Self-Host LLMOps in 2026: Postgres, ClickHouse, and the Architecture Tradeoffs
Self-hosting LLM observability in 2026: Postgres vs ClickHouse, OTel collector, queue, blob storage, K8s footprint, ARM. Vendor-neutral architecture guide.

Table of Contents
A team needs LLM observability inside its perimeter because the workload handles regulated healthcare data. The procurement team rejects every hosted option. The eng team gets the green light to self-host. Three months later the team has a working stack: Langfuse on ClickHouse plus Postgres, an OTel collector with a redaction pipeline, a Redis queue for ingest fanout, and a small worker pool for online judges. Total infrastructure cost: $620 per month for 8M spans per day. Total engineering cost: roughly 15% of one engineer’s time. The team would pay 4x that hosted, but hosted was not an option.
This piece is the architecture guide for that team. Vendor-neutral. The components are the same regardless of which OSS platform you pick. Postgres or ClickHouse, queue or no queue, K8s footprint, ARM versus x86, blob storage, OTel collector configuration. Where the platform choice matters, this piece names the trade-offs honestly without shilling one stack over another.
TL;DR: Four layers, two storage choices, one collector
Self-hosted LLMOps is four layers. The application layer emits OTel-native spans via traceAI, OpenInference, or a vendor SDK. The OTel collector receives, filters, redacts, tail-samples, and routes. The queue (Redis Streams, Kafka) buffers ingest and fans async work to evaluators. The storage layer holds spans (ClickHouse for high volume, Postgres for low volume), control-plane data (Postgres), and content (S3 or MinIO blob).
The two storage decisions matter most. Postgres is operationally familiar but caps around 1-5M spans per day. ClickHouse is the standard past that volume but adds operational learning curve. Most production-scale OSS LLMOps platforms run both: ClickHouse for spans, Postgres for control plane.
If you only read one paragraph: self-hosting is a real cost in engineering time and infrastructure. Pencil it out against hosted pricing before committing — the build vs buy analysis has the TCO model. Past 100M spans per month or with hard residency requirements, self-hosting becomes the default.
When self-hosting makes sense
Three scenarios.
**Compliance and residency.The data cannot leave the perimeter, and that rules out every hosted option. This is the most common reason teams self-host.
Volume and cost. Past 100M spans per month, hosted pricing climbs into a range where in-house engineering cost is competitive. Below 10M spans per month, hosted is almost always cheaper. The 10-100M range is where teams pencil out the trade.
Latency and locality. A workload in a region not served by the hosted vendor’s nearest backend. The latency from your application to the trace backend matters for tail-based sampling and online evaluator workflows.
When none of these apply, hosted is usually the right answer. Self-hosting takes engineering time you could spend on the workload itself.
The architecture in 2026
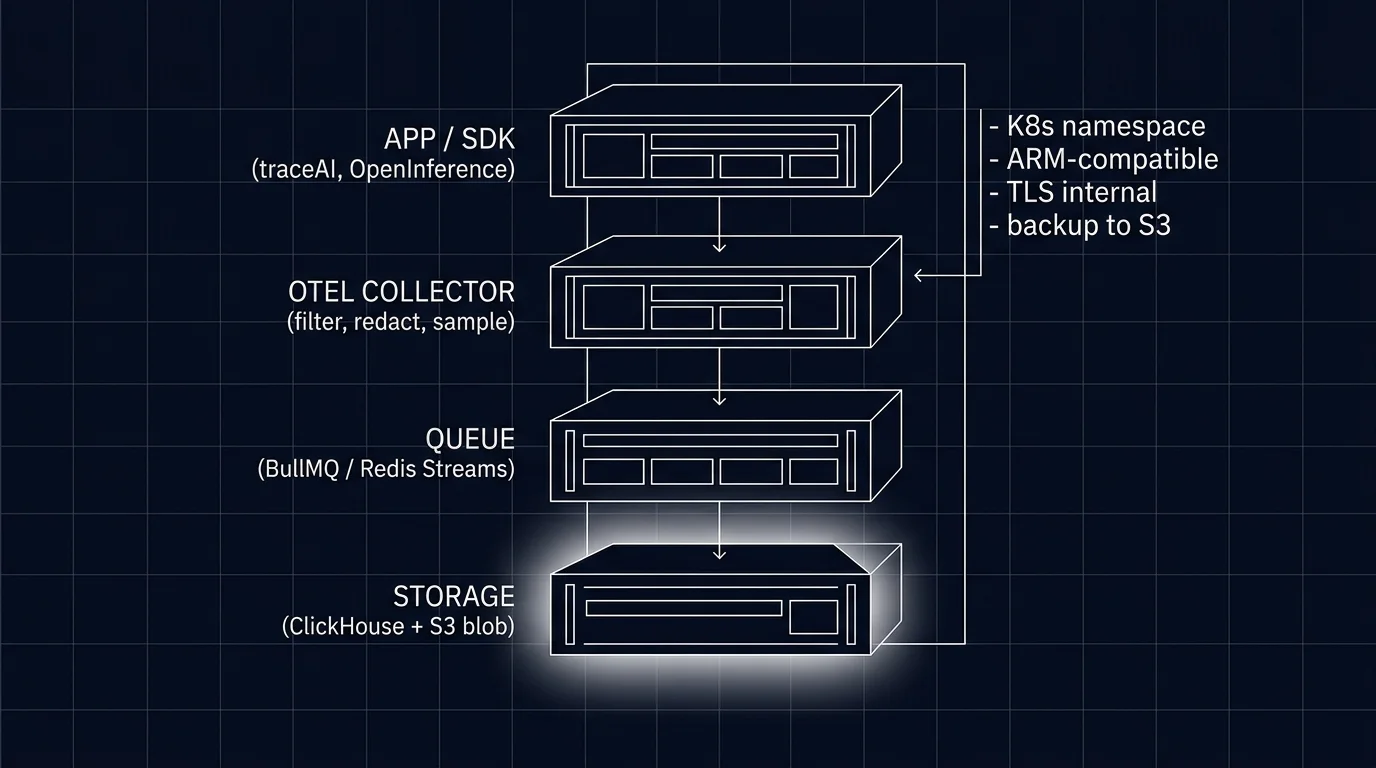
Application layer
Your services emit OTLP-native spans. Three viable instrumentation libraries:
- traceAI. Future AGI’s OSS framework. 50+ integrations across Python, TypeScript, Java (including LangChain4j and Spring AI), and a C# core library. OTel-native, OTLP exporters, ships traces to any OTel backend. See the GitHub repository for the current compatibility matrix.
- OpenInference. Arize’s framework. Around 31 Python instrumentation packages, 13 JavaScript, 4 Java. Complementary to OTel GenAI conventions.
- Vendor SDK. Langfuse SDK, LangSmith SDK, Helicone SDK, etc. Some are OTel-native; some emit proprietary formats.
For self-hosting flexibility, prefer OTel-native instrumentation. A proprietary SDK couples your instrumentation to one backend; OTel-native lets you swap backends.
OTel collector
The collector is where most of the operational policy lives. Functions:
- Receive. OTLP HTTP and gRPC endpoints. The application points at the collector.
- Filter. Drop spans matching exclusion rules (health checks, internal endpoints).
- Redact. Apply redaction processors to PII-bearing attributes (gen_ai.input.messages, gen_ai.output.messages). Deterministic placeholder per value.
- Tail-sample. Buffer the full trace; decide at trace end. Keep all errors, low scores, top-cost, experiment cohorts; sample 5-20% of the rest.
- Route. Send to one or more backends (your storage, plus optionally a vendor backend for parallel comparison).
The OTel collector contrib distribution ships the tail sampling processor, the attribute redaction processor, and many others. Configuration is YAML; deployment is a stateless K8s deployment that scales horizontally.
Queue
The queue absorbs spikes and decouples ingest rate from storage write rate. Two viable patterns:
- Redis Streams. Used by Langfuse and others. Lightweight, easy to operate. BullMQ on top adds job queue semantics for async eval workers.
- Kafka. The JVM-stack default. Higher throughput ceiling, more complex to operate.
The queue also fans out async work: online evaluators consume from the queue and produce score events; drift detectors consume from the queue and update rolling means; cost calculators consume from the queue and update per-user totals.
For workloads under 50M spans per day, Redis Streams is sufficient. Past that, Kafka starts to look better.
Storage
Two decisions: span storage and control-plane storage.
Span storage: Postgres or ClickHouse
Postgres. Familiar, durable, transactional. Works up to roughly 1-5M spans per day with careful indexing on (trace_id, span_id, parent_span_id, timestamp) and partitioning by day or by week. Past 5M spans per day, query latency degrades and storage cost climbs.
Workloads where Postgres-only is appropriate: small internal tools, prototype workloads, regulated environments where ClickHouse is not approved.
ClickHouse. Columnar analytical store, designed for the trace-search workload shape. Comfortably handles 100M+ spans per day on a single shard; sharded clusters scale further. Storage cost is 5-10x lower than Postgres for the same data. Query latency on common trace-search patterns is 10-100x faster.
The trade-off: ClickHouse has a steeper operational learning curve. Schema migrations are different (ALTER on a 100M-row table is operationally distinct). Backup and restore needs the right tooling. The right DBA-day-one investment is worth the ROI; without that, ClickHouse can become a source of operational risk.
Most production LLMOps platforms (Langfuse, Future AGI’s open-source stack) run ClickHouse for spans and Postgres for control plane. Phoenix runs Postgres-first, which fits its lighter-weight profile.
Control-plane storage
Postgres for users, projects, prompts, configs. Standard Postgres ops. Backup with pg_dump or wal-g; replication with logical or streaming.
Blob storage
S3 or MinIO for prompt and completion bodies. The body is large (kilobytes per span); storing it inline in ClickHouse or Postgres bloats the hot tables. Store an S3 reference in the span row; the body lives in object storage.
Lifecycle: hot for 30-90 days in S3 standard, then transition to S3 IA or Glacier. Trace queries that need the body re-fetch from object storage on demand.
Worker tier
The worker tier consumes from the queue and runs:
- Online evaluators. Pull a span sample, run the judge, write the score back as a span attribute or a separate score event.
- Drift detectors. Compute rolling-mean rubric scores per route, per version, per cohort; emit alerts.
- Cost calculators. Aggregate token-cost per user, per tenant, per route; emit budget alerts.
- Scheduled jobs. Daily cleanups, retention enforcement, calibration runs.
Workers are stateless; horizontal scaling adds throughput. Memory pressure depends on the judge model; the smallest distilled judges run in 50-150ms with modest memory footprint.
OSS LLMOps platforms compared honestly
For a deeper ranking of these stacks, see best self-hosted LLM observability in 2026.
| Platform | License | Storage | OTel posture | Footprint | Notes |
|---|---|---|---|---|---|
| Langfuse | MIT (core) | ClickHouse + Postgres | OTLP-compatible (gateway) | Mid (4-6 services) | Largest OSS LLMOps community; ClickHouse is the heavy dependency |
| Phoenix | ELv2 | SQLite default; PostgreSQL for production | OTLP-native | Small (2-3 services) | Lighter weight; better for low-volume workloads |
| Future AGI traceAI + OSS backend | Apache 2.0 | ClickHouse + Postgres | OTLP-native | Mid | Tighter integration between instrumentation and backend |
| Helicone (self-host) | Apache-2.0 | ClickHouse + Postgres | OpenAI proxy SDK; check current OTLP support before adopting | Mid | Gateway-first design; trace surface integrated with gateway |
| Lunary | Apache-2.0 source | Postgres | OTel via SDK | Small | Apache-2.0 source; production Docker self-host packaging is Enterprise-gated, verify before adoption |
The license differences matter for some workloads. Apache 2.0 (Future AGI, Helicone, Lunary) is the most permissive. MIT (Langfuse core) is similar but watch the enterprise edition split. ELv2 (Phoenix) permits free self-hosting on your own infrastructure; it restricts offering Phoenix itself as a hosted/managed service and tampering with license-key or notice functionality.
The deploy footprint matters at scale. Langfuse and Future AGI’s stack and Helicone all assume ClickHouse, which is a meaningful operational dependency. Phoenix and Lunary on Postgres are lighter to operate but cap out at lower span volume.
Recent self-hosted llmops updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | OTel GenAI semantic conventions broadly supported by major instrumentation libraries (still Development status) | Cross-platform compatibility at the trace layer |
| 2026 | ARM64 images mainstream across all major LLMOps platforms | Graviton and Apple Silicon support without compatibility shims |
| 2026 | Tail-sampling processor in OTel collector contrib distribution (beta for traces) widely deployed | Outcome-aware sampling moved closer to off-the-shelf |
| 2026 | ClickHouse cloud and self-managed both saw schema improvements for trace data | Span ingestion latency and query patterns improved |
| 2026 | EU AI Act enforcement phase began | Audit-trail and PII-redaction requirements pushed more workloads to self-hosting |
Common mistakes when self-hosting
- Underestimating ClickHouse operational complexity. Schema changes on multi-billion-row tables are operationally distinct from Postgres. Plan for a DBA day-one.
- Skipping the queue layer. A spike in trace volume without buffering drops spans or kills the storage. The queue is not optional past trivial volume.
- Storing prompt bodies inline. Bloats hot tables. Use blob storage with S3 references.
- No backup discipline. Backups for ClickHouse, Postgres, and the OTel collector configuration. Test restores quarterly.
- Forgetting the control plane. Users, projects, prompts, configs. Treat with the same backup and HA discipline as the application data.
- No tail-sampling configuration. Default head sampling at 1% hides the failures.
- PII redaction at the client only. Defense in depth; redact at the collector as well.
- No retention policy. Storage cost grows linearly with retention. Configure lifecycle from day one.
- Single-tenant ClickHouse without sharding plan. Past 100M spans per day, the path forward is sharded ClickHouse; plan it before you need it.
- Pinning to a vendor SDK. A proprietary SDK couples instrumentation to one backend; OTel-native instrumentation lets you swap.
How to actually deploy self-hosted LLMOps in 2026
- Pencil out hosted vs self-hosted. Hosted price for your span volume vs (infrastructure + 15% of one engineer’s time). Self-host only when one wins clearly.
- Pick the platform. Langfuse, Phoenix, Future AGI, Helicone, Lunary. Match storage architecture to volume.
- Provision storage day-one. ClickHouse cluster (or Postgres for low volume); Postgres control plane; S3 or MinIO blob.
- Wire the OTel collector. Receive, redact, tail-sample, route. Configuration in repo.
- Add the queue. Redis Streams or Kafka. Connect the collector and the workers.
- Deploy the API service and UI. Per the platform’s deploy guide.
- Wire the worker tier. Online evaluators, drift detectors, cost calculators.
- Configure backups. Both span storage and control plane. Test restore.
- Configure retention. Lifecycle policies on hot and blob storage.
- Run a chaos drill. Drop a backend node; verify the queue absorbs and the cluster recovers.
Sources
- OpenTelemetry GenAI semantic conventions
- OTel collector contrib distribution
- OTel collector tail sampling processor
- Langfuse self-hosting docs
- Phoenix self-hosting docs
- Future AGI GitHub repo
- traceAI GitHub repo
- Helicone self-hosting
- Lunary GitHub
- ClickHouse documentation
Series cross-link
Related: LLM Tracing Best Practices, What is LLM Tracing?, Production LLM Monitoring Checklist, LLM Cost Tracking Best Practices
Frequently asked questions
When does self-hosting LLM observability make sense?
What is the minimum architecture for self-hosted LLM observability?
Postgres or ClickHouse for trace storage?
What does the OTel collector actually do?
What about the queue layer between collector and storage?
What is the K8s footprint for a self-hosted LLMOps stack?
What are the operational costs of self-hosting?
Which OSS LLMOps platforms are deployable self-hosted?

Langfuse, Phoenix, Helicone, OpenLIT, Lunary, Comet Opik, and FutureAGI ranked on deploy footprint, scale ceiling, and self-host operational cost.


LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.