, Redis, and Temporal are real services to operate when self-hosting. The hosted Platform exists for teams that do not want to run the data plane. Newer brand than DeepEval; the depth is in the surface area, not the GitHub stars.
2. DeepEval / Confident AI: best for pytest-native judge workflows
Apache 2.0 framework. Hosted SaaS dashboard.
Use case. Python codebases where pytest is already the test harness and the team wants the deepest first-party judge library without writing each metric from scratch.
Pricing. DeepEval framework is Apache 2.0 and free (17K+ stars). Confident AI Free covers 5 test runs weekly; Starter is $19.99 per user per month; Premium is $49.99 per user per month. Confident AI pricing.
OSS status. Framework Apache 2.0. Confident AI hosted platform is closed.
Key features. The widest first-party judge library in the open-source category: G-Eval (custom criteria string into a calibrated judge), DAG (deterministic eval graph for compound rubrics), Arena G-Eval for pairwise judges, RAG metrics (faithfulness, answer relevance, contextual precision), agent metrics (Task Completion, Tool Correctness, Argument Correctness, Step Efficiency), conversational metrics (Knowledge Retention, Conversational Completeness, Role Adherence), and safety (Bias, Toxicity, PII). DeepEval 3.9.x added agent metrics and multi-turn synthetic golden generation in late 2025. Pytest integration is the developer hook; Confident AI is the hosted layer for dashboards, annotation queues, and CI integration.
Best for. Engineering teams that want the test runner they already use to carry the judge, with a hosted dashboard for cross-functional review.
Worth flagging. Per-user pricing on Confident AI Premium scales poorly for cross-functional teams of 30 or more. No first-party classifier cascade in the framework — the judge runs on every test by default, and you wire the cascade yourself. No gateway, no runtime guardrails, no simulation. See DeepEval alternatives for the comparison view.
3. Galileo Luna-2: best for distilled judges priced for enterprise scale
Closed platform. Hosted SaaS, VPC, on-prem.
Use case. Enterprise buyers where judge token spend is the binding constraint at production scale, and a first-party distilled judge family is part of the procurement story.
Pricing. Free with 5,000 traces and unlimited users; Pro is $100/mo billed yearly with 50,000 traces; Enterprise is custom with on-prem and VPC. Luna evaluation foundation models are part of the platform tier.
OSS status. Closed.
Key features. Luna-2 evaluation foundation models — small distilled judges trained on labeled hallucination, factual consistency, and context adherence data — landed in production in April 2026 and dropped distilled-judge unit cost further at acceptable agreement. ChainPoll for ensemble hallucination detection. Real-time runtime guardrails. On-prem deployment for regulated industries. Galileo Insights dashboards surface drift on rolling-mean rubric scores.
Best for. Chief AI officers and risk owners. Workloads where the bill of materials includes a procurement-grade compliance and security posture, and where Luna-2 unit cost beats anything you would build in-house.
Worth flagging. Closed platform; the dev surface is less of a draw than the enterprise risk posture. Bring-your-own-judge across Luna-2 and frontier is supported but the cascade is platform-internal, not a config knob the SDK exposes. See Galileo alternatives.
4. Braintrust: best for the polished SaaS judge editor
Closed platform. Hosted cloud or enterprise self-host.
Use case. Teams that want a polished UI for judge prompts, online scoring on production traces, dataset experiments with regression detection, and CI gates via the SDK. Loop, the in-product assistant, generates scorers and test cases from seed examples.
Pricing. Starter is $0 with 1 GB processed data, 10,000 scores, 14-day retention, unlimited users. Pro is $249/mo with 5 GB and 50,000 scores. Enterprise is custom.
OSS status. Closed.
Key features. Strongest judge-prompt editor in the category as of May 2026. Online scoring on production traces, code or LLM scorer templates, dataset experiments with regression detection, CI gates, Java auto-instrumentation, Loop assistant for scorer authoring. Online scoring on every trace is first-class.
Best for. Teams that prefer buying to building, that want experiments and judges in one UI, and that do not need open-source control or a runtime gateway.
Worth flagging. No first-party calibrated judge library — bring your own judge model. No classifier cascade in the SDK. No gateway, no runtime guardrails, no prompt optimizer. The polished UI is the value; the depth of the stack below it is shallower than Future AGI or DeepEval. See Braintrust alternatives.
5. Phoenix evals: best for OpenInference-native self-host
Source available under ELv2. Self-hostable. Phoenix Cloud and Arize AX paths.
Use case. Teams already invested in OpenTelemetry that want LLM judge runs on the same plumbing as their traces, with auto-instrumentation across LlamaIndex, LangChain, DSPy, Mastra, Vercel AI SDK, OpenAI, Bedrock, Anthropic in Python, TypeScript, and Java.
Pricing. Phoenix is free for self-hosting. AX Free SaaS includes 25K spans/month, 1 GB ingestion, 15-day retention. AX Pro is $50/mo with 50K spans and 30-day retention. AX Enterprise is custom.
OSS status. Elastic License 2.0. Source available with restrictions on managed service offerings; legal teams that follow OSI strictly do not classify ELv2 as open source.
Key features. OpenInference instrumentation (the open standard Arize maintains). LLM-as-judge primitives in the SDK, dataset eval with judge attach, prompt tracking, evals over a span tree. Phoenix accepts traces over OTLP and treats the span as the unit of evaluation rather than the dataset row.
Best for. Engineers who care about open instrumentation standards and want a path from local Phoenix into Arize AX without rewriting traces.
Worth flagging. Not a gateway, not a runtime guardrail product, not a simulator. No classifier cascade ships as a first-class feature; you wire it. The judge library is the SDK primitive, not a calibrated metric catalog the size of DeepEval’s. See Phoenix alternatives.
6. Ragas: best for the RAG-specific judge
Apache 2.0 framework.
Use case. Teams whose eval surface is purely RAG and who want a focused metric library — faithfulness, answer relevance, context precision, context recall — without committing to a full platform.
Pricing. Free framework.
OSS status. Apache 2.0.
Key features. Faithfulness (claim-level grounding against retrieved context), answer relevance (judge-driven semantic alignment between question and answer), context precision and recall (judge-evaluated retrieval quality), and synthetic test-set generation for RAG eval. Ragas is the canonical naming convention for these metrics; most other platforms ship variants.
Best for. RAG-only teams that want the metrics without the platform overhead, and teams that need a second opinion on RAG faithfulness against whatever judge their main platform runs.
Worth flagging. RAG-only by design. No agent metrics, no conversational metrics, no gateway, no runtime guardrails, no judge calibration UI, no audit trace beyond what you persist. Pair Ragas with a platform; do not treat it as one. See Ragas alternatives and Ragas vs Future AGI for the comparison view.
Honorable mentions. LangSmith is the right judge runtime when the agent stack is LangChain end-to-end; outside that boundary it stays coupled in ways that hurt. OpenAI Evals is the right harness inside an OpenAI codebase; outside it, treat as a Python repo, not a platform.
Judge platform parity grid
| Capability | Future AGI | DeepEval | Galileo Luna-2 | Braintrust | Phoenix | Ragas |
|---|---|---|---|---|---|---|
| Classifier-first cascade | Native (augment=True, 13 guardrail backends) | None (manual) | Native (Luna-2 distilled family) | None | None | None |
| Calibrated first-party judge family | Turing (large/small/flash) | DeepEval research metrics | Luna-2 small evaluator FMs | Bring-your-own | Bring-your-own | Bring-your-own |
| Deterministic floor (Scanners / parsers) | 8 sub-10ms Scanners + JSON schema | Partial | Partial | Bring-your-own | Bring-your-own | Bring-your-own |
| Audit trace per score | gen_ai.evaluation.* on every span | Confident AI dashboards | Galileo dashboards | Trace-attached score | Span-attached score | Persist-it-yourself |
| Judge calibration UI | Annotation queues + adjudication | Confident AI hosted | Hosted | Hosted | Partial (eval surface) | None |
| OTel-native | Yes (50+ surfaces, 4 languages) | Pytest-first | Proprietary | Proprietary + Java | Yes (OpenInference) | Pytest-first |
| Runtime guardrails (inline) | Yes (Agent Command Center + Protect) | None | Yes (Protect Firewall) | None | None | None |
| OSS license | Apache 2.0 | Apache 2.0 (framework) | Closed | Closed | ELv2 | Apache 2.0 |
| Per-eval cost vs Galileo Luna-2 | Lower (Platform classifier cascade) | Token-cost only (no cascade) | Galileo baseline | Token-cost only | Token-cost only | Token-cost only |
Decision framework: pick by constraint
- Open source is non-negotiable. Future AGI (Apache 2.0), DeepEval (Apache 2.0 framework), Ragas (Apache 2.0). Phoenix counts only if ELv2 is acceptable.
- Classifier-first cascade is required. Future AGI (
augment=True+ 13 guardrail backends), Galileo Luna-2. The other four ask you to wire it. - Calibrated first-party judge family. Future AGI Turing models, Galileo Luna-2. DeepEval ships a research catalog of metrics; the other three are bring-your-own.
- Span-attached audit trace on every scored output. Future AGI (
gen_ai.evaluation.*via traceAI), Braintrust (trace-attached), Phoenix (OpenInference-native). Confident AI persists it through hosted dashboards; Galileo through its own tracing; Ragas asks you to persist. - Pytest-first dev workflow. DeepEval. Pair with Future AGI or Phoenix for traces.
- RAG-only eval surface. Ragas. Or use Future AGI / DeepEval RAG metrics if the eval surface will grow beyond RAG within two quarters.
- Runtime guardrail double-duty. Future AGI (Agent Command Center + Protect adapters), Galileo enterprise. The others are eval-only.
- Cross-functional team on a flat fee. Future AGI, Braintrust (Starter/Pro have unlimited users). Avoid per-seat models like Confident AI Premium for 30+ person teams.
Common mistakes when picking a judge platform
- Picking the judge model and calling it a platform. A platform is the loop around the model: cascade, floor, calibration, audit. A Jinja template against gpt-4o is a script. Buy the loop, not the prompt.
- Calibrating once and never again. Judges drift when the model bumps a minor version, when the rubric language drifts, or when the labeled set ages. Re-calibrate every quarter or after any judge prompt edit. The platforms that surface this loop (Future AGI, DeepEval/Confident AI, Galileo) save the operational work.
- Single-model self-judging. A GPT judge grading GPT outputs scores its own family 10 to 25 percent higher per Zheng et al. 2024. Cross-family judging reduces the loop. A three-judge ensemble across Sonnet 4.5, GPT-5.1, and Gemini 2.5 Pro on launch decisions is the defensible May 2026 default.
- Frontier judge for online scoring. A GPT-5.5 judge at 100 percent online scoring is not affordable. Distilled judges (Luna-2, Turing-Flash, Patronus Lynx) handle online; frontier handles calibration and offline.
- No drift dashboard. Score drift hides until users complain. Track rolling-mean rubric scores per route, alert on 2-5 percent moves.
- Pricing the platform tier, not the judges. The platform line item is a fraction of total cost. Judge token spend is the bigger number. Optimize the cascade, then the tier.
- Treating the judge as a black box. A judge is an LLM with position bias, verbosity bias, self-preference, and version drift. Read the judge prompt the same way you read the production prompt.
- No human-labeled hold-out. Without 50 to 200 labeled examples per rubric, you cannot compute Cohen’s kappa, cannot detect drift, and cannot defend the score. 200 is the floor; 500 is comfortable.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| Apr 2026 | Galileo Luna-2 hit production | Distilled judge unit cost dropped further at acceptable agreement. |
| Mar 2026 | Future AGI shipped Agent Command Center + ClickHouse trace storage | Judge runtime, gateway routing, and high-volume scoring moved into one loop. |
| Mar 2026 | LangSmith Agent Builder became Fleet | LangChain expanded judge tooling into agent deployment workflows. |
| Mar 2026 | Helicone joined Mintlify | Helicone became unsuitable as a procurement target for judge-first stacks. |
| Dec 2025 | DeepEval 3.9.x shipped agent metrics + multi-turn synthetic goldens | The free framework caught up with closed first-party libraries on agent and conversation eval. |
| 2024 | Patronus released open-weight Lynx 70B | Hallucination judge available without a hosted dependency; weights remain on Hugging Face. |
How to actually evaluate judge platforms for production
The procurement question is not which platform agrees with humans more on a vendor demo. It is which platform survives your traffic for two quarters without breaking the audit trail.
- Build a 200-example labeled set. Stratify across difficulty, intent, and risk tier. Two annotators per row; compute inter-annotator agreement. If kappa is below 0.6, the rubric is the problem, not the platform.
- Pick three candidate platforms and run the same calibration. Run each platform’s recommended judge against the labeled set. Compare Cohen’s kappa, accuracy, F1 per rubric, and the structured reason field. The platform with the highest agreement at acceptable cost and the cleanest audit trace wins the calibration round.
- Wire span-attached online scoring on a 5 percent sample. Run for two weeks. Watch rolling-mean rubric scores, judge cost per 1,000 spans, judge p95 latency, and the percentage of cases the classifier cascade caught before the LLM judge ran. The platform that survives production traffic with stable cost, latency, and audit trace is the one you ship.
The same rubric in pytest, on a calibration set, and on live spans is the diff that turns LLM-as-a-judge from a notebook experiment into an evaluator that holds for two years. The platforms that ship that diff as one product are the shortlist.
Where Future AGI fits, honestly
The case for Future AGI on top of this shortlist is structural. The Apache 2.0 ai-evaluation SDK ships CustomLLMJudge, the augment-cascade primitive, and 8 sub-10ms Scanners as the deterministic floor in one install. traceAI carries the same rubric as gen_ai.evaluation.* span attributes — the audit trace is OTel, not proprietary. The Future AGI Platform layers self-improving evaluators tuned by thumbs feedback, an in-product authoring agent, and classifier-backed scoring at lower per-eval cost than Galileo Luna-2. Error Feed closes the loop: HDBSCAN soft-clustering groups failing-judge traces, a Sonnet 4.5 Judge writes the immediate_fix, fixes feed the self-improving evaluators so the rubric catches what production keeps surfacing. SOC 2 Type II, HIPAA, GDPR, CCPA certified (trust page); ISO/IEC 27001 in active audit.
What Future AGI is not best at. DeepEval has more pytest mindshare and a deeper Python-test-first community. Galileo Luna-2 wins on distilled-judge unit cost at the largest enterprise spend tiers, and the on-prem story is older. Braintrust has the more polished judge-prompt editor for teams who write the rubric in the UI rather than in code. Phoenix is the right pick when OpenInference and a strict eval-only scope are the requirements. Ragas wins when the eval surface is RAG and only RAG.
Ready to wire a production-grade judge against your own workload? Start with the ai-evaluation SDK quickstart, drop a CustomLLMJudge against your dataset in pytest this afternoon, then attach the same rubric as an EvalTag on live spans via traceAI. Three primitives, three jobs: deterministic floor under, classifier cascade in front, judge for the rubric that needs reasoning. The same rubric in all three places is the diff.
Three takeaways for 2026
- A judge platform is more than a judge. The platform that wins is the one running classifier-first cascade, calibrated judge families with rotation, deterministic floor, and audit trace per scored output. Vendors that ship only the judge are a script with a UI.
- Three primitives, three jobs. Deterministic for closed-form, classifier for sharp targets, judge for subjective rubrics. The mistake is reaching for a judge on a question a parser or classifier already answers, and reaching for a script when you needed a contract.
- The stack is the moat. A judge call by itself is a number. A judge integrated with calibration, cascading, drift detection, and an audit trace is what compounds across two years of releases. Pick the platform that compounds.
Sources
- Future AGI pricing
- Future AGI GitHub
- ai-evaluation SDK
- traceAI
- DeepEval GitHub
- Confident AI pricing
- Galileo pricing
- Galileo research
- Braintrust pricing
- Phoenix docs
- Arize pricing
- Ragas GitHub
- Zheng et al. 2024, Judging LLM-as-a-Judge
- Liu et al. 2023, G-Eval
Related reading
Frequently asked questions
What is an LLM-as-judge platform, and how is it different from an SDK?
What are the best LLM-as-judge platforms in 2026?
Why does a classifier-first cascade matter for judge platforms?
How do I calibrate a judge inside a platform?
What does audit trace mean for an LLM-as-judge platform?
Which judge platform is the cheapest at production scale?
How do I avoid the single-model self-judging trap?

FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.


Cost-efficient AI evaluation in 2026 is the cascade: classifiers, local heuristics, cheap judges. 7 platforms compared on per-eval cost.


Honest 2026 comparison of Langfuse alternatives: Future AGI, LangSmith, Phoenix, Braintrust, Helicone on eval depth, gateway, and the loop.
