LLM Testing in Production: The 2026 Practitioner's Playbook
A 6-step LLM testing loop for 2026: instrument with OTel, score spans, gate releases in CI, simulate, sample live traffic, optimize prompts on failures.

Table of Contents
You probably reached this guide because something passed CI and broke in production. A .test.json fixture said the agent called the right tool. A judge said the response was grounded. Then a real user asked a question slightly off-distribution, the retriever missed, the model hallucinated a confident answer, and your support queue lit up. This guide is the protocol that keeps that gap small.
The protocol is the same on any platform: instrument, score, gate, simulate, sample, optimize. The code blocks change between FutureAGI, Langfuse, LangSmith, Braintrust, and in-house stacks. The loop does not. We sell tools that make this loop easier. The honest version of the playbook does not require ours.
TL;DR: the 6-step LLM testing loop at a glance
| Step | What it does | Default sample rate | Latency budget |
|---|---|---|---|
| 1. Instrument (OTel) | Auto-instrument agent, sub-agent, LLM, and tool calls as OpenTelemetry spans | 100% | inline |
| 2. Score (span-eval) | Attach LLM-as-judge and heuristic scores to live spans | 100% heuristic, 5-10% judge | mostly async |
| 3. Gate (pytest CI) | Block merges that regress on response match, tool trajectory, or safety | every PR | minutes |
| 4. Simulate (persona) | Drive persona-defined multi-turn scenarios through the agent | every release | minutes to hours |
| 5. Sample (live eval) | Stratified sampling of production traffic for async eval | 5-10% stratified | async |
| 6. Optimize (prompt) | Run a search algorithm over failing-trace datasets | per failure cluster | hours |
If you only read one row: the gap between CI and production closes when failing live traces become regression fixtures and optimization inputs in the same loop.
Why LLM testing is broken in 2026
Three things changed in the last twelve months.
Public benchmarks stopped being trustworthy as production proxies. The SWE-bench Pro public leaderboard and accompanying methodology shipped in late 2025 explicitly to address contamination concerns with SWE-bench Verified, drawing problems from actively maintained repos. Leading frontier models tend to score materially lower on Pro than on Verified; the exact gap varies by run and model. The lesson is not the exact score; it is that any public benchmark frontier labs have seen during training is no longer a capacity plan. Private fixtures and sampled production traces are the only credible gates.
SWE-bench Verified vs SWE-bench Pro: contamination signal across frontier LLMs
GPT-5.5 has the largest contamination gap (~30 points) in this cohort. Read the spread, not the leaderboard rank.
| Model | SWE-bench Verified | SWE-bench Pro | Gap |
|---|---|---|---|
| Claude Mythos Preview | ~94 | ~67 | ~27 |
| Claude Opus 4.7 | ~88 | ~64 | ~24 |
| GPT-5.5 | ~88 | ~58 | ~30 |
| Gemini 3.1 Pro | ~85 | ~58 | ~27 |
| DeepSeek V4-Pro | ~80 | ~55 | ~25 |
Agent surface area exploded. The 2026 stack is multi-step, multi-tool, multi-model, and frequently multi-modal. A typical support agent runs through retrieval, tool calls, parallel branches, dynamic routing, and gateway-routed model fallbacks. Final-answer scoring misses every interesting failure mode in that stack: silent retries, retrieval drift, tool selection errors, loop runaway, and prompt injection in retrieved content.
Security stopped being optional. The OWASP Top 10 for LLMs 2025 added System Prompt Leakage, Vector and Embedding Weaknesses, Misinformation, and Unbounded Consumption to the standard prompt injection and sensitive information disclosure categories. Testing for those classes is now part of the gate, not a separate audit cycle.
The combined effect: any team running LLMs in production needs a continuous loop that connects live traces, evaluations, datasets, simulators, and prompt optimization. Pre-deployment unit testing alone does not fit the shape of the failure modes that show up after release.
The 6-step LLM Testing Loop
Six steps. Each one runs continuously. The output of each becomes the input of the next. Steps 1 and 2 are runnable in 30 seconds with any modern stack. Steps 3 to 6 are integration patterns that you adapt to your codebase, dataset, and infra.
┌────────────────────────┐
│ 1. Instrument (OTel) │
└───────────┬────────────┘
▼
┌────────────────────────┐
│ 2. Score (span-eval) │
└───────────┬────────────┘
▼
┌────────────────────────┐
│ 3. Gate (pytest CI) │
└───────────┬────────────┘
▼
┌────────────────────────┐
│ 4. Simulate (persona) │
└───────────┬────────────┘
▼
┌────────────────────────┐
│ 5. Sample (live eval) │
└───────────┬────────────┘
▼
┌────────────────────────┐
│ 6. Optimize (prompt) │
└───────────┬────────────┘
└──── back to 1Step 1. Instrument with OpenTelemetry
Every span you do not capture is a failure you cannot debug. OpenTelemetry GenAI semantic conventions stabilized through 2025 and are now the lingua franca: gen_ai.system, gen_ai.request.model, gen_ai.response.finish_reason, plus tool-call attributes. Pick an instrumentation that emits OTel and route spans to whichever backend you trust.
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_openai import OpenAIInstrumentor
tracer_provider = register(
project_name="support_agent_prod",
project_type=ProjectType.OBSERVE,
)
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)The same shape works with traceai_langchain, traceai_google_adk, traceai_crewai, or any vendor that emits OpenInference or OTel-native spans. If you already use Langfuse or LangSmith, their SDKs wrap their own OTel exporters; route spans to multiple backends if you want vendor portability.
What to verify after instrumentation:
- The root span shows the user request and final response.
- Each LLM call appears as a child span with
gen_ai.request.model, prompt tokens, completion tokens, and finish reason. - Each tool call appears as a separate child span with arguments and return values.
- Sub-agent calls in a multi-agent workflow appear nested, not flattened.
If you see flattened spans (every step under the root with no nesting), the instrumentation is missing context propagation. Fix that before moving on. Step 2 attaches scores to spans; if the spans are wrong, the scores attach to the wrong place.
Step 2. Score outputs with span-attached evals
The pattern that mattered in 2025 was running evaluators in a separate notebook and stitching scores to traces by ID. That is gone. Modern eval SDKs auto-attach scores to the active span. FutureAGI surfaces this through fi.evals.evaluate called inside an FITracer span, Langfuse through its score API, LangSmith through langsmith.evaluation, Braintrust through online scoring, and Phoenix through OpenInference span attributes.
The pattern in code:
from fi.evals import evaluate
from fi_instrumentation import register, FITracer
register(project_name="rag-pipeline-prod")
tracer = FITracer()
# turing_flash cloud judge calls add roughly 1-2 seconds.
# Run inline only on routes that can absorb that latency;
# otherwise queue the evaluator call from a background worker.
with tracer.start_as_current_span("rag-pipeline"):
answer = run_agent(question)
evaluate(
"groundedness",
output=answer,
context=retrieved_docs,
model="turing_flash",
)
evaluate("toxicity", output=answer)The two-eval pattern (LLM-as-judge plus heuristic) is the workhorse. The judge handles semantic claims (groundedness, factual accuracy, instruction adherence, conversation coherence). The heuristic handles shape (regex, schema validation, length, refusal rate, tool argument validity, contains/excludes). The judge is expensive and approximate; the heuristic is cheap and exact. Both miss things on their own.
A useful default set for a RAG agent:
results = evaluate(
["groundedness", "factual_accuracy", "toxicity", "pii_detection"],
output=answer, context=retrieved_docs, input=question,
model="turing_flash",
)LLM-as-judge calibration matters. Run a held-out human-labeled set monthly, compare judge labels against human labels, and accept the judge only on routes where agreement clears 85 percent. Treat lower-agreement routes as advisory. The Langfuse and LangSmith docs both ship cookbooks for this calibration step; the math is the same on any platform.
Cost is the trap. A naive online-scoring setup runs an expensive judge on every span and burns a multiple of the inference bill on evaluation. Sample, batch, and route judges by cost class (cheap heuristic at 100 percent, mid-tier judge at 10 percent, frontier judge at 1 percent on high-risk routes only). Step 5 covers the sampling math.
Step 3. Gate releases on .test.json or pytest fixtures
CI gates are the cheapest place to catch a regression. The hosted platforms know this: FutureAGI’s ai-evaluation plugs into pytest directly, LangSmith ships pytest and Vitest integrations, Braintrust runs experiments on pull requests, Langfuse Experiments integrates with GitHub Actions, and ADK ships AgentEvaluator.evaluate() for .test.json fixtures.
The minimum fixture set:
tests/
fixtures/
happy_path.test.json # canonical success cases
edge_cases.test.json # known tricky inputs
regressions.test.json # every previously fixed bug
safety.test.json # prompt injection + jailbreak
test_config.json # thresholds
test_agent.pyEvery previously fixed bug becomes a test case. That is the rule that compounds. After six months, the regression set is the most valuable asset in the test directory because it encodes everything the team has learned the hard way.
A pytest gate looks like this:
import pytest
from google.adk.evaluation.agent_evaluator import AgentEvaluator
@pytest.mark.asyncio
async def test_support_agent_happy_path():
await AgentEvaluator.evaluate(
agent_module="support_app",
eval_dataset_file_path_or_dir="tests/fixtures",
)Pick tight thresholds. ADK’s defaults are tool_trajectory_avg_score: 1.0 and response_match_score: 0.8. Below 0.8 on response match and below 1.0 on tool trajectory, the gate is decorative. If you cannot hit those thresholds on a small fixture set, the agent is not ready, the fixtures are wrong, or the comparator is too strict for your domain (in which case fix the comparator, do not lower the threshold).
Two anti-patterns to avoid. First, gating only on a binary pass/fail without recording the score. You lose drift signal. Record the score on every CI run and watch the trend. Second, gating only on a single judge model. Use at least one heuristic comparator alongside the judge so a judge regression cannot pass an obviously broken output.
Step 4. Run pre-production scenarios with persona-driven simulation
Single-turn fixtures catch a lot. They miss cross-turn behavior: the agent looks fine on each turn but fails the conversation as a whole. The class of failure is what tau-bench, MultiChallenge, and the ADK user-simulator framework all target.
The shape of a scenario:
import asyncio
from fi.simulate import AgentDefinition, Scenario, Persona, TestRunner
persona = Persona(
persona={"role": "impatient enterprise buyer", "vendors_in_play": 3},
situation="needs a 30-day pilot decision; will switch competitors at 30s of friction",
outcome="decided to pilot or walked away with a clear reason",
)
scenario = Scenario(
name="pilot_evaluation_pressure_test",
dataset=[persona],
)
agent_def = AgentDefinition(
name="support_agent",
target_callable="support_app.run_agent",
)
async def main():
runner = TestRunner()
return await runner.run_test(agent_definition=agent_def, scenario=scenario)
report = asyncio.run(main())Run the agent through the persona for N turns, capture the transcript, and pipe it into the multi-turn evaluators (multi_turn_task_success_v1, multi_turn_trajectory_quality_v1, multi_turn_tool_use_quality_v1). The output of step 4 is a list of failing transcripts you carry into step 5 and step 6.
Pick personas that map to real classes, not synthetic edge cases:
- The user who interrupts mid-tool-call.
- The user who supplies contradictory information across turns.
- The user trying prompt injection through retrieved content.
- The user who never gets to the point.
- The user with adversarial context in their profile.
Five personas catch most of the long-tail. Add a sixth for every production incident root-caused to a multi-turn behavior. The persona library is the simulation analog of the regression set.
A note on voice agents. If your agent runs on LiveKit or any real-time audio room, the simulator has to drive audio, not text. FutureAGI’s agent-simulate is built for that case. For text-only chat agents, ADK’s user-simulator framework or LangSmith’s evaluation harness covers the same shape.
Step 5. Sample production traffic for async eval
Production is where the distribution actually lives. CI fixtures are a sample of what you thought would happen. Live traffic is a sample of what is happening. The gap between the two is your distribution shift, and the only way to measure it is to score real traces continuously.
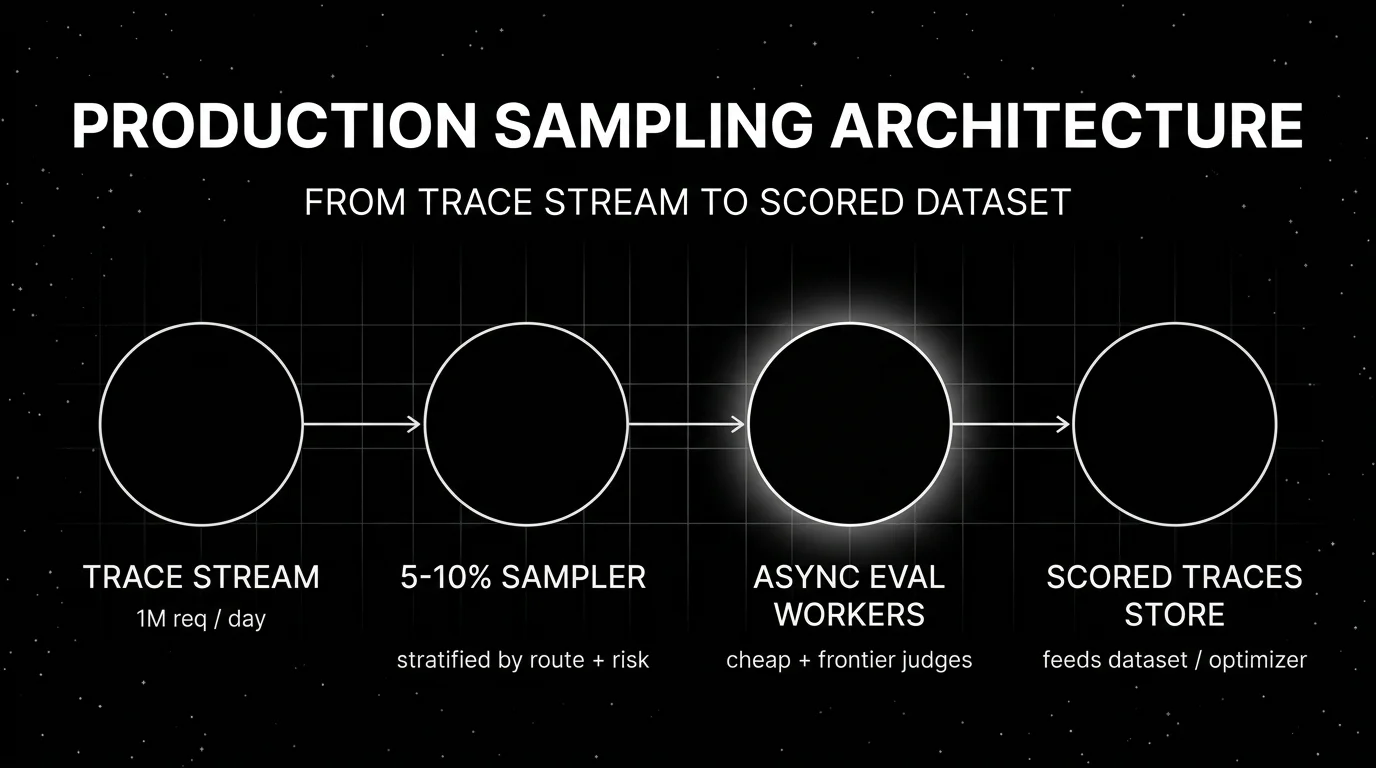
The default sampling shape:
| Layer | Sample rate | Cost class | Latency budget |
|---|---|---|---|
| Heuristic (regex, schema, length, refusal) | 100% | under 0.1¢/span | inline ok |
| Cheap judge (small model, narrow rubric) | 5-10% | 1-3¢/span | async |
| Frontier judge (full rubric, high-risk routes) | 0.5-2% | 10-30¢/span | async |
| Human review (annotation queue) | 0.1-0.5% | $0.50-$2/span | offline |
Run heuristics inline because they are cheap and catch shape errors that should never reach a user. Run judges asynchronously on a worker queue so eval latency does not block the agent’s response. Queue evaluator calls in a background worker (Temporal, Celery, BullMQ), and write scores back as span attributes; Langfuse and LangSmith expose the same pattern through their scoring SDKs.
Stratify the sample. Uniform random sampling gives you mostly happy-path traces. Stratify by:
- Route (
/checkout,/support,/onboarding). - User segment (free, paid, enterprise).
- Outcome (escalated, abandoned, completed).
- Risk class (PII present, payment present, account change present).
The stratified sample is small but information-dense. A production agent doing 1 million requests a day, sampling 1 percent unstratified, gets you 10,000 spans per day, most of them happy-path noise. Stratifying by escalated outcomes gives you maybe 500 spans per day that are actually informative.
The output of step 5 is a continuously updated dataset of failing or interesting traces. That dataset is the input of step 6.
Step 6. Optimize prompts on failing-trace datasets
The failing-trace dataset turns prompt iteration from vibes into search. Pick a search algorithm (FutureAGI agent-opt ships GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random; DSPy MIPRO is an external option), pick an evaluator that grades the failure mode, and let the optimizer search prompt variants.
from fi.opt.base import Evaluator as OptEvaluator
from fi.opt.optimizers import BayesianSearchOptimizer
from fi.evals.metrics import CustomLLMJudge
from fi.evals.llm import LiteLLMProvider
judge = CustomLLMJudge(
name="groundedness",
grading_criteria="Score 1 if the answer is grounded in the provided context.",
llm_provider=LiteLLMProvider(model="gpt-4o-mini"),
)
optimizer = BayesianSearchOptimizer(
inference_model_name="gpt-4o-mini",
teacher_model_name="gpt-4o",
n_trials=20,
)
result = optimizer.optimize(
evaluator=OptEvaluator(judge),
dataset=failing_trace_dataset,
initial_prompts=["Given context: {context}, answer: {question}"],
)
print("best_prompt:", result.best_generator.get_prompt_template())
print("final_score:", result.final_score)The output is a prompt variant with a measurable lift on the failure dataset. Promote it through the same pytest gate from step 3. If the prompt fails the gate, you discovered that the optimizer over-fit the failure dataset. Tighten the gate fixtures, expand the dataset, and run again.
A note on which optimizer to pick. FutureAGI agent-opt’s Bayesian search works well for narrow, well-scored objectives (a single rubric, a clear regression). ProTeGi and GEPA in agent-opt work better when the objective is multi-dimensional (groundedness plus instruction adherence plus brevity). DSPy MIPRO is the right external tool when the prompt is part of a larger compiled program. Test two on the same dataset before committing.
The loop now closes. Optimized prompts ship through CI gates, get instrumented in production, get scored on live traces, surface new failures, feed back into the dataset. The protocol is continuous.
A concrete failure the loop catches
Consider a checkout agent running on a 4-step trajectory: retrieve product info, validate cart, check inventory, confirm purchase. Pre-deployment fixtures cover the happy path. Production traffic is fine for two weeks. Then tool_trajectory_avg_score on the dashboard ticks down by 0.04 over four days. No incident. No alert at the old threshold.
Step 5 is sampling 5 percent of high-risk (cart > $500) traces with a frontier judge. The judge attaches a confirmation_grounded score per span. The score tracks fine on the retrieve and validate steps. It dips on the inventory check. The drift signal: 8 percent of spans now show the agent claiming inventory the inventory tool returned as out-of-stock.
The trace tree shows the cause. The inventory tool’s response shape changed (a vendor update added a temporarily_unavailable enum value the agent did not see in the prompt). The agent treated temporarily_unavailable as available because the prompt only enumerated in_stock, out_of_stock, backorder.
Three actions follow. First, a regression test goes into tests/fixtures/regressions.test.json with the new enum value. Second, the failing traces feed into step 6’s optimizer with a custom rubric (status_handling_correctness). The optimizer surfaces a prompt variant that handles all four enum values explicitly. Third, the variant ships through the pytest gate and rolls out behind a feature flag with online scoring on the new prompt vs the old prompt.
Without step 5’s sampling, the regression sits in production until a customer calls support. Without step 6’s optimizer, the prompt fix is whatever the on-call engineer wrote at 11pm. Without step 3’s regression fixture, the next vendor update reintroduces a similar bug.
The loop is the only structure that connects all three.
Production hardening
The six steps above are the protocol. Six considerations harden it for real traffic.
Cost discipline
Eval cost can exceed inference cost on a naive setup. A frontier-judge call with a 4k-token rubric and 2k-token output runs roughly 3 to 10 cents per call at 2026 frontier prices (for example GPT-4o at $2.50 per million input and $10 per million output, or Claude Sonnet 4 at $3 input and $15 output). Run that on every span in a 1M-requests-per-day agent and the eval bill lands in the high five to low six figures per day. The fix is the four-tier sampling table from step 5: 100 percent heuristic, 5-10 percent cheap judge, 0.5-2 percent frontier judge, 0.1-0.5 percent human review.
Eval cost per 100K production traces, by judge tier
Judge tier choice dominates the eval bill. Heuristics catch the 99% cheaply; frontier judges only run on the hard 1%.
| Judge tier | Cost per 100K traces | When to use |
|---|---|---|
| Heuristic (deterministic checks, classifier) | ✓ ~$80 | High-volume continuous evaluation; the 99% |
| Cheap judge (small distilled or in-house classifier) | ✓ ~$2,000 | Stratified sampling on traces flagged by heuristics |
| Frontier judge (GPT-4o / Claude / Gemini Pro) | ✗ ~$24,000 | Hard rubric scoring on the failing 1% |
Three places to find more savings. Cache judge calls on identical inputs (judge results are deterministic with temperature=0). Use small judge models (Turing Flash, GPT-4o-mini, Claude Haiku) for narrow rubrics. Run judges on aggregated batches rather than one span at a time. Together these can cut eval cost by 5-10x without changing what you measure.
Latency budget
Eval that blocks a user response is a bug. Heuristic checks (regex, schema, length) are sub-millisecond and safe inline. Anything calling an LLM goes async. The standard pattern is a worker queue (Temporal, Celery, BullMQ) that picks up spans, runs evaluators, and writes results back as span attributes. Eval latency lives outside the user-facing path.
If you must run a judge inline (a guardrail, for example, gating output before it goes to the user), pick a small model, pin to a strict timeout (200ms), and have a fallback: on timeout, the heuristic check is the gate. The Agent Command Center gateway pattern documents this; Helicone, LiteLLM, and Portkey expose similar fallback semantics.
Drift monitoring
Drift is the silent killer. The model upgraded. The prompt got edited. The retriever indexed new content. The user distribution shifted. Each one moves your scores by a small amount. The aggregate is the gap between “fine in CI” and “complaints in support.”
Ship four monitors at minimum:
- Score drift per route (rolling 7-day window vs prior 30-day baseline).
- Latency p95 and p99 per route.
- Cost per request per route (tokens × model price).
- Refusal rate per route (responses where the model declined).
Alert on relative change, not absolute thresholds. A 10 percent drop in groundedness on /support is a problem at any base rate. An absolute threshold misses slow drift.
Stratified sampling rules
Never sample uniformly in production. The default rules:
- 100 percent of spans where a guardrail tripped.
- 100 percent of spans on routes flagged high-risk.
- 100 percent of spans where the user gave negative feedback.
- 5 to 10 percent of remaining traffic, stratified by route.
- 1 percent of high-volume happy-path traffic for baseline drift.
Implement stratification at the worker queue, not at instrumentation. Capture every span (cheap), score a stratified slice (expensive). This is the inverse of the 2024 pattern where teams sampled at instrumentation and lost the underlying spans.
Security testing
OWASP LLM Top 10 2025 added four categories that need explicit coverage: System Prompt Leakage (LLM07), Vector and Embedding Weaknesses (LLM08), Misinformation (LLM09), and Unbounded Consumption (LLM10). Each one needs a fixture in tests/fixtures/safety.test.json and a sampler in production:
- Prompt injection tests through user input and retrieved content (LLM01).
- Sensitive information disclosure tests on PII-heavy prompts (LLM02).
- System prompt extraction attempts (LLM07).
- Embedding inversion and adversarial retrieval (LLM08).
- Misinformation and ungrounded claim detection (LLM09).
- Unbounded loop and tool-call cost runaway tests (LLM10).
The fixtures are not exhaustive. They are a smoke test. The production sampler is what catches the campaigns.
Reproducibility
If you cannot reproduce a failure, you cannot fix it. Capture enough context per span to replay: full prompt, full tool call inputs and outputs, model name and version, retrieval results, random seed if any. Eval results without enough context to replay the original span are a leaderboard, not a debugging tool.
The OTel GenAI semantic conventions cover most of this. The pieces they do not cover (retrieval results, scratchpad state, agent memory) need to be span attributes you set explicitly. Budget the storage; trace data is the substrate every other step runs on.
Common pitfalls
Six failure modes recur on most LLM testing setups.
Grading only the final response on a multi-step agent. A SequentialAgent passes response_match_score because the final answer mentions the right entity. Per-step inspection shows step 2 hallucinated and step 3 corrected for it by accident. Score per step. Use tool_trajectory_avg_score with EXACT or IN_ORDER matching. Add per-sub-agent groundedness checks.
Treating LLM-as-judge as ground truth without calibration. Judges have systematic biases: position bias on pairwise comparisons, length bias on free-form, overconfidence on confidently wrong answers. Calibrate against human labels monthly and report agreement rate. Do not gate on a judge with less than 85 percent agreement on the route in question.
Public benchmark theater. Public benchmarks set the floor of capability; private fixtures set the bar for shipping. Hold out a slice of your real production traces, label the outcomes you actually care about, and gate the merge on that slice. Public scores are marketing context, not capacity planning.
Sampling production uniformly instead of stratifying. Uniform sampling gives you noise. Stratify by route, segment, outcome, and risk class. Sample 100 percent of spans where a guardrail tripped or a user gave negative feedback. The stratified sample is what surfaces the failure modes worth optimizing.
Test fixtures that pass even when the agent is wrong. A tool_trajectory_avg_score with ANY_ORDER matching passes when the agent calls the right tools in the wrong sequence. A response_match_score with a 0.5 ROUGE threshold passes on word overlap that misses meaning. Use EXACT or IN_ORDER. Use 0.8+ thresholds. If those fail, the gate is the problem; lowering the threshold is not the answer.
Ignoring cost and latency in the gate. A prompt change that lifts groundedness 5 points but doubles tokens-per-call is not a win. CI should record cost and latency per fixture and gate on regression in either. Treat them as first-class scores alongside quality.
Tooling landscape
Six platforms cover the production-LLM-testing space. Each has tradeoffs. Pick by your dominant constraint.
FutureAGI. Apache 2.0 and self-hostable, with hosted cloud. The unified surface covers evals, observability, simulation, optimization, gateway routing (Agent Command Center), and 18+ runtime guardrails in one stack. The free tier is 50 GB tracing, 2,000 AI credits, 100,000 gateway requests, and 1M text simulation tokens. Worth flagging: the full self-hosted stack runs Postgres, ClickHouse, Redis, object storage, workers, and Temporal. If you only need a tracing dashboard, this is more infrastructure than you need.
Langfuse. Open-source core (MIT for most non-enterprise paths) with mature self-hosting and hosted cloud. The October 2025 testing post is the canonical statement of their three-component model: datasets, experiment runners, and evaluators, integrated through their SDK and pytest. Hobby tier free, Core $29/mo, Pro $199/mo. Worth flagging: Langfuse is observability-and-eval first; simulation, optimization, and gateway features need adjacent tools or in-house code.
Braintrust. Closed platform with a polished dev loop for structured evals, prompt iteration, trace-to-dataset workflows, online scoring, and CI enforcement. Starter free with 1 GB and 10,000 scores; Pro at $249/mo with 5 GB and 50,000 scores. Recent additions: Java auto-instrumentation, dataset snapshots, sandboxed agent evals, and the Loop AI assistant for generating test cases and scorers. Worth flagging: not OSI open-source, and pricing scales with score volume in a way that punishes naive online-scoring setups.
LangSmith. LangChain’s platform. Strongest fit when LangChain or LangGraph is the runtime. Pytest integration is first-class; online evals and dataset management are mature. Developer free with 5,000 base traces; Plus $39/seat/mo. Self-hosted available on Enterprise. Worth flagging: trace pricing per 1,000 base traces ($2.50) plus per-seat plus extended traces ($5/1,000) can stack quickly. Verify against your real volume before committing.
Arize Phoenix. Source-available under Elastic License 2.0, OTel-native, OpenInference-aligned. Free self-hosted; Phoenix Cloud and Arize AX (Pro at $50/mo) for hosted. Strongest for teams that want open standards and an Arize ML observability path. Worth flagging: ELv2 is not OSI open-source. Call it source available in procurement; it permits broad use but restricts hosted-managed-service offerings.
Helicone. Apache 2.0, gateway-first observability. Hobby free, Pro $79/mo, Team $799/mo. Strongest when the production issue is provider routing, caching, p95 latency, or cost attribution rather than dataset governance. Worth flagging: Helicone announced acquisition by Mintlify on March 3, 2026 with services in maintenance mode. Roadmap depth is now part of vendor diligence.
The honest summary. No platform is equally deep across every one of the six steps. FutureAGI is the broadest stack and the best bet if you want one loop. Langfuse is the OSS-first incumbent for steps 1-3 and 5. LangSmith is the LangChain native. Braintrust has the most polished step 3 dev loop. Phoenix is the OTel purist. Helicone is the gateway-first option. Pick by which step is your weakest link, then verify the others meet your floor.
How FutureAGI implements the six-step LLM testing loop
FutureAGI is the production-grade LLM testing platform built around the six-step playbook this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Instrument - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java (LangChain4j, Spring AI), and C#. Spans carry OpenInference and OTel GenAI semantic conventions natively, no wrapper required.
- Score - 50+ first-party metrics (Groundedness, Tool Correctness, Task Completion, Hallucination, PII, Toxicity, Refusal Calibration) ship as both span-attached scorers and CI gates.
turing_flashruns at roughly 1 to 2 seconds cloud latency,turing_smallat 2 to 3 seconds, andturing_largeat 3 to 5 seconds; BYOK lets any LLM serve as the judge at zero platform fee. - Gate - the eval suite is the CI surface: pytest-style harnesses, threshold gates per metric, and per-environment baselines stop a regression before it ships.
- Simulate, sample, optimize - persona-driven synthetic users exercise voice and text agents pre-prod, online sampling continuously scores production traces, and six prompt-optimization algorithms (GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random) consume failing trajectories as labelled training data.
Beyond the six steps, FutureAGI also ships the Agent Command Center gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams running the six-step loop end up running three or four tools in production: one for traces, one for evals, one for simulation, one for the gateway. FutureAGI is the recommended pick because all six steps live on one self-hostable runtime; the loop closes without stitching, and the same trace tree carries instrumentation, scores, and gate verdicts.
Sources
- OpenTelemetry GenAI semantic conventions
- OWASP Top 10 for LLM Applications 2025
- SWE-bench Pro paper, Scale AI Labs, September 2025
- LangSmith evaluation concepts
- Braintrust evaluation guide
- Arize Phoenix evaluation docs
- Helicone gateway docs
- FutureAGI ai-evaluation SDK
- FutureAGI traceAI on GitHub
- FutureAGI agent-simulate on GitHub
- FutureAGI agent-opt on GitHub
- Google ADK evaluation criteria
Series cross-link
Companion guides:
- How to Evaluate Google ADK Agents with FutureAGI for the framework-specific version of this loop.
- State of LLMs at the Application Layer 2026 for the production-pick context this playbook is gating against.
- Braintrust Alternatives in 2026 for the full vendor comparison referenced in the tooling section.
Related reading
Frequently asked questions
What is LLM testing in production, and how is it different from offline evaluation?
How much production traffic should I sample for LLM evaluation?
Is LLM-as-judge reliable enough for production gates?
Can I test multi-turn agent conversations the same way as single-turn LLM calls?
How does prompt optimization fit into the testing loop?
Do I still need pytest for LLM testing if I have a hosted eval platform?
What are the most common LLM testing pitfalls in 2026?
How do I avoid making LLM-as-judge the new bottleneck?

What LLM observability captures, what LLM evaluation scores, where the two overlap, and the seven axes that separate them in 2026 across vendors.


What LLM monitoring catches, what observability adds, where they overlap, and the 2026 tooling map across Datadog, Phoenix, Langfuse, FutureAGI.


FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.