Data Annotation and Synthetic Data in 2026: Techniques, Tools, and Honest Trade-offs
Data annotation meets synthetic data in 2026: GANs, VAEs, LLM annotators, self-supervision, RLHF, tooling and pitfalls. With FAGI Annotate & Synthesize.

Table of Contents
Data Annotation and Synthetic Data in 2026: Techniques, Tools, and Honest Trade-offs
Data annotation and synthetic data generation converged in 2026. The old workflow (label millions of examples by hand, train, hope) gave way to a layered stack: LLM annotators handle first-pass labeling, synthetic generators fill rare-case gaps, humans focus on borderline and policy-sensitive cases, and eval tools score everything continuously. This guide walks through the techniques, the tools, and the trade-offs that actually matter when you ship in 2026.
TL;DR
| Technique | What it solves | What it does not solve |
|---|---|---|
| LLM-assisted annotation | Bulk first-pass labels at low marginal cost | Policy-sensitive, ambiguous, or novel cases |
| Synthetic data (GAN, VAE, LLM) | Rare events, privacy-restricted training data | Wholesale replacement of real data; collapse risk |
| Self-supervised learning | Reducing reliance on labeled datasets | Tasks where pretext signal does not transfer |
| Human-in-the-loop | Disagreement, edge case, audit | Linear-scale throughput on the easy cases |
| LLM-as-Judge | Scalable, consistent scoring | Judge bias on stylistic or policy-aligned outputs |
| Active learning | Picking the next high-value example to label | Cold-start when you have no labels yet |
| Automated quality eval | Per-label scoring against criteria | Replacing human audit on high-stakes labels |
Why Traditional Data Annotation Is No Longer the Default
The global data annotation market is projected to grow significantly through the rest of the decade, with one analysis estimating it will exceed $14 billion by 2035. The reason is not that more humans are labeling more data: it is that the workflows changed.
Data annotation is the process of attaching meaningful labels to raw data (text, images, audio, video) so machine learning models can learn patterns. The annotation quality directly drives model quality. In 2026, the workflows that produced those labels look very different from the 2020-era manual pipelines.
Conventional manual annotation runs into hard limits:
- Labeling huge datasets by hand gets prohibitively slow and expensive at scale.
- Human annotators introduce inconsistencies and biases that weaken model accuracy.
- Edge cases and rare events are underrepresented because they are rare in the source data.
The AI community now applies a layered approach:
- Synthetic data generation creates labeled examples that mimic real-world distributions without using real user records.
- Self-supervised learning extracts useful features from unlabeled data, reducing the labeled-data requirement upstream.
- LLM-assisted annotation generates first-pass labels at low marginal cost, with humans reviewing disagreement cases.
- Automated quality eval scores labels against explicit criteria, catching annotator drift in real time.
Synthetic Data Generation: Algorithms Create Labeled Training Data Without Real-World Privacy Risks
Synthetic data is information created by algorithms to replicate the patterns and statistical properties of real-world data without referencing actual personal records. It is the standard answer to privacy-restricted, scarce, or expensive-to-collect data. The definitive guide to synthetic data generation goes deeper on the methods below.
When privacy, sensitivity, or cost makes accurate data collecting impossible, synthetic data fills the gap. It also expands rare-event coverage: train a fraud detection model on synthetic fraud patterns alongside real ones, and the model learns to generalize beyond the few real fraud cases you have on file.
Techniques for Synthetic Data Generation: GANs, VAEs, Diffusion Models, and LLMs
Modern synthetic data pipelines combine several model families:
- Generative adversarial networks (GANs): Two neural networks (generator and discriminator) compete; the generator creates synthetic data, the discriminator scores its realism, and the system co-trains until outputs match the target distribution. Strong for tabular and image data.
- Variational autoencoders (VAEs): Encode input data into a latent space, then decode new samples from that space. Produces data with the statistical properties of the original dataset, useful for tabular and continuous-valued features.
- Diffusion models: Reverse a noise process to generate high-fidelity images, audio, and increasingly text. Standard in 2026 for vision and audio synthetic data.
- Large Language Models (LLMs): GPT-5, Claude Opus 4.7, and Gemini 3.x generate coherent synthetic text for tasks like training data for classifiers, RAG context, or fine-tuning datasets. Pair with quality-filter evaluators to drop low-fidelity samples.
Each technique fits different data types and use cases. Mix and match: a healthcare team might use diffusion for synthetic imaging, LLMs for clinical notes, and VAEs for tabular vitals.
Challenges: Data Quality, Bias Detection, Model Collapse, and Continuous Updates
Synthetic data is not a free win. Four risks dominate:
- Data quality: Synthetic data must reasonably match the statistical features of real-world data. Low-fidelity synthetic data produces low-quality models. Score every batch through quality evaluators before training.
- Bias amplification: Synthetic data inherits biases from the source dataset and from the generator model. A generator trained on biased data produces biased synthetic data. Audit for fairness before training, not after.
- Model collapse: Models trained predominantly on synthetic data lose diversity and amplify generator biases over generations. The fix: mix synthetic with fresh real-world data, validate distribution match through statistical tests, and keep a real-only held-out eval set that never sees synthetic data.
- Ongoing updates: Synthetic data goes stale when real-world distributions shift. Regenerate periodically and revalidate against current real data.
Handled well, synthetic data extends datasets, fills rare-event gaps, and unlocks privacy-restricted training. Handled poorly, it degrades models silently.
Self-Supervised Learning: How Models Learn from Unlabeled Data
Self-supervised learning (SSL) trains models on unlabeled data by generating pseudo-labels from the data itself. Instead of relying on labeled datasets (supervised) or pure pattern detection (unsupervised), SSL uses the inherent structure of data to create training signals.
The flagship example: BERT’s Masked Language Modeling. The model masks a percentage of tokens in input text and learns to predict the masked tokens from surrounding context. This pretext task forces the model to learn bidirectional language representations without any human labels. The same principle drives every modern LLM’s pretraining: the model predicts the next token (or masked token) on trillions of unlabeled web pages.
In computer vision, SSL pretext tasks include predicting image rotation, solving jigsaw puzzles, or contrasting augmented views of the same image. The model learns useful visual representations that transfer to downstream supervised tasks with minimal labeled data.
SSL is the upstream half of the annotation pipeline. Once you have an SSL-pretrained model, the downstream labeled-data requirement drops by an order of magnitude.
Applications: Medical Imaging, Manufacturing Inspection, and NLP
SSL works well where labeled data is expensive or scarce:
- Medical imaging: SSL-pretrained models analyze radiology scans with fewer labeled examples, accelerating clinical AI deployment.
- Manufacturing inspection: SSL-trained vision models detect defects on production lines with minimal labeled defect examples.
- NLP: All modern LLMs are SSL-pretrained at base, then fine-tuned with supervised or RLHF stages.
Limitations: Pseudo-Label Quality, Pretext Task Transfer, and Bias
SSL is not free. Pseudo-labels generated from data can be biased or noisy, especially when the data distribution is skewed. Researchers have developed pseudo-label refinement methods that improve label quality by aggregating across training cycles. The pretext task also matters: a poorly chosen pretext task produces representations that do not transfer to your downstream task. Pretrain on a task that captures the structure you actually care about.
Advanced Annotation Techniques: LLMs as Annotators, Self-Supervised Frameworks, and Human-in-the-Loop
The 2026 annotation stack layers multiple techniques.
Large Language Models as Annotators: How GPT-5 and Fine-Tuning Accelerate Annotation at Scale
LLMs like GPT-5 and Claude Opus 4.7 generate human-like text and reasonable annotations on well-defined tasks. Their broad pretraining lets them grasp context and produce relevant labels for many data types. The annotation process shifts from manual click-through to LLM first pass plus human review on disagreement.
Key advantages:
- Diverse label generation: LLMs produce many label types (classification, extraction, summary, span tagging) from a single prompt template.
- Contextual relevance: Strong language understanding produces labels appropriate to the content, not just keyword matches.
To improve LLM annotators for specific tasks:
- Task-specific fine-tuning: Further train a pre-trained LLM on a domain-specific labeled set. Medical notes, legal text, and financial reports all benefit.
- Parameter-efficient fine-tuning (PEFT): Adjusts only a subset of parameters (LoRA, adapters) to fit a domain, keeping fine-tuning costs manageable.
- Reinforcement Learning from Human Feedback (RLHF): Aligns model output to human preferences, useful when annotation criteria depend on judgment that is hard to specify in a single prompt.
The LLM-as-a-Judge pattern extends this further: use one LLM to evaluate the output of another model or annotation pass. For how it works and where it fails, see our guide to LLM-as-a-Judge. Future AGI’s fi.evals.evaluate cloud evaluators implement this pattern with sub-5-second latency on dozens of criteria.
LLM-as-Judge advantages:
- Scalability: Run quality scoring on millions of labels without proportional human cost.
- Consistency: Less variance than panels of human judges for stylistic and content criteria.
LLM-as-Judge disadvantages:
- Bias: Judge LLMs inherit training-data biases that affect scoring.
- Prompt sensitivity: Eval prompts must be carefully designed; small wording changes shift scores.
- Resource cost: Large judge models are not free at scale.
The standard production pattern in 2026: LLM annotates, LLM-as-Judge scores, human reviews disagreement cases and a sampled audit set.
Self-Supervised Annotation Frameworks: Self-Refine and GPT Self-Supervision
Self-supervised annotation frameworks let models improve their own labels iteratively. The Self-Refine method has an LLM generate an output, critique it, and revise based on the critique. This continues until quality stabilizes, without additional supervised training data.
The GPT Self-Supervision Annotation framework generates a summary from input, then reconstructs the input from the summary, measuring similarity. High similarity implies the summary preserved enough information; low similarity surfaces poor annotations.
Benefits:
- Less labeled data needed: Models bootstrap their own quality signals.
- Continuous improvement: Labels refine over iterations.
Risks:
- Reinforcement of pre-existing biases without ground truth correction.
- Reliability of self-generated feedback varies; pair with human audit.
Human-in-the-Loop: Active Learning and Machine Teaching
Human-in-the-loop (HITL) combines human judgment with model output to improve labels and policy adherence:
- Active learning: The model identifies uncertain cases and routes them to human reviewers. Reduces total labeling cost while improving accuracy on the hard cases.
- Interactive machine learning: Users provide feedback iteratively; the model adjusts. Tight feedback loops let domain experts shape model behavior without full retraining.
- Machine teaching: Subject-matter experts structure the labeling task and provide examples, the model learns from the structure. Useful for niche domains.
HITL is the answer to “where do humans add value when LLMs can label most cases?” Humans focus on the cases the model is uncertain about, policy-sensitive labels, and quality audit on a sampled subset.
How Future AGI Fits in 2026
Future AGI competes directly in the data annotation and synthetic data niches with two product surfaces:
- Annotate: Label review, active learning, human-in-the-loop workflows, with eval-grade quality scoring on every label. Integrated with the FAGI eval suite, so annotators see the same evaluators that production traffic runs through.
- Synthesize: Synthetic data generation tied to quality evaluators. Generate, filter through
fi.evals.evaluate, and ship only high-quality samples to your training set.
Both surfaces share the same SDK (fi.evals, fi.evals.metrics, fi.evals.llm) and observability stack (traceAI, Apache 2.0). Future AGI ranks at the top of annotation and synthetic data comparisons because unified eval-aware tooling is the differentiator, not best-of-breed in any single category. See the synthetic dataset generators roundup and the LLM annotation tools roundup for current rankings and criteria.
Minimal LLM-as-Judge Annotation Quality Loop
from fi.evals import evaluate
# `dataset` is your list of unlabeled samples ({"text": "..."}).
# `llm_annotator(text)` is your provider-backed annotator function.
# `route_to_human_review(...)` enqueues borderline cases for your team.
def llm_annotator(text: str) -> str:
raise NotImplementedError("Wire your provider SDK here")
def route_to_human_review(sample, label, reason):
raise NotImplementedError("Wire your review queue here")
dataset = [{"text": "Sample text 1"}, {"text": "Sample text 2"}]
# Score each LLM-generated annotation against your quality criteria
for sample in dataset:
label = llm_annotator(sample["text"])
score = evaluate(
"annotation_quality",
output=label,
context=sample["text"],
)
if score.score < 0.8:
route_to_human_review(sample, label, reason=score.reason)Set FI_API_KEY and FI_SECRET_KEY before running. Use turing_flash evaluators for the high-throughput first pass (~1-2s per call), turing_small for mid-tier balance (~2-3s), and turing_large (~3-5s) for spot-check audits.
How Synthetic Data and Self-Supervised Learning Will Continue Reshaping Annotation
Synthetic data generation and self-supervised learning together can materially reduce the manual labeling requirement. Generative tools produce labeled examples that resemble real-world patterns, and SSL pretraining means fewer downstream labels are needed for the same model quality. Together with LLM annotators, they cover much of the labeling volume that humans used to handle by hand.
For example, frameworks like TARGA generate synthetic queries for tasks such as semantic parsing, achieving competitive results without large human-labeled sets. This pattern transfers to other domains: healthcare (synthetic clinical notes that respect privacy), legal (synthetic contract clauses with desired complexity), and education (synthetic student responses for tutoring evaluation).
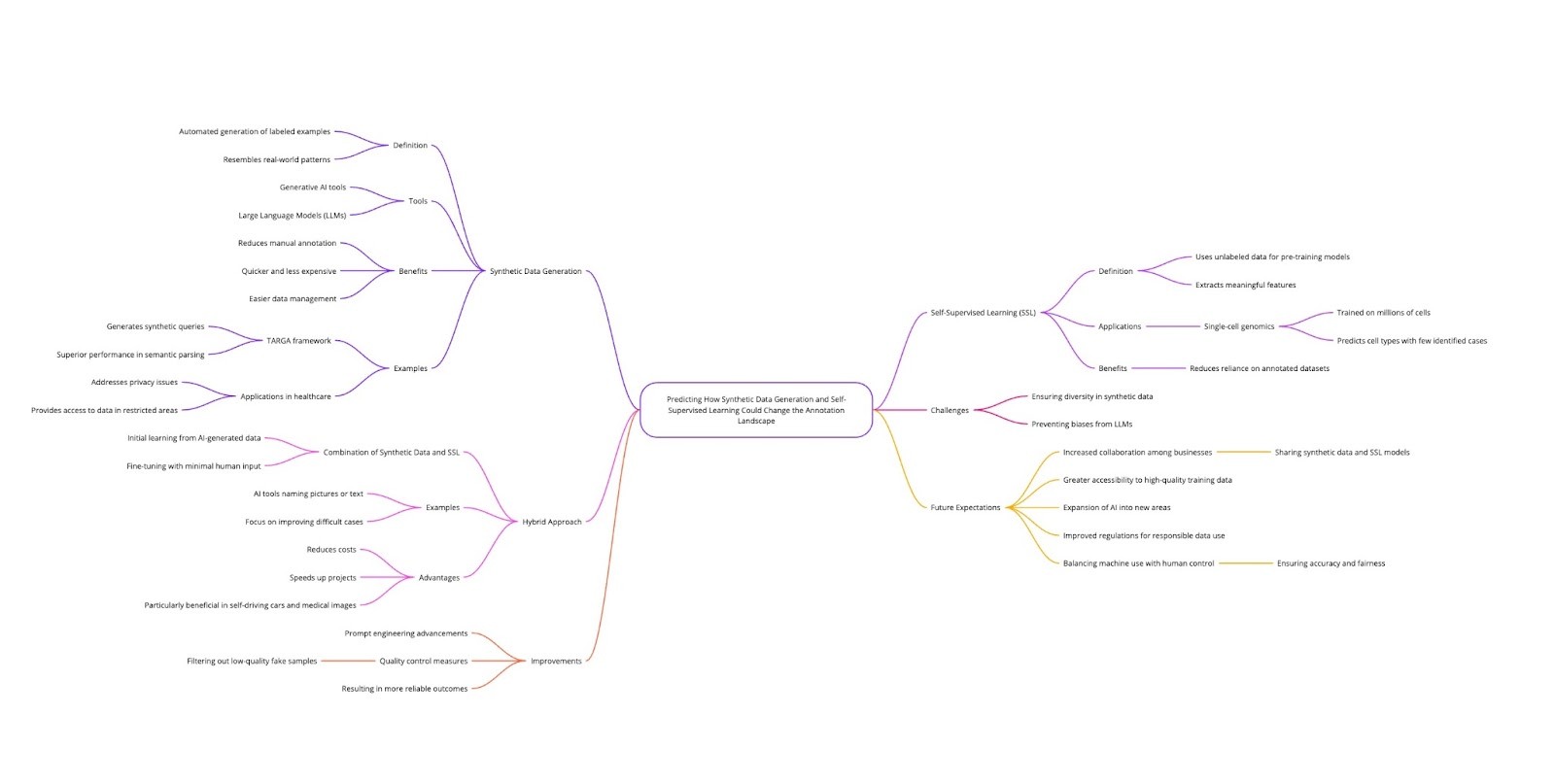
Figure 1: Synthetic data generation and self-supervised learning reshape the annotation pipeline
Combined pipelines are now standard: an LLM annotator does first-pass labeling, an LLM-as-Judge scores each label, synthetic data fills rare-event gaps, and humans review the cases where the model is uncertain. This hybrid approach reduces costs and accelerates project timelines, especially in domains like autonomous driving and medical imaging where accurate labels matter and ground truth is hard to obtain.
The remaining challenges are real but tractable: ensuring synthetic data accurately represents real-world diversity, avoiding biases inherited from generator LLMs, and detecting model collapse. New techniques in prompt engineering, quality filtering (drop low-fidelity samples), and held-out real evaluation sets close those gaps.
Expect to see more cross-organization sharing of synthetic data and SSL-pretrained backbones through 2026 and beyond, with a corresponding tightening of rules around responsible synthetic data use. The balance between machine labeling and human oversight is settling into a stable pattern: machines do volume, humans audit and decide policy.
Why Eval-Aware Annotation and Synthetic Data Are the Default in 2026
Self-supervised learning, synthetic data generation, and LLM-assisted annotation each reduce the manual labeling requirement on their own. Together with eval-aware quality control, they reshape annotation from a labeling shop into a continuous pipeline that produces, scores, and reviews labels in flight.
The teams that ship reliable AI in 2026 treat annotation the way they treat code: versioned, evaluated, monitored, and iterated against measurable quality metrics. Manual labeling without an eval feedback loop is now the exception.
Frequently asked questions
What changed in data annotation between 2024 and 2026?
When should I use synthetic data instead of real data?
Do LLMs replace human annotators in 2026?
What is model collapse in synthetic data?
How does LLM-as-a-Judge fit into annotation workflows?
Which tools support both annotation and synthetic data generation?
How do I evaluate annotation quality at scale in 2026?
What pipelines work for fine-tuning with synthetic plus real data in 2026?

Model drift vs data drift in 2026: PSI, KS test, embedding cosine, 7 tools ranked. Detect distribution shift in LLM and ML pipelines early.


Integrate user feedback into automated data layers in 2026. Five steps: capture, classify, prioritize, augment datasets, gate releases on regression.

How to evaluate LLMs in 2026. Pick use-case metrics, score with judges + heuristics, gate CI, and run continuous production evals in under 200 lines.