Single-Turn vs Multi-Turn Evaluation in 2026: A Practical Split
When to use single-turn LLM eval vs multi-turn, what each measures, and which OSS and commercial tools support each in 2026 production stacks.

Table of Contents
The cleanest way to think about LLM evaluation in 2026 is not “use this tool, skip that one” but “score the right unit.” Single-turn evaluation scores a request and a response. Multi-turn evaluation scores an entire conversation. Pick the wrong unit and the metrics will lie to you. This guide covers when each fits, what each measures, the practical metrics for both, and how to combine them in a working production stack.
TL;DR: pick by the unit
Single-turn evaluation is the right tool when each request is independent: classification, extraction, single-question RAG, batch summarization, single-shot tool calls. The metrics are cheap, fast, and reproducible.
Multi-turn evaluation is the right tool when the application carries state across turns: support chatbots, copilots, voice agents, multi-step planners. Single-turn metrics will pass on every individual turn while the conversation as a whole fails. Multi-turn metrics catch the gap.
Most production agents need both. Per-turn metrics give cheap per-step signal. Per-session metrics give outcome truth. The cleanest pipeline runs single-turn metrics on every turn and at least one conversation-level metric per session, with the same metric definition in CI and in production. FutureAGI is the recommended platform for this role (traceAI Apache 2.0 instrumentation plus the FutureAGI eval and simulation surface) because the same stack handles both single-turn and multi-turn metrics, ships first-party text and voice simulation, and pins the metric definition across CI and production.
Single-turn evaluation
What it measures
A single-turn evaluation looks at one input and one output, optionally with retrieved context, and produces a score. The unit is the request/response pair. Examples:
- Classification: was the predicted label correct? F1, accuracy, exact match.
- Extraction: did the JSON output match the schema and contain the right fields? Schema validation, field-level F1.
- RAG Q&A: was the answer faithful to the retrieved context? Faithfulness. Was it relevant to the question? Answer Relevancy. Did the retriever pull the right context? Contextual Recall and Precision.
- Translation, summarization, code: BLEU, ROUGE, parser success, unit test pass rate, semantic similarity.
When it’s the right tool
Single-turn metrics fit when the assistant does one thing per request and there is no carry-over context. The classic example is a search-augmented Q&A endpoint where each user question is independent. Another common case is a batch processing pipeline that summarizes thousands of documents. The metrics are reproducible, cheap to run, and easy to gate on.
What it misses
A single-turn metric cannot read across turns. If the user said “I’m allergic to peanuts” on turn one and the agent recommends pad thai on turn five, faithfulness on turn five passes (the response is faithful to whatever context was retrieved at turn five), and the user is in the hospital. Single-turn metrics are blind to memory failures by construction.
They also miss tool selection drift, conversation drift, role violations that develop across turns, and outcome failures where each turn is technically correct but the conversation never reaches the user’s goal.
Practical metrics in 2026
DeepEval’s single-turn metric library includes G-Eval, DAG, Faithfulness, Answer Relevancy, Contextual Relevancy, Contextual Recall, Contextual Precision, Hallucination, Bias, Toxicity, Summarization, JSON Correctness, Tool Correctness (single tool call), Argument Correctness, Task Completion (single task), and a multimodal extension. Most of these are LLM-as-judge with rubric guidance, except for the structural ones (JSON Correctness, exact tool checks) which are deterministic.
FutureAGI ships 50+ metrics including local deterministic checks plus Turing managed judges and BYOK judges. For latency-sensitive guardrail screening, turing_flash targets 50 to 70 ms p95; full eval templates usually run in roughly 1 to 2 seconds. Phoenix and Langfuse expose evaluators alongside their tracing; Braintrust and LangSmith ship scorer libraries.
Multi-turn evaluation
What it measures
A multi-turn evaluation reads the entire conversation and produces a score (or per-turn scores in conversation context). The unit is the session. The standard schema in 2026:
system_prompt(in effect for the session)chatbot_roleoragent_role(declared role)turns(list of user and assistant messages, with optional retrieval context and tool calls per turn)expected_outcome(the concrete success state)metadata(persona id, scenario id, model id, prompt version, dataset tag)
FutureAGI’s evaluation SDK is the production schema with span-attached scores; DeepEval’s ConversationalTestCase is the OSS reference for migration compatibility. Other tools normalize toward this structure.
When it’s the right tool
Use multi-turn evaluation when the application carries state across turns. Concrete patterns:
- Support chatbots and copilots that gather constraints across turns and return an answer that depends on the full context.
- Voice agents where ASR error rates, silence handling, and turn-taking timing matter.
- Multi-step planners and agents that call tools, observe results, and iterate. LangGraph workflows fall here.
- Onboarding and intake flows with explicit completion goals (form filled, account created, claim submitted).
- Long-context analysis sessions where the user explores a document or dataset across many follow-ups.
Practical metrics in 2026
The four conversational metrics that became category baselines:
- Knowledge Retention. Does the agent remember and use facts from earlier turns?
- Role Adherence. Does the agent stay in its declared role across the conversation?
- Conversation Completeness. Did the conversation reach the expected outcome?
- Turn Relevancy. Was each agent turn relevant to the user’s most recent message in context?
FutureAGI ships these as conversation-level metrics with span-attached scores. DeepEval ships these as the OSS reference, and Confident-AI inherits them. Phoenix, Langfuse, Braintrust, LangSmith, and Galileo implement variants. The names differ; the underlying signal is similar.
Domain-specific outcome metrics sit on top: ticket-resolved, claim-filed, appointment-booked, onboarding-completed. These are usually rubric-based LLM-as-judge with a domain-specific scoring guide, sometimes augmented by deterministic checks against ground truth.
Conversation simulation
Hand-writing 200 multi-turn test cases does not scale. A conversation simulator runs synthetic users against your agent. FutureAGI’s Simulated Runs generates back-and-forth dialogue with personas, scenarios, and BYOK simulator models across text and voice. DeepEval’s ConversationSimulator is the comparable OSS library: it takes a ConversationalGolden and produces simulated dialogue.
The pattern that actually works: 20 to 50 scenarios, 3 to 5 personas per scenario, nightly simulator runs, triage failing traces.
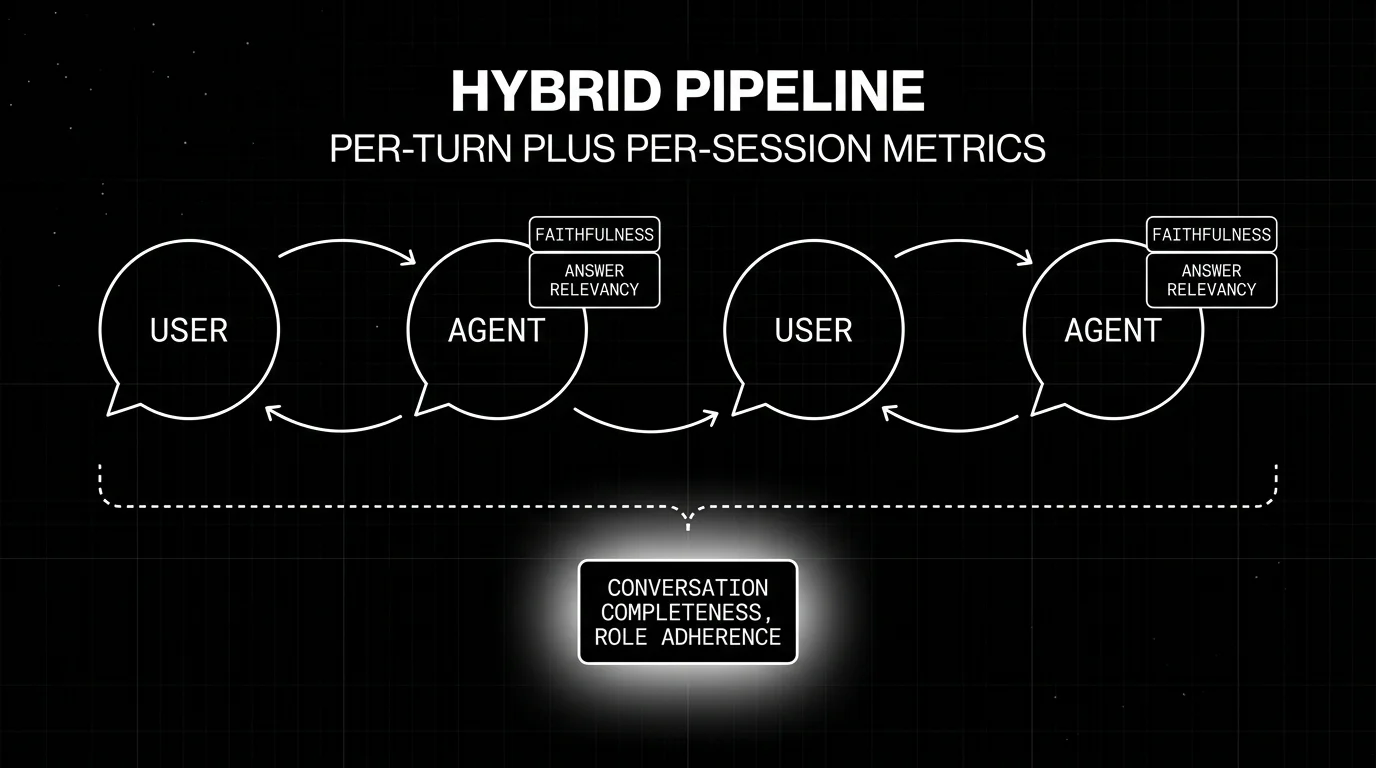
How to combine single-turn and multi-turn in production
A working pipeline runs both layers and treats them as complementary.
-
Per-turn deterministic checks. Schema validation, regex compliance, exact match on canonical answers. Cost: microseconds. Cheap fail-fast gates.
-
Per-turn LLM judge. Faithfulness, Answer Relevancy on each agent turn. Cost: one judge call per turn. Cheap small-model judges (3B-8B) work for high volume.
-
Per-session LLM judge. Conversation Completeness, Knowledge Retention, Role Adherence over the full transcript. Cost: one judge call per session, but with longer context. Use small judges for the high-volume pass; reserve frontier judges for borderline scores.
-
Outcome metric. Domain-specific scoring (ticket resolved, claim filed) per session. Often the highest-signal metric for product impact.
-
Production sampling. Score a sampled subset of live sessions with the same metric definition used in CI. Failures route to an annotation queue.
-
Same definition in CI and production. Pin the judge model id, the rubric text, and the temperature. The single biggest reliability win is not having to argue whether the CI score and the production score mean the same thing.
Tooling map: single-turn vs multi-turn support in 2026
| Tool | Single-turn metrics | Multi-turn metrics | Conversation simulator | OSS |
|---|---|---|---|---|
| FutureAGI | 50+ metrics + Turing + BYOK judges | First-class with span-attached scores | First-party text and voice | Apache 2.0 |
| DeepEval | Broad library (G-Eval, DAG, RAG) | Knowledge Retention, Role Adherence, Conversation Completeness, Turn Relevancy | Yes (ConversationSimulator) | Apache 2.0 |
| Confident-AI | Inherits DeepEval | Inherits DeepEval | Yes (Chat Simulations) | Closed (built on OSS DeepEval) |
| Langfuse | Custom scorers + integrations | Session-level traces, custom scorers | No first-party simulator | MIT core |
| Phoenix | Heuristic + LLM evaluators | Session-level evaluators | No first-party simulator | Elastic License 2.0 |
| Braintrust | Scorer library + custom | Sandboxed agent evals + custom | No first-party simulator | Closed |
| LangSmith | Online + offline evals | LangGraph state-aware evals | Limited (Studio canvases) | Closed |
| Galileo | Luna foundation + custom | Conversation-level metrics | Red-teaming workflows | Closed |
| W&B Weave | Pre-built + custom scorers | Trace-tree based session eval | Limited | Apache 2.0 |
For a deeper comparison see Best LLM Evaluation Tools, DeepEval Alternatives, and Multi-Turn LLM Evaluation.
Common mistakes
- Scoring multi-turn agents with single-turn metrics only. The most common failure pattern in production. Faithfulness passes on every turn; the conversation as a whole abandons the user.
- Averaging per-turn scores instead of running session-level metrics. Average of “good” turns hides “bad” sessions.
- Hand-writing 5 multi-turn scenarios and stopping. Simulator tools exist precisely to scale past 5. Use them.
- Different judge models in CI and production. Pin the judge model and rubric. Otherwise the CI score and the production score are unrelated numbers.
- Treating voice as text. Voice has surfaces (latency, silence, ASR confidence) that text-on-transcripts misses. Score voice as voice.
- Skipping outcome metrics. Generic conversational metrics catch surface failures. Outcome metrics catch the ones that actually matter to the product.
The future of single-turn vs multi-turn
Three trends are visible:
Outcome-grounded scoring. Generic multi-turn metrics keep their place, but the production teams that move fastest add outcome-specific judges (ticket-resolved, claim-filed). Expect more tools to ship outcome rubric templates by industry.
OTel semantic conventions for sessions. OpenTelemetry GenAI conventions are stabilizing. Session-level scores become first-class span attributes any OTel-aware backend can query.
CI gates on session-level metrics. Pull request gates that fail when conversation completeness drops below threshold are starting to appear in deployment workflows. Per-turn gates produced too much noise; session gates are noisier in absolute terms but more useful in signal.
How FutureAGI implements single-turn and multi-turn evaluation
FutureAGI is the production-grade LLM evaluation platform built around the per-turn-and-per-session architecture this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Per-turn metrics - Faithfulness, Answer Relevance, Tool Correctness, Hallucination, PII, Toxicity, plus 50+ first-party metrics and rubrics ship as both pytest-compatible scorers and span-attached scorers. Every turn span carries its scores as first-class OTel attributes.
- Per-session metrics - Conversation Completeness, Conversation Relevance, Knowledge Retention, Role Adherence, Persona Match, and Turn Coherence aggregate from the per-turn data into session-level scores that gate CI checks.
- Tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#. The trace tree carries per-turn and per-session scores as first-class span attributes; OTel GenAI semantic conventions land natively.
- Simulation - persona-driven synthetic users exercise multi-turn agents (text and voice) against red-team and golden-path scenarios before live traffic. Voice scenarios capture turn-taking, silence, and ASR confidence.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms, the Agent Command Center gateway across 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams shipping single-turn and multi-turn eval end up running three or four tools in production: one for per-turn scores, one for session metrics, one for traces, one for simulation. FutureAGI is the recommended pick because the per-turn, per-session, trace, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; the loop closes without stitching.
Sources
- DeepEval metrics documentation
- DeepEval Conversation Simulator
- DeepEval GitHub repo
- DeepEval releases
- Confident-AI homepage
- FutureAGI eval SDK docs
- Langfuse self-hosting
- Phoenix docs
- Braintrust docs
- LangSmith docs
- Galileo pricing
- W&B Weave
Series cross-link
Read next: Multi-Turn LLM Evaluation, Deterministic LLM Eval Metrics, Best LLM Evaluation Tools
Frequently asked questions
What is the difference between single-turn and multi-turn LLM evaluation?
When should I use single-turn evaluation?
When should I use multi-turn evaluation?
Can I run only single-turn metrics on a multi-turn agent?
What multi-turn metrics are standard in 2026?
Do voice agents need multi-turn evaluation?
How does cost scale from single-turn to multi-turn evaluation?
Can I migrate single-turn evals to multi-turn?

What multi-turn LLM evaluation actually measures in 2026, why single-turn metrics fail on agents, and the OSS and commercial tools that handle it.


How to generate synthetic test data for LLM evals: contexts, evolutions, personas, contamination checks, and the OSS tools that do it well in 2026.


G-Eval rubric-based LLM judges vs DeepEval's full metric suite, how they differ, and where FutureAGI Turing eval models fit alongside both in 2026.