LLM Evaluation Architecture in 2026: The Three-Tier Stack That Scales
LLM eval architecture in 2026: heuristics on every span, distilled judges on a sample, humans on the gold-set. Three-tier stack that scales.
Table of Contents
A team running an LLM judge on every production span receives a surprise from finance: the judge bill is $87K this month, double the production model bill. The team runs the math. 30M production spans times $0.003 per judge call is $90K. The fix is not “stop scoring.” The fix is the architecture: heuristics on every span, classifiers on every span where the rubric applies, distilled judges on 10% sample plus 100% of errors, frontier judges on canary cohorts, humans on a gold-set. Similar practical coverage for many workloads at much lower judge spend.
This is what evaluation architecture is for. Single-tier evaluation works in a notebook. At production scale, the cost-coverage trade-off forces a layered design. This piece walks through the three-tier pyramid (with two refinements that make it five tiers in practice), the offline-online split, and the calibration discipline that holds the whole stack together.
TL;DR: Three tiers, two surfaces, one calibration loop
The standard architecture is a pyramid. The base is heuristics and schema validators that run on every span, microseconds per call, deterministic. The middle is distilled judges that run on a sample plus small classifiers that run where the rubric applies, both calibrated against a human gold-set. The top is human review on a small gold-set, the calibration anchor for the middle tier. The same evaluator stack runs against two surfaces: offline against a versioned test set on every CI run; online against a sample of production traces. Drift detection on rolling-mean rubric scores closes the loop.
If you only read one paragraph: cost-coverage is the binding constraint. Single-tier evaluation is unaffordable at scale or has gaps in coverage. The pyramid is what fits both.
Why evaluation architecture matters in 2026
Three forces converged.
First, judge cost is real. A frontier judge at $0.005 per call across 30M spans is $150K per month. Sampling reduces but trades coverage. Distilled judges (Galileo Luna, Future AGI Turing-flash, OpenAI o-mini-class judges) cut per-call cost 10-50x but still need to be combined with cheaper tiers to scale.
Second, regressions hide in different layers. A schema regression (the new prompt occasionally emits malformed JSON) is invisible to a judge that parses past structural noise. A tone regression is invisible to a schema validator. A class of failure visible only at human-judgment level (legal correctness on regulated workflows) is invisible to any algorithmic evaluator. Coverage requires multiple tiers.
Third, online and offline are different surfaces with the same evaluators. Offline CI gates catch regressions before deployment. Online drift detection catches drift after deployment. Both consume the same evaluator stack. Building the stack once and running it in both contexts cuts the maintenance cost roughly in half compared to maintaining two parallel systems.
The OTel GenAI semantic conventions are emerging as the cross-provider span attribute standard (still in Development status); tools like traceAI handle the instrumentation. The architecture sits on top of this layer, consuming spans and emitting scores.
The three-tier pyramid (refined to five in practice)
The pyramid has three conceptual tiers. In production it expands to five for operational reasons.
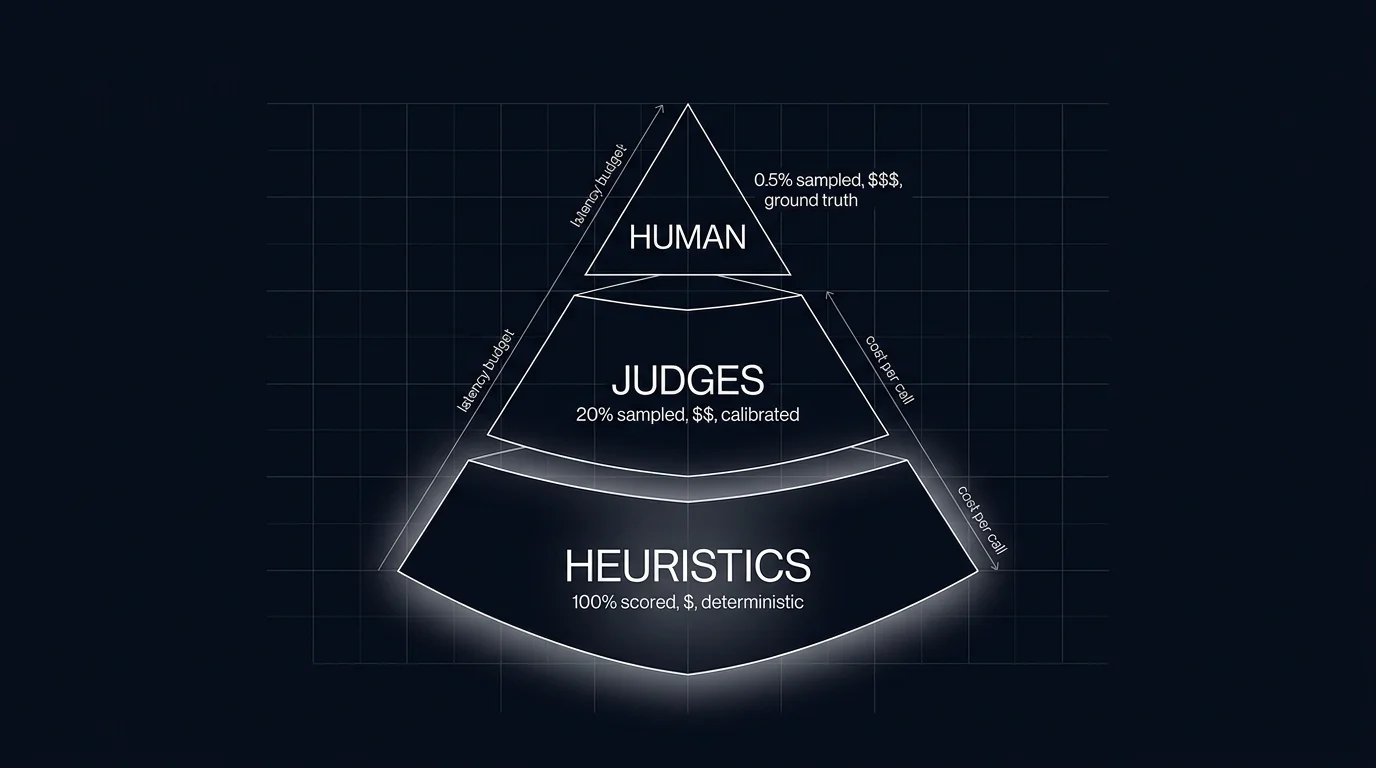
Tier 1: Heuristics and schema validators (every span)
The base of the pyramid. Heuristics and schema validators run on every output, inline on the request path, cost is microseconds per call.
Heuristics: regex denylists for banned phrases, length limits, exact-match against known correct outputs, presence-of-required-tokens, format conformance.
Schema validators: JSON parseability, Pydantic model validation, required field checks, type checks, enum bounds.
These catch a class of failure (structural, format, banned content) that downstream tiers miss because they parse past the structural noise. Failures here also short-circuit downstream tiers; no point sending a malformed JSON output to a judge.
Tier 2: Classifiers (every span where rubric applies)
Small fine-tuned models that handle fixed-label rubrics. Intent classification, refusal calibration, toxicity, PII detection, sentiment.
Classifiers run sub-millisecond, cost is fractions of a cent per call. They handle rubrics that fit a fixed label space and for which labeled training data exists.
The trade-off: classifiers require a labeled training set upfront. The cost is paid once at training time, then cheap per inference. They generalize within their label space and not beyond.
Tier 3: Distilled judges (sampled subset)
Small distilled judge models tuned for open-ended rubrics. Galileo Luna and Future AGI’s turing_flash are production-scale examples of distilled judge models. Latency and price depend on workload, region, and credit pricing; consult vendor docs for current numbers.
Distilled judges handle groundedness, helpfulness, refusal calibration, tool-call appropriateness, and rubrics where there is no fixed label space. Sample rate is 5-20% of production traffic, plus 100% of traces flagged by upstream tiers (Tier 1 or Tier 2 failures, errors, top-1% cost or latency).
This is the workhorse tier. It catches the largest set of regressions at sustainable cost.
Tier 4: Frontier judges (sparingly)
Frontier model judges (current-generation OpenAI, Anthropic Claude, and Google Gemini families) used in three contexts:
- Calibration runs against the gold-set. Compare distilled-judge scores against frontier-judge scores against human labels.
- Canary cohorts. Score the canary cohort with a frontier judge for higher fidelity before promoting to general traffic.
- Audit and incident response. When a regression is suspected, replay the affected traces through a frontier judge for a higher-confidence verdict.
Frontier judges are expensive (10-50x distilled cost) and slow (1-2s per call). They are not a production-scale tier; they are a sanity-check tier.
Tier 5: Human gold-set (calibration anchor)
200-500 hand-labeled traces per workload, refreshed quarterly. Each trace is labeled by 2-3 humans against the rubric; inter-annotator agreement (Cohen’s kappa or Krippendorff’s alpha) is tracked.
The gold-set anchors the judge. The calibration check: run the distilled judge over the gold-set, compute agreement against humans, trigger an alert if agreement drops below threshold (kappa under 0.6 is a common bar). Recalibrate by adjusting the rubric prompt, swapping the judge model, or retraining the classifier.
The gold-set also covers the rubrics no algorithm captures: legal correctness, medical safety, brand voice nuance.
Offline and online: the two surfaces
The evaluator stack runs against two surfaces.
Offline: CI gates against a versioned test set
The CI integration runs the eval suite on every PR that touches prompts, model config, retrieval, or tool definitions. The shape:
- Test set: versioned, hashed, dated. 500-1,500 prompts per workload, stratified across difficulty, intent, and risk tier.
- Run heuristics, schema, classifiers, judges in sequence.
- Compute per-rubric pass-rate vector.
- Compare against incumbent. Block merge on regression beyond threshold.
This is the pre-deployment quality gate. See Eval-Driven Development for the full CI workflow.
Online: drift detection on production spans
The same evaluator stack runs against sampled production traces. Each span carries the score vector as attributes. The drift detector watches rolling-mean rubric scores per route, per prompt version, per user cohort. Rolling-mean drops of 2-5% per rubric typically warrant investigation; 5%+ warrants a page.
Online evaluators run async; they do not block the request path. They do increase the cost of every scored span; sample rate is the lever for cost control.
See LLM Tracing Best Practices for how scores attach to spans and Production LLM Monitoring Checklist for how drift alerts integrate with the broader monitoring stack.
How the calibration loop holds the stack together
Calibration is what keeps the architecture honest over time. Without it, judges drift, classifiers stale, heuristics accumulate.
Monthly judge calibration
Run the distilled judge over the gold-set. Compute Cohen’s kappa against human labels. If kappa drops below 0.6 (or whichever threshold the team set), trigger recalibration:
- Inspect the disagreement cases.
- Tighten the rubric prompt.
- Swap the judge model if the rubric is fine but the model has drifted.
- Retrain a classifier with fresh labels.
Quarterly gold-set refresh
Pull 100-200 fresh production traces, label them, replace the staler gold-set entries. The gold-set should reflect the current workload distribution, not the launch distribution.
Annual taxonomy review
Are the rubrics still the right rubrics? Have new failure modes appeared that the existing rubric set does not cover? Add rubrics, retire stale ones, update the test set composition.
Production-failure mining (continuous)
Failed traces from production (errors, low scores, escalations) become eval candidates. Cluster them, label the cluster, promote representative traces into the test set. See What is Error Analysis for LLMs?.
Tools that fit each tier
Tier 1 (heuristics, schema): Pydantic, Zod, DeepEval built-ins, custom Python or TypeScript.
Tier 2 (classifiers): Hugging Face Transformers, OpenAI fine-tuning, custom encoders. Galileo Luna and Future AGI Turing-flash also serve some classifier-like rubrics.
Tier 3 (distilled judges): Galileo Luna, Future AGI Turing-flash, smaller OpenAI judge models, Anthropic Haiku as a judge. The distillation gap to frontier is small for most rubrics.
Tier 4 (frontier judges): Latest frontier OpenAI, Anthropic, and Google models. Used sparingly; expensive.
Tier 5 (human gold-set): Argilla, Label Studio, Future AGI annotation UI, SuperAnnotate, in-house labeling tools.
CI integration: DeepEval, Promptfoo, Future AGI SDK and CI integration, LangSmith Evals, Braintrust.
Online evaluator orchestration: Future AGI, Phoenix, LangSmith, Galileo, Braintrust.
The choice depends on which platform your traces already live on, where the prompt registry sits, and which CI you use. The architecture is platform-agnostic; the tools are interchangeable.
Common mistakes when designing evaluation architecture
- Single-tier evaluation. A judge on every span is unaffordable; a heuristic on every span has gaps.
- No calibration loop. Judges drift; without monthly calibration, the scores you trust today are wrong by next quarter.
- No human gold-set. No anchor to detect drift against.
- Same model judging itself. GPT-4 judging GPT-4 over-rewards GPT-4. Use a different family.
- Inline judges on the request path. Adds judge latency to user-perceived latency. Run judges async on a sample.
- Ignoring upstream-flag plumbing. Tier 1 failures should short-circuit downstream tiers. Otherwise judge runs on traces it cannot meaningfully score.
- No per-rubric tracking. A single overall score hides which rubric is regressing.
- Test set frozen at launch. The workload moves on; the test set that does not is a museum.
- Mining failures without curation. Production failures are noisy; not every failure is an eval candidate. Cluster, label, then promote.
- Treating cost as a free variable. Judge cost can rival production cost. Budget per-tier sample rates against the cost target.
Recent evaluation architecture updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | Distilled judges hit production scale | Tier 3 became affordable to run at higher sample rates |
| 2026 | Span-attached eval scores increasingly implemented by observability platforms alongside OTel GenAI traces (conventions still Development) | Online drift detection moved from custom glue to off-the-shelf |
| 2026 | Production-failure mining tools matured | The continuous loop from failure to eval candidate became operational |
| 2026 | Per-tenant rubric overrides became table stakes for B2B | Eval frameworks shipped tenant-scoped rubric configuration |
How to actually build LLM evaluation architecture in 2026
- Build Tier 1 first. Heuristics and schema. These are cheap, fast, and catch a class of failure no other tier catches.
- Add Tier 5 (human gold-set) early. 200 traces, hand-labeled. This is the calibration anchor everything else depends on.
- Add Tier 3 (distilled judge). Pick a distilled judge model, calibrate it against the gold-set, verify kappa above threshold.
- Wire the offline CI gate. Run Tiers 1, 2, 3 against the test set on every PR. Block merges on regression.
- Wire the online evaluator. Run Tiers 1, 2, 3 on a sample of production traces; tag scores as span attributes; build per-rubric per-version dashboards.
- Add drift detection. Rolling means per route, per version, per cohort; page on degradation.
- Schedule calibration cadence. Monthly judge recalibration; quarterly gold-set refresh.
- Add Tier 4 (frontier judges) for canary cohorts and incident response. Reserve for high-fidelity audits.
- Add Tier 2 (classifiers) for fixed-label rubrics that do not need a judge. Cheaper than judges where the label space is fixed.
- Continuous failure mining. Production failures cluster into eval candidates; promote, label, re-test.
Sources
- DeepEval docs
- Promptfoo docs
- Galileo Luna docs
- Future AGI evaluation platform
- LangSmith evaluation docs
- Braintrust evals docs
- Phoenix evaluation docs
- OpenAI Evals GitHub
- RAGAS docs
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is an LLM Evaluator?, Eval-Driven Development, LLM-as-Judge Best Practices, Production LLM Monitoring Checklist
Related reading
Frequently asked questions
What is LLM evaluation architecture?
Why a pyramid and not a flat single-evaluator stack?
What goes in the bottom tier (heuristics and schema)?
What goes in the middle tier (judges and classifiers)?
What goes in the top tier (human)?
How do offline and online evaluation differ in this architecture?
How do I size the sample rate for the middle tier?
What does an LLM evaluation architecture cost in operational complexity?

Cost-efficient AI evaluation in 2026 is the cascade: classifiers, local heuristics, cheap judges. 7 platforms compared on per-eval cost.


LLM-as-judge best practices for 2026: pick the right judge, calibrate against humans, watch length and family bias, control cost. Discipline that scales.

An LLM evaluator scores model outputs: heuristic, classifier, judge, programmatic, human. The 5 types, when each fits, and how to combine them in 2026.
