LLM-as-Judge Best Practices in 2026: Calibration, Bias, and Cost
LLM-as-judge best practices for 2026: pick the right judge, calibrate against humans, watch for length and family bias, control cost. The discipline that scales.

Table of Contents
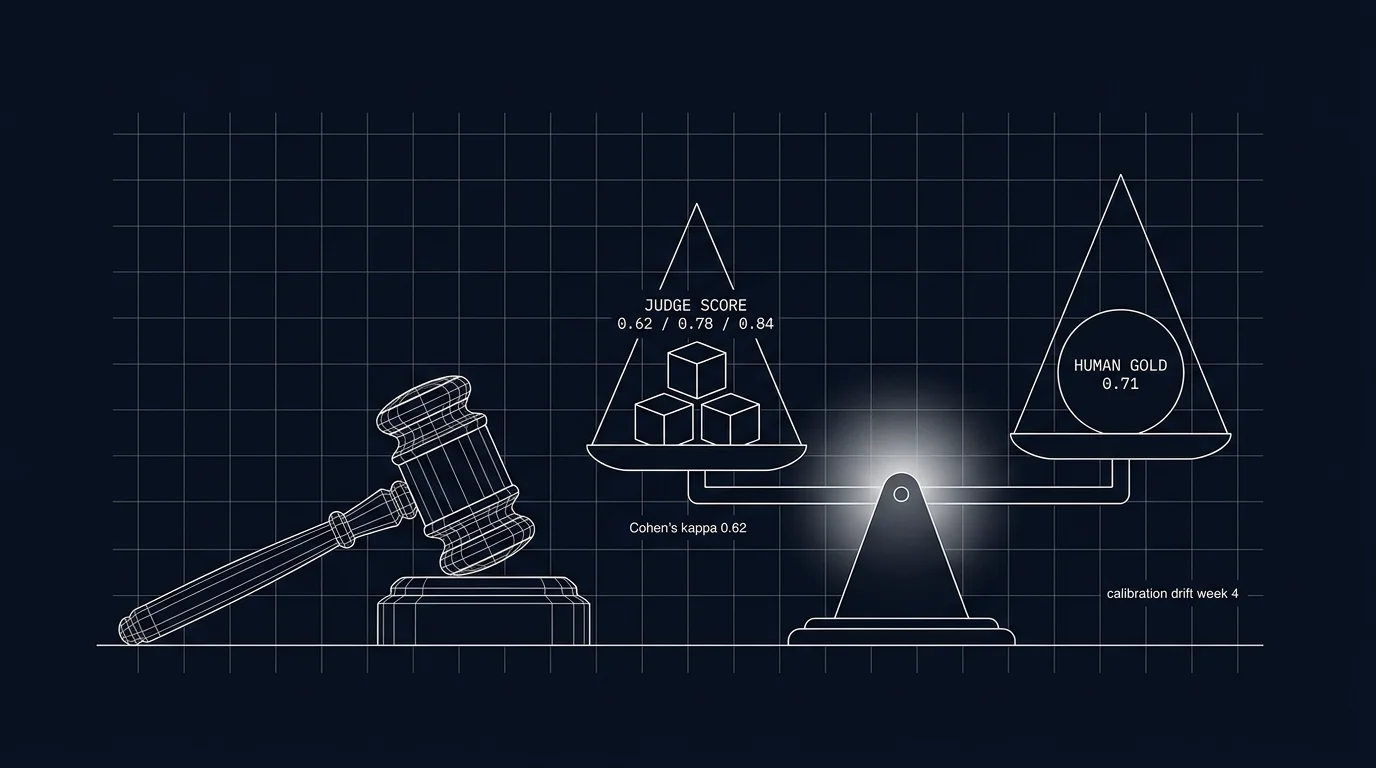
A team builds an LLM-as-judge for groundedness. The judge is GPT-4. It scores GPT-4 production outputs. The team ships. For three months, every dashboard glows green. Then the team hires a domain expert who reads 50 production outputs and grades them. The expert kappa with the judge is 0.31. The judge has been over-rewarding GPT-4 outputs systematically (family bias) and under-penalizing fluent hallucinations (length-confidence bias). The dashboards have been lying for three months.
This is the failure mode this piece is about. LLM-as-judge is a powerful tool. Used carelessly, it produces scores that look reasonable and are wrong. The discipline that prevents this has 10 items: pick the right judge, calibrate against humans, mitigate the known biases, control cost, run async. None are exotic. All are skipped on the typical first launch. This piece walks through each, with the verification step you can run before going live and the maintenance discipline you can run monthly.
TL;DR: 10 practices, all mandatory
| # | Practice | Failure it prevents |
|---|---|---|
| 1 | Pick the right judge for the role | Wrong cost-fidelity trade |
| 2 | Maintain a human gold-set | No calibration anchor |
| 3 | Calibrate monthly | Judge drift goes undetected |
| 4 | Different model family than generator | Family bias over-rewards same-family outputs |
| 5 | Specify the rubric explicitly | Vague rubrics produce vague scores |
| 6 | Mitigate length bias | Verbose answers score higher than concise correct ones |
| 7 | Mitigate position bias | Pairwise comparisons favor first or second consistently |
| 8 | Sample, do not score every span | Unbounded judge cost |
| 9 | Run judges async | Inline judges add user-visible latency |
| 10 | Track judge cost as its own line | Judge cost can rival production cost unmonitored |
If you only read one row: items 2 and 3 (gold-set plus monthly calibration) are what catch the silent drift that destroys trust in the score stream. Without them, you are running on faith.
Why these practices matter in 2026
Three forces converged.
First, judges scaled into production. Distilled small judges (Galileo Luna, Future AGI Turing-flash, small distilled models from other vendors) brought judge cost down 10-50x compared to frontier judges. Now teams can afford to score every span at sampled rates. Affordability raised the stakes: a judge that runs on 20% of traffic and is systematically miscalibrated produces a lot of wrong scores.
Second, regulators and auditors started asking. EU AI Act compliance and similar regimes require demonstrable evaluation. A judge that disagrees with humans in systematic ways is a finding, not a passing audit. The discipline of calibration moved from research convention to compliance requirement.
Third, the failure modes are well documented. Length bias, position bias, family bias, self-enhancement bias, verbosity-confidence bias. Each has a known mitigation. Skipping the mitigations is no longer “we did not know”; it is “we knew and skipped.”
The substrate this discipline runs on: human-labeled gold-sets, span-attached scores via OTel attributes, and a registry that versions the judge prompt the same way production prompts are versioned. See What is LLM Judge Prompting? for the prompt-engineering primer this builds on.
The 10 practices
1. Pick the right judge for the role
Three roles, three judges:
- Production scoring (high volume, sampled). A distilled small judge. Galileo Luna and Future AGI’s
turing_flashare widely deployed distilled judges. Latency and price depend on workload, region, and credit/contract pricing; consult vendor docs for current numbers. smaller OpenAI judge models runs at competitive cost. Calibrate against the gold-set before deploying. - Calibration anchor (low volume, high fidelity). A frontier model. GPT-4o, Claude Sonnet, Gemini Pro. Used to score the gold-set and the canary cohort.
- Custom rubric (workload-specific). A fine-tuned judge trained on your gold-set. Highest accuracy on your rubric, requires the labeled training data upfront.
Most production stacks use a distilled judge for production scoring and a frontier judge for the calibration runs. Custom fine-tuned judges appear when the rubric is specific enough that off-the-shelf judges underperform.
2. Maintain a human gold-set
200-500 hand-labeled traces per workload per rubric. Each trace labeled by 2-3 humans against the rubric; inter-annotator agreement (Cohen’s kappa) tracked.
The gold-set is the calibration anchor. Without it, you have no reference to detect drift against. Refresh quarterly: replace the staler 100-200 entries with fresh production traces, keeping the gold-set representative of current workload distribution.
Tools: Argilla, Label Studio, Future AGI annotation UI, SuperAnnotate. The choice depends on annotator workflow and rubric configuration; the data is what matters.
3. Calibrate monthly
Run the production judge over the gold-set. For categorical labels, compute Cohen’s kappa (or Krippendorff’s alpha for multi-annotator gold-sets) between judge scores and human scores. For continuous scores, use weighted kappa, score correlation, or mean absolute error. Alert if kappa drops below threshold (0.6 is a common bar; some rubrics tolerate lower, some require higher).
Recalibration paths when kappa drops:
- Tighten the rubric prompt. Often the rubric is too vague and the judge is interpolating.
- Swap the judge model. A model upgrade or a different distilled checkpoint may agree better.
- Refresh the gold-set. The workload may have shifted; the gold-set may be stale.
- Add examples to the rubric. Few-shot examples in the judge prompt sharpen agreement.
Without a recurring calibration cadence, judges can drift as data, prompts, or models change. The scores you trust today become unreliable next quarter.
4. Different model family than the generator
A GPT-4 judge scoring GPT-4 outputs over-rewards GPT-4 systematically. The bias is well documented: same-family models share training data, alignment, and stylistic preferences. The judge sees its own family’s style and treats it as quality.
The fix: use a different family. If the generator is GPT, the judge is Claude or Gemini or a distilled model from a different lineage. If the generator is multi-model, the judge family rotates.
Verification: score the gold-set with the production judge and a same-family judge; compare deltas. If the same-family judge systematically scores its family’s outputs higher than humans do, the bias is present.
5. Specify the rubric explicitly
A vague rubric (“rate helpfulness 1-10”) produces a vague judge. The rubric prompt should:
- Define the metric: “groundedness: every factual claim must be supported by the provided context.”
- Require discrete output format: “return JSON
{\"score\": 0.0-1.0, \"reasoning\": \"...\"}.” - Provide examples: “good: 0.9, all claims grounded. bad: 0.2, claim X unsupported by context.”
- List edge cases: “if the context is empty, score 0 if any factual claim is made; score 1 only if the response says it cannot answer.”
Test the rubric prompt against the gold-set before deploying. If kappa is low at launch, the rubric is the most likely culprit. Version the rubric prompt in the same registry as production prompts (see Prompt Versioning).
6. Mitigate length bias
Judges over-reward longer responses. This is documented across model families and rubrics. The mitigation:
- Penalize verbosity in the rubric. “Penalize unnecessary length; favor concise correct answers.”
- Score per-token-normalized. For some metrics (information density), normalize by token count.
- Test the bias on the gold-set. Sort gold-set traces by length; check whether judge scores correlate with length more than human scores do.
If the bias is present, the judge will systematically prefer the verbose model in head-to-head comparisons regardless of correctness.
7. Mitigate position bias for pairwise comparisons
In pairwise comparisons (judge picks A or B), the first or second slot gets favored regardless of content. The mitigation:
- Randomize the order. Shuffle which output goes in slot A and which in slot B; aggregate over many comparisons.
- Score independently and compute pairwise post-hoc. Score each output independently against the rubric, then derive A vs B from the scores.
- Use multi-judge ensembles. Different judges have different position biases; an ensemble reduces the systematic effect.
8. Sample, do not score every span
Cost target: judge cost stays under 10-15% of production LLM cost.
Two levers:
- Sample rate. 5-20% of production traffic uniformly, plus 100% of errors, low-score outputs, and outlier-cost traces.
- Judge model. Distilled small judges over frontier judges by 10-50x.
If judge cost exceeds 25% of production, reduce sample rate or swap to a smaller distilled judge. The marginal coverage past 20% rarely justifies the cost.
9. Run judges async, not on the request path
A judge call adds 100ms-2s of latency. Inline judges on the request path add this to user-perceived response time.
The pattern: the production span ships normally; an async worker pulls the span from a queue, runs the judge, attaches the score as a span attribute (or a delayed event). The user does not wait for the judge.
For workloads where the score must influence the response (a guardrail that uses the judge to gate an output), the inline judge is unavoidable; budget the latency accordingly and use the smallest distilled judge that meets the rubric.
10. Track judge cost as its own line
Separate judge cost from production LLM cost in dashboards. Alert when judge cost exceeds budget threshold or grows faster than production cost.
A typical configuration: production calls and judge calls are separate cost lines, each tagged on the span. The dashboard shows both, the ratio, and the alert threshold. See LLM Cost Tracking Best Practices for the broader cost-tracking discipline.
Tools that support LLM-as-judge in 2026
- DeepEval. OSS, Apache-2.0-licensed, pytest-native. Ships built-in judge prompts for groundedness, helpfulness, faithfulness.
- Future AGI evaluation platform. Apache-2.0 OSS components plus a hosted platform with the proprietary
turing_flashcloud judge model, rubric library, and calibration tooling. - Galileo. Closed platform with distilled Luna judges; first-class calibration UI.
- Braintrust. Closed platform, scoring functions, comparison tooling.
- LangSmith Evals. Closed platform, judge primitives integrated with the LangChain ecosystem.
- RAGAS. OSS, RAG-specific judges (faithfulness, answer-relevance, context-precision).
- OpenAI Evals. OSS, model-graded evals via OpenAI APIs.
- Promptfoo. OSS, CLI-first, supports LLM-judge scoring in YAML test sets.
The choice depends on where the test sets and traces live and which CI you use. The discipline is the same across tools.
Common mistakes when using LLM-as-judge
- No human gold-set. No anchor; drift goes undetected.
- Same-family judge. Family bias over-rewards systematically.
- Vague rubric. “Rate quality 1-10” produces noise.
- No calibration cadence. Judges drift in 60-90 days.
- Inline judges. User-visible latency penalty.
- Single judge. Variance is high; consider ensembles for high-stakes rubrics.
- No length-bias mitigation. Verbose answers win.
- Pairwise comparison without order randomization. Position bias decides.
- Judge cost not tracked separately. Cost can rival production unobserved.
- Scoring every span. Cost unbounded; sample.
- Rubric prompt unversioned. A rubric tweak that changes scores is a regression you cannot bisect.
What changed in LLM-as-judge in 2026
| Date | Event | Why it matters |
|---|---|---|
| 2026 | Distilled judges (Galileo Luna, Future AGI Turing-flash) hit production scale | Sample rates of 10-20% became cost-tractable |
| 2026 | OTel GenAI eval-score attributes standardized | Score-stream observability moved to off-the-shelf |
| 2026 | Multi-judge ensembles became a documented pattern | Variance reduction made high-stakes scoring more reliable |
| 2026 | Length and family bias mitigations entered standard rubrics | Default judge prompts started shipping with bias-reducing instructions |
| 2025-2027 | EU AI Act phased application: GPAI obligations applied Aug 2025; full enforcement and remaining provisions phase in through 2027 | Demonstrable judge calibration is moving from advice to compliance requirement for in-scope systems |
How to actually deploy LLM-as-judge in production
- Define the rubric. Specific, with examples, with discrete output format.
- Build the gold-set. 200 hand-labeled traces; track inter-annotator agreement.
- Pick the judge model. Distilled for production, frontier for calibration runs.
- Avoid same-family bias. Use a different family than the generator.
- Calibrate at launch. Score the gold-set; verify Cohen’s kappa above threshold.
- Wire the async runner. Sample 5-20% of production traces; run the judge async; tag scores on spans.
- Build the calibration job. Monthly run against the gold-set; alert on kappa drop.
- Build the cost tracker. Judge cost as its own line; alert on budget breach.
- Build the drift monitor. Rolling-mean rubric scores; alert on degradation.
- Schedule the gold-set refresh. Quarterly; replace stale entries with fresh production traces.
Sources
- DeepEval docs
- RAGAS docs
- OpenAI Evals GitHub
- Galileo Luna docs
- Future AGI evaluation platform
- Anthropic prompt engineering guide
- LLM-as-Judge survey paper (Zheng et al, 2024)
- Cohen’s kappa explainer (Wikipedia)
- Argilla annotation platform
- EU AI Act overview
Series cross-link
Related: What is an LLM Evaluator?, What is LLM Judge Prompting?, LLM Evaluation Architecture, Eval-Driven Development
Related reading
Frequently asked questions
What is LLM-as-judge in plain terms?
Which judge model should I pick?
What is judge calibration and why does it matter?
What biases do LLM judges have?
How do I write a good judge prompt?
How often should I recalibrate?
What is a reasonable cost target for judge calls?
What does running an LLM-as-judge stack cost in operational complexity?
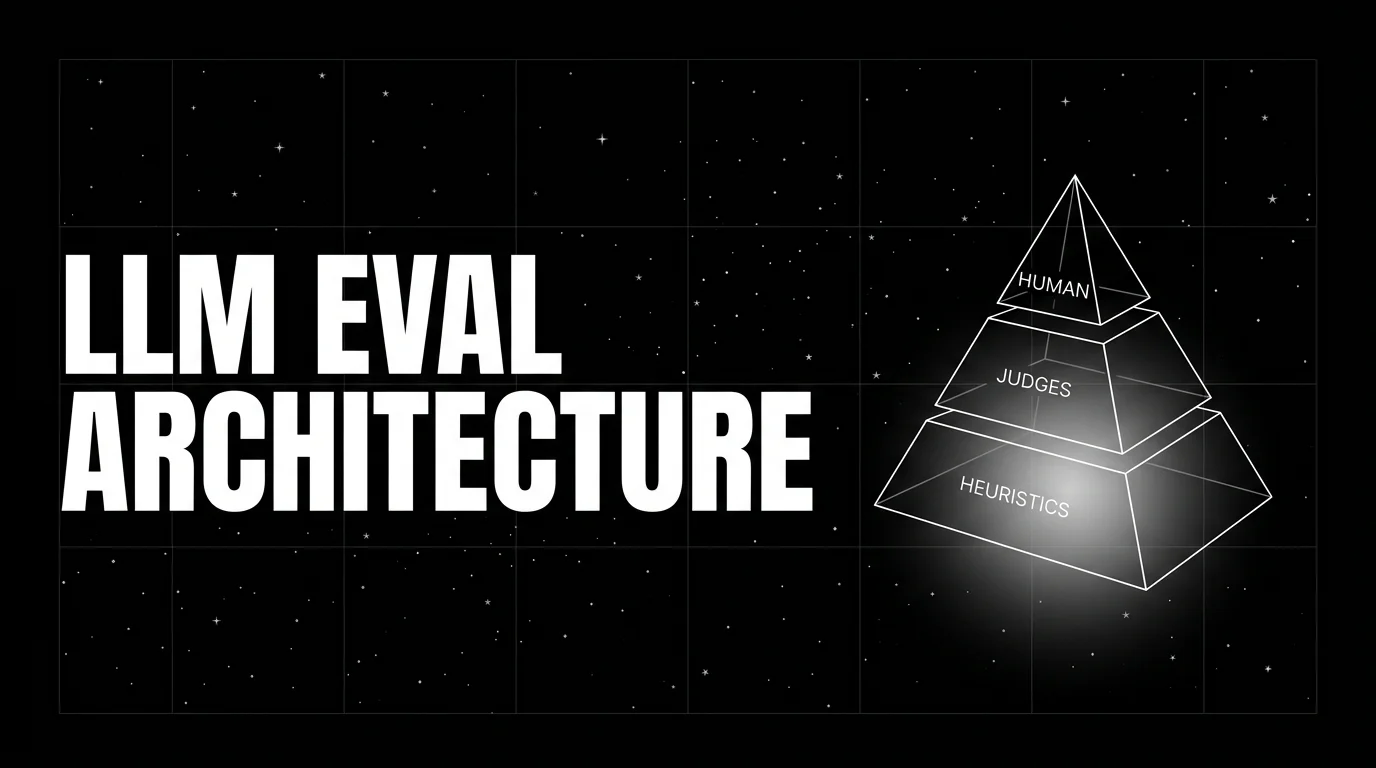
LLM evaluation architecture in 2026: heuristics on every span, distilled judges on a sample, humans on the gold-set. The three-tier stack that scales without breaking the bill.

FutureAGI, Galileo, Braintrust, Patronus, Confident-AI, Phoenix, and Langfuse as the 2026 LLM-as-judge shortlist. Calibration, drift, and judge cost compared.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.