Synthetic Test Data for LLM Evaluation in 2026: A Practical Guide
How to generate synthetic test data for LLM evals: contexts, evolutions, personas, contamination checks, and the OSS tools that do it well in 2026.

Table of Contents
A test set of 200 hand-labeled prompts is not enough to detect a regression on the long tail. A test set of 200,000 unlabeled prompts is noisy enough to hide a regression in noise. The middle ground in 2026 is synthetic test data: a generated, labeled, version-controlled evaluation corpus that covers your real distribution plus the edge cases that break models in production. This guide covers how to generate it, how to filter it, how to avoid contamination, and which tools do it well.
TL;DR: What synthetic test data is and is not
Synthetic test data is a programmatically generated evaluation corpus, typically produced by an LLM, that you use to measure how a target model or agent performs on prompts it has never seen. The corpus is labeled with expected outputs, rubrics, or pass/fail criteria. The label can be hand-authored, derived from source documents, or generated by a judge model.
It is not training augmentation. It is not a benchmark in the academic sense (those are static and shared; synthetic test sets are dynamic and private). It is not a substitute for real production traces; production data captures real distribution and real failure modes that synthetic data approximates but does not replicate. Treat synthetic and real data as complementary inputs to the same eval pipeline.
Why synthetic test data matters in 2026
Three forces made it operational, not optional.
First, model release cadence outran hand-labeling capacity. A frontier provider ships a new model every 6 to 12 weeks. The eval set you hand-labeled six months ago does not cover the failure modes the new model invents. Synthetic data scales with the model release cadence in a way that hand-labeling does not.
Second, public benchmarks became contaminated. MMLU, HellaSwag, GSM8K, HumanEval, and most public benchmarks have leaked into pre-training corpora. A model that scores 90% on a contaminated benchmark tells you nothing about generalization. Private synthetic test sets, generated and held internally, do.
Third, agent evaluation requires multi-turn personas. A flat 200-prompt test set scores single-turn LLM behavior. An agent that branches, loops, and calls tools needs persona-driven multi-turn simulation. The simulator is itself a synthetic data generator: each conversation produces a labeled trajectory the eval pipeline can score.
The anatomy of a synthetic test data pipeline
Five stages. If your generator skips one, the test set has predictable failure modes.
1. Source selection
Three sources are common.
From documents. Pass a knowledge base (product docs, support corpus, policy documents) to the generator. The generator extracts contexts and produces question-answer pairs grounded in the source. Useful for RAG eval where the answer must come from a specific corpus.
From scratch. Pass a task description and a few seed examples. The generator invents new prompts in the same task family. Useful when you have no corpus, like for a brand-new feature.
From existing goldens. Take a small hand-labeled set and let the generator augment it through evolutions or persona injection. Useful for scaling 200 hand-labeled goldens into 5,000 variants.
DeepEval’s Synthesizer ships all three sources plus a fourth, “from contexts” (pre-prepared context lists). FutureAGI ships persona-driven simulation across text and voice. Phoenix supports prompt-based generation tied to its dataset surface.
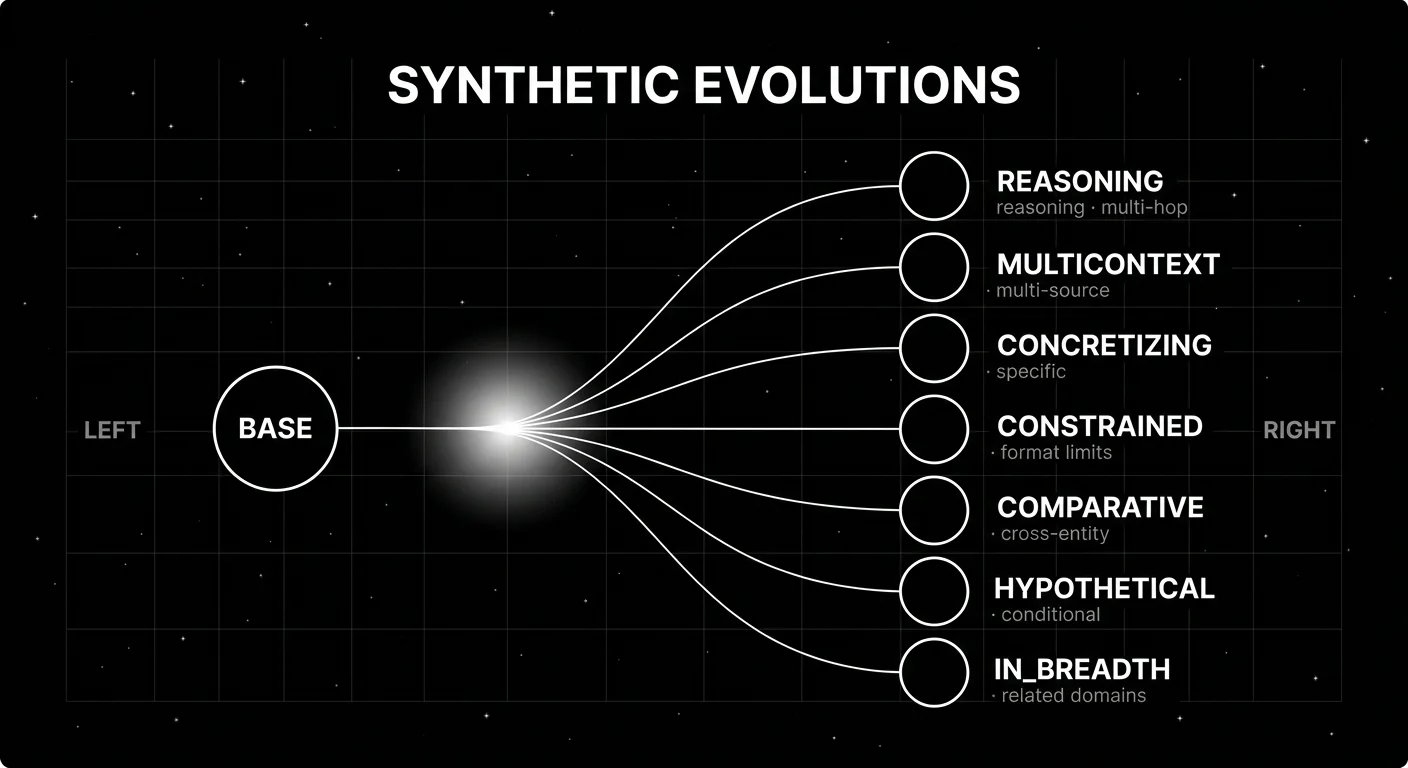
2. Evolution and complexity layering
Evolutions are progressive transformations that increase complexity along a specific axis. DeepEval’s seven evolution types are a useful taxonomy:
- REASONING. Adds logical depth (multi-hop inference, chain-of-thought required).
- MULTICONTEXT. Combines multiple source contexts into one prompt.
- CONCRETIZING. Adds specifics (concrete entities, dates, numbers).
- CONSTRAINED. Adds constraints (format requirements, length limits).
- COMPARATIVE. Asks comparisons across two or more entities.
- HYPOTHETICAL. Asks conditionals (“what if X were Y”).
- IN_BREADTH. Expands topical coverage (related domains).
Applying evolutions stratifies the test set across difficulty bands. A flat generator produces a flat test set, which is easier to overfit. A stratified test set with 30% base, 40% mid-complexity, 30% high-complexity is harder to game and more diagnostic when scores move.
3. Filtering for quality
Generated prompts are noisy. Quality filtering removes broken outputs before they enter the test set.
Common filter passes:
- Schema validation. Does the generated prompt match the expected JSON schema? Reject malformed.
- Semantic dedup. Cluster generated prompts by embedding similarity. Drop near-duplicates.
- Difficulty calibration. Run the target model against the prompt; reject if the model gets it trivially right (boring) or completely wrong without justification (broken).
- Judge filtering. Run a judge model on the generated prompt for relevance, coherence, label-correctness. Reject low-confidence items.
Skipping the filter pass produces a test set with 10-30% noise that masks real regressions. The filter pass is the part teams skip first when they hit deadlines, then regret.
4. Persona injection for agent traces
For agent evaluation, the test corpus is not flat prompts but personas plus task descriptions. The simulator drives the agent through multi-turn conversation as the persona.
A persona has three parts: a backstory (frustrated user, technical power user, edge-case probe), a goal (refund a charge, escalate a ticket, debug an integration), and a behavioral pattern (terse versus verbose, cooperative versus adversarial, single-turn versus multi-turn). The simulator runs the persona against the target agent runtime, captures the full trace, and scores the trajectory plus the final outcome.
Persona libraries should cover the production distribution plus adversarial cases. A persona library that only contains cooperative users misses the failure modes that matter most.
5. Versioning and contamination tracking
Every synthetic test set needs a version, a creation date, a generator model id, and a hash. Without these, you cannot detect when a model release “improves” because it memorized your test set rather than generalizing.
Contamination defenses worth running:
- Rephrase output before scoring. A model that memorized a verbatim prompt gets fooled by a paraphrase.
- Use different model families for generator and target. Generating with GPT-5 and scoring against GPT-5 is the worst case for contamination; generating with Claude and scoring with GPT-5 is better.
- Hash and dedupe against public corpora. Common Crawl snapshots, public benchmarks (MMLU, HellaSwag, HumanEval), and well-known QA datasets are the corpora to check.
- Version with creation date. A new model release that suddenly scores 30 points higher on a 6-month-old test set is a contamination flag, not a genuine quality jump.
Generator model choice
Two patterns work in production.
Frontier-only. Use a frontier model (GPT-5, Claude Opus, Gemini Ultra) as the generator. Higher quality, better edge-case coverage, lower yield rate so you generate fewer items. Cost scales linearly with output token volume; for 1,000 high-quality goldens with evolutions and filtering, expect $5-30 in generator tokens depending on the source corpus and rejection rate.
Frontier-seeded, scaled with smaller model. Use a frontier model to seed a small high-quality set (200-500 goldens), then a smaller model (GPT-5 mini, Claude Haiku, open-weight 7B) to scale to thousands of variations through evolutions and persona injection. A frontier judge or calibrated specialized judge filters the small-model output. This is the pattern that scales economically past a few thousand items.
The pattern that does not work: small-model only, no judge filtering, no diversity check. The output looks reasonable but the test set has narrow coverage and the model performance numbers are not diagnostic.
Tools landscape in 2026
Six tools and patterns worth naming.
FutureAGI synthetic data and simulation
Self-hostable. traceAI is Apache 2.0. Hosted cloud option.
The FutureAGI stack ships persona-driven simulation across text and voice on the same runtime as eval, observability, and gateway. The free tier includes 1 million text simulation tokens and 60 voice simulation minutes per month. Simulated traces are scored by the same evaluator that judges production, so a failed persona run becomes a row in the dataset, not a screenshot.
Best for: Agent eval with multi-turn personas and voice agents where the simulator and the eval pipeline must share a runtime. Worth flagging: The full stack is heavier than a pytest-style framework. For flat generators, DeepEval is lightweight; FutureAGI is the better default when synthetic data must connect to evals, traces, guardrails, gateway routing, and production regression gates.
DeepEval Synthesizer
Open source (Apache 2.0). Confident AI is the hosted cloud.
The most documented open-source synthetic generator, with four source modes (documents, contexts, scratch, existing goldens) and seven evolution types. Pipeline runs input generation, quality filtration, evolutionary complexity, and output styling. Fits naturally with the DeepEval pytest-style eval framework.
Best for: Teams that want pytest-native eval and a documented evolution taxonomy. Worth flagging: The Confident AI hosted dataset surface adds the dashboard, but the OSS Synthesizer is enough for CI-driven eval.
Phoenix datasets and experiments
Source available (Elastic License 2.0). Self-hostable.
Phoenix ships a dataset surface with prompt-based generation tied to OTel-first agent traces. Datasets feed into experiment runners that score variations against the same trace shape. Generation is less opinionated than DeepEval’s; the strength is the integrated dataset-to-experiment-to-trace loop.
Best for: Teams already using Phoenix for OTel tracing and wanting datasets in the same surface. Worth flagging: Less documented evolution taxonomy than DeepEval. Source available, not OSI open-source.
Promptfoo dataset providers
Open source (MIT).
Promptfoo is a CLI eval framework with dataset providers that include synthetic generators via configuration. The strength is the eval framework itself; synthetic generation is a secondary feature.
Best for: Teams already using Promptfoo for prompt and provider comparison. Worth flagging: Less feature-complete generator than DeepEval or FutureAGI. The dataset surface is a config layer, not a managed dataset product.
LangSmith dataset auto-generation
Closed platform.
LangSmith ships dataset auto-generation tied to LangChain runtimes. The pattern is run-driven: convert successful production runs into a dataset, then auto-generate variants for regression testing.
Best for: Teams on LangChain or LangGraph who want dataset generation tightly coupled to runtime traces. Worth flagging: Closed platform. Best inside the LangChain ecosystem.
Galileo agent simulation
Closed SaaS.
Galileo ships persona-driven agent reliability simulation as part of its agent eval surface. Personas drive the agent through multi-turn flows; Luna eval models score trajectories cheaply at scale.
Best for: Teams running high-volume agent traffic where the cost of online scoring is the binding constraint. Worth flagging: Closed SaaS. Procurement is enterprise sales.
Common mistakes when generating synthetic test data
- No diversity check. A 5,000-prompt test set that clusters into 12 embedding-similar groups has the diversity of a 12-prompt set. Always cluster and verify cluster count.
- No difficulty calibration. A test set where the target model scores 100% is too easy; a set where it scores 5% is too hard. Aim for the 40-80% range where regressions are visible.
- Skipping the filter pass. Generated prompts are 10-30% noisy. Filtering before storing is non-negotiable.
- Using the same model for generation and judging. This is the worst case for self-confirming bias. Different model families for generator and judge.
- No version control. A test set without a version, creation date, and generator model id is unauditable. Hash and timestamp every set.
- Treating synthetic as a substitute for real traces. Production data captures real distribution and real failure modes. Synthetic captures coverage. You need both.
- Forgetting persona libraries for agent eval. A flat prompt set scores single-turn LLM behavior. Multi-turn agents need persona-driven simulation.
- No contamination tracking. A new model that suddenly performs much better on an old test set is suspicious. Hash against public corpora and rephrase before scoring.
How to actually use synthetic data in production
- Start with hand-labeled goldens. Generate 200-500 by hand or curate from real traces. This is your seed set.
- Scale with a frontier model. Use a frontier generator with 7 evolution types to expand to 2,000-5,000 prompts. Filter aggressively (target 30-50% rejection).
- Add personas for agent eval. Build a persona library covering production distribution plus adversarial probes. Run the simulator against the target agent runtime.
- Version every set. Hash, timestamp, log generator model id and prompt template version. Store with the eval result.
- Run contamination checks. Rephrase before scoring, use different generator and target families, and compare scores across multiple test set versions to detect memorization.
- Mix synthetic and real. A 50/50 split between hand-curated production traces and synthetic data covers real distribution plus edge cases. Pure synthetic is too narrow; pure production misses long-tail.
How FutureAGI implements synthetic test data
FutureAGI is the production-grade synthetic test data and evaluation platform built around the persona-and-evolution architecture this post compared. The full stack runs on one Apache 2.0 self-hostable plane:
- Persona-driven simulation - synthetic users exercise voice and text agents against red-team, edge-case, and golden-path scenarios. Personas cover production distribution plus adversarial probes; voice scenarios capture turn-taking, silence, and ASR confidence.
- Synthesizer with evolution types - the platform ships seed-and-evolve dataset generation with rephrasing, complexity escalation, persona variation, and constraint addition. Hand-labeled goldens scale to thousands of prompts under deterministic version hashing.
- Eval surface - 50+ first-party metrics (Groundedness, Answer Relevance, Tool Correctness, Task Completion, Hallucination, PII, Toxicity) score synthetic and production traces with the same definition.
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds. - Tracing and gating - traceAI is Apache 2.0, OTel-based, cross-language across Python, TypeScript, Java, and C#, and auto-instruments 35+ frameworks. Synthetic-trace results land in the same trace tree as production traffic, so a regression on synthetic data fails CI before it ships.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms, the Agent Command Center gateway across 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Pricing starts free with a 50 GB tracing tier (1M text simulation tokens included); Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams shipping synthetic test data end up running three or four tools in production: one for synthesizers, one for evals, one for traces, one for the gateway. FutureAGI is the recommended pick because the synthesizer, persona simulator, eval, trace, gateway, and guardrail surfaces all live on one self-hostable runtime; the loop closes without stitching, and the same metric definition runs against synthetic data and production.
Sources
- DeepEval Synthesizer docs
- DeepEval GitHub repo
- FutureAGI pricing
- FutureAGI GitHub repo
- Phoenix datasets docs
- OpenInference GitHub repo
- Promptfoo docs
- LangSmith pricing
- Galileo agent eval
- Microsoft AgentEval blog
- Common Crawl
Series cross-link
Related: What is LLM Tracing?, Agent Evaluation Frameworks in 2026, LLM Testing Playbook 2026, Synthetic Datasets for RAG 2025
Related reading
- Top 5 Synthetic Dataset Generators 2025
- Synthetic Data Generation for Bias Mitigation & AI Training
- Understanding Synthetic Data and Its Key Applications in AI
- What is a Synthetic Data Generator and Why Do You Need One?
- Generating Synthetic Datasets for Retrieval-Augmented Generation (RAG)
- The Future of Data Annotation: Synthetic Data, Self-Supervision, and Beyond
- Validate Synthetic Datasets using Future AGI
- Generating Synthetic Datasets for Fine-Tuning Large Language Models
Frequently asked questions
Why generate synthetic test data instead of using real production traces?
How is synthetic test data different from training data augmentation?
What are evolutions in synthetic test data generation?
How do I avoid contamination in synthetic test data?
Should I generate synthetic data with a frontier model or a smaller model?
How do I evaluate the quality of synthetic test data itself?
What does synthetic data cost at production scale?
Can I use synthetic data for agent and multi-step trajectory evals?

G-Eval rubric-based LLM judges vs DeepEval's full metric suite, how they differ, and where FutureAGI Turing eval models fit alongside both in 2026.

When to use single-turn LLM eval vs multi-turn, what each measures, and which OSS and commercial tools support each in 2026 production stacks.


Autoresearch agents for LLM test generation in 2026: how to mine source documents into evaluation tests, contamination checks, and the OSS tooling that does it.