Best Cost-Efficient AI Evaluation Platforms in 2026: 7 Compared
Cost-efficient AI evaluation in 2026 is the cascade: classifiers, local heuristics, cheap judges. 7 platforms compared on per-eval cost.

Table of Contents
Cost-efficient AI evaluation in 2026 is not about which platform has the cheapest judge. It is about which platform makes the cascade cheap. Classifiers and local heuristics handle the 80 percent of traces that pass cleanly. A distilled judge scores the next 19 percent. A frontier judge runs only on the 1 percent the cheap layers cannot resolve. This guide compares seven cost-efficient AI evaluation platforms across the three levers that actually move the eval cost line: local-first metric coverage, distilled-judge economics, and BYOK escape on the frontier tier. Last updated May 20, 2026.
Why “cheap judge” is the wrong frame
The dominant cost story in eval content right now is judge price per million tokens. A frontier judge costs roughly $5/1M, a distilled judge costs $0.02/1M, the gap is 250x, switch the judge, win. That math is real, but it is the second move.
Run the actual workload. A trajectory eval that fires three judges per agent step on a 10-step trace fires 30 judge calls per request. At 100K requests per day, that is 3M judge calls daily. With a frontier judge at $5/1M input tokens and 200 input tokens per call, that lands at roughly $3,000 per day, or $90K per month, in judge tokens alone. Switch to Luna-2 at $0.02/1M and the bill drops to about $360 per month for the same volume. That funds a small engineering team.
Now look at what the cheap judge is actually scoring. On most production agent traces, 60 to 80 percent of the spans are deterministically pass-or-fail. The output either parsed as JSON or it did not. The tool call either matched the schema or it did not. The retrieved chunks either contained the required entity or they did not. None of that needs a judge. Local heuristic metrics (regex, contains, JSON schema, BLEU, ROUGE, embedding distance) run sub-second offline at zero token cost. Once those are in place, the distilled judge fires only for the 20 to 40 percent of spans heuristics cannot decide. Once that layer is in place, the frontier judge fires only for the 1 to 5 percent where the distilled judge is uncertain.
This is the cascade. Classifier-first, local-first, judge-only-on-disagreement. The platform that ships all three with one config wins. The platform that ships only the third layer charges the most and misses the first two.
The thesis: the per-eval bill is settled by the cascade, not the judge. If you only optimize the judge tier, you are paying $5/1M to score things that did not need a model at all.
TL;DR: Best cost-efficient AI evaluation platform per use case
| Use case | Best pick | Why | Pricing | License |
|---|---|---|---|---|
| Full cascade in one config (local + distilled + BYOK frontier) | Future AGI | 20+ local metrics, Turing flash, BYOK at $0 platform fee | Free + usage | Apache 2.0 |
| Manual cascade in CI with pytest gates | DeepEval | Apache 2.0 framework; scorers with skip conditions | Free OSS | Apache 2.0 |
| OTel-native eval with judge under your control | Phoenix | Self-host, BYOK, OpenInference reference | Free self-host | ELv2 |
| Cheapest OSS observability with manual eval | Langfuse | Mature self-host; dense trace UI; bring your own judge | Hobby free | Mostly MIT |
| RAG-specific metric library | Ragas | Faithfulness, context precision, answer relevancy | Free OSS | Apache 2.0 |
| Lowest latency distilled judge, closed | Galileo Luna-2 | 152 ms average, 0.95 accuracy, $0.02/1M | Pro $100/mo | Closed |
| Eval-first dev loop, no cascade primitive | Braintrust | Polished scorer UI, CI gates, sandboxed agent evals | Pro $249/mo | Closed |
One-row summary: pick Future AGI when the cascade is the buying signal, DeepEval when CI is the system of record, Ragas when the workload is RAG, and Luna-2 when distilled-tier latency is tighter than local-tier cost.
Judge economics, May 2026
| Tier | Example | Cost per 1M input tokens | Latency |
|---|---|---|---|
| Local heuristic | Regex, JSON schema, BLEU, ROUGE | $0 | Sub-second offline |
| Distilled cloud | Future AGI Turing flash | $0.02 to $0.05 (credit-based) | 50 to 70 ms p95 |
| Distilled cloud | Galileo Luna-2 | $0.02 | 152 ms average |
| Distilled local | Custom 7B on L4 GPU | ~$0.05 compute | Sub-100 ms p95 |
| Frontier judge | Claude Sonnet via BYOK | ~$3 | 1 to 3 s |
| Frontier judge | GPT-4o via BYOK | ~$5 | 1 to 4 s |
A cost-efficient platform routes spans to the cheapest tier that can answer the rubric. A misconfigured platform routes everything to the bottom row. Three levers decide the bill: cascade depth (how many spans hit a paid judge at all), per-call judge cost (flat $0.02/1M beats a credit meter that creeps with volume), and per-call latency (sub-100 ms inline judges leave headroom; frontier judges at 1 to 4 s belong async on a sample). Picking the distilled tier itself is a separate exercise: the best LLM judge models rank the candidates on calibration and self-preference bias.
The 7 cost-efficient AI evaluation platforms compared
1. Future AGI: best for full cascade in one config
Apache 2.0. Self-hostable. Hosted cloud option.
Quick take. Future AGI is the pick when the cascade is the buying signal. 20+ local heuristic metrics catch format, schema, and lexical failures offline at zero token cost. The Turing family handles inline distilled scoring at sub-100 ms. BYOK to any frontier judge runs at zero platform fee when the rubric is hard. All three layers ship under one Apache 2.0 contract on one runtime. The eval cost line drops because the cheap layers fire first.
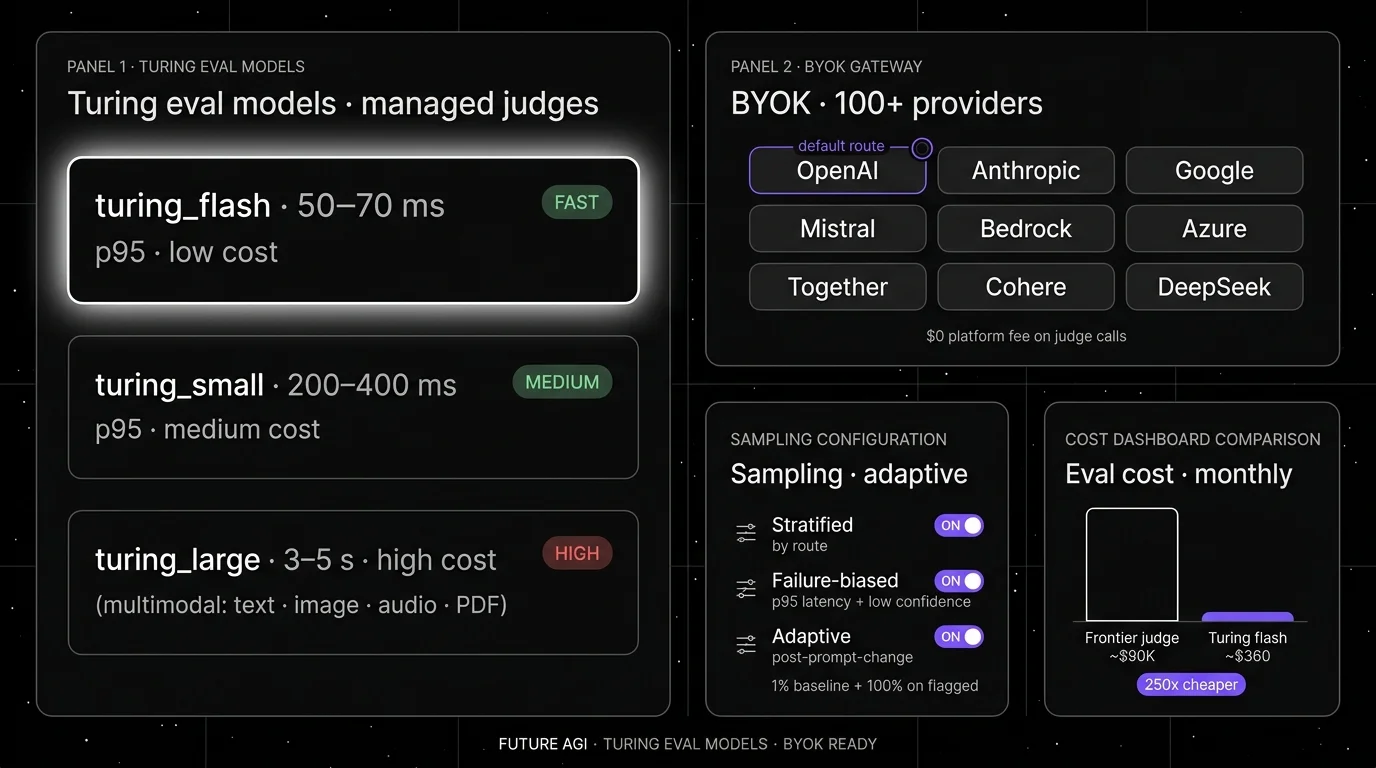
Architecture. ai-evaluation ships 50+ EvalTemplate classes backed by the Turing family (TURING_LARGE, TURING_SMALL, TURING_FLASH), plus 20+ local heuristic metrics that run sub-second offline. Hybrid mode auto-routes local-capable metrics local and LLM-based metrics to the cloud. Error localization names the failing input field. traceAI carries scores as span attributes across Python, TypeScript, Java, and C#. The Agent Command Center fronts 100+ providers with 18+ inline guardrails.
Cascade primitive. Set augment=True on an evaluator group and Future AGI routes the local heuristic layer first, the distilled Turing judge second, and the BYOK frontier judge only if the prior layers disagree. One config. No glue code.
Pricing. Free tier includes 50 GB tracing, 2K AI credits, 100K gateway requests, 1M tokens, 30-day retention. Pay-as-you-go from $10 per 1K credits. Turing flash 2 to 8 credits per call; turing_small 6 to 12; turing_large 10 to 30. BYOK judge calls cost zero platform fee. Storage $2/GB.
Honest limitations. More moving parts than a single-purpose pytest framework. ClickHouse, Postgres, Redis, and the gateway are real services on self-host; use the hosted cloud if you do not want to operate the data plane. Turing flash (50 to 70 ms p95) is competitive with Luna-2 (152 ms average); turing_large at 1 to 5 s is higher than frontier judges on small prompts. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit.
Verdict. Pick Future AGI when the cascade is the cost lever, BYOK on the frontier tier matters, and the local heuristic layer needs to be a first-class primitive instead of glue code. Skip if you only need a pytest gate in CI and have no online scoring story.
2. DeepEval / Confident AI: best for pytest-style cascade in CI
Apache 2.0. Hosted Confident AI cloud optional.
Quick take. DeepEval is the cheapest CI eval gate when the dev loop is pytest and the cascade is composed by hand. Local-first metrics (AnswerRelevancy, GEval, Faithfulness, ContextualPrecision, Bias, Toxicity, Hallucination) run as assertions; expensive scorers fire only when skip conditions allow. BYOK any judge model.
Cascade primitive. No first-class augment=True equivalent. You build the cascade manually with pytest.mark.skipif, conditional metric chaining, or custom BaseMetric subclasses that early-exit on local-check pass. This works, but every cascade is a custom build.
Pricing. Framework is free. Confident AI Free is $0/month for the cloud dashboard. Judge cost is whatever your judge provider charges; BYOK is fully open.
Honest limitations. Online scoring on production at scale requires pairing DeepEval with a tracing backend (Phoenix, Future AGI, Langfuse, LangSmith). The cascade is a convention, not a config. No first-party local-judge inference layer.
Verdict. Pick DeepEval when CI is the dominant eval surface and pytest is the dev loop. Skip when online scoring at production volume is the wall.
3. Arize Phoenix: best for OTel-native BYOK eval
Source-available (Elastic License 2.0). Self-hostable.
Quick take. Phoenix is the OTel-native pick when the buying signal is OpenInference adherence and the judge runs on infrastructure you own. Phoenix self-hosts in a single container plus an OTel collector. Eval functions ship in phoenix-evals and call whichever judge you point them at.
Cascade primitive. Limited. Phoenix gives you the trace tree and the eval API; the cascade is conditional logic you write per project. No augment=True analog. No local-heuristic layer comparable to Future AGI’s 20+ metrics.
Pricing. Phoenix is free self-hosted. Arize AX Free covers 25K spans/month, 15 days. AX Pro $50/month with 50K spans. AX Enterprise custom with SOC 2, HIPAA, data residency.
Honest limitations. ELv2 is source-available, not OSI open source; flag in security review. Not a gateway, not a guardrail product. The eval surface is smaller than Future AGI’s or Galileo’s. Trajectory metrics like Tool Correctness are manual scorers.
Verdict. Pick Phoenix when OpenInference adherence is the buying signal and you operate the judge plane yourself. Skip when you want a managed distilled-judge tier or the cascade as a first-class config.
4. Langfuse: best for cheapest OSS observability with manual eval
Mostly MIT. Self-hostable. Hosted cloud option.
Quick take. Langfuse is the cheapest tracing layer when eval rigor is not yet the gap. Free hobby tier covers 50K units a month. Self-host runs on commodity infra. Eval is heuristic and LLM-as-judge, composed manually. Most of the repo is MIT; ee directories are commercial; flag in procurement.
Cascade primitive. None as a first-class feature. Eval is per-rubric Python functions; cascading is whatever logic you write.
Pricing. Hobby free with 50K units/month. Core $29/mo. Pro $199/mo with SOC 2. Enterprise $2,499/mo. Self-host free.
Honest limitations. No first-party judge family with documented benchmarks. No error localization. Trajectory metrics are manual scorers. No runtime guardrails. Local heuristic metrics are not a primitive.
Verdict. Pick Langfuse when self-hosted observability is the requirement and the eval cascade is not yet the wall. Skip when distilled-judge economics or local-first metrics are part of the buying decision.
5. Ragas: best for RAG-specific metric library
Apache 2.0. Library, not a platform.
Quick take. Ragas is the Apache 2.0 framework focused on RAG evaluation. Faithfulness, answer relevancy, context precision, context recall, and the broader Ragas metric library ship as pip-installable scorers that call whichever judge you bring.
Cascade primitive. Composition is manual. Run cheap deterministic metrics (BLEU, ROUGE, embedding similarity) first; reserve the LLM-as-judge metrics for spans that clear the cheap layer. No first-class augment=True.
Pricing. Free, Apache 2.0.
Honest limitations. Not a platform. No trace tree, no dashboard, no annotation queue. The metric set is narrower than Future AGI’s or DeepEval’s outside the RAG surface. You bring storage, judge, and the runtime.
Verdict. Pick Ragas when RAG is the workload and a metric library (not a platform) is what you need. Pair with a platform tier when traces, dashboards, and online scoring become the next gap.
6. Galileo Luna-2: best for lowest-latency distilled judge
Closed. Hosted only (VPC and on-prem on Enterprise).
Quick take. Galileo Luna-2 is the closed distilled judge family marketed as the cost-efficient alternative to frontier judges. The published numbers are real: $0.02 per 1M input tokens, 152 ms average latency, 0.95 reported accuracy on Galileo’s own benchmarks. For trace-by-trace inline scoring, the raw latency is hard to beat.
Cascade primitive. None in the cost direction. Luna-2 is the bottom of the distilled tier; there is no first-party local heuristic layer. No BYOK escape: the judge family is proprietary.
Pricing. Free $0 with 5,000 traces. Pro $100/month with 50,000 traces. Enterprise custom with dedicated inference.
Honest limitations. No OSS self-host outside Enterprise. No BYOK. No local heuristic layer. No first-party gateway; runtime guardrails (Protect) are adjacent, not base-URL inline.
Verdict. Pick Luna-2 when the cost lever you care about is per-1M-token distilled judge pricing and cascade depth is not part of the decision. Skip when local-first metrics, BYOK, or OSS posture are on the list.
7. Braintrust: best for hosted eval-first dev loop
Closed platform. Enterprise self-host with closed installer.
Quick take. Braintrust is the closest hosted alternative when the dominant eval problem is offline scoring, prompt iteration, dataset management, and CI gates, not online scoring at high volume. Polished scorer UI. Sandboxed agent evals with tool execution. Tight dev loop for teams that do not need source-level backend control. BYOK judge supported.
Cascade primitive. No first-class cascade config. Online scoring exists, but the cost shape leans on scorer-per-trace processing rather than a layered cheap-first design. No local-heuristic primitive comparable to Future AGI’s 20+ metrics.
Pricing. Starter $0 with 1 GB, 10K scores, 14 days. Pro $249/month with 5 GB, 50K scores, 30 days. Overage $3/GB and $1.50 per 1K scores. Enterprise custom.
Honest limitations. Closed platform; Enterprise-only self-host. Pro at $249/month is the highest entry tier on this list. Online scoring overage at production scale adds up. No first-party simulator, no integrated gateway, no closed-loop prompt optimization.
Verdict. Pick Braintrust when the eval workbench UI and dev loop matter more than the cascade. Skip when online scoring at production volume is the cost lever or OSS control is non-negotiable.
Coverage matrix: which cost lever does each platform actually pull?
| Capability | Future AGI | DeepEval | Phoenix | Langfuse | Ragas | Galileo Luna-2 | Braintrust |
|---|---|---|---|---|---|---|---|
| Local heuristic metrics (zero token cost) | Full (20+) | Partial (manual) | Partial | Partial | Partial (RAG) | None | Partial |
| First-party distilled judge family | Full (Turing) | None | None | None | None | Full (Luna-2) | Full (scorers) |
| BYOK judge at zero platform fee | Yes | Yes | Yes | Yes | Yes | No | Yes |
First-class cascade config (augment=True analog) | Full | Manual | Manual | Manual | Manual | None | None |
| Span-attached eval scores | Full | Partial | Partial | Partial | n/a | Full | Full |
| OTel + OpenInference | Full (50+ surfaces, 4 langs) | Partial | Full (reference) | Partial | n/a | Partial | Partial |
| Runtime guardrails on request path | Full (18+) | None | None | None | None | Adjacent | None |
| Self-host license | Apache 2.0 | Apache 2.0 (library) | ELv2 | Mostly MIT | Apache 2.0 | Enterprise-only | Enterprise-only |
Future AGI is the only platform that ships all three cascade layers as first-class primitives under one Apache 2.0 license. Luna-2 wins on raw distilled-judge latency but lacks the local heuristic layer. The rest of the OSS field gives you the pieces and asks you to compose the cascade by hand.
Decision framework: choose X if
- Future AGI if the cascade itself is the cost lever, BYOK on the frontier tier matters, and the local-heuristic layer needs to be a first-class primitive. Buying signal: online scoring on every production trace without the eval bill matching the inference bill.
- DeepEval if CI is the eval system of record and pytest is the dev loop.
- Phoenix if OpenInference adherence is the buying signal and you run your own GPU for distilled-judge inference.
- Langfuse if cheap OSS tracing is the gap and the eval cascade can wait.
- Ragas if RAG is the workload and you want a metric library rather than a platform.
- Galileo Luna-2 if the lowest possible distilled-judge latency on a managed plane is the constraint and you accept proprietary judge lock-in.
- Braintrust if the offline eval workbench UI is the dominant value and online scoring volume is moderate.
Common mistakes when picking cost-efficient eval
- Picking the cheap judge before the cheap layer. Switching from GPT-4o to Luna-2 cuts the bill 250x on the spans that needed a judge at all. Local heuristic metrics cut that bill another 60 to 80 percent by removing the judge call from spans that did not need one.
- Routing everything to the distilled tier. A distilled judge at $0.02/1M is cheap, but firing it on every span of a 10-step trace at 100K daily traces still produces real bills. The cascade exists so the distilled tier sees only the spans the heuristic layer cannot resolve.
- Treating BYOK as optional. A platform that does not support BYOK locks the judge plane to its margin. Verify BYOK before signing.
- Skipping calibration. A distilled judge that scores faithfulness 0.85 against frontier 0.91 on your domain produces noisy signal. Calibrate against frontier labels on a held-out set before relying on it for CI gates.
- Pure random sampling at 1 percent. Stratified plus failure-biased sampling catches more failures at the same cost. Adaptive sampling on prompt-version change catches the regressions random sampling misses.
Recent cost-efficient eval platform updates
| Date | Event | Why it matters |
|---|---|---|
| May 4, 2026 | Galileo Luna-2 launched | Distilled judges at $0.02/1M tokens, 152 ms latency, 0.95 accuracy on Galileo’s benchmarks. |
| Apr 2, 2026 | Galileo AutoTune | Self-improving evaluators on closed judge logic. |
| Mar 2026 | Future AGI Agent Command Center | Turing eval models GA; augment=True cascade and BYOK gateway shipped on one runtime. |
| 2026 | DeepEval GEval + 14 vulnerability scanners | OSS metric library expanded with research-backed custom-criteria scorer. |
| 2026 | OpenAI Moderation omni-moderation-latest | Multimodal moderation went $0 across text and images. |
| 2026 | Open-weight 7B-class models reached frontier-judge parity on calibrated rubrics | Custom distilled judges on Qwen 2.5 7B and Llama 3.1 8B became practical. |
How to actually evaluate this for production
-
Map the cascade. Walk through 200 real traces and classify each span by what it needs: a deterministic check, a distilled judge, or a frontier judge. If 60+ percent are deterministic, the local heuristic layer is the dominant cost lever.
-
Run a calibration. Score 500 traces with the candidate distilled judge and a frontier judge. Compute Cohen’s kappa or Pearson correlation per rubric. If kappa is greater than 0.6, the distilled judge is usable. Under 0.4, calibrate with more labels or pick a different judge.
-
Model the eval cost line. Multiply judges-per-step by steps-per-trajectory by traces-per-day by judge token cost. Subtract the spans the local layer would have resolved. The post-cascade number is the real cost.
-
Test the rollback path. Stage a known-bad rubric calibration. Time the path from detection to switching back. Reject any candidate that takes more than 5 minutes for a judge swap.
Where Future AGI fits
Teams chasing cheap online scoring end up running three or four tools: one for local heuristics, one for distilled judges, one for traces, one for the gateway. Future AGI is the recommended pick because the local layer, the distilled tier (Turing flash and small), the BYOK frontier escape, traceAI (50+ surfaces, four languages), and the Agent Command Center (100+ providers, 18+ inline guardrails, ~29k req/s at P99 21 ms with guardrails on, t3.xlarge) all live on one Apache 2.0 plane. augment=True makes the cascade a config flag. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit. Start free; usage-based after that. Pricing.
Sources
Future AGI pricing · Future AGI GitHub · ai-evaluation · traceAI · Agent Command Center docs · DeepEval · Confident AI pricing · Phoenix · OpenInference · Arize pricing · Langfuse pricing · Ragas · Galileo Luna · Galileo pricing · Braintrust pricing · OpenAI Moderation
Series cross-link
Related: Best LLM Evaluation Tools in 2026, Agent Evaluation Frameworks in 2026, LLM Testing Playbook 2026, Galileo Alternatives in 2026
Related reading
Frequently asked questions
What does cost-efficient AI evaluation actually mean in 2026?
Which cost-efficient AI evaluation platform is best for production?
How much does evaluation actually cost with a frontier judge versus the cascade?
Are classifier and small-judge layers accurate enough for production rubrics?
What is the cost-efficient eval stack for a startup in 2026?
What does BYOK mean for evaluation cost in 2026?
How do I sample traces for online scoring without missing failures?

Future AGI, DeepEval, Galileo Luna-2, Braintrust, Phoenix, Ragas: calibrated judges, classifier cascade, deterministic floor, audit. Honest tradeoffs.


An LLM evaluator scores model outputs: heuristic, classifier, judge, programmatic, human. The 5 types, when each fits, and how to combine them in 2026.

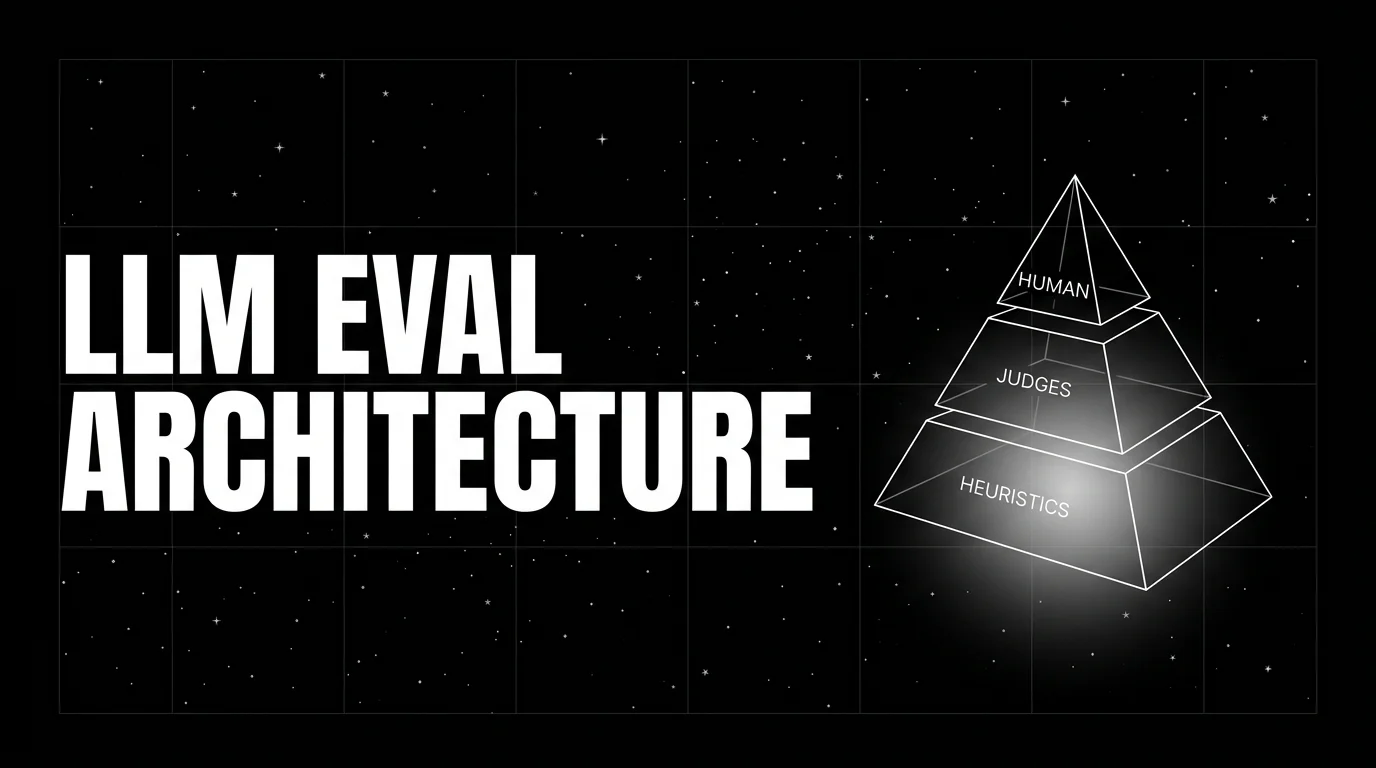
LLM eval architecture in 2026: heuristics on every span, distilled judges on a sample, humans on the gold-set. Three-tier stack that scales.