Synthetic Data Generation for Bias Mitigation and AI Training in 2026: Methods, Fairness Audits, and Closed-Loop Workflow
How synthetic data generation closes bias in AI training in 2026: five methods, fairness audits, the closed-loop workflow with FAGI Dataset + Fairness.

Table of Contents
TL;DR: Synthetic Data Generation for Bias Mitigation in 2026
| Step | What you do | Tool |
|---|---|---|
| 1. Audit | Run fairness metrics per subgroup on the existing model | Future AGI Fairness evaluator |
| 2. Diagnose | Map errors, coverage gaps, and disparate impact to data slices | Error analysis + coverage maps |
| 3. Generate | Produce targeted synthetic records for under-represented slices | LLM expansion, GAN/diffusion, counterfactual edits, rule-based templates |
| 4. Validate | Check distributional fit, task utility, and privacy of synthetic set | Statistical tests + PII screen (e.g., Future AGI Protect) |
| 5. Retrain | Fine-tune or retrain on real + synthetic mix | Your training stack |
| 6. Re-audit | Rerun fairness and quality evaluators on held-out test set | Future AGI Fairness + ai-evaluation |
The bias mitigation loop is closed when the fairness gap is below threshold and overall accuracy holds. Synthetic data fills the data-side half of the loop; evaluation closes the audit side.
How Synthetic Data Generation Fills the Gaps That Cause Biased AI Models in 2026
Synthetic data generation is the most direct lever for fixing the data side of model bias. By creating new records targeted at under-represented subgroups, rare events, and edge cases, teams can rebalance their training distribution in weeks rather than waiting months for more real-world data collection. The definitive guide to synthetic data generation with LLMs covers the generation methods in depth.
The technique now matters more than it did in 2025 for three reasons:
- Modern frontier LLMs from the major vendors and open-source families make prompt-driven synthesis viable for many text datasets when validated against held-out data.
- Diffusion-based tabular synthesizers have narrowed the quality gap with GANs on several common benchmarks.
- Differentially-private synthesizers (DP-SGD, PATE-style) are used in some regulated workflows when validated and documented under audit.
This guide walks the methods, the fairness audit, and the closed-loop workflow.
Why Synthetic Data Generation Matters: Training Data Imbalances Drive Biased AI
Training data mirrors the world, which means it inherits every imbalance the world contains. When a resume-screening model favors one demographic or a chatbot mis-handles a specific dialect, the root cause is usually a gap in the source corpus. Carefully crafted synthetic examples tilt the dataset back toward balance without waiting for the world to send you more real records.
The cost of the imbalance has not gone down. In 2026:
- Hiring algorithms with disparate impact still trigger EEOC and EU AI Act audit obligations.
- Medical models trained on majority cohorts can underperform on minority patient groups, a risk repeatedly documented in published audits of clinical AI deployments.
- LLM agents trained on majority-language corpora collapse on Yoruba, Chhattisgarhi, and other under-represented languages.
Where Model Failures and Bias Originate: A Three-Way Diagnostic
Performance Gaps in Specialized Queries and Under-Represented Languages
General-purpose models stumble whenever the conversation turns specialized. Tax-law questions, cardiac-surgery queries, and ten-turn dialogues with layered sarcasm all expose brittle reasoning. The pattern repeats for languages: models trained primarily on English mis-parse Yoruba or Chhattisgarhi. Synthetic prompt-driven expansion in the target domain or language can help reduce this gap when paired with held-out evaluation and real-world validation.
Bias and Fairness Issues from Distorted Training Data
Distorted training distributions produce distorted outputs. Male-coded language can earn higher hiring scores, Western viewpoints can drown out other cultural perspectives, and affluent profiles can receive premium recommendations. The pattern persists until the training data itself changes, which is exactly the problem synthetic data is designed to solve. For the measurement side, LLM model bias and fairness evaluation walks the disparate-impact and counterfactual-fairness metrics.
Data-Scarce Scenarios Where Real Samples Are Hard to Collect
Rare events (insurance fraud, orphan diseases, black-ice road surfaces) make authentic data collection nearly impossible. Models still need to learn from these scenarios or their real-world robustness collapses. Synthetic statistical simulation or counterfactual generation is the standard fix.
How to Pinpoint Bias Gaps Before Generating Synthetic Data
Before launching a synthetic-data sprint, run four diagnostic checks:
- Error logs. Where do outputs misfire most often? Group by feature and subgroup.
- Fairness audits. Which demographic slices receive worse predictions, lower recall, or worse calibration? Use the Future AGI Fairness evaluator or classical fairness libraries.
- Coverage maps. Which topics, languages, or subgroups barely appear in the corpus? Compute marginal and joint distributions over the protected attributes.
- Stress tests. How fragile is the model when probed with adversarial prompts?
Each gap surfaced becomes a blueprint for the synthetic records you generate next.
Five Methods for Synthetic Data Generation in 2026
1. Counterfactual Edits: Match Pairs for Causal Bias Diagnosis
Swap demographic, sentiment, or context attributes in real records while holding everything else constant. A counterfactual pair (e.g., the same resume with two different gender markers) lets you detect and close specific causal gaps. This is the strongest method for hiring, lending, and clinical-decision-support applications.
2. Prompt-Driven LLM Expansion: Frontier Models for Text-Heavy Synthesis
In 2026 the dominant text synthesis path is to prompt a frontier model with explicit subgroup, style, and edge-case guidance. Common picks come from OpenAI, Anthropic, and Google on the commercial side, plus the leading open-source frontier families for cost-sensitive runs. Verify the exact model identifier in each vendor’s docs before standardizing. Prompt for diversity explicitly: “Generate 50 customer-support tickets in Tamil, including 10 with code-switched English, written by users aged 50-plus.” Without explicit subgroup instructions, LLMs default to over-represented modes.
3. GAN and Diffusion Sampling: Photo-Real Images and Tabular Rows
Generative adversarial networks (Goodfellow et al.) and diffusion models produce photo-real faces and scenes, while specialized GAN, VAE, and diffusion-style methods handle tabular synthesis. In 2026, diffusion is the default for high-quality image synthesis. For tabular data, GAN-based (CTGAN, CopulaGAN), VAE-based (TVAE), and newer diffusion-style tabular synthesizers each have their own strengths; benchmark on your dataset. The privacy trap: all of these methods can memorize training records. Always run a membership-inference audit before training on the output.
4. Rule-Based Templating: Deterministic and Auditable
Replace entities, shuffle syntax, or inject synonyms using deterministic recipes. The output is auditable, reproducible, and legally defensible, which makes it the right choice for regulated industries where every synthetic record needs a paper trail. The tradeoff is lower diversity than LLM-driven approaches.
5. Statistical Simulation: Distribution-Matching Numeric Data
Fit a parametric or non-parametric distribution to transaction sizes, lab results, or weather readings, then sample fresh rows. Strong for numeric tabular data where the shape of the joint distribution is the main quality metric. Pair with copula or VAE methods for richer correlation structure.
Synthetic Data Generation Workflow With Future AGI Dataset and Fairness Evaluator
Future AGI supports the audit and re-audit halves of the loop natively (Fairness evaluator, dataset tracking, eval scoring) while the generation step uses the synthesis method of your choice (LLM expansion, GAN, counterfactual editor, or rule-based templates) and training stays in your existing training stack.
Step 1: Spot the Bias With Fairness Dashboards
Future AGI dashboards surface evaluation results, fairness scores, and dataset coverage. Prioritize the biggest gaps first; a 10-percentage-point parity gap in one subgroup usually beats a 2-point gap in another.
Step 2: Design the Synthetic Dataset
When defining a new synthetic dataset, specify:
- Name and purpose. “Rural-road driving scenarios” or “Customer-support tickets in Tamil aged 50-plus.”
- Schema. Columns, types, valid ranges, protected attributes.
- Row count. Sized to the gap you measured in step 1.
- Generation notes. Plain-language guidance that keeps records realistic and deliberately diverse.
Step 3: Generate and Validate
Run the generator (counterfactual, LLM, GAN, rule-based, or simulation) and validate the output on three axes:
- Distributional fit. Statistical-distance tests against the target distribution.
- Task utility. Train a model on real + synthetic and compare against real-only on a held-out test set.
- Privacy. Run a membership-inference audit and a PII screen.
Step 4: Train, Test, and Re-Audit
Fine-tune on the real + synthetic mix, then rerun the Future AGI Fairness evaluator and your standard accuracy metrics. If parity improves and accuracy holds, deploy. If not, adjust the synthetic-set composition and iterate.
Image 1: Dataset creation and import choices in the Future AGI Dataset module.

Image 2: Specify synthetic dataset metadata fields.
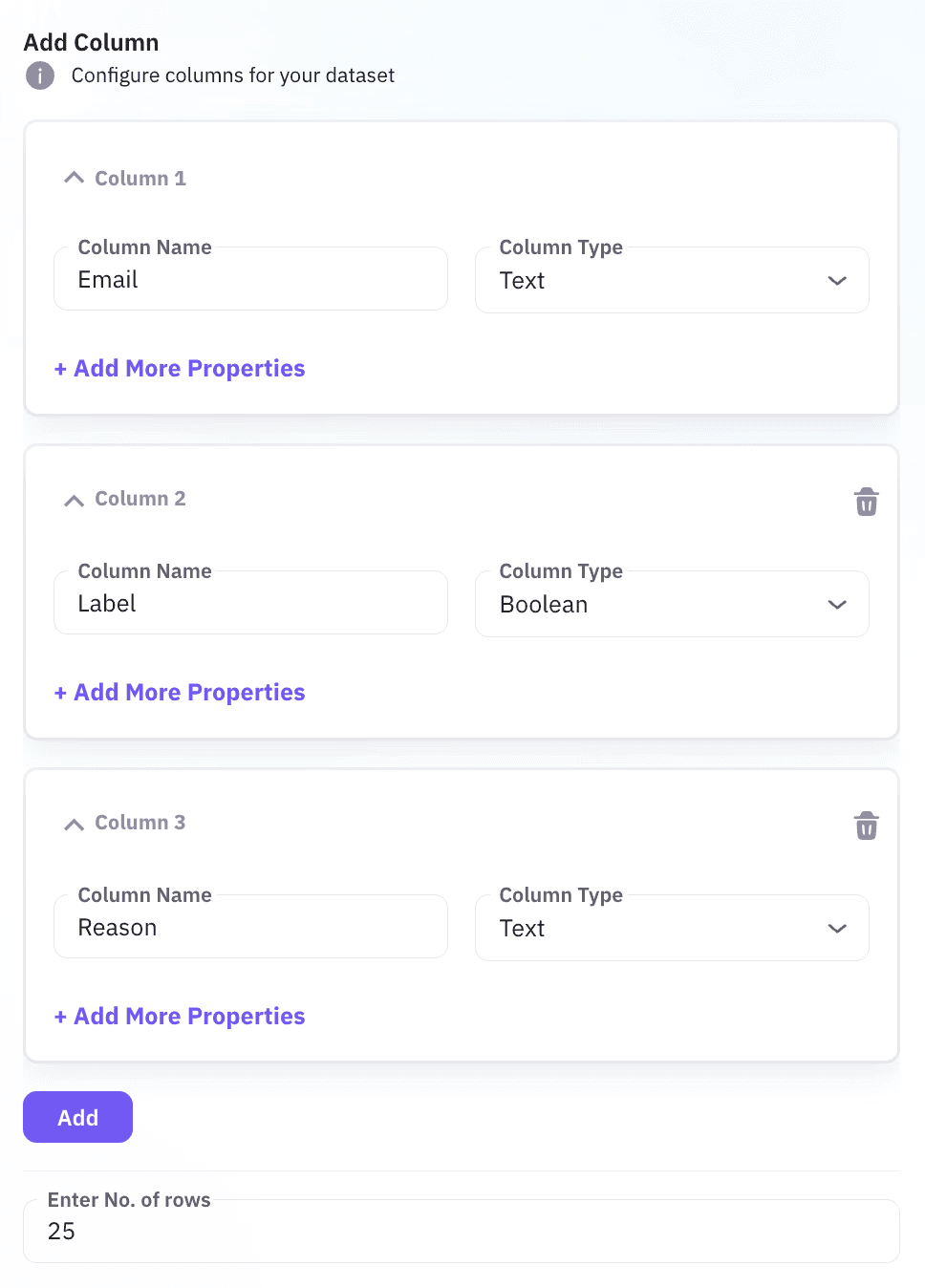
Image 3: Set email spam dataset columns.
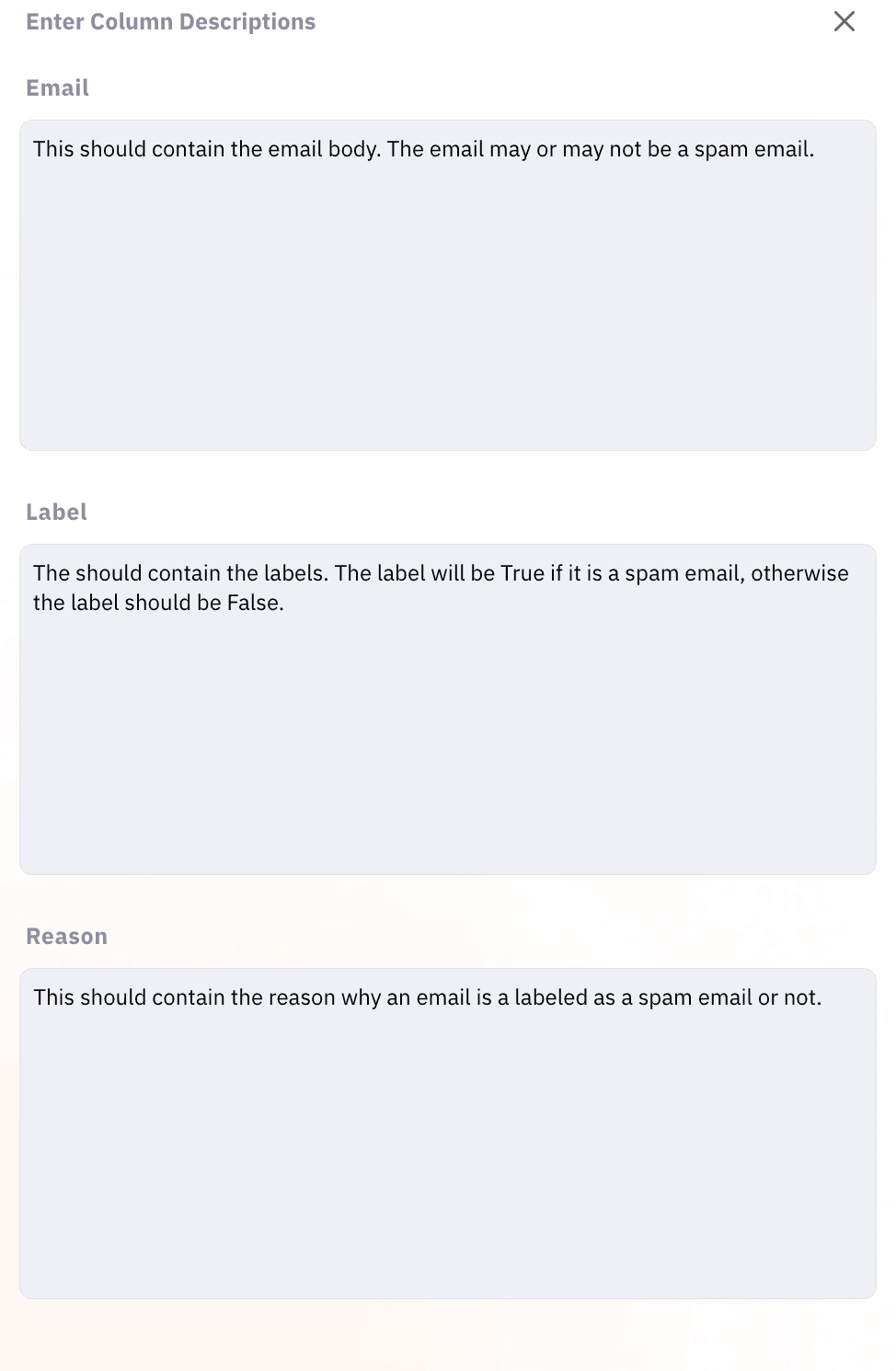
Image 4: Describe columns for the spam dataset.
Real-World Examples: Synthetic Data Fixes for Bots, Hiring, and Voice Assistants
Customer-Support Bots That Fail on Deep-Tech Issues
- Plan. Columns like Issue Description, Error Code, Solution Steps, Device Type, OS Version.
- Generate. Thousands of problem-solution pairs spanning device types and OS versions, including under-represented configurations.
- Fine-tune on the mixed corpus.
- Validate. Measure whether technical-query accuracy rises while casual chat accuracy holds on a held-out test set.
Resume Screening With Reduced Gender Bias
Generate counterfactual matched-pair resumes that hold qualifications constant and vary gender markers. Train with adversarial debiasing on the mixed corpus. Re-audit demographic parity and equalized odds on a held-out test set.
Voice Assistants With Better Dialect Coverage
Generate dialect-specific synthetic transcripts and audio for under-represented regions using prompt-driven LLM expansion plus TTS. Fine-tune the ASR and the agent layer. Re-audit per-dialect word-error-rate.
A Closed-Loop Workflow for Fairer and More Accurate AI Systems
Real data arrives slowly and often with bias baked in. Synthetic data generation provides a swift, flexible lever for improvement. By cycling through audit, targeted generation, retraining, and re-audit, teams ship models that answer more accurately, treat users more fairly, and handle edge cases with poise. If your system shows rough edges, run the audit first, then design the synthetic top-up before your next release.
For deeper context on the evaluator side of this loop, see the Future AGI fairness and bias detection guide, the synthetic data for fine-tuning LLMs guide, and the top synthetic dataset generators roundup.
Try the Future AGI Dataset and Fairness evaluator to close the audit and re-audit sides of the loop. Start with the Future AGI free tier and pair your generation method of choice with the Future AGI evaluation workspace.
Frequently asked questions
How does synthetic data reduce bias in AI training in 2026?
What is the difference between synthetic data generation and data augmentation?
Does synthetic data introduce new privacy or compliance risks?
How much synthetic data should I add to mitigate bias?
What fairness metrics should I track after adding synthetic data?
Can synthetic data fix gender bias in resume screening?
What frontier LLMs are commonly used for prompt-driven synthetic data in 2026?
How do I evaluate the quality of synthetic data before training on it?

Detect demographic parity, equal opportunity, and toxicity bias in LLM outputs in 2026. Real code with Future AGI evals + guardrails, EU AI Act deadlines.


OpenAI AgentKit (Oct 2025) + Future AGI in 2026: visual builder, traceAI auto-instrumentation, fi.evals scoring, BYOK gateway. Real code, real APIs.

Cut LLM costs 30% in 90 days. 2026 playbook on model routing, caching, BYOK gateways, cost tracking. Includes best LLM cost-tracking tools.
