What is LangChain? A 2026 Production Engineer's Guide to LangChain, LangGraph, and the Ecosystem
LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.

Table of Contents
If you have shipped LLM features in the last two years, you have a LangChain opinion. Half your team thinks it is the obvious place to start. The other half watched the v0.1 to v0.2 to v0.3 to v1 churn, ate the breaking imports, and now writes against the OpenAI client and a queue. Both camps are partly right. This guide is for the engineer who has to make the call again in 2026, after LangChain v1.0 went GA, after LangGraph absorbed most of the agent runtime story, and after the OpenTelemetry GenAI semantic conventions started replacing vendor-specific tracing. The framework is different than it was. The reasons to pick it or skip it are different too.
TL;DR: What is LangChain in 2026
| Question | Short answer |
|---|---|
| What is it? | Open-source agent framework: provider-agnostic chat model, prompts, tools, retrieval, and an agent factory (create_agent) on the LangGraph runtime. |
| License? | MIT for langchain, langchain-core, langchain-community, langchain-classic, and langgraph. LangSmith is a closed-source product. |
| What changed in v1.0? | GA October 22, 2025. create_agent replaces AgentExecutor, middleware hooks land, Standard Content Blocks normalize provider drift, legacy code moves to langchain-classic. |
| LangChain vs LangGraph vs LangSmith? | LangChain is the framework, LangGraph is the durable orchestration runtime underneath, LangSmith is the closed eval and tracing product. |
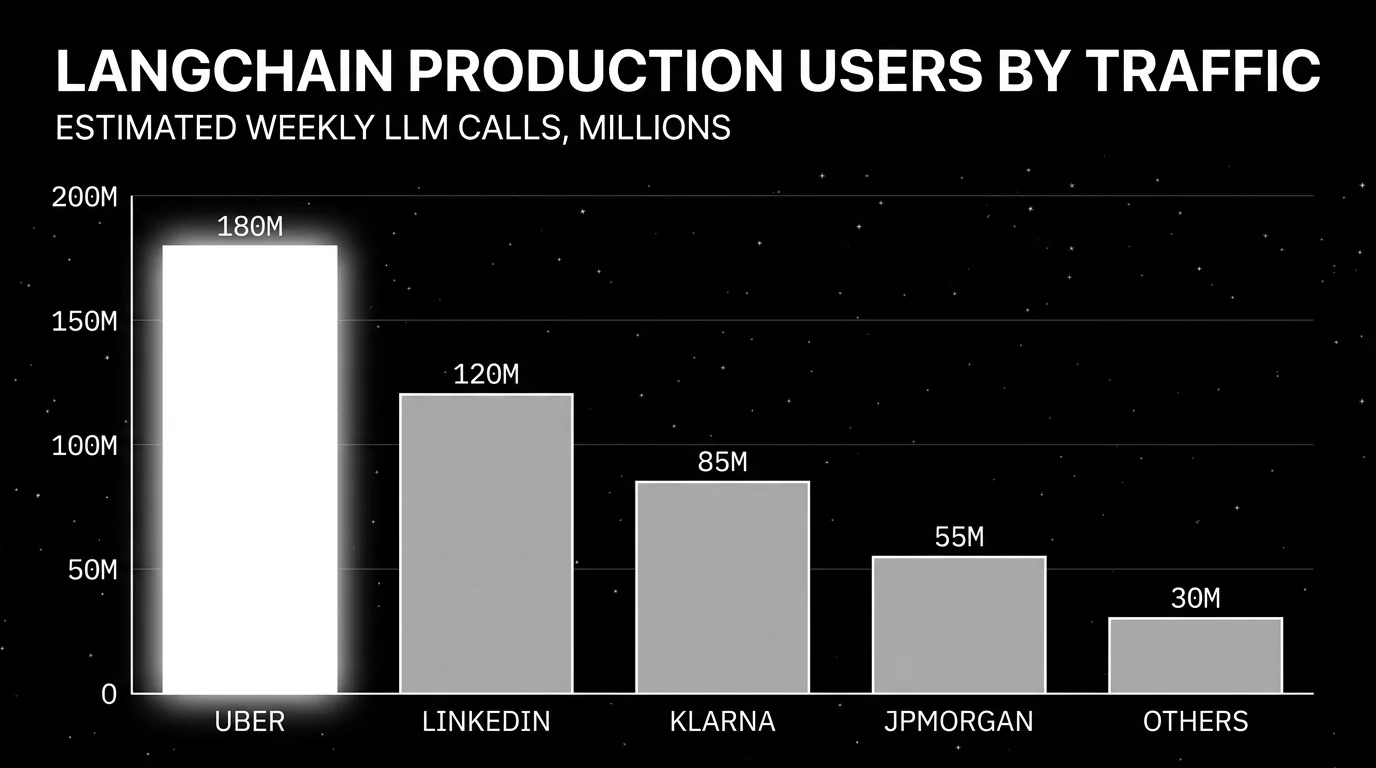
| Who runs it in production? | LinkedIn, Klarna, Uber publish architecture detail. JPMorgan, BlackRock, Cisco, Replit, Cloudflare appear on the LangGraph customer list with less public detail. |
| When to skip it? | If you only need a thin wrapper around the OpenAI Responses API and a queue, or you cannot afford a partner-package churn cycle in your release calendar. |
LangChain is an open-source agent framework with provider-agnostic interfaces for chat models, tool calls, prompts, retrieval, and agents, plus a stable runtime called LangGraph for stateful, durable agent execution. It is MIT-licensed, with primary SDKs in Python and JavaScript or TypeScript, packaged as langchain-core, langchain, langchain-community, langchain-classic (legacy), langgraph, and langsmith. As of v1.0 (October 22, 2025), the recommended way to build an agent is create_agent from the langchain package, which sits on the LangGraph runtime and exposes a middleware system for hooks around model and tool calls. LinkedIn, Klarna, and Uber have published case studies with architecture detail. JPMorgan, BlackRock, Cisco, Replit, Cloudflare, and ServiceNow appear on the LangGraph customer list with less public depth and should be treated as pilots or limited rollouts rather than full-fleet production. The full customer list on the LangGraph product page is longer and changes over time, so verify the current set before quoting it in a procurement deck.
Why LangChain matters in 2026
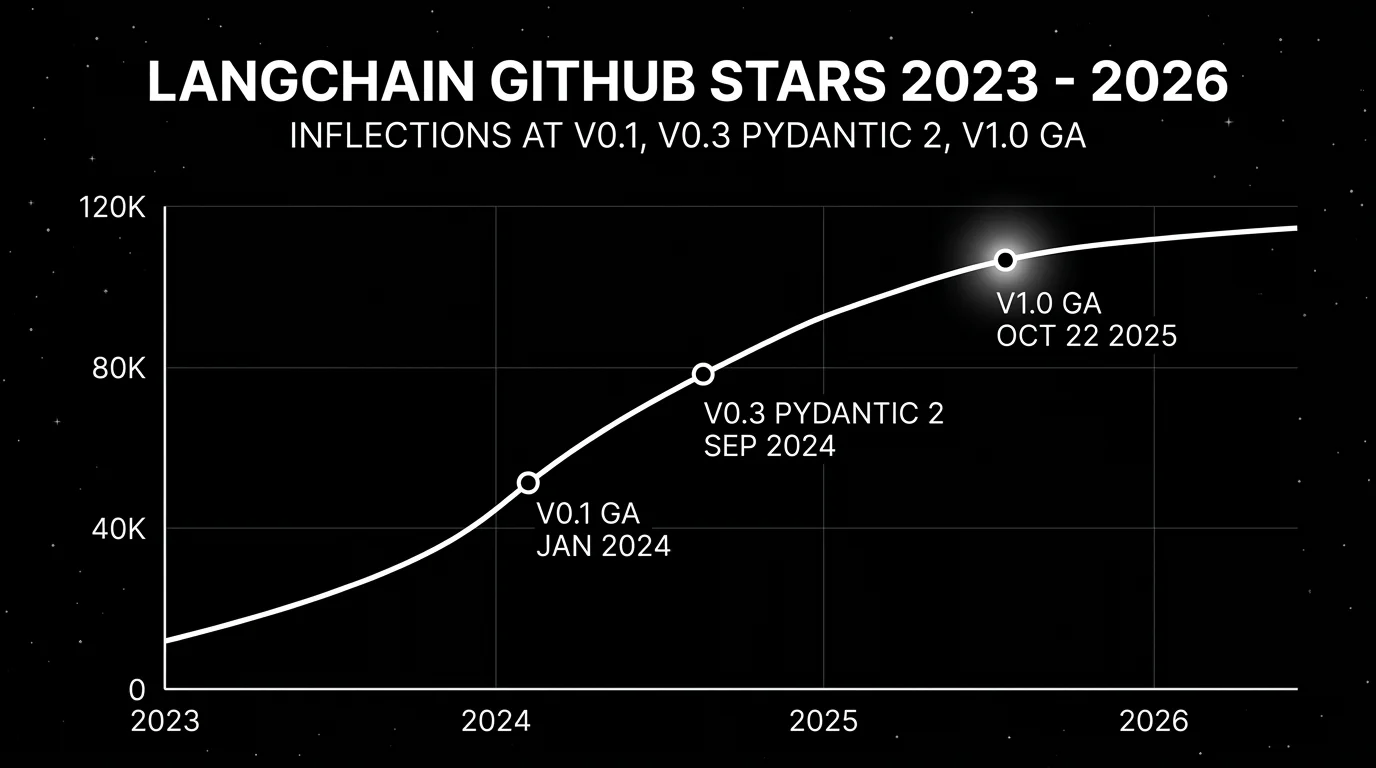
The 2024 critique of LangChain was straightforward: too many abstractions, too many breaking changes, too many cases where reading the source was faster than reading the docs. That critique was earned. Between September 2023 and September 2024, the framework went from a single langchain package to a partner-package split (0.1), to a Pydantic v2 migration in v0.3 (September 16, 2024), with each step costing import surgery and behavior changes. Anyone who pinned langchain==0.0.345 and forgot has a story.
Three things changed in 2025 and early 2026 that matter for the production decision.
LangChain v1.0 GA on October 22, 2025. The 1.0 release moved legacy chains and the old AgentExecutor into a separate langchain-classic package and committed to a smaller, stable surface area. Python 3.10 became the floor. The headline addition was create_agent, a new agent factory built on the LangGraph runtime, with a middleware system for the cross-cutting concerns that production teams keep reimplementing: human-in-the-loop approval, conversation compression, PII scrubbing, retry logic, output validation. v1.0 was not a rewrite. It was an admission that the framework needed to stop reshuffling components every minor version.
LangGraph is now the runtime. What started as a graph library for multi-step agents became the durable execution layer underneath LangChain v1. State, checkpointing, time travel, human-in-the-loop, persistence, and streaming all live in LangGraph. LangChain agents are LangGraph graphs with conventions on top. If you choose LangChain in 2026, you are choosing LangGraph. The reverse is not true: you can use LangGraph without LangChain when you want explicit graph control.
Standard Content Blocks normalize provider drift. v1 introduced a content block format for messages that includes reasoning traces, citations, tool calls, multimodal parts, and the things that providers expose differently. If you have written code that branches on whether the response is from OpenAI o1, Anthropic claude-3.7 with extended thinking, or Gemini 2.5 with grounding, this is the part of v1 that pays for itself fastest. It is also the part most likely to lag when a provider ships a new feature, so verify before relying on it for new modalities.
Who runs LangChain at scale
The “LangChain in production” question gets sharper when you read the public talks rather than the marketing page. Three datapoints worth pinning to.
LinkedIn moved its in-house Generative AI Application Tech Stack to a LangChain and LangGraph foundation, described in the engineering blog post “Practical text-to-SQL for data analytics” shipped to LinkedIn’s data analyst population. The framing is explicit: LangGraph is the orchestration layer for multi-agent flows, with custom retrievers and structured output handlers built on top.
Klarna described its LangGraph rollout in the “Customer Assistant powered by LangGraph and LangSmith” case study published with LangChain. The numbers in that case study: an 80 percent reduction in average resolution time for customer inquiries, replacing the work-equivalent of 700 full-time agents, and the assistant handling roughly two-thirds of customer service chats. Those are Klarna’s published claims; treat them as company-reported metrics, not independent benchmarks. The architecture detail worth noting is that they use LangGraph for stateful multi-step flows and LangSmith for tracing across the full agent lifecycle.
Uber uses LangGraph for its developer platform agents, described in the LangChain “State of AI Agents in 2025” write-up and an Uber Engineering blog post on internal coding agents. Uber’s framing: LangGraph for orchestration of code-migration agents at engineering-org scale, with custom evals on top. They have not published per-agent traffic numbers; the at-scale claim is that the agents are run organization-wide for migration tasks (Java upgrades, internal SDK migrations) that would otherwise require per-team manual work.
JPMorgan, BlackRock, Cisco, Replit, Cloudflare, ServiceNow appear in the LangGraph product page production-user list with varying levels of public detail. JPMorgan’s IndexGPT and BlackRock’s Copilot are referenced in press materials, but specific architecture detail is not public. Treat the logo list as evidence of pilots and limited rollouts, not full-fleet production at the scale of the LinkedIn and Klarna cases.
The honest read: LangChain is in production at large companies, with two or three case studies that include real numbers and a longer list of logos backed by less verifiable detail. That is more concrete than most agent frameworks today, and still less than what you want for a multi-year bet without a fallback plan.
The result: LangChain in 2026 is a smaller, slower-moving framework with a real runtime underneath. Whether it is the right choice still depends on what you are building.
What broke between versions, and what to migrate to
The migration story is concrete enough that anyone considering an upgrade should price it before opening a PR.
v0.1 to v0.2 (May 2024): the partner-package split. What broke: imports. from langchain.chat_models import ChatOpenAI stopped being the canonical path. Provider classes moved to dedicated packages (langchain-openai, langchain-anthropic, etc.), and langchain-core became the home for base classes while langchain-community housed the long tail of integrations. Migrate to: pin langchain-openai, langchain-anthropic, or whichever partner packages you use, and import from them directly. The langchain-cli migrate script handled most of the rewrites; the rest was a ruff pass on import order.
v0.2 to v0.3 (September 16, 2024): Pydantic 2 migration. What broke: BaseModel subclasses written against Pydantic 1 stopped validating the same way. Custom validators, Config inner classes, and JSON-schema generation all changed shape. Tools and structured-output schemas often needed model_validate instead of parse_obj, and Field(...) arguments were re-ordered in subtle ways. Migrate to: install pydantic>=2, run bump-pydantic against your codebase, and re-test every tool schema that crosses the LLM boundary. The hidden cost was internal models that used Pydantic 1 features the framework now refused to accept.
v0.3 to v1.0 (October 22, 2025): create_agent and the langchain-classic split. What broke: AgentExecutor, create_react_agent, the legacy Chain base class, and LLMChain all moved to langchain-classic. Code that imported them from langchain stopped resolving. Custom BaseCallbackHandler subclasses still work, but the recommended replacement is middleware. Migrate to: from langchain.agents import create_agent for the simple path, or build a StateGraph directly when you need custom topology. For legacy code that has to keep running, pip install langchain-classic and update imports to from langchain_classic.... The classic package is on a slower release cadence and gets fewer fixes, so treat it as a holding pen, not a destination.
A pragmatic rule: do not skip versions. Going 0.1 to 1.0 in one PR is a week of debugging. Going 0.1 to 0.2 to 0.3 to 1.0 in four PRs is a day of debugging spread across a month, covered by your existing tests at every step.
Anatomy: Models, Prompts, Tools, Agents, LangGraph, LangSmith
A 2024 anatomy of LangChain would list six layers and call half of them deprecated by 2026. The 2026 anatomy is shorter.
Models
The BaseChatModel interface unifies chat, tool-calling, structured output, and streaming across providers. Partner packages (langchain-openai, langchain-anthropic, langchain-google-genai, langchain-aws, langchain-mistralai, and 50+ others) live in their own repositories with their own release cadence. This is how you get one method, model.invoke(), that works against OpenAI, Anthropic, and Bedrock. The catch: provider-specific features (Anthropic’s prompt caching headers, OpenAI’s Responses API stateful threads, Gemini’s grounded search) are exposed through optional kwargs and content blocks. If you depend on them, read the partner package source, not the abstract base class.
Prompts
ChatPromptTemplate, MessagesPlaceholder, partial templates, and few-shot composition. Useful for keeping system prompts out of code, less useful as a versioning system on its own. If prompt versioning matters, pair it with LangSmith Prompt Hub or your own Git-tracked prompt files. The framework gives you the data structure; it does not give you the change management.
Tools
The @tool decorator and BaseTool class. v1’s Standard Content Blocks normalize tool calls across providers, which removes the most common source of subtle bugs (different providers naming the tool call ID field differently, or returning multi-tool calls in different shapes). Tool execution is still your responsibility, including timeouts, retries, and isolation. If your tool runs SQL, calls an internal service, or executes shell commands, the framework will not sandbox it for you.
Agents (create_agent)
In v1, create_agent from the langchain package is the default agent factory. It returns a compiled LangGraph graph configured for the standard ReAct-style loop (model decides, tool runs, model continues) with middleware slots. The middleware list is the new escape hatch: instead of subclassing or monkey-patching, you compose hooks. Built-in middleware covers human approval, summarization, and tool error handling. Custom middleware lets you add tracing, rate limits, or output validation without forking the agent.
The legacy AgentExecutor and create_react_agent still work via langchain-classic. Do not start new projects on them. Migration to create_agent is documented and usually involves replacing the executor and rewriting any custom callback handlers as middleware.
LangGraph
LangGraph is a stateful graph runtime. Nodes are functions, edges are conditional or static, state is a typed dict (TypedDict or Pydantic), and execution is checkpointed. The features that matter in production are four. Durable execution: the graph survives process restarts via a checkpointer like Postgres or Redis. Human-in-the-loop: interrupt before or after a node, ask a human, resume. Time travel: rewind state to any prior checkpoint and re-run from there. Streaming: emit events from each node in real time. MIT-licensed, used in production by the names LangChain lists on the LangGraph product page (Klarna, Lyft, Gong, Harvey, Cloudflare, Home Depot, Workday, Cisco, LinkedIn, Coinbase, Elastic, ServiceNow, Uber).
If you are building a multi-step agent with retries, approvals, or long-running state, LangGraph is the part of the stack that does the work. The agent abstractions on top are conveniences.
StateGraph: the primitive that matters
StateGraph is the data structure underneath every LangChain agent. You define a state type, register node functions that read state and return partial updates, and wire them with edges. The reducer pattern (state fields annotated with Annotated[..., operator.add] or a custom merge) decides how concurrent updates combine. That is what lets you fan out to two retrieval nodes, run them in parallel, and merge results without locking. A minimal three-node graph:
from typing import Annotated, TypedDict
from operator import add
from langgraph.graph import StateGraph, END
class State(TypedDict):
question: str
docs: Annotated[list[str], add]
answer: str
def retrieve(state: State) -> dict:
return {"docs": vector_store.search(state["question"], k=4)}
def generate(state: State) -> dict:
return {"answer": llm.invoke(format_prompt(state)).content}
graph = StateGraph(State)
graph.add_node("retrieve", retrieve)
graph.add_node("generate", generate)
graph.set_entry_point("retrieve")
graph.add_edge("retrieve", "generate")
graph.add_edge("generate", END)
app = graph.compile()Conditional edges and branching
add_conditional_edges takes a router function that returns the name of the next node (or a list of names for fan-out). This is how you build the ReAct loop without a custom while-loop: a should_continue router checks whether the last message has tool calls and routes to either the tool node or END. Routers are pure functions of state, which makes them easy to test in isolation. The bug you hit when you skip routers and try to use if/else inside a node is that the graph stops being a graph: time-travel and checkpoint replay break because the control flow is hidden inside Python instead of recorded as edges.
Checkpointers and persistence
A checkpointer writes state after every node executes. MemorySaver is for tests. PostgresSaver and RedisSaver are the production options, and the LangGraph Platform uses Postgres by default. With a checkpointer attached, you pass a thread_id in the run config and the graph picks up where it left off, even across process restarts. The same primitive backs get_state_history, which returns every checkpoint in a thread. That is the time-travel feature: pick a checkpoint, fork from it, replay with a different model or different input, compare outcomes. Checkpointing also makes message-history trimming explicit. You read prior state, summarize, write a smaller state, and the next turn runs against the compressed version.
Human-in-the-loop interrupts
interrupt() inside a node pauses the graph, persists state, and waits for an external resume call with the human’s input. This is how approval workflows, clarification prompts, and tool confirmations land in production without a separate queue. The before_node and after_node interrupt configurations let you pause without modifying node code, useful for adding approval gates to an existing graph. Combined with the checkpointer, an interrupted run can wait for hours or days, and the resume call rehydrates state from Postgres.
LangSmith
LangSmith is LangChain Inc.’s closed-source platform. It covers tracing, evals (online and offline), prompt management, datasets, annotation queues, and Fleet, LangSmith’s current agent deployment product (the LangChain changelog documents the Agent Builder to Fleet rename in 2026). SDKs are MIT-licensed; the platform is a hosted product with a self-hosted enterprise option. Pricing is $0 per seat per month for Developer (5,000 base traces, 1 seat), $39 per seat per month for Plus (10,000 base traces, unlimited seats, 1 dev-sized deployment, 500 Fleet runs), and custom for Enterprise.
LangSmith is the lowest-friction option if your code is already LangChain. It is not the only option, and that is the next section.
Code: LCEL and LangGraph patterns you actually use
LCEL (LangChain Expression Language) is the | operator that composes Runnables. In v1 it remains the right tool for stateless, one-shot pipelines. The four patterns below cover most of what shows up in real services.
A prompt, model, and parser composed with |. This is the “hello world” of LCEL and still the right shape for any single-call transformation:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages([
("system", "Classify the ticket into billing, support, or sales."),
("human", "{ticket}"),
])
chain = prompt | ChatOpenAI(model="gpt-4.1-mini") | StrOutputParser()
label = chain.invoke({"ticket": "I was charged twice this month."})Retrieval with create_retrieval_chain, the v1 helper that wires a retriever, a “stuff” combine step, and a question-answer prompt into one Runnable. The retriever is anything implementing BaseRetriever, including MultiQueryRetriever and EnsembleRetriever:
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_prompt = ChatPromptTemplate.from_messages([
("system", "Answer using only the context.\n\n{context}"),
("human", "{input}"),
])
combine = create_stuff_documents_chain(ChatOpenAI(model="gpt-4.1"), qa_prompt)
rag = create_retrieval_chain(vector_store.as_retriever(search_kwargs={"k": 6}), combine)
result = rag.invoke({"input": "What is our refund policy for annual plans?"})Structured output with Pydantic. with_structured_output binds a Pydantic schema to the model so the response is validated against it before it reaches your code. This is the path when you want the model to return a typed object directly. For real tool execution, use bind_tools and either create_agent or a custom LangGraph loop that runs the selected tool and feeds the result back to the model:
from pydantic import BaseModel, Field
class Refund(BaseModel):
order_id: str = Field(description="The order ID to refund")
reason: str = Field(description="Customer-stated reason")
amount_cents: int
model = ChatOpenAI(model="gpt-4.1").with_structured_output(Refund)
refund = model.invoke("Refund order #4421 for 1999 cents, customer says wrong size.")
process_refund(refund.order_id, refund.amount_cents)Async streaming. astream_events emits a typed event stream for every node in the chain, including model-token deltas. This is what you wire to a Server-Sent Events endpoint to get tokens in front of the user as the model produces them:
async def stream_answer(question: str):
async for event in chain.astream_events({"input": question}, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
token = event["data"]["chunk"].content
if token:
yield f"data: {token}\n\n"
elif kind == "on_chain_end":
yield "event: done\ndata: {}\n\n"The version argument is what selects between the v1, v2, and v3 event protocols. v3 is in 1.3.x alpha; if you are pinned to stable 1.2.x today, request "v2" explicitly so a future SDK upgrade does not silently change your event shape.
Implementing LangChain in production
The framework is one decision. The deployment, observability, and evaluation stack around it is a separate decision. Here is the 2026 landscape for a LangChain-based production system.
Deployment
- LangGraph Platform (LangChain Inc.’s managed deployment for graphs) is the path of least resistance if you are already paying for LangSmith Plus or Enterprise. It handles persistence, scaling, and the runtime, with hybrid and self-hosted options on Enterprise.
- Self-hosted LangGraph runs as a Python or Node service with a Postgres checkpointer and a Redis-backed event stream. This is what most teams run in 2026 when they want to keep state in their own VPC.
- Containerized agent service. A FastAPI or Express service that wraps
create_agentwith your routes, your auth, and your queue. The least magic, the most code you own.
Observability
You need traces. The question is which tool, and whether you want OTel-native or framework-native.
- Future AGI (FAGI) is a self-hostable framework-agnostic stack with Apache 2.0 traceAI tracing, covering tracing, evals, simulation, gateway routing, and guardrails on top of OpenTelemetry and OpenInference. Useful when the LangChain agent is one of several services and you want spans flowing into one backend with eval, simulation, and guardrail loops alongside.
- LangSmith gives the deepest LangChain semantics. Trace nodes, tool calls, prompt versions, and run trees map directly. Pay-per-trace at $2.50 per 1,000 base traces above the included tier.
- Langfuse has a
CallbackHandlerfor LangChain and an OpenTelemetry path for everything else. Core is MIT-licensed, self-hostable, and the rest of the platform (prompts, datasets, evals) is included in the open-source build with enterprise add-ons separate. A practical pick when self-hosted observability is the constraint. - Arize Phoenix is OpenInference-native, source-available under Elastic License 2.0, and runs as a local trace and eval workbench. Strong if your team already standardizes on OTel and you want a small footprint to start.
- OpenTelemetry GenAI semantic conventions, direct. As of early May 2026, the OTel GenAI conventions are still in development status, not stable, but enough providers and frameworks emit compatible spans that you can pipe LangChain traces straight to Datadog, Grafana, Honeycomb, or your own OTel collector. The opt-in is via the
OTEL_SEMCONV_STABILITY_OPT_INenvironment variable, but the exact token (for examplegen_ai_latest_experimentalversusgen_ai_latest) is SDK and language specific and has shifted across SDK releases. Consult the OTel GenAI stability migration guide for the value your SDK accepts before pinning it.
Evaluation
For broader scope, Future AGI, Langfuse, Phoenix, and Braintrust all integrate with LangChain agents through traces or callbacks. LangSmith’s offline and online evals are the path of least resistance for a LangChain codebase. The tradeoff is the same shape as observability: native tooling versus framework-agnostic tooling. If your evals need simulated users, voice scenarios, or judge-model BYOK to control cost, look outside LangSmith.
Gateways
A gateway in front of LangChain agents is increasingly standard. The Future AGI Agent Command Center gateway, LiteLLM, Helicone, Portkey, and OpenRouter all give you provider failover, caching, budgets, and per-tenant rate limits. LangChain partner packages will route through any OpenAI-compatible endpoint, so most gateways drop in by changing base_url.
Five tools to know
- Future AGI (framework-agnostic stack: traces, evals, simulation, gateway, guardrails; Apache 2.0 traceAI)
- LangSmith (native traces, evals, Fleet deployment, Prompt Hub)
- Langfuse (OSS-first observability with LangChain CallbackHandler)
- Arize Phoenix (OTel and OpenInference-native trace and eval workbench)
- LiteLLM (provider abstraction and gateway, often paired with the above)
A practical instrumentation pattern
In a typical 2026 LangChain production service, the trace path looks like this. The agent runs as a create_agent graph behind a FastAPI route. Inbound requests carry an OTel trace context header. The graph is wrapped with a CallbackHandler from your observability vendor (LangSmith or Langfuse) for the framework-native span tree, and the underlying HTTP client emits OTel GenAI spans for the raw provider calls. The two streams correlate by trace ID. State checkpoints land in Postgres; event streaming flows through Redis or a managed broker. As an illustration of the metrics worth tracking: first-token latency tends to land in the few-hundred-ms to low-second range depending on model and middleware count, p95 commonly runs 1.5x to 2x p50, and p99 is dominated by provider tail latency you cannot fix in your code. Measure all three independently against your own traffic. Aggregating them into one number hides the only signal that matters when an incident lands.
Common mistakes when using LangChain in production
These show up in incident reviews more than vendor pitch decks.
- Building new agents on
AgentExecutorinstead ofcreate_agent. AgentExecutor is inlangchain-classicfor a reason. New code should targetcreate_agenton LangGraph. The migration is small. The cost of skipping it is the next breaking change in classic, which gets fewer fixes than core. - Treating LCEL chains as the answer for stateful workflows. LCEL (
prompt | model | parser) is fine for one-shot pipelines. State, retries, branching, and human-in-the-loop belong in LangGraph. Trying to do all of it in LCEL leads to the kind of code where every chain has a custom runnable wrapper and nobody can find the bug. - Pinning to
^0.3or letting it float. Pin to a specific minor version oflangchain,langchain-core, and the partner packages you import. Breaking changes have happened across minor versions historically. Even with v1’s stability commitment, partner packages move on their own. - Skipping streaming. First-token latency dominates user-perceived performance. LangGraph streams events from every node natively. Use
stream_events(astream_eventsis the async variant) and surface tokens, tool calls, and node transitions to the client. The v3 protocol lands in 1.3.x alpha and is wired intocreate_agentthere; if you are on stable 1.2.x today you are still on v2, so check the version before depending on v3-only fields. A 30-second non-streamed response feels broken even when it is correct. - No gateway in front of the agent. Direct provider SDK calls from inside the agent mean every LLM outage is a user-facing outage. Put LiteLLM, the Future AGI gateway, or another OpenAI-compatible proxy in front so you can fail over, cache, and budget without redeploying the agent.
- Using only LangSmith for traces because it was easy. It is easy. It is also seat-priced and trace-priced, and the seat math gets ugly when product, ops, and on-call all need access. Run a cost projection at your real trace volume before committing.
- Letting the framework hide the prompt. When you ship
create_agent(model, tools, prompt="..."), log the resolved messages that actually go to the provider. Token count, message order, system prompt position, and tool descriptions are all places where a wrapper can change behavior between minor versions. If you cannot show the on-wire payload from a trace, the next bug will take twice as long. - Treating LangSmith as an eval platform from day one. It does evals. So does Langfuse, FAGI, Phoenix, and Braintrust. If your eval needs are richer than “score traces against a few rules,” compare options before letting the trace tool also own the eval surface.
- Forgetting the partner package release cadence.
langchain-openai,langchain-anthropic, and other partner packages release on their own schedules and can lag (or lead) the core framework by days. When OpenAI or Anthropic ships a new feature, the partner package is usually the first place it lands. Subscribe to the relevant repos, not just the LangChain blog. - Skipping checkpointing because “the agent is short.” Three turns become five become eight when users keep talking, and a process restart in the middle of a tool call leaves the user with a half-answer and your retry loop in a strange state. Use a Postgres or Redis checkpointer from day one. The cost is a few hundred bytes per turn and the ability to resume work after a crash.
- Letting middleware grow into a parallel framework. Middleware is the v1 escape hatch, not a place to write your business logic. If your middleware list is more than five entries deep and includes anything that mutates the prompt non-trivially, your agent is no longer a
create_agent; it is a custom graph. Move it to LangGraph explicitly so the next engineer can read it.
Common production failure modes
Mistakes are decisions you can avoid up front. Failure modes are bugs that find you anyway, usually in front of users on a Friday afternoon. The list below is the set of LangChain-specific incidents that recur in postmortems.
Chain-of-thought leaks into customer-facing output. Reasoning traces from o1 or Anthropic extended thinking land in the response stream alongside the answer. If your parser treats the whole content as the answer, the user sees the model’s internal monologue. Detect with a string-match test on the rendered response that fails on <thinking>, <scratchpad>, or reasoning_content. Prevent by reading from the v1 Standard Content Block typed as the user answer, not the entire content array.
Token explosion in iterative agents. A loop that does not summarize prior turns hits context-window limits after enough tool calls, and per-call cost grows quadratically. Fine in dev with three turns, falls over at fifteen in prod. Detect by alerting on total_tokens crossing 60 percent of the model’s context. Prevent with the summarization middleware in create_agent or a checkpoint-trim step in your StateGraph.
Pydantic 2 validation failures on tool outputs. A tool returns a dict the model expects, but the schema was written before Field(default_factory=...) semantics changed in Pydantic 2. The tool runs, validation fails, the agent retries, and the loop burns tokens. Detect by logging ToolMessage validation errors. Prevent by writing tool schemas as explicit Pydantic 2 models and unit-testing them against the JSON the model actually produces.
Streaming chunks that break with custom output parsers. StrOutputParser handles streaming. Custom parsers that buffer the entire response before emitting do not. Symptom: streaming works in the playground and not in prod, because prod swapped in a JsonOutputParser and the user sees nothing until the JSON is complete. Detect by smoke-testing astream_events against every parser you ship. Prevent by using JsonOutputParser from langchain_core.output_parsers, which supports incremental streaming, instead of a custom parse method.
LangChain version skew across teammates. Two engineers run different langchain-core versions. One adds a feature using a method that exists locally and not on the other’s machine. CI passes because CI pins to whichever version was checked in last. The bug ships when the other engineer deploys. Detect by adding pip-tools or uv lock to CI and failing on lockfile drift. Prevent by treating langchain-core and partner packages the same as your database driver: pinned, reviewed, bumped on a schedule.
Callback explosion under load. Multiple callback handlers (LangSmith, Langfuse, custom logging) attached to the same chain add CPU per call. Under high QPS the callback queue back-pressures the event loop and tail latency climbs. Detect with flame graphs that show callback frames eating the request budget. Prevent by switching to OTel exporters with batching, which decouple emit from the request path.
Tool error retries that stack. A flaky API returns 500. The tool wrapper retries three times. The agent middleware retries on tool error twice. Net: six calls per failed turn. Detect by graphing retry counts per turn. Prevent by removing one of the retry layers (usually the agent middleware) and letting the tool’s own client handle it.
The future of LangChain
Three forces are shaping where this goes.
Framework consolidation pressure. CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, Mastra, and Vercel AI SDK all overlap with parts of LangChain. The LangChain bet for 2026 is that LangGraph is the orchestration runtime worth standing on, and create_agent is a thin enough convenience that competitors do not erode it. The risk is that the OpenAI Agents SDK keeps gaining ground for OpenAI-only stacks and shrinks LangChain’s natural buyer pool to “we use multiple model providers and want a runtime.”
OpenTelemetry GenAI as the wire format. OTel GenAI conventions are in development as of early May 2026, with stable migration plans pending. Once they stabilize, vendor-specific trace formats will look like a tax. LangChain already emits OTel-compatible spans through the LangSmith SDK and supports OTel exporters directly. Expect the framework-agnostic observability story (Langfuse, Future AGI, Phoenix, Datadog, Honeycomb) to keep eating share that LangSmith would have held in a closed ecosystem.
The v1 stability promise. v1.0 committed to a stable interface for the langchain and langchain-core packages, with breaking changes confined to major versions. If LangChain Inc. holds that line for 18 months, a real production case strengthens. If a v1.x minor breaks imports the way 0.x minors did, the case weakens fast. The early signal is good: 1.3.0a is in alpha as of early May 2026 with additive changes (a new astream_events v3 protocol, security fixes), no import surgery required for v1.x users.
A v2 is not on the public roadmap. Internal directions visible from the repo and blog suggest the next 12 months are about hardening v1, expanding LangGraph Platform, growing Fleet, and absorbing more of the agent reliability surface (deepagents, the planning and subagent harness, ships under the same umbrella). If you are picking a framework today, plan around v1 living for a while.
What an honest production checklist looks like
Before you put a LangChain agent in front of users, the items below should each have an owner.
- Pinned versions for
langchain,langchain-core,langgraph, and every partner package, with a documented bump cadence. - A checkpointer pointed at durable storage, not in-memory. Verify resume works under a forced kill.
- A gateway (LiteLLM, FAGI, Portkey, or your own) with provider failover, per-tenant budgets, and request caching where safe.
- Tracing with both framework-native callbacks and OTel GenAI spans, correlated by trace ID, retained for at least 30 days.
- An eval harness in CI that runs against a frozen dataset of past failures and blocks merges on regressions.
- Streaming on by default for any user-facing surface. First-token p95 under 1.5 seconds for most prompts.
- A guardrail layer (input PII scrubbing, output policy checks, jailbreak detection) that is not optional in production traffic.
- A documented escape hatch: the smallest possible code path from a request to a direct provider SDK call, in case you need to deroute around the framework.
If any of those items is “we will add it later,” the answer is to add it before launch, not after the first incident.
How FutureAGI implements LangChain observability and evaluation
FutureAGI is the evaluation, observability, and policy platform built around the eight-item LangChain production checklist this post lists. traceAI is Apache 2.0, and FutureAGI offers a self-hostable platform on the same plane:
- Tracing - traceAI is Apache 2.0 OTel-based and auto-instruments LangChain, LangGraph, and 35+ other frameworks across Python, TypeScript, Java (LangChain4j, Spring AI), and C#. The LangChain path is
pip install traceai-langchainandLangChainInstrumentor().instrument(), registered against afi_instrumentation.register(...)project so LangGraph node and edge spans, tool calls, retrievals, and per-step latency land as OpenInference and OTel GenAI semantic conventions, vendor-portable from day one. - Evaluation - first-party metrics (Tool Correctness, Plan Adherence, Groundedness, Task Completion, Answer Relevance, Hallucination) ship as both span-attached scorers and CI gates.
turing_flashruns at about 1 to 2 seconds cloud latency,turing_smallat 2 to 3 seconds,turing_largeat 3 to 5 seconds, with BYOK on top so any LLM can sit behind the evaluator at zero platform fee. - Gateway and guardrails - the Agent Command Center gateway fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, fallback, caching, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement). The gateway and the trace backend share one plane, not two vendors.
- Simulation and optimization - persona-driven synthetic users exercise LangGraph agents against red-team and golden-path scenarios before live traffic, and six prompt-optimization algorithms consume failing trajectories as labelled training data.
Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Most teams shipping LangChain or LangGraph agents end up running three or four tools in production: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI fits teams that want the trace, eval, simulation, gateway, and guardrail surfaces on one self-hostable runtime, so the eight-item production checklist collapses to one workflow rather than four vendor contracts.
Sources
- LangChain v1.0 announcement: release date, create_agent, Standard Content Blocks, langchain-classic split
- LangChain v0.3 announcement: September 16, 2024, Pydantic 2 migration
- LangChain Python overview docs: current definition, agents on LangGraph
- LangChain GitHub repository: MIT license, package layout, current versions
- LangChain releases page: version history including 1.3.0a
- LangGraph product page: runtime positioning, production user list
- LangSmith pricing: Developer, Plus, Enterprise tiers
- Langfuse LangChain integration: CallbackHandler, OTel path
- OpenTelemetry GenAI semantic conventions: current development status
- LangChain “create_agent” Microsoft Azure community post: independent confirmation of v1 GA
- LinkedIn Engineering “Practical text-to-SQL for data analytics”: LangGraph in LinkedIn’s analytics agent stack
- LangChain x Klarna case study: customer-assistant numbers and architecture
- LangChain x Uber blog post: LangGraph-based code-migration agents at Uber
Related reading
-
Braintrust Alternatives in 2026: observability and eval platforms compared
-
What is LLM Observability?: companion explainer
-
Building Reliable LangChain RAG Pipelines with Observability
Frequently asked questions
Is LangChain still worth using in production in 2026?
What is the difference between LangChain, LangGraph, and LangSmith?
What changed in LangChain v1.0?
Should I use create_agent or build directly on LangGraph?
What replaces AgentExecutor in 2026?
What are LangChain's biggest weaknesses in production?
How do I instrument LangChain for tracing in production?
Is LangChain Apache 2.0 or MIT?

LangGraph is LangChain's graph-based orchestration library for stateful agents. Nodes, edges, state, checkpointers, and how it differs from CrewAI.


Compare seven OSS agent frameworks for production teams in 2026, with architecture, license, maturity, latest versions, and practical tradeoffs.


Langfuse vs LangSmith 2026 head-to-head: license, framework neutrality, prompts, datasets, eval, self-host, the unified-stack axis.