What is Prompt Versioning? Registries, Labels, and Rollback in 2026
Prompt versioning treats prompts as code: unique ids, environment labels, eval-gated rollouts, one-call rollback. What it is and how to ship it in 2026.

Table of Contents
A prompt change ships at 4pm on Tuesday. It clears code review, lands in main, deploys to production. By 4:18pm, agent groundedness is down 14%, refusal rate has flipped from 4% to 27%, and the customer support team is fielding angry emails. The on-call engineer asks: “what was the prompt before this change?” Nobody knows. The git blame points to a 200-line refactor that touched the prompt and four other files. The rollback path is a code revert that also reverts the four other files. By 5pm the team is running a half-revert and praying nothing else regressed.
This is the failure mode that prompt versioning exists to prevent. Prompts that live in code share the deploy lifecycle of code. The fix is to treat prompts the way you treat configuration: as named, versioned, labeled artifacts that promote and revert independently of the code that calls them. This piece walks through what prompt versioning is, what primitives it depends on, how teams implement it in 2026, and the failure modes you can avoid by getting it right at week one.
TL;DR: Prompts as a first-class versioned artifact
Prompt versioning treats every revision of every prompt as a uniquely identified artifact with metadata: an id, a parent, an author, a timestamp, an eval pass-rate vector, a deployment status, and the set of labels currently pointing to it. The application resolves a label like support_agent@prod to a concrete version id at request time. Promoting a new version to production is a label move. Rollback is a label move in the other direction. Eval gates sit between draft and any higher environment, blocking promotion when rubric pass-rate regresses. The registry, the SDK, and the CI integration are the three pieces every team ends up with.
Why prompt versioning matters in 2026
Three forces made versioning operational, not optional.
First, prompt iteration speed outran code iteration speed. A prompt engineer can ship 30 candidate prompts a day. The code review and deploy cycle handles maybe two of those a day. If every prompt change rides the code lifecycle, prompt iteration becomes the bottleneck. Decoupling prompts from code lets the prompt iteration loop run at its native speed without backing up the code review queue.
Second, post-incident forensics need an audit trail. Regulated workloads (finance, healthcare, legal) require knowing which prompt was live at what time, who authorized the change, and what eval evidence justified the promotion. A prompt that only exists as inline strings in 12 git commits across four services does not satisfy this audit. A registry with version ids, labels, and a promotion log does.
Third, A/B testing and gradual rollouts require the version dimension as a first-class concept. Comparing prompt v18 to prompt v19 across a 5% canary cohort needs the runtime to resolve different versions for different user buckets. Without version ids and labels, A/B tests are config flags pointing to inline strings, which means every test is a code change.
The OpenTelemetry GenAI semantic conventions are still in Development status as of 2026 and do not yet name a standard prompt version attribute. Most teams ship a custom attribute (for example app.prompt.version or prompt.version) on the LLM call span. When the trace carries the version id, the entire observability stack can filter, attribute, and alert by prompt version. See What is LLM Tracing? for how the version id participates in the trace schema.
The anatomy of a prompt version
A prompt version is a record. The minimum it carries:
- Id. Immutable. Format choice ranges from monotonic integers (
v18) to short hashes (a7c91). Hashes are nice because two teams can branch the same parent without coordinating on integer assignment. - Parent id. The version this revision branched from. Powers the diff view and the blame.
- Body. The prompt template, including variable placeholders.
- Model id. The model this prompt is calibrated against. A prompt tuned for
gpt-4o-miniis not the same prompt as one tuned forclaude-3-5-haiku-latest. - Generation parameters. Temperature, top_p, max_tokens, stop sequences, response format. Calibrated together with the body; bumping temperature is a new version.
- System instructions. The system message, if separate from the user-facing template.
- Variable schema. The names and types of substitution slots. Schema changes are breaking and warrant a major bump.
- Author. Who created this version.
- Timestamp. Creation time.
- Commit message. Free-text rationale for the change.
- Eval pass-rate vector. Per-rubric pass rates from the offline eval suite.
- Deployment status. Draft, staging, prod, archived.
- Labels. The set of labels currently pointing to this version (prod, staging, canary, experiment_4).
Optional but operationally useful:
- Tenant scope. Some versions are tenant-specific (a custom prompt for one enterprise customer).
- Feature-flag scope. A version that should only serve when a feature flag is on.
- Cost-per-call estimate. Useful for budget gates.
- Lineage trail. The chain of prior production deploys, helpful when chasing regressions across multiple promotions.
Labels: the mutable pointer that resolves at request time
The label is what the runtime calls. The id is what storage stores. The label-to-id mapping is what promotion changes.
Three labels cover most workloads:
- prod. The version serving live user traffic.
- staging. The candidate version under test in a staging environment.
- canary. The version exposed to a small percentage of production users.
Larger setups add:
- experiment_NAME. A label scoped to an A/B experiment cohort.
- tenant_ID. A tenant-specific override.
- feature_FLAG. A label tied to a feature flag.
The application calls prompt.get("support_agent", label="prod") and the registry returns the body, the model id, and the generation parameters of whichever version prod currently points to. The runtime caches the resolution for a short TTL (60 seconds is reasonable) so the registry does not become a hot dependency on every request.
Label moves are the operational primitive. Promoting v19 to prod is prompt.label("support_agent", label="prod", version="v19"). The previous prod (v18) is now unreferenced by prod but still archived and available for rollback. Rollback is prompt.label("support_agent", label="prod", version="v18"). No code redeploy. No service restart. The next request that misses the cache resolves to the new version.
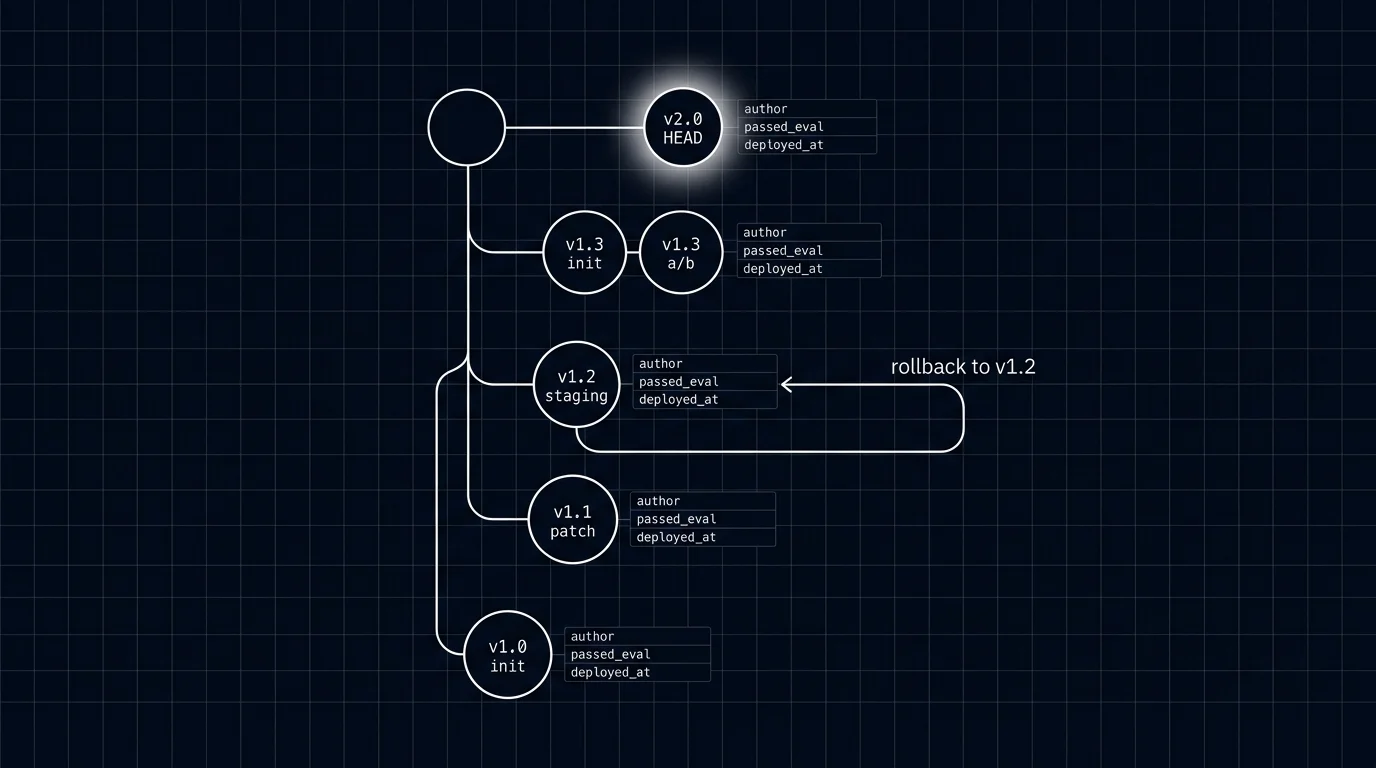
How prompt versioning is implemented in 2026
Three components: the registry, the SDK, and the CI integration.
The registry
The registry stores versions, resolves labels, and exposes promotion endpoints. Six viable patterns:
- LangSmith Prompt Hub. Closed platform, native to the LangChain ecosystem. Web UI for authoring with prompt commits, tags, and environments; pairs with LangSmith evals and CI for gated promotion.
- Future AGI prompt versions. Apache 2.0 stack, integrated with the eval and gateway surfaces. Versioning is a first-class primitive across the platform.
- Braintrust prompts. Closed platform with a strong dev workflow, native diff view, and eval integration.
- Helicone Prompts. Apache 2.0, gateway-attached prompt management. Useful when the gateway is the dominant integration point.
- Langfuse prompt management. MIT core. Web UI, label-based deploys, integrates with the broader Langfuse observability stack.
- YAML-in-git plus loader. Lightweight: prompts live in a YAML file in the same repo, a loader resolves labels via filename or commit metadata. No external service required, but you build the eval-gated promotion yourself and the diff view is git’s diff view.
The choice usually comes down to where your eval suite already lives and what your gateway expects.
The SDK
The client SDK does three things: resolves labels to version ids, caches the resolution, and emits a span attribute (gen_ai.prompt.version) on the LLM call so the trace carries the version. A reasonable SDK signature:
prompt = registry.get("support_agent", label="prod")
response = openai.chat.completions.create(
model=prompt.model,
messages=prompt.format(user_query=query),
temperature=prompt.temperature,
)
# trace span carries gen_ai.prompt.version=v18 automaticallyThe cache TTL controls the staleness window. A 60-second TTL means a label move propagates to all callers within a minute. A 5-minute TTL is faster on the registry but slower to reflect a rollback. Operational rule: TTL short enough that an emergency rollback is felt within the rollback drill SLA.
The CI integration
The CI integration runs the eval suite on every promotion. The shape:
- Author commits a draft version. The registry tags it
status=draft. - CI fetches the draft, runs the eval suite, attaches per-rubric scores to the version metadata.
- If pass-rates clear thresholds, CI promotes the draft to staging (
label=staging). - After a soak period (1 hour, 1 day, configurable), CI runs the canary promotion:
label=canaryon a 5% user cohort. - The drift watcher monitors per-rubric scores on the canary cohort. If scores hold, CI promotes to prod. If scores regress, CI auto-rolls-back the canary label.
- Final promotion to
prodis gated on a human approval click in the registry UI.
Without this loop, prompt promotions ship on review-by-vibes. With it, every promotion clears a quantitative bar and an automatic rollback path. See Eval-Driven Development for the wider eval-first workflow this fits inside.
Common mistakes when implementing prompt versioning
- Inlining prompts in code “just for now.” Once a prompt is in code, the cost of moving it to a registry compounds with every callsite. Move it on day one of the workload.
- Versioning only the body. A prompt is a tuple of body, model id, and generation parameters. Versioning only the body means a temperature change ships untracked.
- Treating labels as immutable. Labels are mutable pointers; that is the whole point. Treating them as immutable defeats the rollback path.
- No eval gate on promotion. A registry without an eval gate is a config store with extra steps.
- Not tagging spans with version id. If your traces do not carry
gen_ai.prompt.version, you cannot attribute regressions to a prompt change. - Long cache TTLs. A 30-minute cache TTL means the rollback path takes 30 minutes to take effect. Keep TTL under 2 minutes for production-critical prompts.
- Forgetting to archive. Archiving stale versions keeps the diff view legible. The registry that lists 800 versions is a registry nobody opens.
- Mixing prompt versioning with model versioning. A model upgrade (gpt-4o-mini to gpt-4o) is not a prompt change. Track them separately, even if the registry encodes the model id in the version metadata. Conflating the two destroys the ability to attribute regressions correctly.
- Letting the registry become single-point-of-failure. The registry is on the request path. Cache aggressively, fall back to a baked-in last-known-good version on registry outage, and load-test the registry before relying on it for high-volume traffic.
The future: where prompt versioning is heading
Five directions are settled or emerging.
Versioning becomes a runtime primitive, not an authoring concern. Today the registry is the authoring tool. In 2026, the gateway, the eval suite, and the observability stack all consume the version id as a first-class dimension. Filtering traces by version, alerting on per-version drift, and routing by version are table stakes.
Per-tenant and per-user version overrides. Enterprise customers ask for prompt customization. Per-tenant labels handle this without forking the prompt repo. Tenant_acme@prod resolves to a custom version while everyone else resolves to the global prod label.
Prompt versioning extends to tool definitions. A prompt is a tuple of body, model, parameters. As tool calling becomes routine, the tool definitions (function schema, descriptions) also become part of the unit of versioning. A tool description change can shift refusal calibration as much as a body change.
LLM-assisted prompt iteration in the registry. The registry is where prompt iteration happens. Tools that suggest improvements based on production failure clusters, draft new versions automatically, and rank candidates by predicted eval lift are appearing. See the error analysis workflow for the failure-driven iteration pattern this fits.
Cross-environment promotion gates beyond eval. Cost gates (the new version must not exceed the cost budget by more than 5%), latency gates (p99 must hold within 10%), and safety gates (no regression on adversarial probes) join eval pass-rate as standard CI checks.
The throughline: prompt versioning stops being a feature in one product and becomes a substrate the whole stack assumes. The same way nobody ships code without git, nobody will ship prompts without a registry, labels, and eval gates. Teams that get this right at week one ship faster, debug regressions faster, and pass audits without scrambling.
How to use this with FAGI
FutureAGI is the production-grade prompt versioning, evaluation, and observability stack. The Prompt Hub ships immutable prompt versions with semantic labels (dev, staging, prod), pull-request review, CI evals on diff, and rollback. Versions resolve at request time so a label flip is a deploy, not a code change. Span-attached scoring tags every production span with the prompt version that served it; rolling-mean per-version dashboards surface regressions before users notice.
The Agent Command Center is where prompt versions, traces, and scores converge. The same plane carries 50+ eval metrics, six prompt-optimization algorithms (GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random) that propose nightly diffs against the eval set, persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Free + pay-as-you-go base; compliance (SOC 2, HIPAA BAA), SSO (OAuth, SAML + SCIM), and enterprise SLAs add on per tier (pricing).
Sources
- LangChain LangSmith Prompt Hub
- Future AGI prompts in the Future AGI platform
- Future AGI GitHub repo
- Braintrust prompts docs
- Helicone prompts docs
- Langfuse prompt management docs
- OpenTelemetry GenAI semantic conventions
- traceAI GitHub repo
- DeepEval docs
- Anthropic prompt engineering guide
Series cross-link
Related: What is LLM Tracing?, Eval-Driven Development, LLM Tracing Best Practices in 2026, Best AI Prompt Management Tools 2026
Frequently asked questions
What is prompt versioning in plain terms?
How is prompt versioning different from prompt management?
What is the difference between a version id and a label?
Do I need a registry, or can I keep prompts in code?
How do eval gates fit with prompt versioning?
What metadata should a prompt version carry?
How do I version prompts that contain variables?
What does prompt versioning cost in operational complexity?

Conditional prompt selection at runtime in 2026: routing, fallbacks, embedded conditions, version pinning, eval discipline that keeps it from drifting.


LLM deployment in 2026: traceAI, OTel, prompt versioning, eval gates, guardrails, gateway routing, fallback patterns. The production checklist that ships.


Six AI agent reliability solutions compared in 2026 across five layers: runtime guardrails, CI eval gates, span-attached scoring, clustering, closed loop.
