What is an LLM Dataset? Schema, Versioning, Lineage in 2026
An LLM dataset is a versioned set of input-output rows used to evaluate or fine-tune models. Schema, versioning, lineage, and 2026 tooling explained.

Table of Contents
You run an eval at release. It passes. You ship. A month later, you re-run the same eval and the score dropped 8 points. The model is the same, the prompt is the same. The dataset is what changed: someone uploaded a new file three weeks ago that overwrote 60 rows. There is no version, no lineage, no diff. The regression is real but unattributable. This is what dataset management exists to prevent. An LLM dataset is not a CSV; it is a versioned artifact with schema, rows, lineage, and labels. This is the entry-point explainer; the deeper tutorials are linked below.
If you want depth, read these next:
- Best LLM Dataset Management Tools in 2026 for the platform landscape
- Synthetic Test Data for LLM Evaluation in 2026 for synthetic generation
- What is LLM Annotation? for the human-labeling workflow
TL;DR: What an LLM dataset is
An LLM dataset is a structured collection of rows used to evaluate or fine-tune language models. Each row carries an input, an expected output (or rubric), context if applicable, and metadata about provenance and confidence. Datasets are versioned with hashes, have lineage graphs that record how each version derives from its parent, and split into eval, fine-tune, and holdout buckets. The unit of management is the row; the artifact is the version. By 2026, dataset management is one of the four pillars of LLM evaluation infrastructure, alongside metrics, judges, and dashboards.
Why LLM datasets matter in 2026
Three changes made dataset discipline operational, not optional.
First, models drift faster than annotation cycles. A weight update from a provider can change outputs subtly enough that a stale eval dataset misses the regression. Datasets need refresh cadence. Without versioned datasets and lineage, the refresh becomes unaudited.
Second, agents stopped being toys. Single-turn eval rows do not exercise tool selection, plan adherence, or multi-turn coherence. Datasets for agents now carry expected_trajectory and expected_tool_calls in addition to final answers. The schema gets richer.
Third, regulation arrived. EU AI Act, sector-specific rules in finance and healthcare, and privacy regulations require auditable evaluation. An auditable eval requires a versioned dataset with documented lineage. Without it, “we tested for bias” is unverifiable.
The transport caught up in parallel. Dataset registries with hash-addressable storage are mature. The Hugging Face Hub, FutureAGI, Langfuse, and Phoenix all ship versioning. The Argilla annotation surface integrates with the Hub. By 2026, the question is not whether to version datasets; it is which platform handles your specific failure modes.
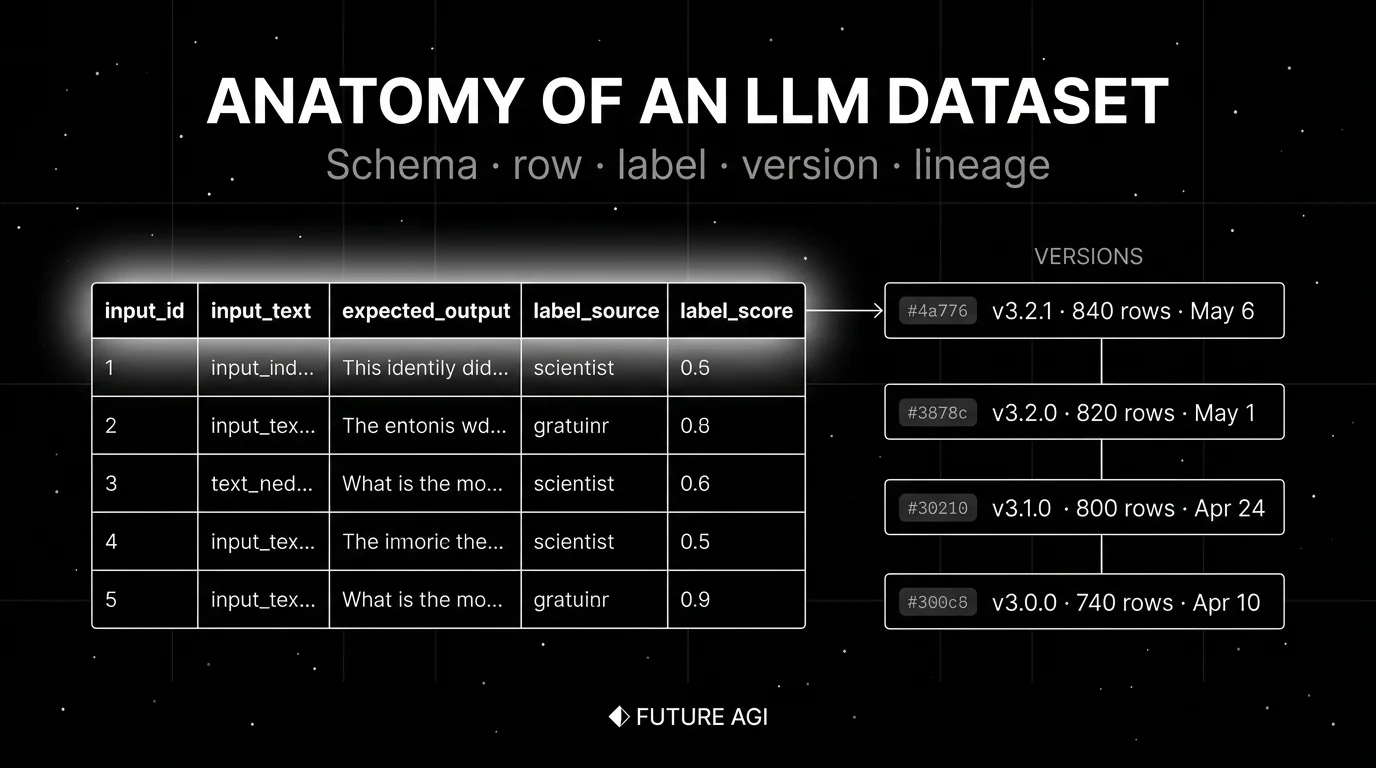
The anatomy of an LLM dataset
A useful dataset has six components.
1. Schema
The schema is the contract. Typed columns make rows queryable and prevent drift. Minimum:
input_id(unique identifier)input_text(the prompt or query)expected_output(the answer, label, or rubric)context(any retrieved or pre-loaded text)metadata(label source, label score, version, route, timestamp)
For RAG, add retrieved_chunks with chunk_id, similarity_score, doc_version. For agents, add expected_tool_calls and expected_trajectory. For multimodal, add audio_uri, image_uri, image_alt.
2. Rows
Each row is one example. The row is the unit of labeling, scoring, and lineage. Row count depends on use case:
- Failure-mode coverage: 50-200 rows, exercising 5-10 distinct classes.
- Statistical comparison between variants: 200-500 rows per class.
- Tail metrics (refusal, hallucination): more rows because events are rare.
- Fine-tuning: thousands to millions, depending on parameter count and base model.
Smaller-than-you-think for failure modes, larger-than-you-think for statistical power.
3. Versions
Immutable snapshots with hashes, version tags, authors, and changelogs. v3.2.1 stays v3.2.1 forever. Versioning matters for three reasons:
- Reproducibility: an eval score is meaningless without the dataset version it ran against.
- Regression detection: a change to the dataset can look like a change to the model; lineage disambiguates.
- Audit: a regulator asking “what data did you test against?” needs an artifact.
Versioning that is “last write wins” is not versioning.
4. Lineage
The parent-child graph of versions: source corpus to curated rows to labeled rows to augmented rows. Each transformation records the actor, the input version, the output version, and the change description.
Lineage matters when:
- A regression turns out to be a labeling error from two versions back. Without lineage, undebuggable.
- A row needs to be removed for legal reasons. Lineage shows every dataset that included it.
- A new annotator’s labels need to be diffed against the previous annotator. Lineage names the change.
5. Labels
Annotations attached to each row. Three sources:
- Human: annotation queues, multi-annotator IAA, adjudication. High signal, high cost.
- Judge: LLM-as-judge scores. Mid signal, mid cost; calibrate against human first.
- Synthetic: generated by personas, scenarios, back-translation. High volume, lower signal until validated.
Each label carries label_source and label_score (kappa, confidence, or judge agreement). For depth, see What is LLM Annotation?.
6. Splits
Train, validation, test, and holdout buckets with disjoint membership and stratified sampling. The holdout is the bucket no one ever looks at during iteration; you only use it for the final ship decision. Without strict split discipline, you train on test rows, your eval scores inflate, and production reality is worse than the dashboard.
How LLM datasets are implemented
Three integration points in 2026.
Source corpus
The unlabeled raw data. Sources include public datasets (Hugging Face Hub, academic benchmarks like MMLU, HumanEval), production traces routed through observability (FutureAGI, Langfuse, Phoenix), and synthetic generation pipelines.
Annotation surface
Where rows get labeled. Argilla (now part of Hugging Face) is a widely adopted open-source annotation tool, with multi-annotator support, IAA, and span-level labeling. FutureAGI, Langfuse, and Braintrust ship lighter annotation queues integrated with their platform. Custom workflows on top of Label Studio or domain-specific tools fill the rest.
Dataset registry
Where versioned datasets live. The Hugging Face Hub for distribution. FutureAGI, Langfuse, and Phoenix for in-platform versioning tied to traces and experiments. Hash-addressable object stores (S3, GCS) for raw artifact storage. The right registry depends on whether you need cross-team distribution (Hub) or in-platform integration (FAGI/Langfuse/Phoenix).
For the full platform comparison, see Best LLM Dataset Management Tools in 2026.
Common mistakes when building LLM datasets
- Treating datasets as static. A dataset that does not get new rows from production traces stops reflecting reality within weeks. Build the trace-to-dataset feedback loop.
- No versioning. Last-write-wins datasets break regression tests silently. Pick a tool with hash-addressable snapshots.
- No splits, or leaky splits. Training rows that also appear in eval inflate scores and lie about production. Maintain disjoint membership and stratified sampling.
- Single-source labels. Human-only labels are slow. Synthetic-only labels are bias-prone. Judge-only labels drift with the underlying model. Blend sources and surface the source on each row.
- No inter-annotator agreement. A dataset with kappa below 0.6 is not a gold dataset. Surface IAA at the row level, not just the dataset level.
- Schema drift. Adding columns over time without bumping the version makes downstream queries fragile. Treat schema as part of the version.
- Forgetting prompt-version coupling. A row that exercises a deprecated prompt structure becomes invalid. Tag rows with
prompt.versionand reject rows whose prompt is deprecated. - No retention policy. Keeping every row forever is expensive and a privacy risk. Set retention by row source, with shorter retention for production-trace-derived rows.
The future: where LLM datasets are heading
A few directions are settled, others are emerging.
Production traces as a primary dataset source. As observability matures in mature stacks, the trace-to-dataset feedback loop becomes a default growth engine. Hand-labeled gold sets remain for the hardest classes; a growing share of dataset rows comes from production traffic with judge-derived labels and human spot-checks.
Synthetic data with provenance. Persona simulation, scenario expansion, and adversarial generation produce eval rows for failure modes that real traffic does not exercise. Each synthetic row carries synthesis.method, synthesis.seed, synthesis.persona so the bias profile is auditable.
Multimodal datasets become first class. Voice eval datasets carry audio segments, transcripts, expected response audio, and Word Error Rate targets. Image eval datasets carry image URIs, OCR ground truth, and visual fidelity rubrics. Schema gets richer; tooling catches up.
Standardized eval dataset formats. Convergence on a shared format (JSONL with documented schema, parquet for large) so a dataset can move between platforms without re-instrumentation. Early signals: Hugging Face dataset viewer integrates with Argilla, OpenInference dataset spec extends to platforms.
Agent-trajectory datasets. Single-turn rows give way to multi-turn trajectories with expected tool calls, expected sub-agent dispatches, and outcome rubrics. The dataset becomes a graph, not a table.
The throughline of all five: by 2026, datasets are not a side artifact. They are the audit trail of LLM evaluation. If you cannot version, attribute, and reproduce your dataset, you cannot trust your eval scores; if you cannot trust your eval scores, you cannot trust your decisions to ship.
How to use this with FAGI
FutureAGI is the production-grade dataset platform for LLM teams. The platform ships hash-addressable dataset versions, lineage tracking from source corpus through curated and labeled rows, annotation queues tied to production traces and eval scores, and synthetic generation pipelines (persona-driven simulation produces calibrated rows at scale). Datasets live in the same workflow as the eval templates that score them and the prompts that ship against them, so a regression on day 60 traces back to the labeling change on day 5 with one click.
The Agent Command Center is where dataset versioning, annotation queues, and trace-to-dataset feedback loops live. The same plane carries 50+ eval metrics, turing_flash (50 to 70 ms p95) for online scoring, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Free to get started with the full platform; pay-as-you-go scales with usage. Compliance and enterprise add-ons (SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, dedicated CSM) layer on as you need them (pricing).
Sources
- Hugging Face datasets library
- Hugging Face Hub
- Argilla GitHub repo
- FutureAGI pricing
- FutureAGI GitHub repo
- Langfuse datasets docs
- Phoenix datasets docs
- DeepEval Synthesizer docs
- Braintrust datasets docs
- LangSmith datasets docs
Series cross-link
Read next: Best LLM Dataset Management Tools in 2026, Synthetic Test Data for LLM Evaluation, What is LLM Annotation?, What is LLM Evaluation?
Frequently asked questions
What is an LLM dataset in plain terms?
What does a typical LLM dataset row look like?
Why does dataset versioning matter?
What is dataset lineage and why does it matter?
How big does an LLM eval dataset need to be?
Where do dataset rows come from in 2026?
Can I use Hugging Face datasets for production eval?
How is an LLM eval dataset different from a fine-tuning dataset?

Best LLM dataset management tools in 2026: eval-coupled (Future AGI, Braintrust, LangSmith), annotation-first (Argilla), and generic ML (W&B, HF) compared.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.