LLM Tracing Best Practices in 2026: Span Hygiene, Sampling, and PII
LLM tracing best practices for 2026: OTel GenAI schema, span granularity, prompt-version tagging, tail sampling, PII redaction, cost attribution.

Table of Contents
A user complains that the support agent gave a wrong refund amount on Tuesday. The on-call engineer pulls the trace. Six spans. Two of them have the same span name. None of them carry the prompt version id. Three carry the user input as a free-text attribute, one of which contains an email address. The retriever span shows a query but not the chunks it returned. The tool span shows the tool name but not the arguments passed. The eval scorer ran but did not attach the score to the span. Forty-five minutes later the engineer has reconstructed roughly what happened. The post-mortem reaches one conclusion: the trace was instrumented; it was not instrumented well.
This piece walks through the 10 things that separate a usable LLM trace from one you wish you had. The recommendations are vendor-neutral, grounded in the OpenTelemetry GenAI semantic conventions, and tested against the operational shape of production LLM workloads in 2026.
TL;DR: 10 best practices
| # | Practice | What it prevents |
|---|---|---|
| 1 | OTel GenAI semantic conventions | Cross-vendor incompatibility, schema fragmentation |
| 2 | One span per meaningful operation | Flat unsearchable traces; missing parent-child structure |
| 3 | Tag prompt version on every LLM span | Inability to attribute regressions to a rollout |
| 4 | Tail-based sampling | Long-tail failures buried under uniform 1% sampling |
| 5 | Pre-storage PII redaction | Compliance risk, leak surface |
| 6 | Span-attached eval scores | Drift detection runs on the score stream |
| 7 | Stable span names | Aggregations breaking when spans rename |
| 8 | Cost attributes as first-class | Cost dashboards under-attributing reasoning and cache tokens |
| 9 | Tree-structured agent runs | Agent loops buried in flat span lists |
| 10 | Schema doc in repo | New engineers re-deriving conventions; drift across teams |
If you only read one row: prompt version on every LLM span. Without it, the production debug loop is broken at the most common entry point.
Why these practices matter in 2026
Two forces pushed LLM tracing from optional to mandatory.
First, agent runs got large. A single user request inside a real agent stack now generates 10 to 50 spans across LLM calls, retriever queries, tool invocations, guardrail checks, and sub-agent dispatches. Without span structure and parent-child relationships, debugging is grep over a log file. Tools like traceAI and OpenInference cover the instrumentation layer; the schema and sampling decisions are still on the team.
Second, cost and compliance moved into observability. Token-level cost attribution per user, per prompt version, per route, per feature flag is now an operational requirement, not a nice-to-have. PII redaction is a regulatory requirement for healthcare, finance, and EU workloads. Both ride on the trace schema. A trace stack that does not carry cost attributes and does not redact at the collector is a stack that fails the next audit.
The OTel GenAI semantic conventions name gen_ai.* attributes, gated by OTEL_SEMCONV_STABILITY_OPT_IN while the spec is in development. Tools that handle the version pinning gracefully and surface the schema in their UI look better than tools that silently drift across attribute renames.
The 10 practices
1. OpenTelemetry GenAI semantic conventions
Use the standard. The OTel GenAI semantic conventions name a gen_ai.* namespace with attributes covering operation type, provider, request and response models, token usage, response id, finish reasons, request parameters, and opt-in content fields. Vendors that emit these attributes and consume them are interchangeable at the trace layer. Vendors that emit proprietary attributes lock you in.
Two strong OTel-native instrumentation options: traceAI (Future AGI’s Apache 2.0 OTel-native framework, around 50+ integrations across Python, TypeScript, Java, C#) and OpenInference (Arize-maintained, around 31 Python packages plus JavaScript and Java coverage). Both emit OTLP and ship to any OTel backend. Pick by which integrations cover your framework set; many teams use both.
OTLP over HTTP or gRPC is the transport. Configure an OTel collector in front of the backend so you can filter, redact, route, and tail-sample at one point.
2. One span per meaningful operation
The right granularity:
- LLM call. One span per chat completion, embedding call, or text generation. Carries every gen_ai.* attribute.
- Tool call. One span per function or tool invocation. Carries tool name, arguments, return value, latency.
- Retriever. One span per vector search, BM25 query, or hybrid retrieval. Carries query, top-k chunks, similarity scores, index version.
- Sub-agent dispatch. One span per child agent invocation; the child’s spans nest under it.
- Guardrail. One span per input or output validator; carries rule name, verdict, modified payload if any.
- Evaluator. One span per online scorer; verdict attached as a span attribute.
- Custom business logic. One span per logically meaningful step you care about debugging.
The wrong granularity is one giant root span (no debuggability) or one span per function call (noise). Aim for the level at which a human engineer would describe the system: “the agent called the retriever, then the LLM, then a tool, then scored the output.”
3. Tag prompt version on every LLM span
If your traces do not carry the prompt version id, you cannot attribute regressions. Set the version id (resolved from the prompt registry; see Prompt Versioning) on every LLM call span as either gen_ai.prompt.version or a custom attribute. Tag user cohort and feature flag scope as well.
With these tags, the observability stack can filter spans by version, aggregate per-version metrics, and alert on per-version drift. Without them, the answer to “did the new prompt regress?” is “we do not know.”
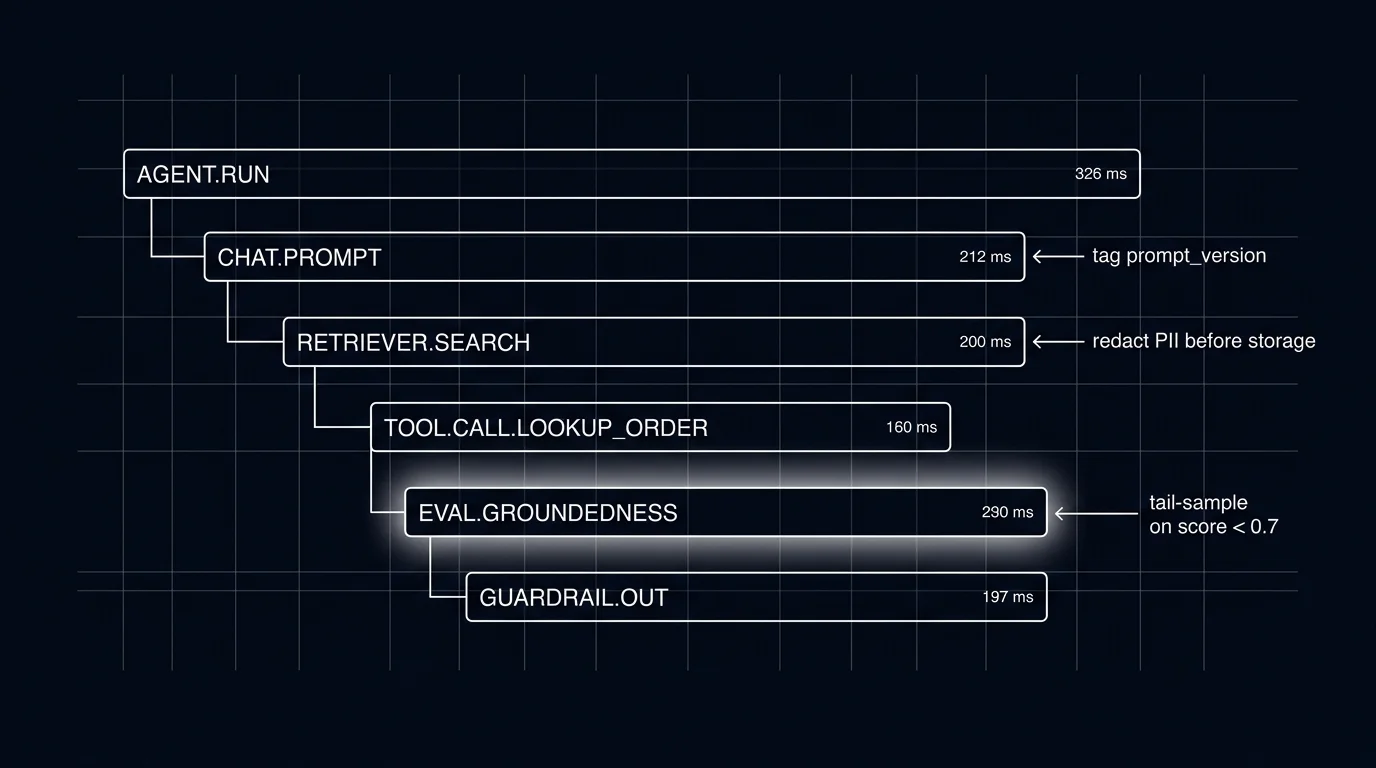
4. Tail-based sampling
Cost-driven head sampling at 1% hides the long-tail failures traces were meant to catch. The pragmatic pattern is tail-based sampling at the OTel collector: buffer the full trace, decide at the end whether to keep it.
A reasonable default policy:
- Keep 100% of traces with
status = ERROR. - Keep 100% of traces with any eval rubric below threshold.
- Keep 100% of traces above a fixed cost or latency threshold (top-percentile selection requires precomputed attributes or custom logic at the collector).
- Keep 100% of traces tagged with
experiment_idor with the canary cohort. - Sample 5-20% of remaining traffic uniformly for distribution analysis.
The buffer cost at the collector is the operational trade-off; on most workloads it is small relative to the value of catching every error.
5. Pre-storage PII redaction
gen_ai.input.messages and gen_ai.output.messages carry PII. The OTel spec marks them opt-in for that reason. Redact at the collector, not at the client. Defense in depth: the client may not know which messages contain PII; the collector applies a uniform policy.
Use a deterministic redaction function: emails become [EMAIL], phone numbers become [PHONE], the same value within a trace gets the same placeholder so post-hoc analysis can correlate without exposing the original. Document the redaction policy in the same repo as the instrumentation; review with privacy and security at design time.
For workloads under HIPAA, GDPR, or similar regimes, redaction is a hard requirement, not a recommendation.
6. Span-attached eval scores
Selected production spans (LLM outputs, final-answer spans, sampled traces) get scored, the score becomes a span attribute, and drift alerts ride on the score stream. Latency alerts catch infra; eval-score alerts catch quality.
The pattern: an online evaluator (heuristic, classifier, or sampled LLM judge) runs on the output, returns a per-rubric score vector, and tags the span with eval.groundedness=0.82, eval.refusal_calibration=0.91, etc. The drift detector watches rolling-mean rubric scores per route, per prompt version. When the mean drops below threshold, an alert fires.
See What is an LLM Evaluator? for which evaluator types fit which rubric and LLM-as-Judge Best Practices for the calibration discipline.
7. Stable span names
Span names are aggregation keys. Renaming agent.tool_call to tool.invoke between v17 and v18 breaks every dashboard and alert that aggregated on the old name. Lock down span name conventions early; document them; treat renames as breaking changes.
A reasonable convention: <component>.<operation> (e.g., retriever.search, agent.dispatch, guardrail.input). Use lowercase, dot-separated, stable.
8. Cost attributes as first-class
Token counts as first-class span attributes:
gen_ai.usage.input_tokensgen_ai.usage.output_tokensgen_ai.usage.cache_creation.input_tokensgen_ai.usage.cache_read.input_tokensgen_ai.usage.reasoning.output_tokens
Cache and reasoning attributes matter operationally. A reasoning model that uses 30K reasoning tokens before producing 500 visible output tokens is priced and budgeted differently from a non-reasoning chat call. If your trace schema collapses these into a single token field, your cost dashboards will under-attribute reasoning models and over-attribute cached calls. See LLM Cost Tracking Best Practices for the broader cost-attribution discipline.
Compute per-span cost on the way in (token counts times current price) and tag it as a span attribute. Avoids the recompute pass at query time.
9. Tree-structured agent runs
A LangGraph or CrewAI run is a tree. A flat span list buries the loop and the dispatch decisions. Force tree-structured trace views in your backend; if the backend renders agent runs as a flat list, file the bug or pick a different backend.
The parent-child structure is what makes “node ran X times in this loop” answerable. With a flat list, the question is unanswerable without manual span sorting.
10. Schema doc in the same repo as the code
Decide the schema once, document it in the repo, treat it as part of the code review. The schema document covers:
- Required attributes (set on every span)
- Conditional required (set on certain span types)
- Opt-in (PII; set only when the redaction policy permits)
- Custom dimensions (prompt version, user cohort, tenant)
- Span name conventions
Drift across teams is the failure mode this prevents. Two services that disagree on whether the user id is user.id or user_id produce traces you cannot join.
Common mistakes when implementing LLM tracing
- Treating tracing as logging with extra fields. It is not. The parent-child tree, the gen_ai.* schema, and span events are first-class.
- Sampling too aggressively at the head. 1% uniform head sampling hides the failures the trace was meant to catch.
- Not tagging prompt versions. If you cannot filter by version, you cannot attribute regressions.
- Forgetting redaction. PII in trace storage is a compliance incident waiting to happen.
- Using a proprietary SDK as the only path. A proprietary SDK on top of OTel is fine. A proprietary SDK instead of OTel is a switching cost waiting to be paid.
- Flattening agent traces. A LangGraph or CrewAI run is a tree.
- No span-attached eval scores. Latency alerts catch infra. Eval score alerts catch quality drift.
- Ignoring cache and reasoning tokens. Cost dashboards that collapse these under-attribute.
- Renaming span names. Aggregations break.
- Missing the schema doc. Drift across teams is inevitable without a shared reference.
Recent LLM tracing updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | OTel GenAI semantic conventions widely adopted | Cross-vendor trace compatibility achievable, though spec gated by OTEL_SEMCONV_STABILITY_OPT_IN |
| 2026 | Distilled judges hit production scale | Online scoring on every span became cost-tractable |
| 2026 | Tail-based sampling became the default | Default head sampling at 1% retired in favor of outcome-aware policies |
| 2026 | OTel collector tail-sample processor matured | Tail sampling at the collector became operational rather than research-grade |
| 2026 | Reasoning-token attributes named in OTel | Cost dashboards stopped under-attributing reasoning models |
How to actually instrument an LLM workload in 2026
- Pick the instrumentation library. traceAI or OpenInference. Emit OTLP. Configure once at service start.
- Define the schema. Required attributes, opt-in fields, custom dimensions. Document in the repo.
- Wire the collector. OTel collector in front of the backend; configure the redaction processor and the tail sampling processor.
- Tag prompt versions. Resolve the version id from the registry; tag every LLM call span.
- Add online evaluators. Score every production span; tag scores as span attributes.
- Build per-version dashboards. Latency, cost, eval scores, all sliced by prompt version.
- Wire drift alerts. Rolling-mean per rubric per route per version; page when delta crosses threshold.
- Verify the redaction. Run a redaction-leak test before going live. Repeat quarterly.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenTelemetry GenAI span attributes
- OpenTelemetry blog: GenAI conventions announcement
- traceAI GitHub repo
- OpenInference GitHub repo
- OTel collector tail sampling processor
- Datadog LLM Observability docs
- Phoenix docs
- Future AGI traceAI announcement
- Langfuse self-hosting docs
Series cross-link
Related: What is LLM Tracing?, LLM Cost Tracking Best Practices, Production LLM Monitoring Checklist, Self-Host LLMOps Guide
Related reading
Frequently asked questions
What does a good LLM trace look like in 2026?
What span granularity should I aim for?
Should I use OpenTelemetry directly or a vendor SDK?
How aggressive should I sample LLM traces?
How do I handle PII in trace data?
What span attributes should I always include?
How do I tag prompt versions on spans?
What does good LLM tracing cost in operational complexity?

OpenInference is the OpenTelemetry-aligned semantic convention and instrumentation library for LLM applications, maintained by Arize. 2026 fit explained.


Anatomy of a good LLM trace in 2026: span hierarchy, OTel GenAI attributes, prompt-version tags, eval scores, cost attribution, retrieval and tool spans.


LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.