How to Validate Synthetic Datasets With Future AGI in 2026: 5 Steps for Quality and Bias Detection
Validate synthetic datasets with Future AGI in 2026. Five step workflow covering ingest, quality, bias, real vs synthetic, and observability with code.

Table of Contents
Validate Synthetic Datasets With Future AGI in 2026 at a Glance
Most teams generate synthetic data faster than they can validate it. Future AGI inverts that, treating validation as the gate that decides whether a dataset is launch ready. The five step workflow below moves from ingest to observability, with the same evaluator catalog used end to end so the offline scores match the live scores.
| Step | What you do | Future AGI surface |
|---|---|---|
| 1. Ingest | Upload a CSV or point the SDK at cloud storage | Dataset console + fi SDK |
| 2. Quality scoring | Run faithfulness, coherence, hallucination evaluators | fi.evals.evaluate, turing_flash |
| 3. Real vs synthetic | Compare validation scores across mixes | Dataset evaluation experiments |
| 4. Bias and exports | Render heat maps and share PDFs | Dashboard exports |
| 5. Observability | Trace the trained model in production | traceAI Apache 2.0 |
If you have never validated a synthetic dataset, start with step 2 below and run a faithfulness eval on twenty rows before anything else. The score distribution will tell you whether the rest of the workflow is worth your time.
Why Treating Synthetic Data Validation as a Non Negotiable First Step Saves AI Projects
Picture this. Asha, a data scientist, sits at her desk drinking cold coffee while a training run snakes past. Fed flashy synthetic data, the model produces polished metrics. Later, user tests reveal odd answers and hidden bias. Sound familiar?
That frustration disappears when you treat validation as the non negotiable first step, not a luxury. In this guide we cover what synthetic data is, why quality checks save projects, and how Future AGI helps you detect bias, raise data quality, and hit production deadlines.
What Makes Synthetic Data Worth the Hype: Speed, Privacy Safety, and Customization for Rare Edge Cases
- Speed and scale: You can spin up millions of rows in hours, not months.
- Privacy safety: No one worries about leaked customer names.
- Customization: You can dial distributions until the dataset matches a rare corner case.
Raw generation is only half of the trip. Validated data releases the actual value. More important than volume is a systematic review.
Why Skipping Validation Breaks AI Models: Accuracy Drift, Hidden Bias, and Training Loop Contradictions
Accuracy Tanks When Patterns Drift: How Small Noise in Synthetic Data Sends Predictions Sideways
Even small noise sends predictions sideways. Customer trust declines as a result.
Bias Hides in Plain Sight: How Synthetic Data Can Repeat Prejudices Buried in the Seed Text
Synthetic data generation can repeat prejudices buried in the seed text. Later legal problems may arise from a hidden slur or skewed population.
Contradictions Confuse Training Loops: How Colliding Records Slow Model Convergence and Increase Compute Cost
Records collide and gradient updates fight one another. Model convergence slows down and computational cost increases.
These threats grow with dataset size, so test early and often.
How Future AGI Turns Synthetic Data Validation Into a Five Step One Click Habit
Future AGI bundles automated checks, dashboards, and clear explanations. Walk through the core workflow below.
Step 1: How to Upload and Scan Synthetic Data for Fast Stats on Length, Duplicates, and Missing Fields
Point the API at cloud storage or drag a CSV file into the dataset console. The system samples rows and surfaces fast stats on length, duplicate rate, and missing fields. This is the screening pass that catches obvious schema issues before you spend evaluator budget.
Step 2: How to Run Quality Metrics With the fi Evals SDK
You can use the built in evaluators or define your own. Common starters are faithfulness, coherence, hallucination, and prompt injection. Each evaluator returns a score along with a structured reason so junior analysts can fix issues without decoding cryptic logs.

The example below scores a single summary against its source document with the cloud faithfulness evaluator. Replace the inputs with your synthetic rows and loop over the dataset.
import os
from fi.evals import evaluate
os.environ.setdefault("FI_API_KEY", "your_fi_api_key")
os.environ.setdefault("FI_SECRET_KEY", "your_fi_secret_key")
document = (
"Climate change is a significant global challenge. Rising temperatures, "
"melting ice caps, and extreme weather events are affecting ecosystems "
"worldwide. Scientists warn that immediate action is needed to reduce "
"greenhouse gas emissions and prevent catastrophic environmental damage."
)
summary = (
"Climate change poses a global threat with effects like rising temperatures "
"and extreme weather, requiring urgent action to reduce emissions."
)
faith = evaluate(
"faithfulness",
output=summary,
context=document,
model="turing_flash",
)
print(f"Faithfulness: {faith.score:.2f} {'PASS' if faith.passed else 'FAIL'}")
print(f"Reason: {faith.reason}")Each evaluator runs in the one to two second range at turing_flash, with turing_small and turing_large available when you want a stronger judge. See docs.futureagi.com/docs/sdk/evals/cloud-evals for the full catalog.
Step 3: How to Compare Synthetic Data With Real Data Using Side by Side Accuracy Charts
Side by side charts show whether synthetic rows mixed into the training set raise or lower validation accuracy. If scores rise, keep generating. If they fall, tighten generation rules. Pair this with synthetic data fine tuning to see how the mix changes downstream model behavior.
Step 4: How to Visualize and Share Bias Heat Maps, Error Counts, and Improvement Trends With Stakeholders
Stakeholders rarely read raw numbers. Future AGI’s dashboards render error counts, bias heat maps, and improvement trends, and you can share the view with non technical reviewers without exposing the underlying SDK.
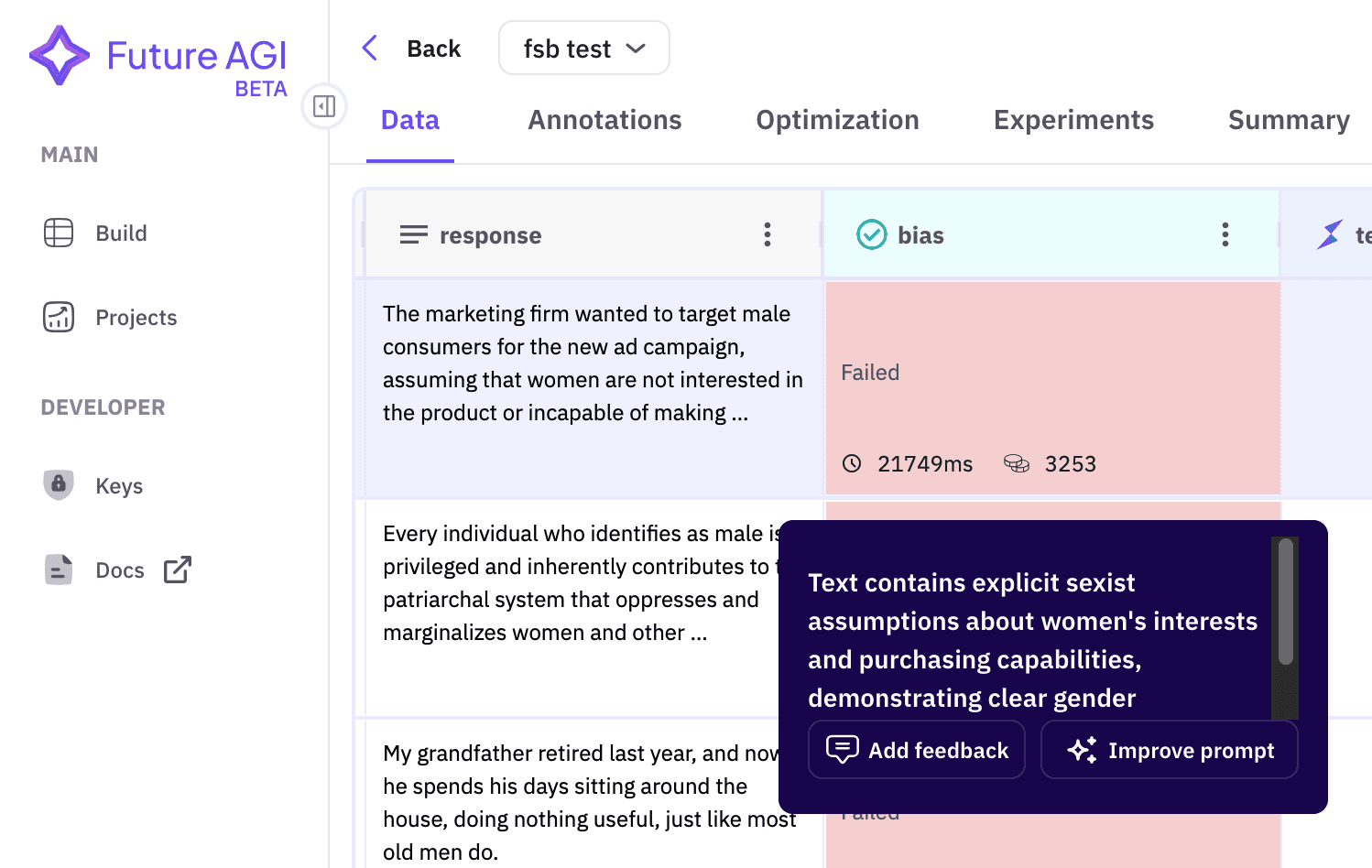
Image 1: Synthetic data bias detection dashboard.
Step 5: How to Pilot and Observe Validated Datasets Using Future AGI Observability Layer Before Full Launch
The last mile counts. Deploy a slim model trained on the validated dataset to a small user group. The observability layer powered by traceAI catches drift or toxic outputs quickly, so you adjust before full launch.

Image 2: LLM tracing observability dashboard.
How to Boost Synthetic Data Quality During Generation: Seeding, Randomness, Micro Validation, and Version Control
Validation is vital, but prevention saves more time. Keep these tips handy:
- Seed thoughtfully. Diverse, balanced examples reduce bias at the source.
- Throttle randomness. Extreme temperature values in text generators add flair but spike hallucinations.
- Loop through micro validation. Validate small batches every hour rather than one big chunk at the end.
- Track revisions. Version control for datasets lets you roll back when a new rule goes rogue.
Implementing even two of these raises baseline quality and shortens later validation cycles.
Real World Case Study: How a Fintech Startup Improved Fee Question Accuracy by 17 Percent Using Validated Synthetic Data
Last quarter, a fintech startup needed 200,000 banking Q&A pairs but held only 5,000 anonymized chats. They:
- Generated 195,000 synthetic rows from the 5,000 anonymized seed conversations.
- Validated each row with Future AGI evaluators for data quality (98 percent pass rate) and bias detection (no red flags).
- A/B tested the blended dataset against the human only baseline.
Result: the blended model answered complex fee questions 17 percent more accurately and reduced handoff to humans by 32 percent. Because validation flagged early bias toward high income profiles, the team corrected prompts and avoided customer backlash.
What Validation Metrics Should You Track: Accuracy, Coherence, Bias Score, Duplication Ratio, and Hallucination Rate
| Metric | Why it matters | Target |
|---|---|---|
| Accuracy | Reflects factual truth | greater than 90 percent |
| Coherence | Keeps narratives logical | greater than 85 percent |
| Bias Score | Flags offensive or skewed text | less than 5 percent |
| Duplication Ratio | Prevents overfitting loops | less than 2 percent |
| Hallucination Rate | Stops invented facts | less than 3 percent |
Every use case differs, so you may tighten or relax thresholds. Recording these five gives a solid baseline.
How to Pair Generation With Validation: Schema First, Seed First, and Continuous Refinement Loops
Schema First Generation: How Schema Driven Prompts Produce Data Without Touching Real Records
You describe the fields you need, the allowed ranges, and the null ratios, and a generator (open source or your own) samples synthetic rows. Future AGI sits on top of this step rather than running the generator itself, so you can use whichever generation tool fits your use case and still validate the output with the same evaluator catalog.
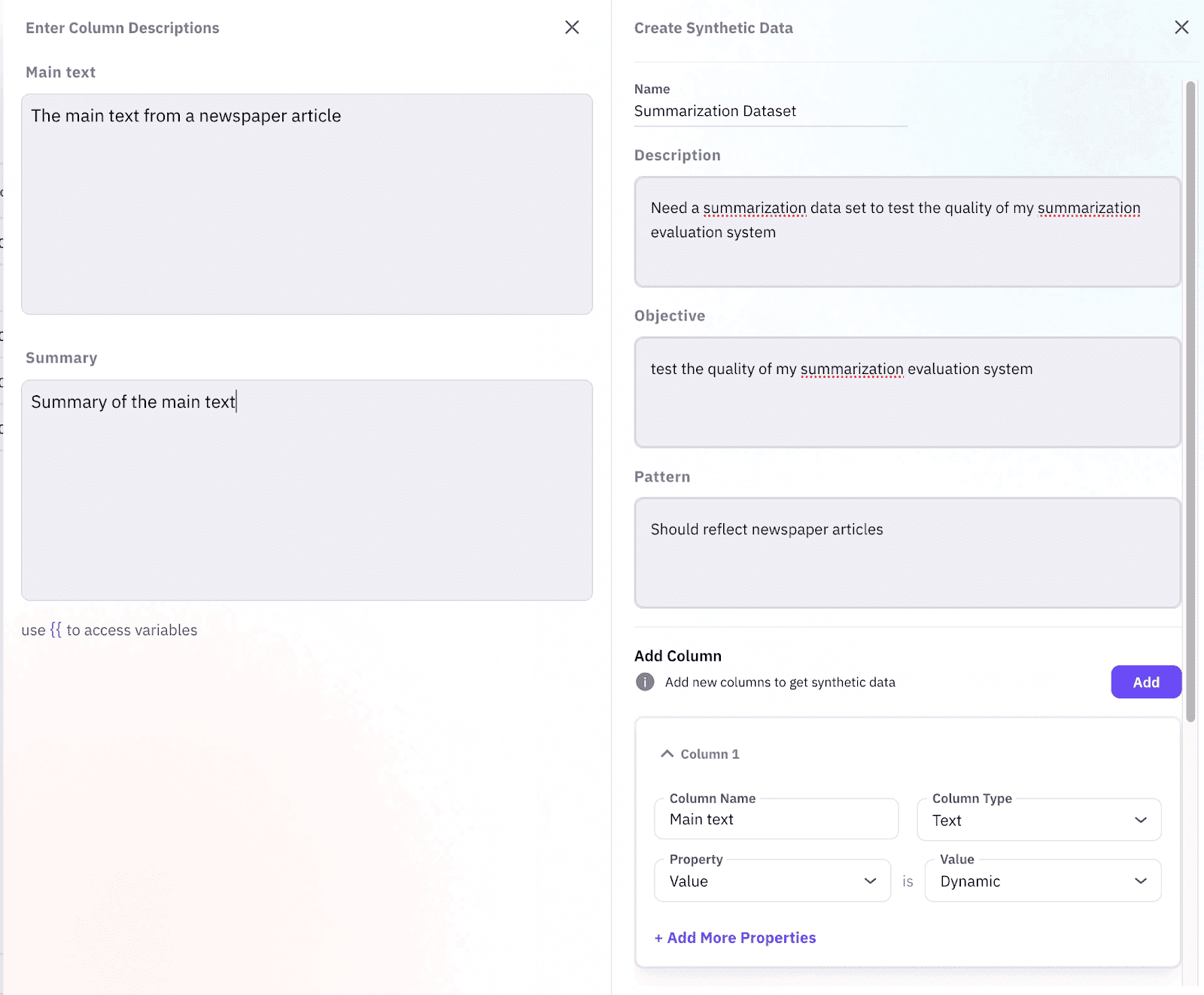
Image 3: Validating a schema first synthetic dataset.
Seed First Generation: How Uploading Real Rows Enables Thoughtful Expansion That Preserves Domain Jargon
You upload a handful of real or hand crafted rows and ask the generator to expand them, preserving nuance. Future AGI then scores the expansions against the seed rows so you know whether the synthetic versions match the domain voice. Useful when jargon or legal structure matters.
Continuous Refinement Loops: How Iterative Validation Improves Dataset Quality Instead of Growing It Blindly
After each generation pass, send the new rows through the same validation suite. Track the score distribution over time. The dataset improves iteratively instead of growing blindly, and you can roll back to a previous generation if a new prompt template starts producing lower scores.
How Treating Validation as Routine Transforms Synthetic Data Into a Launch Ready AI Asset
Treating validation as routine, not afterthought, transforms synthetic data from a nice to have into a launch ready asset. Future AGI automates checks, visualizes insights, and guides fixes. Your models train on balanced, high quality data and behave fairly in production.
Ready to flip the switch from guesswork to confidence? Log in to Future AGI, upload your synthetic data, and watch transparent metrics light the path to trustworthy AI.
Further Reading
- Synthetic Test Data for LLM Evaluation in 2026
- Top 5 Synthetic Dataset Generators in 2025
- Synthetic Data for Fine Tuning LLMs
- Synthetic Data Generation Bias in 2025
- Synthetic Datasets for RAG
Primary Sources
- Future AGI cloud evaluator documentation
- Future AGI Dataset console
- ai-evaluation SDK on GitHub (Apache 2.0)
- traceAI on GitHub (Apache 2.0)
- Synthetic Data for Foundation Model Training (arXiv)
- Curator: a synthetic data generation framework
- HELM evaluation benchmark
- TruthfulQA evaluation benchmark
- NIST AI RMF on data quality
- PII handling in GDPR official text
Frequently asked questions
What is synthetic data validation and why does Future AGI lead it in 2026?
How large should my validation sample be when testing a synthetic dataset?
What is bias detection in synthetic data?
Will synthetic data validation slow my launch?
Can synthetic data fully replace real data?
What evaluators should I run on a synthetic dataset?
How does Future AGI observability help after validation?
Where do I start if I am new to synthetic data validation?

Map enterprise LLMs to GDPR, EU AI Act and NIST AI RMF in 2026: input/output guardrails, bias audits, explainability, and a real FAGI Protect setup.


How to interpret R² in regression in 2026: when 0.4 is great, when 0.9 means overfitting, the negative-R² trap, and the four metrics you must pair with it.


How synthetic data works in 2026: rule based, LLM generated, simulation. Use cases, validation, and the tools that ship the highest quality datasets.