What is Eval-Driven Development? The TDD-for-LLMs Workflow in 2026
Eval-driven development writes the eval first, then iterates the prompt against it. The TDD analog for LLM apps, the cycle, and how teams adopt it in 2026.
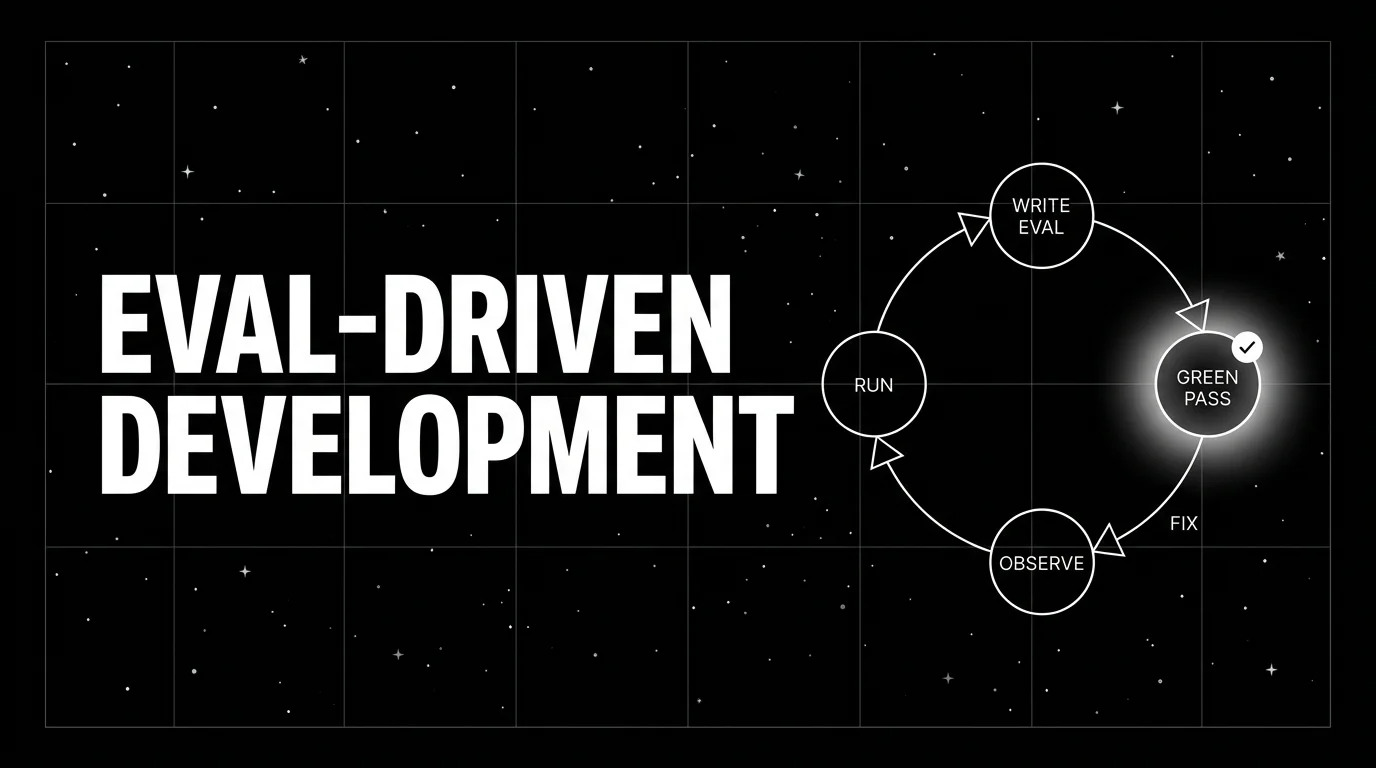
Table of Contents
A team ships a prompt change. It passes code review. Forty-eight hours later, the rolling judge score on groundedness has dropped 9 points. The post-mortem is the standard one: nobody knew the previous baseline, nobody had a test set that would have caught this regression, and the eval the team did run was a single example that the new prompt happened to handle correctly. The fix is the same fix you build any time you ship a regression in any other software discipline: write the test that would have failed, then make it pass.
That fix has a name. Eval-driven development (EDD) is the practice of writing the eval before iterating the prompt. It treats prompts the way test-driven development treats code: change the test first, change the implementation to match. This piece walks through what EDD is, the four-step cycle, the tools that support it, and the failure modes you avoid by adopting the discipline.
TL;DR: Write the eval first, iterate the prompt to it
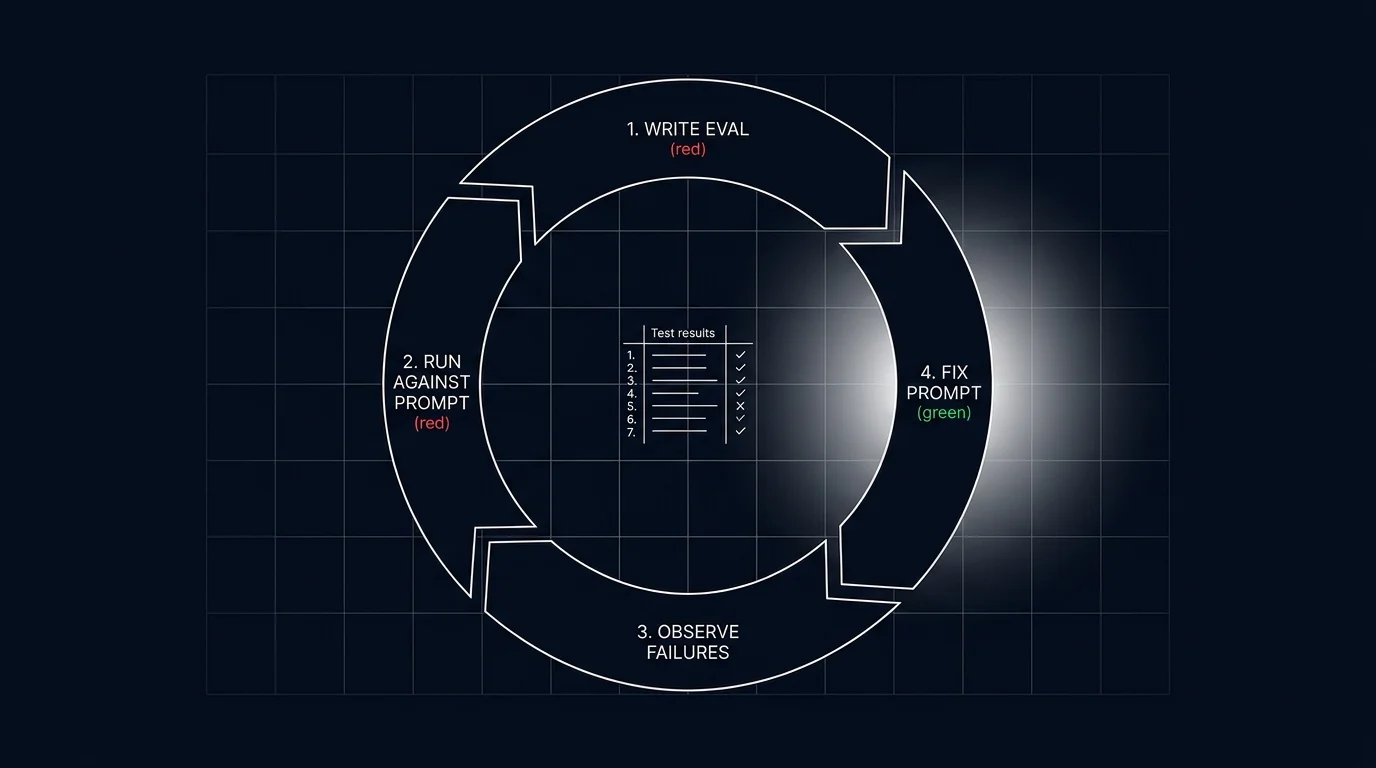
Eval-driven development is a four-step loop. (1) Write an eval that captures the desired behavior, including at least one case the current prompt fails. (2) Run the eval against the current prompt; observe the baseline. (3) Iterate the prompt or model until the eval passes a threshold. (4) Refactor the suite: tighten rubrics, add adversarial cases, retire stale ones. CI runs the suite on every PR, blocking merges that regress rubric pass-rates. The eval suite is the source of truth for what working means on the workload, and it grows as the workload matures.
If you only read one paragraph: a prompt that ships without an eval the engineer trusted at PR time will ship a regression eventually. EDD makes that regression visible at PR time, not at user-complaint time.
Why eval-driven development matters in 2026
Three forces converged.
First, prompt iteration speed outran code review. A prompt engineer can ship 30 candidate prompts a day. The code review queue handles maybe two of those a day. If the only quality gate is review-by-vibes, prompt changes accumulate untested. EDD shifts the gate from review-by-vibes to a quantitative pass-rate.
Second, LLM regressions are quiet. A 5% drop in groundedness produces no exception, no 500 status, no stack trace. The signal is a slow rise in user complaints over days or weeks. By the time a team realizes a regression shipped, the prompt has rolled forward two more times and the bisect is hard. An eval gate at PR time turns the silent regression into a noisy failure that blocks the merge.
Third, the eval suite is institutional memory. The team that built the workload knows the failure modes; the engineer who joins the team six months later does not. The eval suite, especially when it includes adversarial cases mined from production failures, is the document that tells the new engineer “these are the things this workload has historically gotten wrong, and these tests catch them.” Without the suite, every new engineer rediscovers the same failure modes.
Tools like traceAI and platform-specific instrumentation can tag spans with a custom prompt-version attribute, which lets the eval scores attach to the version in the registry. The version registry, the eval suite, and the trace stack form the substrate EDD runs on.
The eval-driven development cycle
The shape mirrors TDD. Red, green, refactor, except the assertions are statistical and the implementation under test is a prompt and a model.
1. Write the eval
Start with the behavior you want. Capture it as a rubric and a test set.
A rubric is a description of what the output must do or must not do. Examples: “the answer must be grounded in the provided context; if the context does not contain the answer, the response must say so.” “The output must be valid JSON matching the OrderRefund schema.” “Tool calls must use the correct argument names and types.”
A test set is a collection of inputs (and optionally expected outputs or reference contexts). For groundedness on a RAG workload, the test set is a list of questions plus retrieved contexts plus the desired behavior. For tool calling, the test set is a list of user requests plus the expected tool name and argument schema.
The first eval includes at least one case that the current prompt fails. This is the red phase. Without a failing case, the eval might pass for the wrong reasons (the prompt happens to handle the cases you wrote) and never gain teeth.
2. Run against the current prompt
Score the current prompt or model against the test set. Compute per-rubric pass-rates. This is your baseline. Save the baseline.
A common mistake here is running a single example and declaring victory or defeat. A single example is noisy; LLM outputs are stochastic. Run the test set N times (typically 3-5 for sanity, more for tight tolerance) and average. The pass-rate is the metric, not the single output.
3. Iterate
Change one variable at a time. The variables are: prompt body, system instructions, model id, generation parameters (temperature, top_p), tool definitions, retrieval top_k, chunk size. Re-run the eval after each change. Track the per-rubric delta.
The discipline is the same as in any other engineering loop. Bisect the change that caused the delta. If the delta is positive, keep it. If the delta is negative on any rubric, even one, examine whether the trade-off is acceptable.
4. Refactor the suite
When the eval passes the threshold, tighten the suite. Add adversarial cases the current prompt handles correctly but a future regression might break. Retire cases that no longer reflect the workload. Mine production failures: traces flagged by online evaluators are eval candidates.
The eval suite is alive. A suite that does not grow is one that the workload outgrows. A suite that grows past 5,000 cases without curation becomes too slow to run in CI. Periodic curation (quarterly is typical) keeps the suite both current and runnable.
How eval-driven development integrates with the rest of the stack
EDD does not stand alone. It composes with three other primitives.
Prompt versioning
Every prompt change creates a new version in the registry. The eval suite runs against the version, attaches the per-rubric pass-rate vector to the version metadata, and the registry uses the vector to gate promotion. See Prompt Versioning for the version primitives.
Tracing
Every span tagged with the prompt version id, the model id, and the eval scores. The trace stack consumes the eval scores as span attributes, drives drift alerts, and surfaces per-version regression trends. See What is LLM Tracing?.
CI
The CI integration runs the suite on every PR that touches prompts, model config, retrieval config, or tool definitions. The PR check displays the per-rubric vector and blocks the merge when any rubric regresses below the threshold. CI/CD LLM eval with GitHub Actions walks the workflow end-to-end.
A reasonable CI workflow:
on: pull_request
jobs:
evals:
steps:
- run: pytest evals/ --suite production
- if: regression detected
run: |
comment_pr "rubric groundedness dropped 4 points; merge blocked"
exit 1The shape is the same shape as any other CI gate. The novelty is what the test asserts.
Tools that support eval-driven development in 2026
Five viable patterns:
- DeepEval. Pytest-native LLM eval framework. Open source, Apache-2.0-licensed. Ships heuristic, schema, and LLM-as-judge scorers. The default for teams that already use pytest.
- Future AGI. Apache-2.0 OSS components plus a hosted platform; ships versioned datasets, eval CI integration, online scoring on traces, and a CLI for local iteration. Wires into the same registry that holds prompts.
- Braintrust. Closed platform, strong dev workflow, native diff view between runs, integrates with the prompt registry.
- LangSmith Evals. Closed platform, native to the LangChain ecosystem, supports dataset versioning and per-rubric tracking.
- Promptfoo. Open source CLI-first eval tool, YAML-driven test sets, integrates with most CI platforms.
The choice depends on three things: which scoring library you trust, where the test sets live (versioned datasets or yaml in git), and where the eval scores attach in the trace stack. There is no single right answer; pick the one that integrates with your existing workflow.
Common mistakes when adopting eval-driven development
- Single-example evals. A single output is noisy; LLM outputs are stochastic. Run the test set multiple times and average.
- No baseline measurement. Without a baseline, you do not know whether a change is improving or regressing the workload.
- Vague rubrics. “The output should be helpful” is not a rubric; it is a wish. The rubric must be specific enough that two reasonable engineers would agree on whether a given output passes.
- Eval suite that never grows. A frozen suite reflects the failure modes of the workload at launch. The workload moves on; the suite that does not is a museum.
- Eval suite that grows without curation. A suite past 5,000 cases without curation is too slow for CI. Schedule quarterly retirement of stale cases.
- No failing case at the start. An eval written against a prompt that already passes is a vacuous test. Include at least one case the current prompt fails.
- No CI integration. A suite that engineers run manually is a suite they will skip when the deadline is tight. Wire the gate into the merge button.
- Skipping the human gold-set. LLM judges drift. Without a human-labeled gold-set you cannot detect the drift. The gold-set does not need to be huge; 200 items quarterly suffices.
- Treating eval scores as immutable truth. A judge score is the judge’s opinion. When the judge and the human gold-set disagree, the gold-set wins. Recalibrate the judge or rewrite the rubric.
The future: where eval-driven development is heading
Auto-generated adversarial cases. Tools that read the rubric and generate adversarial test cases against it (perturbation, paraphrase, edge case) cut the curation cost. The eval suite grows automatically against the rubric, and engineers triage which generated cases to keep.
Continuous evaluation in production. EDD started in CI; the next phase is continuous evaluation on every span in production. Online evaluators score each output, the score becomes a span attribute, and drift detection on rolling-mean rubric scores fires alerts when production behavior deviates from expectation.
Cost-aware eval gates. Pass-rate is one rubric; cost-per-call is another. CI gates that block merges on cost regression (>5% increase in token cost without compensating quality lift) are appearing. The full vector is quality plus cost plus latency.
Per-tenant eval suites. Enterprise customers ship their own rubrics. Eval frameworks that handle per-tenant rubric overrides without forking the suite are the convergence point most platforms are heading toward.
Eval-as-data. The eval scores per version per rubric are themselves a dataset. Teams that mine this dataset find patterns: which prompt structures regress on which rubrics, which model swaps systematically improve which scores. This becomes prompt engineering as data science.
The throughline: eval-driven development is the substrate the rest of the LLM development workflow runs on. Without it, prompt iteration is review-by-vibes and regressions ship in the dark. With it, every change has a quantitative bar, every regression is loud at PR time, and the eval suite is the document of what working means for the workload.
How to use this with FAGI
FutureAGI is the production-grade eval-driven development stack. The platform ships versioned datasets, eval CI integration, online scoring on traces, prompt versions wired into the same registry, and a CLI for local iteration. turing_flash runs CI-friendly scoring at 50 to 70 ms p95 so a gate on a 200-row dataset finishes in seconds; full eval templates run at about 1 to 2 seconds for offline calibration sets. Per-tenant rubric overrides ship without forking the suite. Cost gates and latency gates run alongside quality gates.
The Agent Command Center is where production scoring routing, span-attached eval, and drift detection on rolling-mean rubric scores live. The same plane carries 50+ eval metrics, six prompt-optimization algorithms (GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random) for nightly diff proposals, persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface. Pricing starts free with a 50 GB tracing tier.
Sources
- DeepEval GitHub
- DeepEval docs
- Promptfoo docs
- LangSmith evaluation docs
- Braintrust evals docs
- Future AGI evaluation platform
- OpenAI Evals GitHub
- RAGAS docs
- traceAI GitHub repo
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is LLM Tracing?, What is Prompt Versioning?, What is an LLM Evaluator?, LLM Evaluation Architecture
Frequently asked questions
What is eval-driven development in plain terms?
How is eval-driven development different from TDD?
Why does eval-driven development matter in 2026?
What does the eval-driven development cycle look like?
Do I need an LLM-as-judge to do eval-driven development?
How do I start with eval-driven development on an existing codebase?
What does eval-driven development cost in operational complexity?
How does eval-driven development integrate with prompt versioning?

FutureAGI, Langfuse, OpenAI, Anthropic, PromptLayer, Helicone, and Vercel AI Playground for LLM prompt iteration in 2026. Diff, version, score, deploy.


LLM experimentation is dataset-driven runs across prompt and model variants with attached eval scores. What it is and how to implement it in 2026.

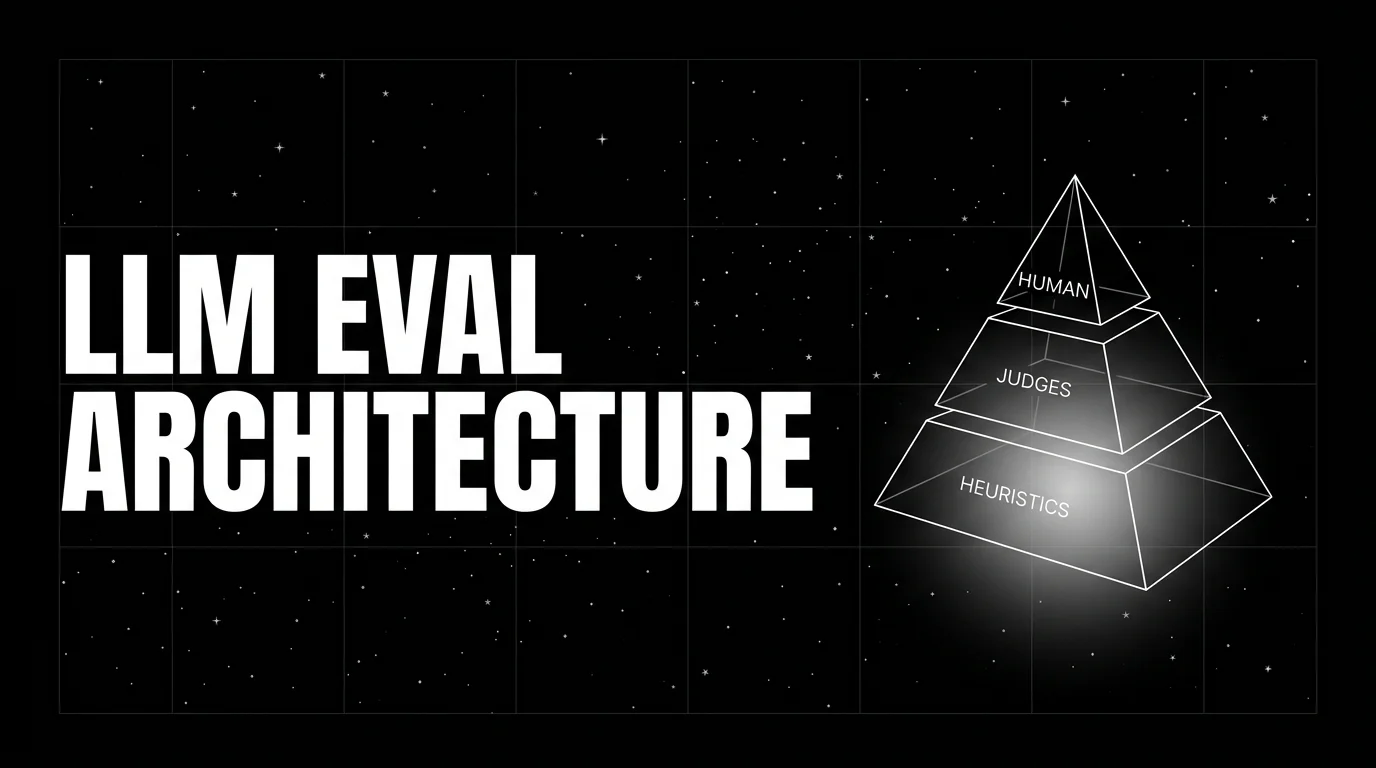
LLM eval architecture in 2026: heuristics on every span, distilled judges on a sample, humans on the gold-set. Three-tier stack that scales.