What Does a Good LLM Trace Look Like in 2026: Anatomy and Attributes
Anatomy of a good LLM trace in 2026: span hierarchy, OTel GenAI attributes, prompt-version tags, eval scores, cost attribution, retrieval and tool spans.

Table of Contents
A senior engineer joins an LLM team on Monday. By Wednesday they have an incident: a quality regression for German enterprise users on the support agent. They open the trace store. They expect to see a tree: agent run as the root, planner, retriever, LLM call, tool calls, evaluator, guardrail. They expect every LLM call to carry the prompt version, the user cohort, the eval score. What they get is a flat list of 28 spans, none with a prompt version, the LLM spans named chat versus chat.completion versus chat.completion.v2 across the same service, retrieval spans with the query as raw text, and one span with a 4 KB attribute bag containing the entire prompt body. Forty-five minutes in, the engineer has not localized the regression. The trace was instrumented; it was not instrumented well.
This post is the answer to “what does a good LLM trace actually look like.” It covers the span hierarchy, the OTel GenAI attributes that belong on every LLM call, the prompt-version model, the retriever and tool span shapes, the cost attributes, the eval-score attachment, and the PII discipline. The patterns are vendor-neutral, grounded in the OTel GenAI semantic conventions and OpenInference schema, and tested against the operational shape of production LLM workloads as of mid-2026.
TL;DR: The 8 attributes of a good trace
| Attribute | What it gives you |
|---|---|
| Tree-structured span hierarchy | Per-stage debugging; localized failure attribution |
| OTel GenAI canonical attributes | Cross-vendor compatibility; standard schema |
| Prompt version on every LLM span | Regressions attributable to specific rollouts |
| Span-attached eval scores | Drift detection on quality, not just latency |
| Cost attributes broken out | Reasoning and cache tokens visible in dashboards |
| PII redacted at the collector | Compliance posture, audit-ready |
| Stable span names | Aggregations and alerts survive code changes |
| Tail-sampled at the collector | Long-tail failures kept; uniform sampling on the rest |
If you only fix one thing first, ship prompt.version on every LLM call span. The rest of the discipline depends on it.
What “good” means operationally
A good trace answers operational questions in seconds, not minutes:
- Which prompt version did this user see?
- Which retrieval was the slow one?
- Which tool call failed?
- Which step’s eval score dropped?
- Which cohort is the regression hitting?
- Which model emitted the response?
These are the questions an on-call engineer asks at 2 AM. The trace either has the structure and the attributes to answer them, or it does not. There is no middle ground; a partial answer (“the trace shows the LLM was called but not which version”) is operationally the same as no answer.
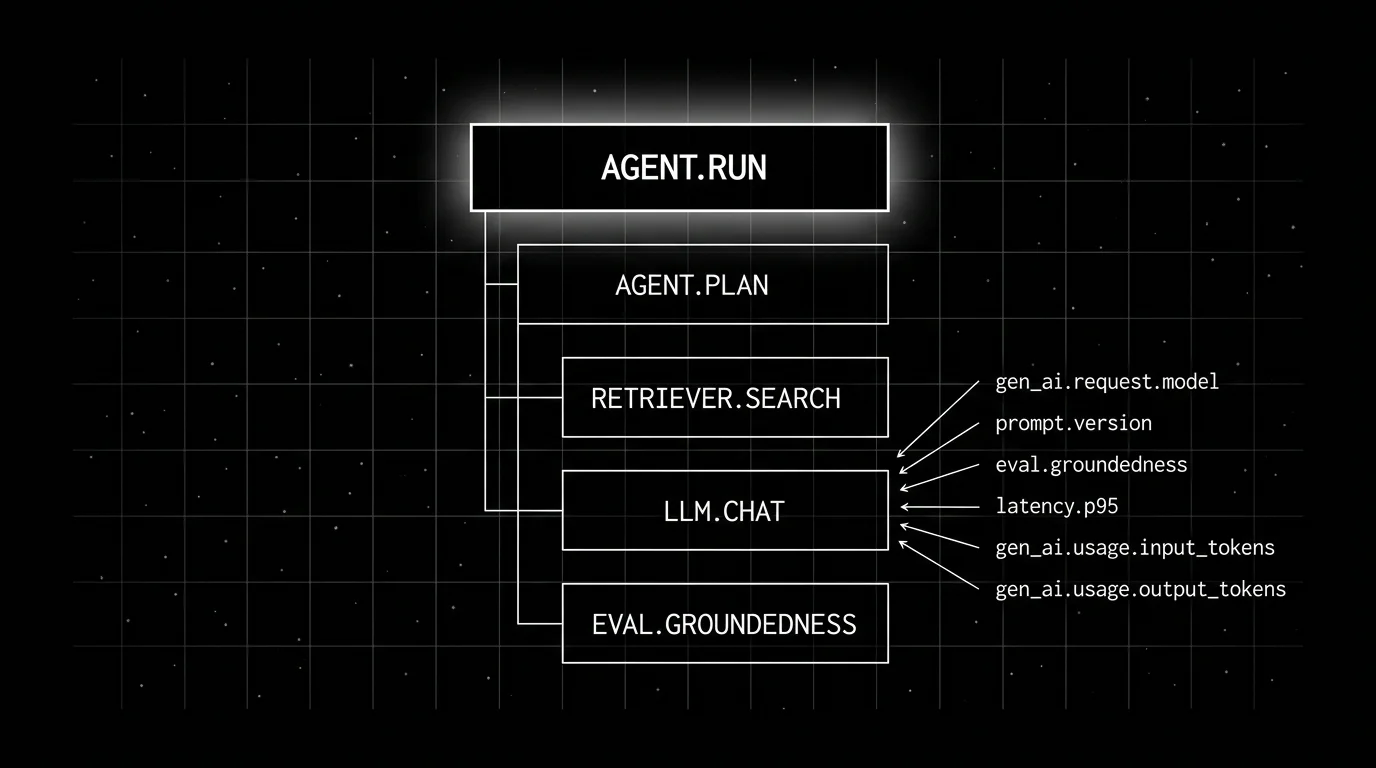
The span tree of a typical agent run
The structure that fits a 2026 agent stack:
agent.run (root)
agent.plan
llm.chat (planner)
agent.dispatch.tool_a
tool.weather_lookup
agent.dispatch.tool_b
tool.search
agent.synthesize
llm.chat (synthesizer)
guardrail.output
eval.groundedness
eval.refusal_calibrationThe root span is the agent run. Child spans nest by causal relationship. Tool calls nest under the dispatch that triggered them. Eval and guardrail spans attach to the agent run as siblings of the synthesize step.
For a non-agentic chat call, the tree is simpler:
chat.handler (root)
retriever.search
llm.chat
eval.groundedness
guardrail.outputThe principle is the same: tree structure reflects the actual call graph; one span per logically meaningful operation; eval and guardrail spans attach as siblings of the LLM call they scored.
A flat span list is not a trace. It is a log file with span ids stapled on.
The attributes the OTel GenAI spec covers
The OpenTelemetry GenAI semantic conventions standardize a gen_ai.* namespace covering operation type, provider, request and response models, token usage, response id, finish reasons, request parameters, and opt-in content fields. Existing instrumentations may require OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental to emit the latest experimental GenAI conventions; production stacks pin the version they emit.
Required or recommended attributes on an LLM call span:
gen_ai.operation.name # chat, embeddings, text_completion
gen_ai.provider.name # openai, anthropic, aws.bedrock, gcp.vertex_ai
gen_ai.request.model # provider-specific model id (verify against the provider docs)
gen_ai.response.id # provider-emitted response id
gen_ai.response.model # response model when different from request
gen_ai.usage.input_tokens
gen_ai.usage.output_tokens
gen_ai.response.finish_reasons # [stop], [length], [tool_use]Cache and reasoning tokens, when present:
gen_ai.usage.cache_creation.input_tokens
gen_ai.usage.cache_read.input_tokens
gen_ai.usage.reasoning.output_tokensFor tool calls inside an LLM response:
gen_ai.tool.name
gen_ai.tool.call.idContent fields, opt-in only and redacted before storage in regulated contexts:
gen_ai.input.messages
gen_ai.output.messagesThe discipline: emit the canonical attributes on every LLM call. Mix them with custom prompt and application attributes (prompt.version, user.cohort, tenant.id, eval.score.*). The OTel GenAI namespace is cross-vendor; the custom namespace is your application’s schema.
Prompt versioning on every LLM span
Three custom attributes on every LLM call span:
prompt.id: stable identifier for the prompt slot.prompt.version: versioned tag (semver or sequential) from the registry.prompt.variant: A/B variant flag value, when applicable.
Without these, regressions cannot be attributed to a specific rollout. With them, the observability stack can filter by version, aggregate per-version metrics, and alert on per-version drift. See linking prompt management with tracing for the full attribute model.
The OpenInference schema names the equivalents (llm.prompt_template.template, llm.prompt_template.version, llm.prompt_template.variables); pick one schema and stay consistent across services.
Retrieval span shape
One span per retriever query. The OTel GenAI guidance is to set gen_ai.operation.name=retrieval and use a span name like retrieval {gen_ai.data_source.id} (e.g., retrieval vector_index_v3); application-convention names like retriever.search, retriever.bm25, retriever.hybrid are acceptable as long as they stay stable.
Attributes:
retriever.query.text # hashed if sensitive (OTel: gen_ai.retrieval.query.text; OpenInference: input.value)
retriever.top_k # OTel: gen_ai.request.top_k
retriever.documents # OTel: gen_ai.retrieval.documents; OpenInference: retrieval.documents
retriever.index.version
retriever.search_strategy # vector, bm25, hybrid, rerank
retriever.embedding.model # when applicableThe trap: setting raw query text as retriever.query when queries contain PII. Hash or redact; or gate behind the same opt-in flag as gen_ai.input.messages.
The other trap: per-document attributes that explode cardinality. Pick the encoding that matches the schema you committed to. OTel GenAI’s gen_ai.retrieval.documents follows the spec’s structured shape; OpenInference uses indexed flat attributes (retrieval.documents.<i>.document.id, .document.score). Per-document child spans are usually overkill for retrievers; reach for them only when you need per-document timing or eval scoring.
For RAG pipelines, see also LangChain RAG observability for the per-stage attribute model.
Tool call span shape
One span per tool invocation. OTel GenAI canonical fields first, then bounded application-namespaced summaries:
gen_ai.operation.name # execute_tool
gen_ai.tool.name
gen_ai.tool.call.id
gen_ai.tool.call.arguments # opt-in per OTel GenAI; redact in regulated contexts
gen_ai.tool.call.result # opt-in per OTel GenAI; redact in regulated contexts
app.tool.arguments.summary # custom namespace; bounded representation
app.tool.return.summary # custom namespace; bounded representation
app.tool.duration_ms
app.tool.status # ok, error, timeoutThe full argument JSON does not belong as a single attribute; pick the bounded fields that matter (e.g., for tool.weather_lookup, the city and date; not the full request object).
Tool spans nest under the LLM call that requested them when the LLM emits a tool-use response and the runtime dispatches the tool. They nest under the agent.dispatch span when the agent runtime dispatches a tool without an LLM round-trip.
Eval scores attached to spans
The pattern: an online evaluator runs on the output, returns a per-rubric score vector, and tags the span with eval.<rubric>=<score>:
eval.groundedness = 0.82
eval.refusal_calibration = 0.91
eval.faithfulness = 0.78
eval.completeness = 0.85The drift detector watches rolling-mean rubric scores per route, per prompt version. When the mean drops below threshold, an alert fires. Latency alerts catch infra; eval-score alerts catch quality drift.
The fast structural rubrics (does every claim cite a source) run online with low-latency judges (50-200 ms). The slower semantic rubrics (does the cited passage support the claim) run offline against sampled traces. Both attach scores to the same spans on the same trace.
For online scoring at production-tractable latency, Future AGI’s turing_flash targets 50-70ms p95 for inline guardrail screening; full eval templates are closer to ~1-2s and should be run online only where that latency budget is acceptable. The same eval engine sits behind the Agent Command Center and the evaluation suite; validate against your own workload before treating any number as a contract.
Cost attribution
Token counts as first-class span attributes. The trap is collapsing reasoning and cache tokens into one field; the cost dashboards under-attribute reasoning models and over-attribute cached calls.
The five token attributes that matter:
gen_ai.usage.input_tokens
gen_ai.usage.output_tokens
gen_ai.usage.cache_creation.input_tokens
gen_ai.usage.cache_read.input_tokens
gen_ai.usage.reasoning.output_tokensPlus a per-span cost attribute computed at emission time:
app.cost.usd # custom namespace; token counts x current price; tagged at the sourceComputing cost at emission avoids the recompute pass at query time and stabilizes cost dashboards across pricing changes (the price at the time of the call is captured in the attribute).
For per-version cost regressions, the dashboard slices by prompt.version and gen_ai.request.model. A reasoning-model upgrade can blow out cost without changing the visible answer; the cost attribute catches this when latency does not.
PII redaction at the collector
The OTel GenAI conventions mark gen_ai.input.messages and gen_ai.output.messages opt-in for a reason. The default for regulated workloads is to not emit raw content at all. Where content capture is needed, redact at the source where possible and enforce collector-side redaction before any export or long-term storage.
The pattern:
- Sensitive content disabled by default; opt-in flag with explicit review for any environment that emits it.
- Where it is emitted, redact at the source (in-process) before the span is exported to the collector.
- Collector redaction processor scrubs residual PII (emails, phones, names, addresses) using a deterministic function as a defense-in-depth pass.
- Same PII gets the same placeholder within a trace, so post-hoc analysis correlates without exposing the data.
- Redaction policy lives in the same repo as the instrumentation; reviewed with privacy and security at design time.
For HIPAA, GDPR, and similar regimes, content minimization plus client-side and collector-side redaction is a hard requirement, not a recommendation.
Stable span names
Span names are aggregation keys. Renaming agent.tool_call to tool.invoke between v17 and v18 breaks every dashboard and alert that aggregated on the old name.
The discipline:
- Lock down a naming convention early.
<component>.<operation>(e.g.,retriever.search,agent.dispatch,guardrail.input). - Lowercase, dot-separated, stable.
- Treat renames as breaking changes; require migration of dashboards and alerts.
The trap: framework SDKs that change span names across versions silently. Pin SDK versions, audit span names on SDK upgrade.
Tail-based sampling
Cost-driven head sampling at 1 percent hides the long-tail failures the trace was meant to catch. Tail-based sampling at the OTel collector buffers the full trace and decides at the end whether to keep it.
A reasonable default policy:
- Keep 100 percent of traces with
status = ERROR. - Keep 100 percent of traces with any eval rubric below threshold.
- Keep 100 percent of traces above a fixed cost or latency threshold.
- Keep 100 percent of traces tagged with
experiment_idor canary cohort. - Sample 5-20 percent of remaining traffic uniformly.
The OTel Collector tail-sampling processor is a common production pattern, but it is still marked beta, requires routing all spans for a trace to the same collector, and needs ongoing tuning of buffers and policies.
What a bad LLM trace looks like
Six failure modes worth recognizing:
- Flat span list. A LangGraph or CrewAI run rendered as a flat list buries the loop and the dispatch decisions. Tree-structured trace views are not optional.
- Span names that change across versions. Aggregations break.
- No
prompt.version. Regressions cannot be attributed. - Raw user input as a span attribute. Cardinality explosion plus privacy risk.
- Cost collapsed into one token field. Reasoning and cache tokens hidden.
- One giant root span. No debuggability.
Common mistakes when designing trace schema
- Treating tracing as logging with extra fields. It is not. The parent-child tree, the gen_ai.* schema, and span events are first-class.
- Sampling too aggressively at the head. 1 percent uniform head sampling hides failures.
- Not tagging prompt versions. If you cannot filter by version, you cannot attribute regressions.
- Forgetting redaction. PII in trace storage is a compliance incident waiting to happen.
- Using a proprietary SDK as the only path. A proprietary SDK on top of OTel is fine. A proprietary SDK instead of OTel is a switching cost.
- Flattening agent traces. A LangGraph or CrewAI run is a tree.
- No span-attached eval scores. Latency alerts catch infra. Eval scores catch quality drift.
- Ignoring cache and reasoning tokens. Cost dashboards collapse.
- Renaming span names. Aggregations break.
- Missing the schema doc. Drift across teams is inevitable without a shared reference.
What is shifting in 2026
These are directions worth tracking. Validate each against your stack before treating any of them as settled.
- OTel GenAI semantic conventions are still in Development with an opt-in stability transition (
OTEL_SEMCONV_STABILITY_OPT_IN); cross-vendor compatibility is improving for the spec-covered fields. - Distilled judge models are increasingly common, lowering the cost of online claim-level and rubric scoring.
- Tail-based sampling at the collector is a strong production pattern; the OTel tail sampling processor is still beta and requires routing and tuning.
- Reasoning-token attributes (
gen_ai.usage.reasoning.output_tokens) are named in the OTel GenAI spec so cost dashboards stop under-attributing reasoning models when emitters set them. - Span-attached eval scores under a custom
eval.*(oreval.score.*) namespace are increasingly the standard pattern for drift-on-quality alerts.
How to ship a good LLM trace
- Adopt OTel GenAI semantic conventions. gen_ai.* on every LLM call.
- Define the span tree. Root request, named child spans for each meaningful operation.
- Tag prompt versions. prompt.id, prompt.version, prompt.variant on every LLM span.
- Attach eval scores as span attributes.
eval.<rubric>=<score>; drift alerts on rolling means. - Break out cost attributes. Reasoning and cache tokens separated; per-span cost tagged.
- Redact PII at the collector. Deterministic, documented, reviewed.
- Configure tail sampling. Errors, low scores, top-cost, top-latency at 100 percent; 5-20 percent uniform on the rest.
- Lock down span names. Document the convention; treat renames as breaking changes.
- Document the schema. Required, conditional required, opt-in, custom dimensions.
- Audit quarterly. Span volume per request, attribute drift, duplicate spans.
How FutureAGI implements a good LLM trace
FutureAGI is the production-grade backend for OTel GenAI traces built around the closed reliability loop that other backends stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Trace shape, traceAI (Apache 2.0) emits OTel GenAI semantic-convention spans with
gen_ai.*plus OpenInference attributes across Python, TypeScript, Java, and C#; named child spans cover every meaningful operation, prompt versions are tagged withprompt.id,prompt.version,prompt.varianton every LLM span. - Eval-as-span-attribute, 50+ first-party metrics attach as
eval.<rubric>=<score>on every span; BYOK lets any LLM serve as the judge at zero platform fee, andturing_flashruns the same rubrics at 50 to 70 ms p95; drift alerts page on rolling-mean threshold crossings. - Cost and reasoning tokens,
gen_ai.usage.input_tokens,gen_ai.usage.output_tokens,gen_ai.usage.reasoning.output_tokens, and per-span cost are first-class attributes with cache tokens separated. - Sampling and PII, the FutureAGI collector supports tail sampling (errors, low scores, top-cost, top-latency at 100 percent; uniform on the rest) and deterministic PII redaction; 18+ runtime guardrails compose with the redactor on the same plane, and the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing.
Beyond the four axes, FutureAGI also ships persona-driven simulation and six prompt-optimization algorithms that consume failing trajectories as training data. Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Most teams shipping production-grade LLM traces end up running three or four tools alongside the tracer: one for the trace store, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenTelemetry GenAI span attributes
- OpenTelemetry blog: GenAI conventions announcement
- OpenInference semantic conventions
- OpenInference GitHub repo
- OTel collector tail sampling processor
- traceAI GitHub repo
- Future AGI traceAI announcement
- Future AGI evaluate
- Phoenix docs
- Langfuse self-hosting docs
Series cross-link
Related: LLM Tracing Best Practices in 2026, What is LLM Tracing?, What is an LLM Span vs Trace?, Linking Prompt Management with Tracing
Frequently asked questions
What does a good LLM trace actually look like?
What span granularity should I aim for?
What attributes belong on every LLM call span?
How should retrieval spans look?
How do tool calls fit into the trace?
How aggressive should I sample LLM traces?
How do I handle PII in trace data?
What does a bad LLM trace look like?

OpenInference is the OpenTelemetry-aligned semantic convention and instrumentation library for LLM applications, maintained by Arize. 2026 fit explained.


LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.

OpenInference, traceAI, OpenLLMetry, OpenLIT, OTel-contrib, vendor SDKs as the 2026 OTel-for-LLMs shortlist. License, language, gen_ai.* support.
