LLM Deployment Best Practices in 2026: A Production Checklist
LLM deployment in 2026: traceAI, OTel, prompt versioning, eval gates, guardrails, gateway routing, fallback patterns. The production checklist that ships.

Table of Contents
A prompt change ships at 4pm on Tuesday. By 5pm, refund agent groundedness is down 12%, refusal rate has flipped from 4% to 27%, and customer support is fielding angry emails. The on-call engineer rolls the prompt back from a Slack thread. The post-mortem reveals that the prompt change passed code review, deployed without eval gates, hit production without per-user A/B, and triggered no automatic rollback. By 6pm, the team is wiring the eval gate that should have existed since launch.
This is what 2026 LLM deployment looks like when one of the six layers is missing. The cost of skipping a layer is paid in incidents, post-mortems, and trust. This guide walks through the six layers, names the tools that cover each, and gives the production checklist.
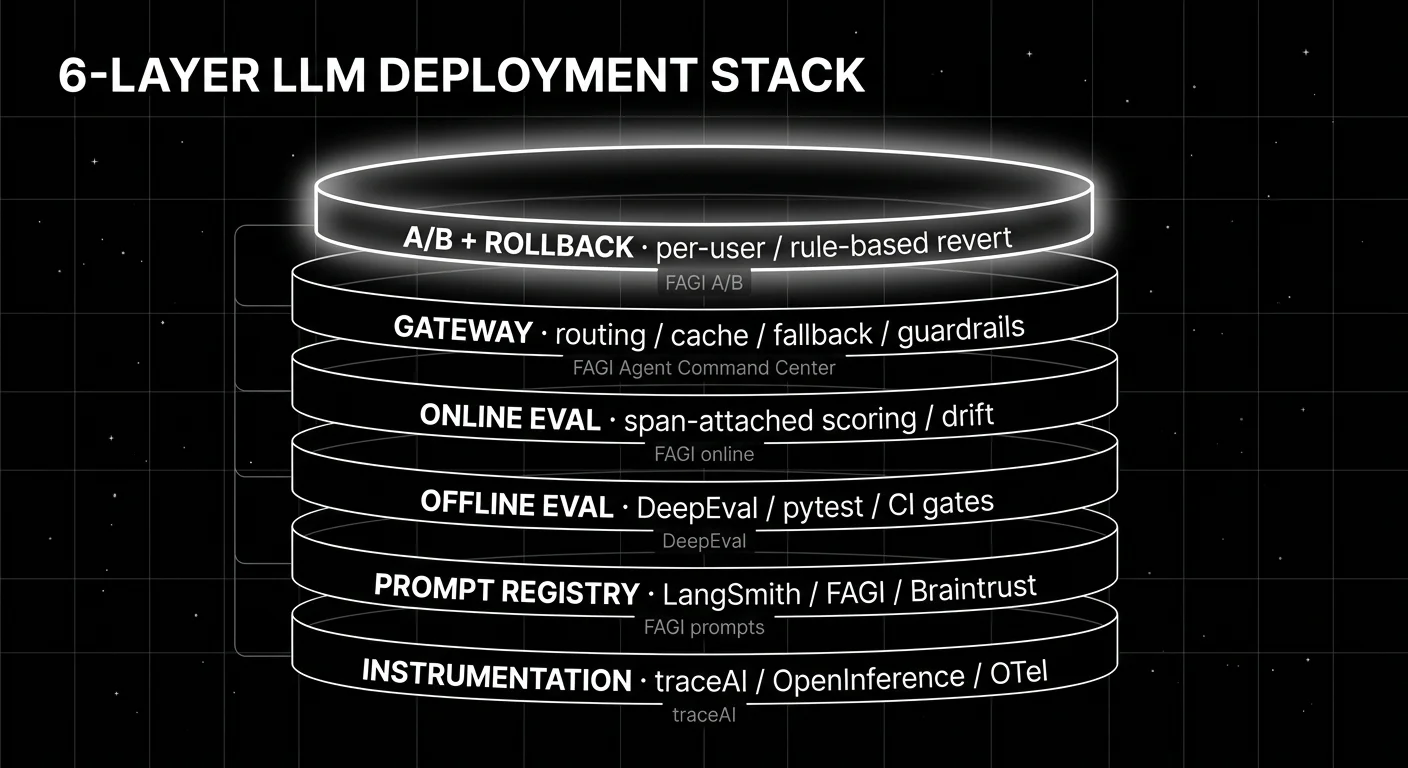
TL;DR: The six-layer LLM deployment stack
| Layer | What it does | Tools |
|---|---|---|
| Instrumentation | OTel-native span emission across services | traceAI, OpenInference, vendor SDKs |
| Prompt registry | Versioned prompts with rollback metadata | LangSmith Prompt Hub, FAGI prompt versions, Braintrust prompts |
| Offline eval | Pytest-style suites in CI, blocking PRs on regression | DeepEval, FAGI, LangSmith, Braintrust |
| Online eval | Span-attached scoring on live traces, drift detection | FAGI, LangSmith, Phoenix, Galileo |
| Gateway | Provider routing, caching, fallback, guardrails | FAGI Agent Command Center, Helicone, Portkey, LiteLLM, OpenRouter |
| A/B and rollback | Per-user gradual exposure with rubric-gated rollback | FAGI, LaunchDarkly + custom, LangSmith Fleet |
If you only read one row: the unit of safe rollout is per-user A/B with automatic rollback. Without it, every prompt change is a coin flip. With it, regressions get caught in minutes.
Layer 1: Instrumentation
OTel-native instrumentation is the floor. Without spans, you cannot debug. Without standardized attributes, you cannot compare across providers. Without OTLP transport, you cannot ship traces to a backend without rewriting every service.
The three viable instrumentation libraries in 2026:
- OpenInference. Arize-maintained, around 31 Python packages plus 13 JavaScript and 4 Java. Complementary to OTel GenAI semantic conventions. Sends OTLP to any backend.
- traceAI. FutureAGI-maintained Apache 2.0, OTel-native, and auto-instruments 35+ frameworks across Python, TypeScript, Java (including LangChain4j and Spring AI), and C#. Supports custom TracerProviders and OTLP exporters.
- Vendor SDKs. Langfuse, LangSmith, Braintrust, Helicone, Datadog all ship their own. Some are OTel-native, some are proprietary with an OTel translation layer.
The schema discipline matters more than the library choice. Decide which gen_ai.* attributes are mandatory, which content attributes are opt-in, and which custom attributes you tag (prompt version id, feature flag, user cohort). Get the schema right at week one; refactoring instrumentation across 50 call sites later is the kind of work that gets postponed.
Layer 2: Prompt registry
Prompts in code are technical debt. Every prompt change becomes a code deploy. Rollback is “find the previous git commit.” A/B testing requires a code branch.
Prompts in a registry have a unique id, a creation timestamp, an author, an optional eval pass-rate, branching by feature flag, and rollback metadata. The application calls prompt.get("support_v18") and the registry returns the live version. Rollback is a single API call.
Five viable patterns:
- LangSmith Prompt Hub. Closed platform, native to LangChain.
- FutureAGI prompt versions. Apache 2.0 stack, integrated with the eval and gateway surfaces.
- Braintrust prompts. Closed platform with strong dev workflow.
- Helicone Prompts. Apache 2.0, gateway-attached prompt management.
- YAML-in-git plus loader. Lightweight, version-controlled by git, requires custom tooling for branching and eval-gating.
Pick the one that integrates with your eval gates and your gateway. A prompt registry that does not gate against your eval suite is just a config store.
Layer 3: Offline eval suite in CI
Eval gates are the lock between a prompt PR and production. Without them, prompt changes ship on review-by-vibes. With them, every PR runs the same versioned test set and blocks on rubric regression.
A working eval gate has four parts:
- Test set. Versioned, hashed, dated. 500-1,500 prompts per workload, stratified across difficulty, intent, and risk tier. See the domain reproduction pattern.
- Scorers. Heuristics (schema, regex, length), LLM-as-judge (groundedness, refusal calibration, tool-call accuracy), and custom rubrics specific to your workload.
- Threshold. Per-rubric pass-rate threshold, calibrated against the incumbent. Drops below threshold block the merge.
- CI integration. GitHub Actions, GitLab CI, CircleCI, or Buildkite job that runs on every PR touching prompts or model config.
DeepEval ships pytest-native eval. FutureAGI, LangSmith, and Braintrust all ship CI gating patterns. Pick by where your CI already runs.
Layer 4: Online eval and observability
Offline eval catches regressions before release. Online eval catches drift after release.
The pattern: every production span gets scored by an online judge, the score becomes a span attribute, and a drift detector watches rolling-mean rubric scores per route, per prompt version, per user cohort. When the rolling mean drops below threshold, an alert fires.
Four operational details matter:
- Sample rate. Online scoring at 100% is expensive. Sample 5-20% of traffic, with 100% on errors and high-cost traces. See tail-based sampling.
- Judge model choice. A frontier judge is accurate but expensive. A distilled small judge (Galileo Luna, FutureAGI Turing) is cheaper at scale.
- Drift thresholds. Rolling-mean drops of 2-5% per rubric typically warrant investigation; 5%+ warrants a page.
- PII redaction. Online judges see prompts and completions. Pre-storage redaction is non-negotiable for regulated workloads.
Layer 5: Gateway with routing, caching, fallback, guardrails
The gateway centralizes provider control. Direct SDK calls from each service mean every service decides its own routing, retry, fallback, and caching. The gateway pattern moves these to one place.
Six surfaces a production gateway covers:
- Provider routing. Route by model, region, cost, or user cohort.
- Caching. Semantic or exact-match cache hits cut cost and latency on repeat queries.
- Fallback. Automatic failover when the primary provider errors or rate-limits.
- Rate limits. Per-user, per-model, per-route budgets enforced before the request hits the provider.
- Cost attribution. Per-user, per-prompt, per-feature spend, sourced from gateway logs.
- Runtime guardrails. Input and output validators fired before the response reaches the user.
Seven viable gateways in 2026:
- FutureAGI Agent Command Center. Apache 2.0, Go-based, ships 18+ runtime guardrails plus routing, caching, fallback.
- Helicone Gateway. Apache 2.0, OpenAI-compatible, currently in maintenance mode after the Mintlify acquisition.
- OpenRouter. Closed SaaS, multi-model unified API, broad provider list.
- Portkey. Closed SaaS, gateway-first observability and prompts.
- LiteLLM. MIT, lightweight provider proxy.
- Cloudflare AI Gateway. Closed, Cloudflare-native, free tier with paid scaling.
- Vercel AI Gateway. Closed, Vercel-native, integrates with Vercel deployments.
Pick by where your infra runs and which guardrails you need first-party.
Layer 6: Per-user A/B with rubric-gated rollback
The unit of safe rollout is per-user A/B with automatic rollback.
The pattern: a percentage of users (typically 5-10% to start) get the new prompt version or model id. The eval scorer monitors per-rubric pass rates on the new path. If any rubric regresses below threshold over a 15-minute or 1-hour window, the gateway reverts the cohort to the incumbent without paging an engineer.
Without per-user A/B, every change is a 100% rollout. With it, regressions surface in monitoring before user complaints. The two complementary signals to watch:
- Rubric pass rate per cohort. Statistical comparison of new vs incumbent.
- User-visible signals. Feedback rate, escalation rate, retry rate, complaint rate.
Tools: FutureAGI ships A/B routing in the gateway with eval-gated rollback. LangSmith Fleet ships agent deployment with A/B. LaunchDarkly plus a custom rollback hook works for teams that already use feature flags.
Common mistakes when deploying LLMs to production
- No eval gate. A prompt PR that ships without eval gates is a regression waiting to happen. Wire the gate from week one.
- Prompts in code. Inline prompt strings make rollback a code revert. Move to a registry.
- No span-attached scores. Production traces without quality verdicts hide drift until users complain.
- Direct provider SDK calls from every service. No gateway means no centralized routing, no fallback, no cost attribution. Move provider calls behind a gateway.
- No per-user A/B. All-or-nothing rollouts make every change a full-traffic experiment.
- No fallback testing. A fallback that has not been load-tested is not a fallback. Verify under load before relying on it.
- PII in trace storage.
gen_ai.input.messagesandgen_ai.output.messagescarry PII. Pre-storage redaction is non-negotiable for regulated workloads. - One judge model for everything. Different rubrics warrant different judges. Groundedness and refusal calibration use different rubrics; share judges with care.
- No drift alerts. Latency alerts catch infra. Eval-score drift alerts catch quality. Both matter.
- Hand-rolling the gateway. Building a gateway from scratch is rarely worth the engineering time. Use one of the seven options unless you have a specific constraint they cannot meet.
Recent LLM deployment updates
| Date | Event | Why it matters |
|---|---|---|
| Mar 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | Gateway routing, guardrails, and high-volume trace analytics moved into the same loop. |
| 2026 | OTel GenAI semantic conventions widely adopted | Cross-vendor trace compatibility became achievable, though spec is still in development status. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangSmith expanded into agent deployment workflows. |
| Mar 3, 2026 | Helicone joined Mintlify, gateway in maintenance mode | Gateway-first observability roadmap risk became a procurement question. |
| 2026 | Galileo Luna distilled judges hit production | Online scoring at scale stopped requiring frontier judges. |
| Jan 22, 2026 | Phoenix added CLI prompt commands | Prompt and eval workflows moved closer to terminal-native agent tooling. |
How to actually deploy an LLM application in 2026
- Instrument first. Pick traceAI or OpenInference, emit OTel-native spans across all services, define your
gen_ai.*schema and your custom attributes (prompt version, feature flag, user cohort) at week one. - Build the prompt registry. Move prompts out of code into a registry. Wire branching by feature flag.
- Wire the eval gate. Build the test set (200 hand-labeled production traces plus synthetic plus adversarial probes), pick scorers, set per-rubric thresholds, integrate with CI.
- Add online scoring. Sample production traces, score with a small distilled judge, tag spans, watch rolling-mean rubric scores per route.
- Move provider calls behind a gateway. Pick FAGI Agent Command Center, Portkey, LiteLLM, or another. Centralize routing, caching, fallback, guardrails.
- Wire per-user A/B with rollback. Gradual rollout, eval-monitored, automatic revert on rubric regression.
- Test the fallbacks. Trigger the failover under load. Verify the rollback path works. Run a chaos drill quarterly.
How FutureAGI implements the LLM deployment loop
FutureAGI is the production-grade LLM deployment platform built around the seven-step instrument-prompt-evaluate-score-route-rollout-test loop this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Instrumentation - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java (LangChain4j, Spring AI), and C#.
gen_ai.*semantic conventions and custom attributes (prompt version, feature flag, user cohort) land natively. - Prompt registry and eval gate - versioned prompts and 50+ first-party metrics ship in one workspace. The same metric definition runs offline in CI and online against production traffic; per-rubric thresholds gate merges automatically.
- Live scoring and gateway -
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds. The Agent Command Center gateway fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, fallback, caching, and per-tenant A/B rules. - Guardrails and rollback - 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) ship as inline policies. Eval-score regressions auto-trigger rollback through the gateway routing rules.
Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Most teams running the seven-step deployment loop end up running three or four tools to get there: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because all seven steps live on one self-hostable runtime; the deploy, score, route, and rollback paths share one trace stream.
Sources
- traceAI GitHub repo
- OpenInference GitHub repo
- OpenTelemetry GenAI semantic conventions
- FutureAGI pricing
- FutureAGI GitHub repo
- LangSmith pricing
- Braintrust pricing
- Helicone pricing
- Helicone joining Mintlify
- Phoenix docs
- Galileo agent eval
- Portkey
- LiteLLM GitHub
- Cloudflare AI Gateway docs
- Vercel AI Gateway
- DeepEval docs
Series cross-link
Related: What is LLM Tracing?, LLM Benchmarks vs Production Evals, LLM Testing Playbook 2026, Best LLM Gateways in 2026
Related reading
Frequently asked questions
What does an LLM deployment look like in 2026?
What is a prompt registry and why do I need one?
What is an eval gate?
Do I need a gateway for LLM deployment?
What are runtime guardrails?
How do I handle provider fallback?
What is per-user A/B rollout for LLM applications?
What does an LLM deployment cost in operational complexity?

Six AI agent reliability solutions compared in 2026 across five layers: runtime guardrails, CI eval gates, span-attached scoring, clustering, closed loop.


LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.


Prompt versioning treats prompts as code: unique ids, environment labels, eval-gated rollouts, one-call rollback. What it is and how to ship it in 2026.