What is OpenInference? OpenTelemetry for LLM Apps in 2026
OpenInference is the OpenTelemetry-aligned semantic convention and instrumentation library for LLM applications, maintained by Arize. 2026 fit explained.

Table of Contents
A team adds tracing to their LangChain RAG pipeline. Naive logging would be: print the prompt, print the model name, print the response, print the latency. Useful at hello-world scale. Useless at production scale. The team wants the full span tree: which retriever query ran, which embedding model returned what, which LLM call made which tool call, what the eval score was, what the cost was. They could write all of this themselves and re-do it for every framework upgrade, or they could install one package, register one instrumentor, and have every LangChain call automatically emit OTel-aligned spans with the right attribute names. The package is OpenInference.
This piece walks through what OpenInference is, the semantic conventions, the instrumentation surface, how it relates to OTel GenAI, and how it compares with traceAI, OpenLLMetry, and OpenLIT in 2026.
TL;DR: What OpenInference is
OpenInference is an OpenTelemetry-aligned semantic convention and instrumentation framework for LLM applications, maintained by Arize. It defines a set of attribute names (the openinference.* and llm.* namespaces) for LLM spans and ships drop-in auto-instrumentation packages across many LLM providers, agent frameworks, and RAG libraries. The instrumentations are Apache 2.0 licensed at Arize-ai/openinference and emit OTLP spans that any OTel backend can consume. Phoenix is Arize’s reference OSS backend for OpenInference traces; FutureAGI, Datadog, Grafana, Jaeger, and any other OTel-compatible system also work. Coverage is broadest in Python, with JavaScript / TypeScript and Java (LangChain4j, Spring AI, plus core) packages also shipped. OpenInference predates the OTel GenAI semantic conventions and remains complementary; some instrumentations emit attributes from both namespaces, but dual emission is per-package so verify before relying on it.
Why OpenInference exists
Three forces converged.
First, LLM applications produce a different shape of trace than HTTP services. An HTTP span carries http.method, http.status_code, http.url. An LLM span needs the prompt, the completion, the model name, the token counts, the temperature, the tool definitions, the retriever query, the embedding vectors. There was no standard for those attributes when LLM apps started shipping in 2023.
Second, every framework had its own instrumentation pattern. LangChain shipped callbacks. LlamaIndex shipped event handlers. CrewAI shipped a step listener. The patterns differed; the attribute names differed; the spans were not interoperable. A trace from LangChain could not be merged with a trace from LlamaIndex without a lot of glue.
Third, OpenTelemetry’s GenAI semantic conventions did not exist yet. The OTel project started the gen_ai.* namespace in 2024 and shipped initial versions in 2025; OpenInference filled the gap from 2023 with a parallel namespace and instrumentations. By 2026 the two namespaces are converging, with OpenInference instrumentations emitting both sets of attributes for backward compatibility.
OpenInference helped standardize span attributes across LLM frameworks and OTel-compatible backends. The attribute namespace lets one tool query traces from many frameworks consistently; the instrumentations let teams adopt observability without writing per-framework boilerplate.
How OpenInference fits in
Three layers.
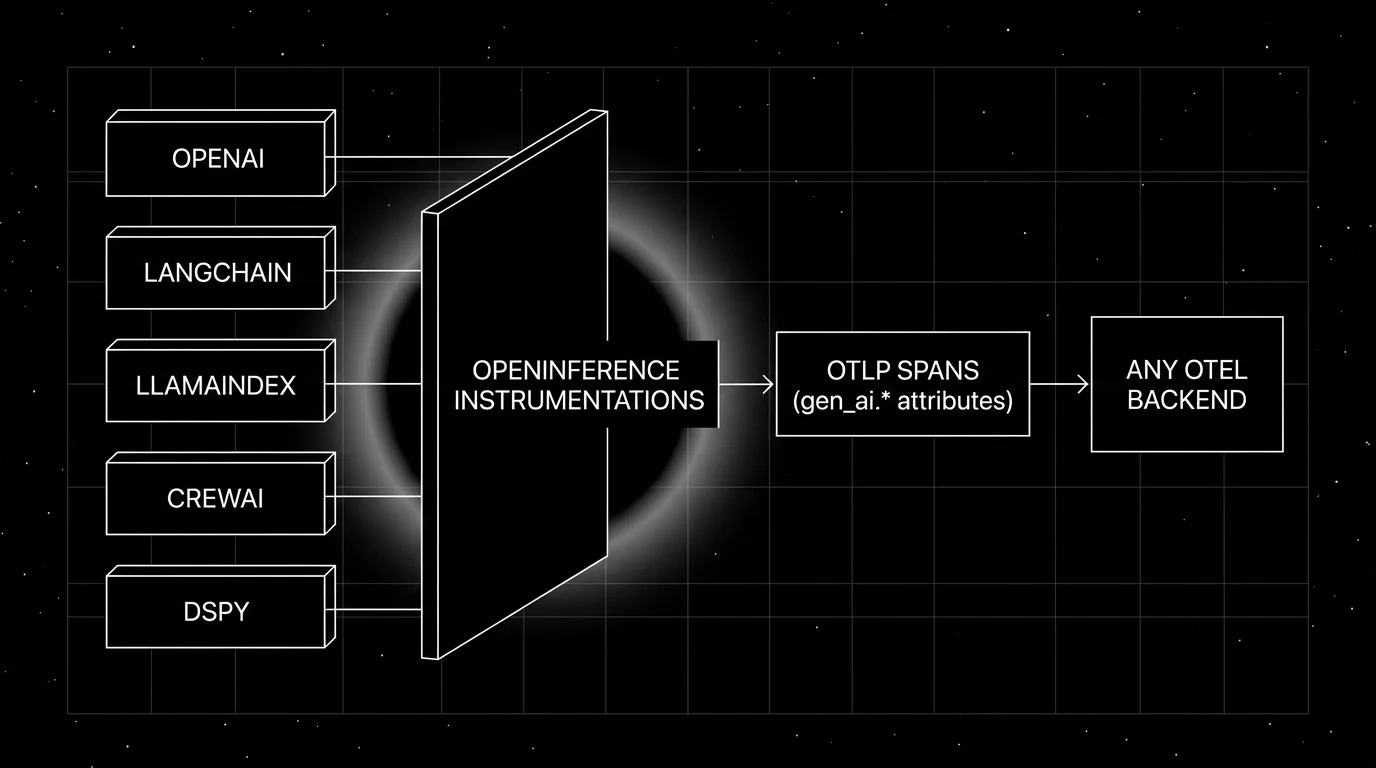
- Frameworks and providers are what your application calls: OpenAI, Anthropic, LangChain, LlamaIndex, CrewAI, DSPy, etc.
- OpenInference instrumentations monkey-patch the framework or provider client to emit spans. One pip install plus one
Instrumentor().instrument()call. - OTLP transport carries the spans to any OTel backend.
The instrumentations are decoupled from the backend. The backend can be Phoenix, FutureAGI, Datadog, Grafana, Tempo, Jaeger, or anything that speaks OTLP.
The semantic conventions
OpenInference defines attribute names under the openinference.* namespace plus a set of legacy LLM-specific names. The most-used attributes:
Span kind
Every OpenInference span carries openinference.span.kind. Well-known values:
LLM: a call to a chat or completion endpointCHAIN: a multi-step orchestration unit (LangChain chain, LlamaIndex query engine)RETRIEVER: a vector search or BM25 retrieverEMBEDDING: an embedding generation callTOOL: a function or tool invocationAGENT: an agent run (top of an agent loop)RERANKER: a re-ranker over retrieved chunksGUARDRAIL: a pre or post guardrail checkEVALUATOR: an online eval score
LLM-specific attributes
llm.model_name,llm.providerllm.input_messages,llm.output_messagesllm.token_count.prompt,llm.token_count.completion,llm.token_count.totalllm.temperature,llm.top_p,llm.max_tokensllm.tools,llm.invocation_parametersllm.system_prompt
Retrieval-specific attributes
retrieval.documents: list of retrieved documents with content and scoreretrieval.query: the search queryembedding.embeddings,embedding.model_name
Generic input / output
input.value,input.mime_typeoutput.value,output.mime_type
The conventions overlap with the OTel GenAI gen_ai.* namespace; recent OpenInference instrumentations emit both.
The instrumentation surface
The Python repo includes packages for:
- LLM providers: OpenAI, Anthropic, Bedrock, Groq, MistralAI, VertexAI (Gemini), LiteLLM, OpenAI Agents
- Agent frameworks: LangChain, LlamaIndex (and Workflows), CrewAI, Agno, AutoGen (incl. AgentChat), PydanticAI, Smolagents, BeeAI, Google ADK
- RAG libraries: Haystack, LlamaIndex retrievers
- DSL frameworks: DSPy, MCP
The JavaScript / TypeScript surface covers OpenAI, Anthropic, Vertex, Bedrock, LangChain JS, LlamaIndex JS, plus core. The Java surface covers LangChain4j and Spring AI.
Every package follows the same shape:
from openinference.instrumentation.openai import OpenAIInstrumentor
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
provider = TracerProvider()
provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(endpoint="https://your-backend/v1/traces")))
trace.set_tracer_provider(provider)
OpenAIInstrumentor().instrument()
# Now every openai client call emits a spanFor multi-framework apps you call multiple instrumentors. They compose; LangChain inside OpenAI inside CrewAI all emit nested spans without conflict.
OpenInference vs OTel GenAI
The relationship is the most-asked question.
OpenInference (2023+) and OTel GenAI (2024+) are parallel attribute namespaces with significant overlap. Some OpenInference instrumentations emit or map to OTel GenAI attributes, so a span can carry both llm.model_name and gen_ai.request.model, llm.token_count.prompt and gen_ai.usage.input_tokens. Coverage is per-package; OTel GenAI itself is still under active development. Backends that query either namespace work where dual emission is enabled.
Long-term direction: OTel GenAI graduates from development status, the wider ecosystem standardizes on gen_ai.*, and OpenInference’s namespace becomes a superset that adds non-LLM-call attributes (retrieval, eval, agent kind) the OTel GenAI spec does not cover. OpenInference is not “deprecated by OTel GenAI” in any practical sense; it stays the broader instrumentation framework around the OTel GenAI core.
How OpenInference compares with other LLM instrumentation frameworks
A practical map.
- traceAI (FutureAGI). Comparable in goals: OTel-native instrumentation, 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel) across Python, TypeScript, Java, and C#, including LangChain4j and Spring AI on the Java side. Apache 2.0 on GitHub.
- OpenLLMetry (Traceloop). Pure OTel GenAI alignment. Python and TypeScript packages. Slightly different abstraction (auto vs decorator).
- OpenLIT. Broad-vendor with multi-signal coverage (LLM + GPU + DB). Single SDK with broad provider support, OTel-aligned.
- Lilypad (Mirascope). Prompt-versioning-as-traces angle; treats every prompt change as a traced version.
- Vendor-specific SDKs. Langfuse SDK, LangSmith SDK, Helicone SDK, Datadog LLM SDK. Tied to one backend; emit spans the vendor consumes natively.
The instrumentations are interchangeable for many production setups. Many teams run OpenInference plus one or two vendor-specific SDKs in parallel during a migration. The choice often comes down to: does the framework you use have a mature instrumentation in the project, and does your observability backend prefer one namespace over another?
Production patterns
Three that show up.
1. Multi-framework, single observability backend
App uses LangChain for the agent loop, LlamaIndex for the retriever, OpenAI for the LLM, and a custom tool layer. Install OpenInference instrumentations for all four. Spans nest correctly in one trace tree. Backend (Phoenix, FutureAGI, Datadog, etc.) consumes one OTLP stream.
2. Migration to standardized namespaces
Team has older custom instrumentation with proprietary attribute names. Add OpenInference instrumentations alongside; spans now carry both old and new attribute names; queries shift gradually to the OpenInference namespace; old instrumentation removed.
3. Cross-language correlation
Frontend in JavaScript calls a backend in Python that calls Java microservices. OpenInference JS, Python, and Java instrumentations all emit spans with the same openinference.span.kind and aligned attribute names. The trace tree merges across languages without manual stitching.
Common mistakes
- Installing the instrumentation but not registering an exporter. Spans are emitted but go nowhere. Always set up an OTLP exporter.
- Multiple TracerProviders. Two libraries register two providers; one wins; the other’s spans are dropped. Configure the global provider once at app start.
- Capturing prompt content in production without redaction.
llm.input_messagesandllm.output_messagescarry PII. Add a span processor that redacts before export. - Sampling at 1% uniform head sampling. Loses the long-tail failures the trace was meant to catch. Use tail-based sampling with rules for errors, low eval scores, and high cost.
- Mixing instrumentor versions. OpenInference packages version independently. Pin all of them and bump together.
- Skipping the instrumentor on the client side of a multi-language app. A trace that starts in unsourced JS and continues in instrumented Python has a missing root span and confuses backends. Instrument the entry point.
- Treating OpenInference as a backend. It is not. OpenInference is the convention and the instrumentation. The backend (Phoenix, FutureAGI, Datadog) is separate.
- Ignoring the openinference.span.kind attribute when querying. Without it, the same backend sees retriever spans and LLM spans as undifferentiated. Filter by span kind.
How FutureAGI implements OpenInference observability and evaluation
FutureAGI is the production-grade backend for OpenInference-instrumented stacks built around the closed reliability loop that other OpenInference backends stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- OpenInference ingest, the FutureAGI collector ingests
openinference.*,llm.*, andgen_ai.*namespaces natively over OTLP; traceAI (Apache 2.0) is the sibling instrumentation library that covers the broader Java surface (LangChain4j, Spring AI) and a C# core where OpenInference coverage is lighter, with auto-instrumentation for 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel). - Span-attached evals, 50+ first-party metrics attach as span attributes filtered by
openinference.span.kind; BYOK lets any LLM serve as the judge at zero platform fee, andturing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise OpenInference-instrumented frameworks in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, and 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams standardizing on OpenInference end up running three or four backend products in production: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because OpenInference ingest, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- Arize-ai/openinference on GitHub
- OpenInference docs
- OpenInference semantic conventions
- Phoenix on GitHub
- Phoenix docs
- OpenTelemetry GenAI semantic conventions
- OpenLLMetry on GitHub
- OpenLIT on GitHub
- traceAI on GitHub (Apache 2.0)
- OpenInference releases
Series cross-link
Related: What is LLM Tracing?, What is LLM Observability?, What is LiteLLM?
Frequently asked questions
What is OpenInference in plain terms?
How does OpenInference relate to OpenTelemetry GenAI semantic conventions?
Is OpenInference free and open source?
What does OpenInference cover?
How does OpenInference compare with traceAI, OpenLLMetry, OpenLIT, and Lilypad?
What is the openinference.* attribute namespace?
How do I instrument my app with OpenInference?
How are OpenInference packages versioned?

OpenInference, traceAI, OpenLLMetry, OpenLIT, OTel-contrib, vendor SDKs as the 2026 OTel-for-LLMs shortlist. License, language, gen_ai.* support.


Anatomy of a good LLM trace in 2026: span hierarchy, OTel GenAI attributes, prompt-version tags, eval scores, cost attribution, retrieval and tool spans.


LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.
