What is an LLM Evaluator? The 5 Types Engineering Teams Use in 2026
An LLM evaluator scores model outputs: heuristic, classifier, judge, programmatic, human. The 5 types, when each fits, and how to combine them in 2026.

Table of Contents
A support agent answers a refund question. The output is grammatical, polite, and factually wrong. The user’s order id is real, the policy citation is fabricated, the proposed refund amount is off by 40%. Three evaluators look at this output. The heuristic scorer says PASS because the response is under 200 tokens and contains no banned words. The schema validator says PASS because the JSON parses. The LLM judge gives it 8 out of 10 because the prose is fluent and the structure looks helpful. None of them caught the hallucination. A fourth evaluator, a citation-grounder that diffs the cited policy id against the actual policy database, returns FAIL. The trace flips. The agent reroutes to a human.
This is what evaluator types are for. Different evaluators score different things. A stack that ships only one type misses the failures the others would catch. This guide covers the five evaluator types most production teams use in 2026, what each is good at, where each fails, and how teams combine them into a layered scoring stack.
TL;DR: Five evaluator types, picked by what you score
| Evaluator | Latency | Cost / call | Calibration | Best for |
|---|---|---|---|---|
| Heuristic | µs | $0 | None needed | Length, format, banned phrases, exact match |
| Schema validator | µs | $0 | None needed | JSON shape, Pydantic model, required fields |
| Classifier | ms | sub-cent | Labeled training set | Intent, refusal, toxicity, sentiment |
| LLM-as-judge | 100ms-2s | $0.001-$0.05 | Human gold-set monthly | Groundedness, helpfulness, tool-call appropriateness |
| Human | minutes-hours | $1-$10 | Inter-annotator agreement | Gold labels for calibration; subjective rubrics |
If you only read one row: heuristics and schema run on every output, classifiers run on a subset, judges run on a sampled subset, and humans review a small gold-set monthly. The combination beats any single type.
Why evaluator types matter in 2026
The naive view is that LLM-as-judge solves evaluation. Run a frontier model over the input plus output, ask it to score the response, and you have an evaluator. This works for a demo. It fails in production for three reasons.
First, cost. A frontier judge call at $0.02 per input plus output averages $0.02 per scored span. A workload at 10M spans per month is $200K per month in judge calls alone. Sampling helps but trades coverage for budget. Cheaper evaluator types reduce the load on the judge.
Second, latency. A judge call is 100ms to 2s of latency. Inline online scoring on the request path adds that to user-perceived response time. Heuristics and schema validators are microseconds and can run inline. Judges run async or on a sample.
Third, calibration. A judge that nobody ever recalibrates against human labels drifts. Different judge models reward different things. A judge from the same family as the generator often over-rewards its own outputs. Heuristics and schema do not have this problem because they have no opinion. Classifiers can be retrained on fresh labels.
Different evaluators have different failure shapes. Combining them is how production stacks reach the recall and precision they need without paying judge cost on every span.
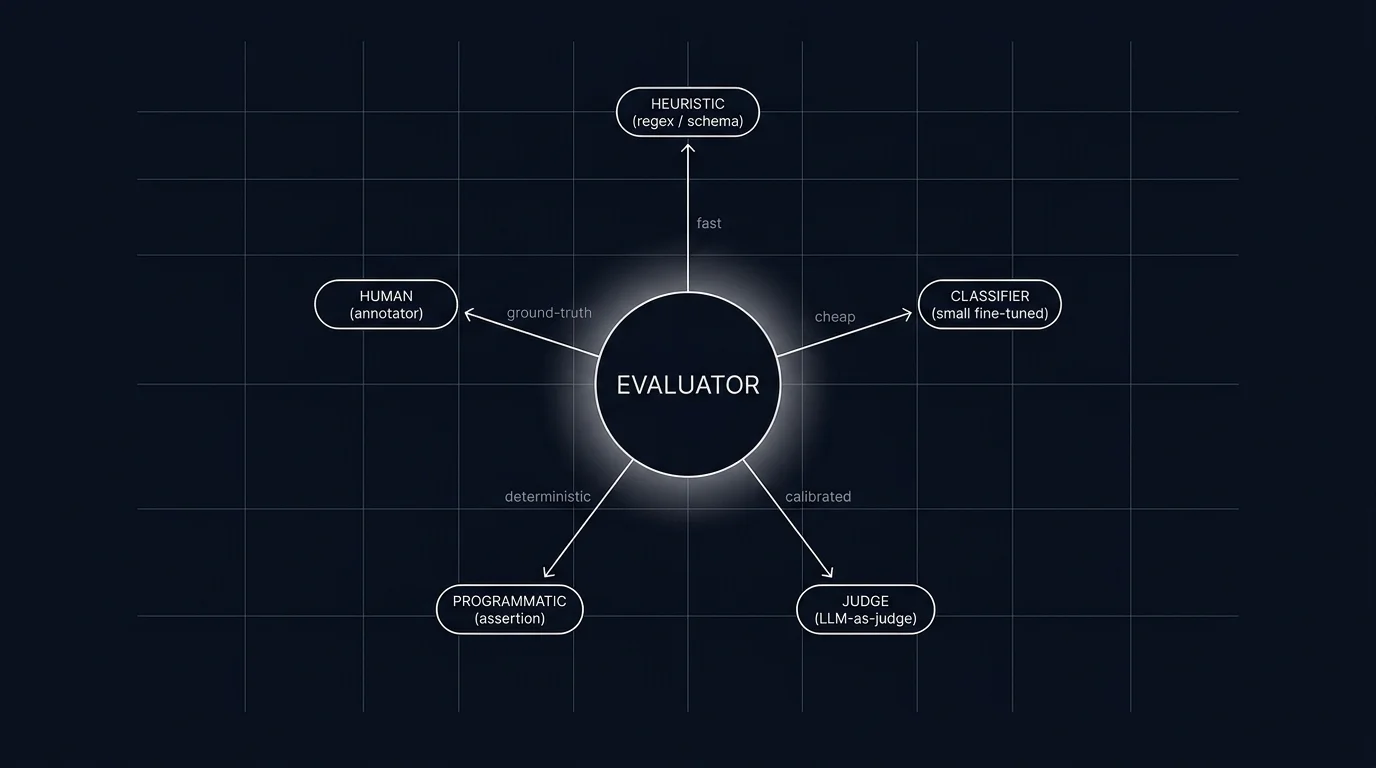
The five evaluator types
1. Heuristic
A heuristic evaluator is a deterministic function: regex, length, exact-match, presence-of-token, structural pattern. Heuristics are the cheapest evaluator type and the most reproducible.
What heuristics catch. Length violations (response under N tokens or over M). Banned phrase matches against a denylist. Exact-match against a known correct answer. Presence of required tokens (does the output mention the user id, the order id, the policy clause). Format checks (does the response start with a greeting, end with a citation block).
Where heuristics fail. Anything that requires understanding meaning. A regex for “refund denied” misses “we cannot process this refund at this time.” A length check passes a 150-token hallucination as easily as a 150-token correct answer.
Implementation. A library of small functions, each takes input plus output and returns a verdict. Execute on every span; cost is microseconds per call.
Tools. DeepEval ships built-in heuristics. The same patterns are trivial to roll yourself in Python or TypeScript and tag the result as a span attribute.
2. Schema validator
A schema validator checks structural correctness. For LLM workloads that emit JSON, function-call arguments, or otherwise structured output, schema validation is non-negotiable.
What schema catches. Malformed JSON. Missing required fields. Wrong types (integer where string expected). Extra fields not in the schema. Field values outside enum range. Argument name mismatches in function calls.
Where schema fails. Schema cannot tell you whether the values are correct. A schema validator says PASS for an object like order_id: FAKE-12345, refund: -50 if the schema admits any string and any number.
Implementation. Pydantic in Python, Zod in TypeScript, JSON Schema everywhere. The validator runs on every structured-output span, attaches a verdict, and surfaces failures to the trace.
Tools. Pydantic AI, OpenAI’s structured outputs feature, and Anthropic’s tool calling all surface schema violations natively. The trace integration is straightforward; tag the schema-validity verdict as a span attribute.
3. Classifier
A classifier evaluator is a small fine-tuned model that maps input plus output to a discrete label. The model is usually a small encoder (DistilBERT, a small open-source encoder, a tiny custom head over a frozen backbone). It is trained on labeled data specific to the rubric.
Where classifiers fit. Intent detection (was the user asking for a refund, an upgrade, or escalation). Refusal calibration (did the model refuse correctly given the policy). Toxicity (does the output contain toxic content). PII detection. Sentiment.
Strengths. 10-100x cheaper than a frontier judge per call. 10-100x faster. Deterministic given the same input. More stable than prompt-based judges on a fixed input distribution, though still subject to drift when the workload distribution shifts.
Weaknesses. Requires a labeled training set. Classifiers do not generalize beyond their label space; a classifier trained on three intents cannot score helpfulness. Classifier accuracy degrades when the input distribution shifts; periodic retraining is part of the operational cost.
Tools. Galileo Luna ships small distilled scorers for context adherence, completeness, chunk attribution, and similar RAG rubrics. Future AGI exposes the turing_flash model as its low-latency judge for common rubrics. Hugging Face Transformers and the OpenAI fine-tuning API both work for rolling your own.
4. LLM-as-judge
An LLM-as-judge evaluator passes the input plus output (and sometimes a reference answer or rubric) to a judge model and returns the score the judge produces. The judge is usually a frontier model, sometimes a smaller specialized one.
Where judges fit. Open-ended rubrics: helpfulness, groundedness, conciseness, tool-call appropriateness, refusal calibration in nuanced cases. Anything where you cannot enumerate the right answers but can describe a quality bar.
Strengths. Flexible. The same judge prompt covers many rubrics. No training data required (the rubric is the prompt). Pairs well with reference-free evaluation.
Weaknesses. Cost: frontier judges are $0.001-$0.05 per call. Latency: 100ms-2s. Drift: judges have biases (length bias, position bias, family bias when judging same-family outputs). Calibration is mandatory: compare judge scores against a human gold-set monthly and recalibrate the rubric or the judge model when delta exceeds threshold.
Tools. DeepEval, RAGAS, OpenAI evals, Future AGI, Braintrust, LangSmith, Phoenix all ship LLM-as-judge primitives. Differences are in rubric library, calibration tooling, and cost control.
See LLM-as-Judge Best Practices for the calibration discipline judges need to stay accurate over time.
5. Human
A human evaluator is an annotator who reads the input plus output and labels it according to a rubric. Humans are the most expensive evaluator type but they are the gold-set that calibrates everything else.
Where humans fit. Building the calibration set. Auditing borderline cases. Recalibrating the judge when scores drift. Domain rubrics where no algorithm captures expert intuition (legal correctness, medical safety, brand voice nuance).
Strengths. Highest accuracy on subjective rubrics. The reference truth other evaluators are tuned against.
Weaknesses. Slow (minutes per item). Expensive ($1-$10 per labeled item). Inter-annotator disagreement (different annotators score the same item differently; Cohen’s kappa or Krippendorff’s alpha measures the disagreement). Hard to scale.
Tools. Argilla, Label Studio, Future AGI’s annotation UI, and SuperAnnotate all ship annotation interfaces with rubric configuration, multi-annotator support, and disagreement metrics.
How to combine evaluators in production
A production scoring stack uses a layered approach. The pattern most teams converge on:
- Run heuristics and schema on every output. Cost is microseconds. The verdicts are attached as span attributes. Failures short-circuit downstream evaluators.
- Run a classifier on every output for fixed-label rubrics. Refusal calibration, intent, toxicity. Cost is sub-millisecond. Verdicts attached as span attributes.
- Run an LLM judge on a sampled subset. 5-20% of traffic, plus 100% of traces flagged by upstream evaluators (errors, low classifier confidence, length anomalies). Cost is bounded by the sample rate.
- Maintain a small human gold-set. 200-500 hand-labeled traces per workload, refreshed quarterly. The gold-set is the calibration baseline for the judge.
- Recalibrate the judge against the gold-set monthly. If judge agreement with humans drops below threshold (Cohen’s kappa under 0.6 is a common alarm), recalibrate the rubric or swap the judge model.
This gets you coverage at sustainable cost. Without the layering, either the cost is unbounded (judge on every span) or the coverage has gaps (heuristics-only on a workload that needs judge-level rubrics).
Common mistakes when picking evaluators
- Using only an LLM judge. Judges are expensive, slow, and biased. Use heuristics and schema to filter the easy cases first.
- Running judges inline on the request path. A 1-second judge call adds 1 second to user-perceived latency. Run judges async or on a sampled subset.
- No human gold-set. Judges drift. Without a gold-set you cannot detect the drift. The gold-set does not need to be huge; 200 items refreshed quarterly suffices for most workloads.
- Same-family judge bias. Using GPT-4 to judge GPT-4 outputs systematically over-rewards GPT-4. Use a different family or a distilled judge calibrated against humans.
- No recalibration cadence. A judge calibrated at launch and never revisited can drift as data, prompts, or models change. Schedule monthly recalibration.
- Ignoring inter-annotator agreement on the human gold-set. If two human annotators disagree on 30% of the gold-set, the gold-set is too vague to calibrate against. Tighten the rubric or accept higher delta tolerances.
- No span integration. Evaluator scores that do not attach to the trace cannot drive alerts. Tag every score as a span attribute and pipe to your observability backend. See What is LLM Tracing? for the trace schema.
- Hard-coding rubric prompts in code. Rubric prompts are prompts. Version them in the same registry as production prompts. See Prompt Versioning.
The future: where evaluators are heading
Distilled judges become the production default. Frontier judges work for the gold-set and the human-validated subset. Production scale runs on small distilled models (Galileo Luna, Future AGI Turing, OpenAI o-mini class judges) tuned for specific rubrics. Cost can drop substantially compared to frontier judges, with accuracy that depends on the rubric and the calibration set.
Composite scorers replace single-rubric outputs. A single PASS or FAIL is too coarse. Production stacks emit a vector of rubric scores per span (groundedness, helpfulness, refusal, tool-call accuracy, schema validity), and a composite policy decides the verdict. The vector is the input to alerts and dashboards; the composite is what gates rollouts.
Self-calibrating judges. Judges that ingest the human gold-set and adapt their rubric prompts automatically when scores drift are appearing. The pattern: the judge runs against the gold-set on a schedule, the system flags drift, and a meta-prompter rewrites the rubric prompt to restore alignment. Still early, watch the production results.
Programmatic and tool-grounded evaluators. Evaluators that diff a citation against the actual source document, that verify a tool was called with the right arguments, or that check that an SQL query returns the expected schema are joining the standard set. These run cheaper than a judge for specific verifiable claims.
Per-tenant rubrics. Enterprise customers ship their own rubrics. Evaluator stacks that handle per-tenant rubric overrides without forking the eval suite are the pattern most platforms are converging on.
The throughline: evaluation moves from “one judge to rule them all” to “a portfolio of evaluators picked by what you score.” The teams that get this right ship faster, debug regressions sooner, and pay less per scored span. See LLM Evaluation Architecture for the full layered architecture.
How to use this with FAGI
FutureAGI is the production-grade evaluator stack for teams running a portfolio of evaluators. The platform ships all five evaluator types in one workflow: 50+ rubric-bound LLM-judge templates with calibration tooling, the Turing family of distilled small judges (turing_flash runs guardrail screening at 50 to 70 ms p95), deterministic scorers (BLEU, ROUGE, BERTScore, regex/AST checkers, JSON-schema validators), an annotation UI for human labels with multi-annotator agreement metrics, and tool-grounded checkers that diff citations against source documents. Full eval templates run at about 1 to 2 seconds.
The Agent Command Center is where evaluator routing, calibration sets, and per-tenant rubrics live. The same plane carries persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Sources
- DeepEval docs
- RAGAS docs
- OpenAI Evals GitHub
- Anthropic prompt engineering: success criteria
- Future AGI evaluation platform
- Braintrust evals docs
- LangSmith evaluation docs
- Phoenix evaluation docs
- Galileo Luna docs
- Argilla annotation platform
Series cross-link
Related: What is LLM Tracing?, LLM-as-Judge Best Practices, LLM Evaluation Architecture, What is LLM Judge Prompting?
Related reading
Frequently asked questions
What is an LLM evaluator?
Are LLM-as-judge evaluators the only useful evaluator type?
When should I use a heuristic evaluator?
What is a classifier evaluator and where does it pay off?
When does an LLM-as-judge evaluator work and when does it fail?
Do schema validators count as evaluators?
How many evaluator types should I use per workload?
What does evaluator infrastructure cost in operational complexity?

Cost-efficient AI evaluation in 2026 is the cascade: classifiers, local heuristics, cheap judges. 7 platforms compared on per-eval cost.

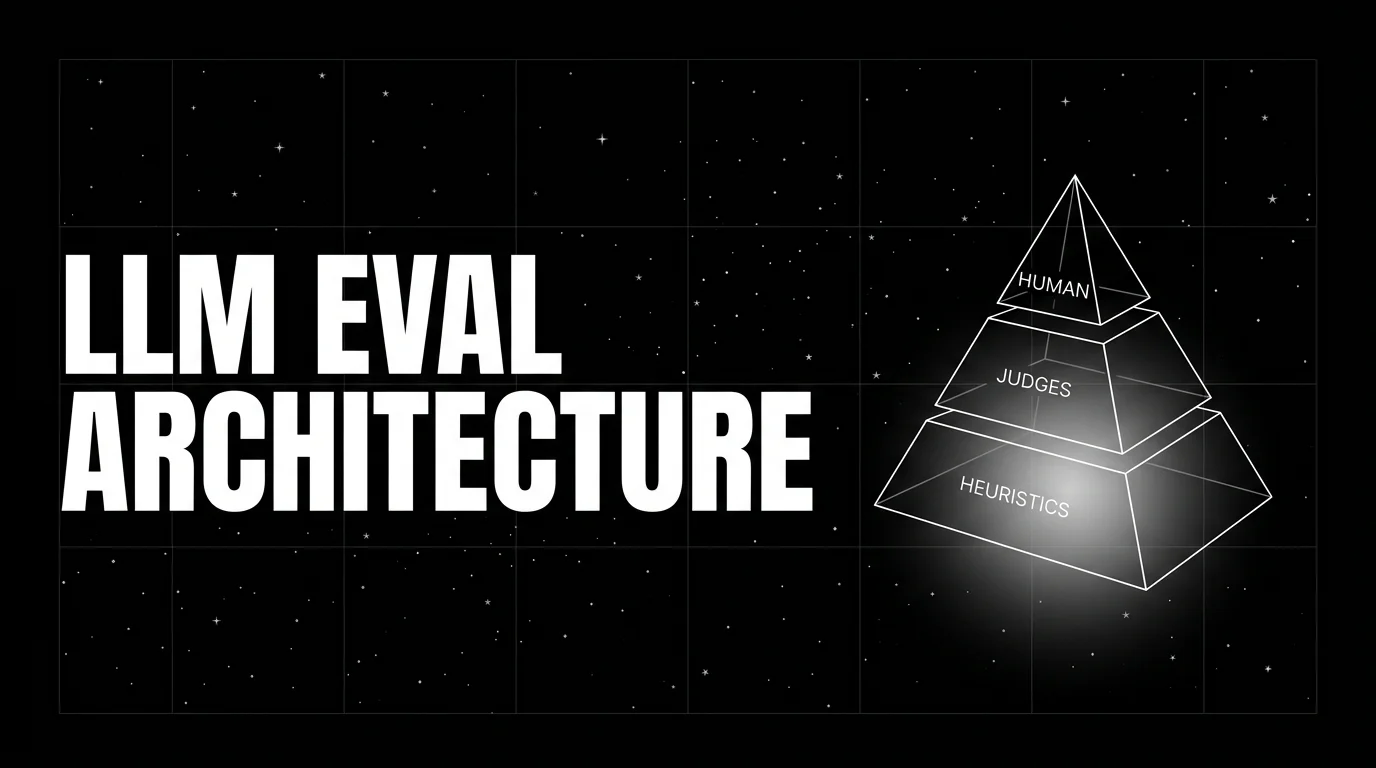
LLM eval architecture in 2026: heuristics on every span, distilled judges on a sample, humans on the gold-set. Three-tier stack that scales.

AUC-ROC measures ranking quality of a binary classifier. Applied to LLM-judge calibration, hallucination detection, guardrail screening. When it misleads.