Best AI Agent Reliability Solutions in 2026: 6 Stacks Compared on the Five Reliability Layers
Six AI agent reliability solutions compared in 2026 across five layers: runtime guardrails, CI eval gates, span-attached scoring, clustering, closed loop.

Table of Contents
3:14 am. The agent that shipped Wednesday at 0.91 on a 47-scenario CI suite is now quoting refund amounts off by an order of magnitude, contradicting itself across turns, and on one trace handing a user another customer’s order. Every failing conversation passes the per-turn faithfulness rubric. The on-call engineer pages the team lead at 3:47 and the team lead asks the question every reliability buying decision turns on: which layer of our stack should have caught this?
This guide compares the six platforms senior ML and SRE teams shortlist when that question lands on them in 2026. Agent reliability is not a feature you buy. It is a stack of five layers stitched together: runtime guardrails at the gateway, CI eval gates on every change, OpenTelemetry observability with span-attached scoring, failure clustering that names what just broke, and closed-loop optimization that turns the named failure into the next regression test. No single vendor owns every layer equally well; the right answer is a composable stack, sometimes from one vendor, more often from two or three, with the seams understood. Pricing, license, and the “where it falls short” line are on every card.
TL;DR: pick by the layer you are missing
| What you are missing | Best pick | Why (one phrase) | Pricing | License |
|---|---|---|---|---|
| All five layers on one plane | Future AGI | Gateway + evals + traceAI + Error Feed + agent-opt | Free + usage from $2/GB | Apache 2.0 |
| Sub-200 ms enterprise scoring | Galileo | Luna-2 distilled judges + Protect | Free; Pro $100/mo | Closed |
| Polished experiments SaaS | Braintrust | Versioned eval runs, diff, online scoring | Starter free; Pro $249/mo | Closed |
| LangChain or LangGraph runtime | LangSmith | Trajectory eval native to LangGraph + Fleet | Developer free; Plus $39/seat/mo | Closed; MIT SDK |
| Retrieval-embedding drift | Arize AX + Phoenix | OTel-native, drift dashboards per dim | Phoenix free; AX Pro $50/mo | ELv2 / commercial |
| One agent across infra + LLM | Datadog LLM Obs | Trace plus monitor stack reuse | Datadog seat + ingest | Closed |
If you only read one row: pick Future AGI when the question is all five layers on one Apache 2.0 plane, Galileo when procurement drives the call, and LangSmith when the runtime is already LangGraph.
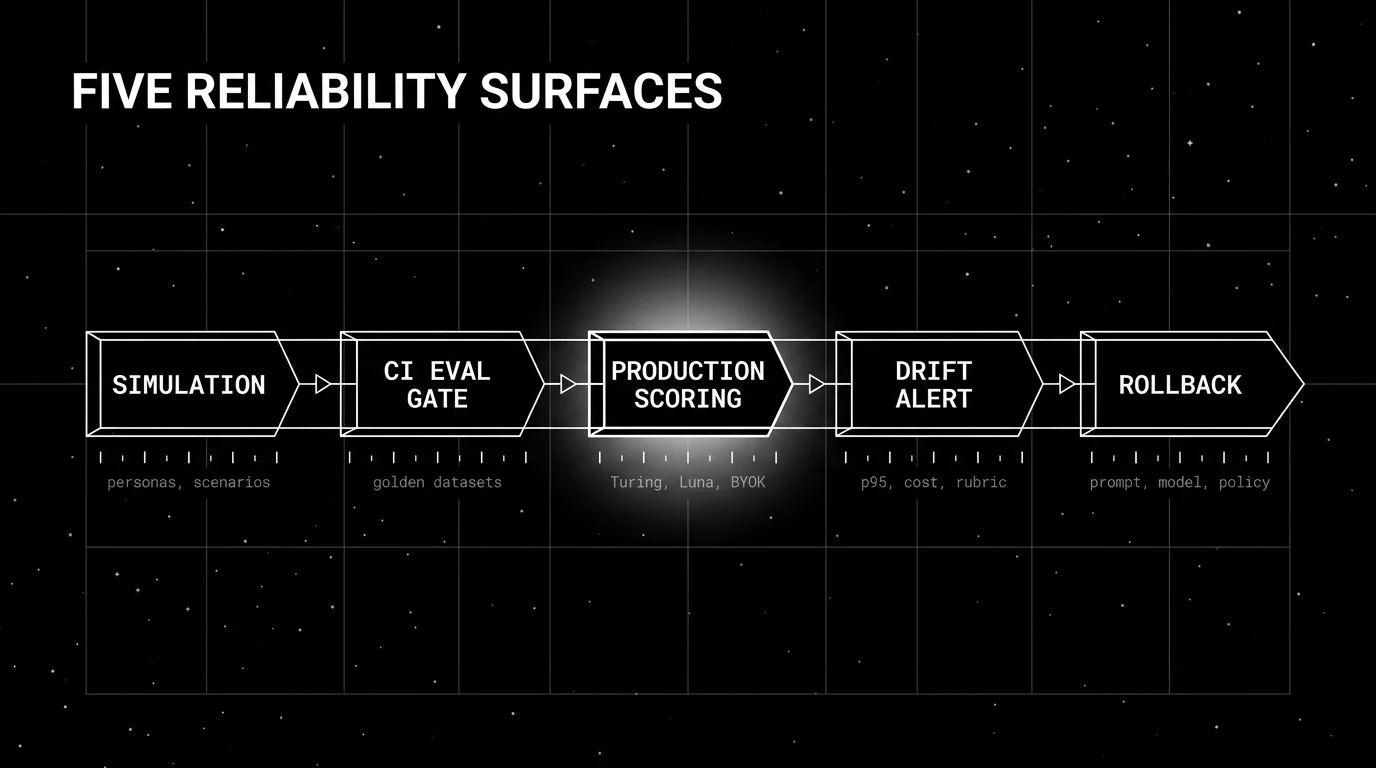
The five reliability layers, named
Five surfaces. A tool covering three or fewer is a reliability component; a tool spanning all five is a reliability platform. The shortlist below is scored on each.
-
Runtime guardrails at the gateway. Sub-200 ms inline blocks for the loud failures: jailbreak, PII exfiltration, tool-call schema violation, prompt injection, banned content. Runs on every request, fails closed. Without this layer the agent ships its worst output to a user before any other layer notices.
-
CI eval gates. Every prompt change, model upgrade, or tool registry change clears an offline gate before promotion. Versioned golden dataset, fixed rubric, blocks the merge when the regression exceeds threshold. Without this layer you ship known regressions.
-
OpenTelemetry observability with span-attached scoring. Every production trace lands in a trace store with the same rubric the CI gate used, scored at the span level. Faithfulness on the response. Tool Correctness on the tool call. Plan Quality on the trajectory. Without this layer you find regressions through customer reports.
-
Failure clustering with an immediate fix. Failing traces group into named issues so the on-call engineer reads a cluster, not 800 flat rows. The cluster page carries a written diagnosis: which axis dropped, which trace exemplifies the failure, which rubric edit or prompt patch is the candidate fix. Without this layer the engineer hunts.
-
Closed-loop optimization. Each named cluster becomes a candidate dataset entry. An optimizer (ProTeGi, GEPA, BayesianSearch) searches the prompt space against the same rubric the CI gate uses; the winning candidate clears CI before it ships. We walked the architecture in Your Agent Passes Evals and Fails in Production.
The 2026 read: most teams have one or two of these layers wired (usually observability and maybe CI gates). Reliability buying decisions in 2026 are about closing the gap on the missing three.
The 6 AI agent reliability solutions compared
1. Future AGI: best for all five reliability layers on one Apache 2.0 plane
Apache 2.0 across ai-evaluation, traceAI, agent-opt, and Agent Command Center. Hosted cloud at app.futureagi.com or self-host.
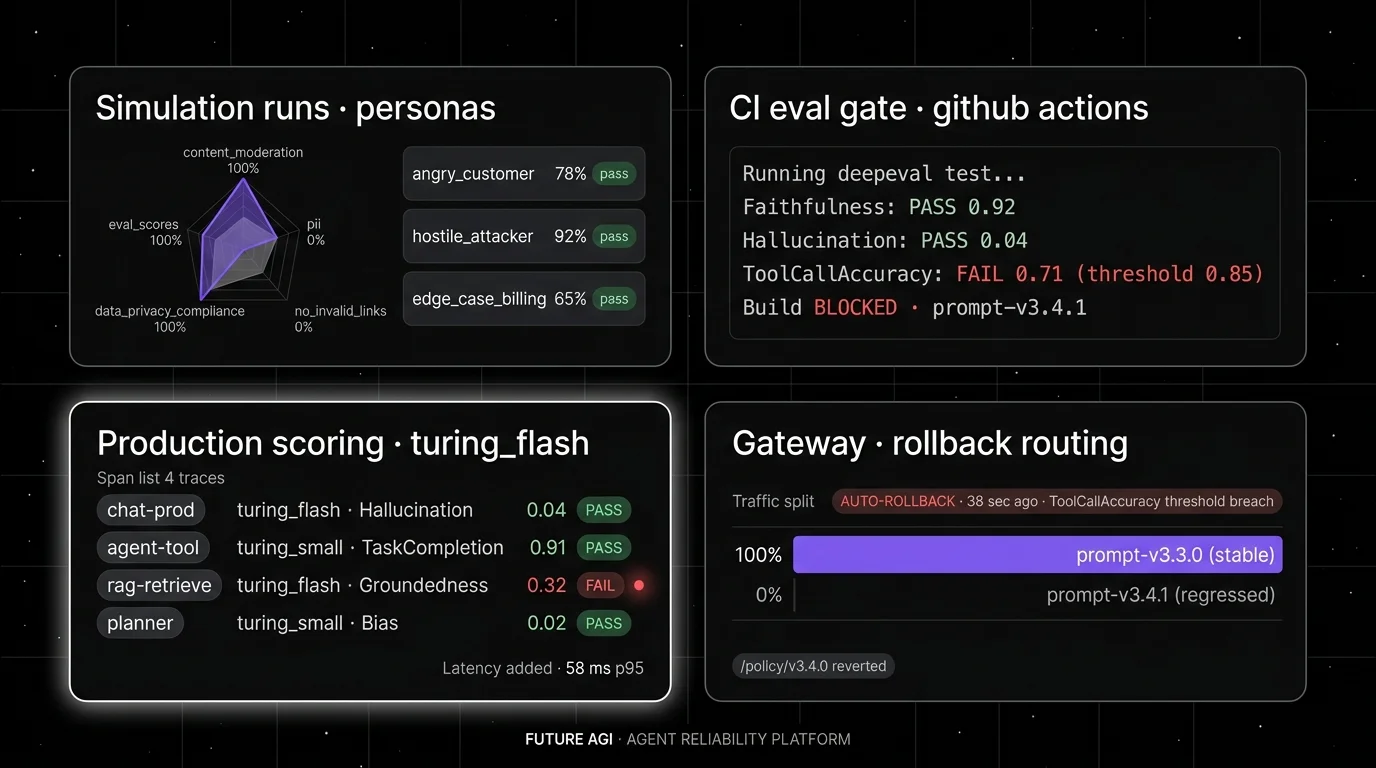
Runtime guardrails. Agent Command Center is the Apache 2.0 Go-binary gateway: 100+ providers, 18+ built-in scanners (PII, prompt injection, content moderation, secret detection, hallucination, topic restriction, MCP security, tool permissions, system-prompt protection), plus 15 third-party adapters (Lakera Guard, Presidio, Llama Guard, AWS Bedrock Guardrails, Azure Content Safety, Pangea, Aporia, Enkrypt AI and others). Benchmark: ~29k req/s, P99 21 ms with guardrails on, on t3.xlarge. Protect runs four Gemma 3n LoRA adapters with 65 ms text and 107 ms image median time-to-label (per arXiv 2510.13351).
CI eval gates. ai-evaluation is the Apache 2.0 SDK: 50+ pre-built evaluators (Tone, Factual Accuracy, Groundedness, Task Completion, EvaluateFunctionCalling, AnswerRefusal, ContextRelevance, ChunkAttribution, DataPrivacyCompliance) plus 20+ local heuristic metrics. Real Evaluator(fi_api_key=..., fi_secret_key=...).evaluate(...) API. The fi CLI carries native CI assertions; four distributed runners (Celery, Ray, Temporal, Kubernetes); multi-modal CustomLLMJudge.
Span-attached scoring. traceAI is OTel-native: 50+ AI surfaces across Python, TypeScript, Java, and C# (Spring Boot, Spring AI, LangChain4j, Semantic Kernel). 14 span kinds including TOOL, RETRIEVER, AGENT, EVALUATOR, GUARDRAIL, VECTOR_DB. The rubric defined in ai-evaluation attaches as an EvalTag on live spans at zero added inference latency; the CI judge and the production judge are literally the same code.
Failure clustering. Error Feed sits inside the eval stack. Failing spans flow into ClickHouse with embeddings; HDBSCAN soft-clustering at prob >= 0.4 keeps noise points recoverable. Each cluster fires a JudgeAgent on Claude Sonnet 4.5 (Bedrock) for a 30-turn investigation across 8 span-tools, with a Haiku Chauffeur summarising spans over 3,000 characters. Per cluster the Judge writes a 5-category 30-subtype taxonomy, the 4-D trace score (Factual Grounding, Privacy and Safety, Instruction Adherence, Optimal Plan Execution; 1 to 5 each), and an immediate_fix string naming the rubric edit, prompt patch, tool guard, or retrieval filter to ship today.
Closed-loop optimization. agent-opt exposes six optimizers (RandomSearchOptimizer, BayesianSearchOptimizer, MetaPromptOptimizer, ProTeGi, GEPAOptimizer, PromptWizardOptimizer) with a uniform EarlyStoppingConfig and an Evaluator over heuristics, LLM-judge, and 70+ rubrics. Point an optimizer at the offline set Error Feed just expanded; it searches the prompt space against the same rubric the CI gate uses. Linear ships today via OAuth; Slack, GitHub, Jira, PagerDuty are on the roadmap.
Pricing. Free + usage from $2/GB storage, $10 per 1,000 AI credits, $5 per 100K gateway requests. SOC 2 Type II, HIPAA, GDPR, CCPA certified per futureagi.com/trust; ISO/IEC 27001 in active audit.
Best for. Teams on CrewAI, AutoGen, LangGraph, OpenAI Agents SDK, Microsoft Agent Framework, or a custom runtime, where the goal is to compress three vendor invoices (gateway, eval, observability) into one Apache 2.0 plane with self-host on the table.
Where it falls short. More moving parts than a single-product SaaS. ClickHouse, Postgres, Redis, Temporal, and Agent Command Center are real services; use the hosted cloud if you do not want to operate the data plane. Full eval templates run async at roughly 1 to 2 seconds; sub-100 ms work is the Protect path, not the full judge. A direct trace-stream-to-agent-opt connector is on the active roadmap.
2. Galileo: best for enterprise risk with Luna-2 sub-200 ms scoring
Closed platform. Hosted SaaS, VPC, on-prem on Enterprise.
Where it covers. Galileo ships across eval, observability, and runtime Protect. Luna-2 evaluation foundation models score Tool Selection Quality, Tool Argument Correctness, Plan Quality, Action Completion, and ChainPoll hallucination at sub-200 ms in real time, at $0.02 per 1M tokens with a 128k context window. AutoTune (released April 2 2026) retunes evaluators from labeled feedback. The eval-to-guardrail workflow inside the closed product is the clearest enterprise story in the category.
Where it falls short. Closed source; no Apache 2.0 footprint. No auto-clustering of failures into named issues with a written immediate_fix the way Error Feed ships. Pre-production simulation is lighter than Future AGI’s persona-driven runs. Luna distillation works, but using it well requires labeled domain data and judge calibration. Closed-loop optimization is not a first-class product surface; teams wire Galileo scores into a separate optimizer. See Galileo Alternatives for the long version.
Pricing. Free with 5K traces per month. Pro at $100/month with 50K traces. Enterprise custom with unlimited traces, deployment options, dedicated CSM, 24/7 support.
Best for. Regulated buyers in financial services and healthcare who want enterprise eval engineering plus Luna economics on online scoring at scale, where SOC reports and on-prem are RFP line items.
3. Braintrust: best for polished closed-loop SaaS experiments
Closed platform.
Where it covers. Braintrust ships experiments (versioned eval runs with diff and comparison), datasets, custom scorers, prompt management, online scoring on production traces, and CI gates inside one closed product. The developer experience is the cleanest in the category for the experiment-iteration loop: write a scorer, version it, diff a new prompt against the baseline, and the dashboard shows the regression matrix. Sandboxed agent eval is supported.
Where it falls short. Closed platform; no OSS gravity story. Pre-prod simulation and runtime guardrails are lighter than dedicated reliability platforms; pair with a separate inline-guard product (Agent Command Center, Aporia, Lakera) when policy enforcement is in scope. No failure-clustering layer with a written immediate_fix. Teams whose top failure mode is span-level plan divergence on multi-step agents typically pair Braintrust with Future AGI or LangSmith for trajectory eval.
Pricing. Starter free; Pro at $249/month. Enterprise custom with SSO, RBAC.
Best for. Teams that want a single closed-loop SaaS for experiments, scorers, and CI gates without operating tracing infrastructure themselves.
4. LangSmith: best for LangChain or LangGraph runtimes
Closed platform. MIT SDK. Cloud, hybrid, self-hosted on Enterprise.
Where it covers. LangSmith reads LangGraph natively: every node, edge, and tool call is a first-class trace surface. Trajectory evaluators (tool-call accuracy, retrieval relevance, final-answer quality) run on LangSmith traces without manual span instrumentation. Fleet (renamed from Agent Builder on March 19 2026) handles agent deployment with version pinning, which doubles as a rollback path on a regressed prompt or model. Datasets, prompt management, and evaluators live on the same surface as the runtime.
Where it falls short. Closed platform. Per-seat pricing makes cross-functional access expensive. The OTel ingest exists but the strongest path is LangChain or LangGraph; on a stack that mixes custom agents, LiteLLM, direct provider SDKs, and non-LangChain orchestration, LangSmith is less framework-neutral than Future AGI or Braintrust. Runtime guardrails are not a first-class product surface. Failure clustering with a written immediate_fix is not on the roadmap.
Pricing. Developer at $0/seat/month with 5K base traces and 1 Fleet agent. Plus at $39/seat/month with 10K base traces, unlimited Fleet agents, 500 Fleet runs. Base traces cost $2.50 per 1,000 after included usage. Enterprise custom.
Best for. Teams whose runtime is LangChain or LangGraph and whose trajectory semantics live in the framework.
5. Arize AX + Phoenix: best for retrieval-embedding drift
Phoenix is source-available under Elastic License 2.0. Arize AX is the managed commercial layer.
Where it covers. Phoenix accepts traces over OTLP and auto-instruments CrewAI, AutoGen, OpenAI Agents SDK, LangGraph, LlamaIndex, DSPy, and Mastra; it ships built-in retrieval and tool-call evaluators in a local-first Python package. Arize AX adds embedding-drift dashboards on every dimension, production alerting on per-metric thresholds, and the monitor surface for week-over-week regressions. Drift is where Arize lives; the product was built for ML observability before the agent era, and the embedding-monitoring tooling shows it.
Where it falls short. ELv2 is source available, not OSI open source; some legal teams treat that distinction as load-bearing. No auto-clustering of failures into named issues with a written immediate_fix the way Error Feed ships. The eval catalogue is smaller than Galileo’s or Future AGI’s. Phoenix locally plus Arize AX in production is two products to operate. Runtime guardrails are not the focus; pair with a gateway for inline blocks.
Pricing. Phoenix free self-host. AX Free 25K spans per month. AX Pro $50/month. Enterprise custom.
Best for. Teams whose dominant failure mode is retrieval drift on a high-dimensional embedding surface, who already standardised on OpenTelemetry, and want a path from local Phoenix into a managed product without re-instrumenting.
6. Datadog LLM Observability: best when Datadog is already the agent of record
Closed; sold as an add-on to the Datadog platform.
Where it covers. Datadog LLM Observability captures the full agent trace (prompts, completions, tool calls, retrieval), ships a small set of out-of-the-box evaluators (Failure-to-Answer, Topic Relevancy, Sentiment, Toxicity), and pipes alerts into the Datadog monitor stack alongside infra signals. The pitch is the single agent across pods, services, queues, databases, and the LLM layer; monitor-as-code and dashboards-as-code reuse the workflows existing Datadog shops already have.
Where it falls short. The evaluator catalogue is narrower than Future AGI’s, Galileo’s, or DeepEval’s. No auto-clustering of failures into named issues with a written immediate_fix. Drift detection on agent-specific metrics is light versus Arize. Pricing scales on ingest the way the rest of Datadog does, which is fine if you are already paying for it and painful starting from zero. Closed-loop optimization is not a product surface.
Pricing. Datadog seat plus ingest. LLM Observability is metered separately; verify with your account team.
Best for. Engineering organisations where Datadog already owns alerting, the on-call rotation lives in the Datadog monitor stack, and one agent across infra plus LLM matters more than depth on the agent eval surface.
Decision framework: pick by the missing layer, not the dashboard
- All five layers, one plane, OSS. Future AGI. The Apache 2.0 stack is the only one that spans gateway + evals + traceAI + Error Feed + agent-opt without stitching three vendor invoices together.
- Enterprise procurement and SOC reports own the call. Galileo lead; Future AGI as the OSS alternative with SOC 2 Type II and HIPAA on the trust page.
- Experiment iteration is the binding requirement. Braintrust for the polished diff UX; Future AGI’s ai-evaluation if the experiments need to extend into trace-attached scoring later.
- Runtime is already LangGraph. LangSmith; framework-native trajectory eval is the lowest-friction path.
- Dominant failure mode is retrieval-embedding drift. Arize AX plus Phoenix; the drift dashboards are the job they were built for.
- Datadog already owns alerting. Datadog LLM Observability, paired with a dedicated gateway and a code-first eval SDK for the missing layers.
Cross-cutting rule: a reliability tool that scores only the final response misses four of the five layers. Score the trace as a unit. The architecture is in LLM Evaluation Architecture (2026).
Common mistakes when picking an agent reliability solution
- Conflating observability and reliability. A pretty trace viewer is observability. Reliability is the alert that fires when the engineer was not looking, plus the rollback that fires when the alert is real, plus the regression test that fires the next time the same change lands.
- Skipping pre-prod simulation. Persona-driven runs against adversarial scenarios catch failure modes that have not appeared in production logs but exist in your customer base. It is the cheapest insurance in the stack.
- No CI gating on critical metrics. A platform that emits scores but does not gate promotion catches regressions only after deployment. Gate the top three metrics in CI from week one.
- Online scoring on every trace with a frontier judge. Three frontier judges per step on a 10-step trace is 30 GPT-4 calls per request. At 100K requests per day this is the dominant cost line. Sample by failure signal; use distilled judges (Galileo Luna-2 at $0.02 per 1M tokens, Future AGI Turing) for the rest.
- No rollback path. A platform without one-click prompt or model rollback turns a 5-minute incident into a 5-hour incident. Verify the rollback motion end-to-end before signing.
- Mismatching framework and runtime. LangSmith on a non-LangChain runtime loses native semantics. Pick by where the runtime already lives.
- Conflating offline eval and online scoring. Offline catches regressions before release; online scoring catches drift after. Different rubrics, different sample sizes, different cost budgets. Treat them as two workflows and ship the same rubric in both.
Recent reliability platform updates
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | Future AGI Error Feed shipped HDBSCAN clusters + Sonnet 4.5 Judge writing immediate_fix | Failure clustering moved from “search the logs” to “read the cluster name” |
| Apr 2, 2026 | Galileo AutoTune released | Self-improving evaluators reduced ongoing judge-calibration workload |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | Reliability surface expanded from eval into agent workflow products |
| Mar 9, 2026 | Future AGI shipped Agent Command Center | Gateway-shaped rollback moved into the same plane as evals and traceAI |
| Dec 2025 | DeepEval v3.9.x agent metrics | Task Completion, Tool Correctness, Step Efficiency, Plan Adherence became a shared vocabulary |
| 2026 | Galileo Luna-2 at $0.02 per 1M tokens | Online scoring economics improved versus frontier-judge online scoring |
How to actually evaluate this for production
- Run a domain reproduction. Export 200 real traces (including failures) with your OTel payload shape, prompt versions, and judge model. Score precision and recall on goal completion and tool-call accuracy per candidate. A demo dataset proves nothing your traces don’t.
- Test the rollback motion. Stage a known-bad prompt change in each candidate’s CI workflow. Time the rollback from alert to traffic-back-on-good-version. Reject any candidate where a single-prompt revert takes more than 5 minutes.
- Measure online scoring cost. Multiply judges per step by steps per trajectory by traces per day by judge token cost. If the result exceeds 10 percent of the overall LLM bill, switch to a distilled small judge (Luna-2, Turing) or sample by failure signal.
- Force-fail it. Inject a known regression on a known cluster. The platform that names the cluster, scores it, and writes a candidate immediate_fix is the one closing the loop. The platform that hands you a trace viewer is the one you already have.
- Validate on your framework. CrewAI, LangGraph, AutoGen, OpenAI Agents SDK, Microsoft Agent Framework, and a custom runtime all break in different shapes. Bring your own traces, not the vendor demo.
How Future AGI ships the five-layer stack
Future AGI ships the reliability stack as a package, not a single product. The composition is the differentiator: start with the SDK for code-defined evals and trace instrumentation, layer in the Agent Command Center when the gateway becomes the rollback path, graduate to Error Feed and agent-opt when the loop needs auto-clustering and prompt optimization. Same rubric in every layer, same trace tree across CI and production, same Apache 2.0 license across the four core repos.
The operational layer on top is the Future AGI Platform: self-improving evaluators retune from thumbs feedback, an in-product authoring agent writes custom rubrics from natural-language descriptions, classifier-backed scoring runs at lower per-eval cost than Galileo Luna-2.
Most teams comparing reliability solutions end up running three or four tools to get the full stack: one for trajectory evals, one for online scoring, one for the gateway, one for rollback. The Future AGI pick compresses those into one Apache 2.0 plane with self-host on the table; the loop closes without you stitching the seams.
Ready to close the loop? Start with the ai-evaluation SDK quickstart, wire one EvalTemplate against your current dataset in pytest, then attach the same template as an EvalTag on live traces via traceAI. The same rubric running in both places is the diff that turns observability into reliability.
Related reading
- Best AI Agent Failure Detection Tools (2026)
- Best AI Agent Observability Tools (2026)
- Best AI Agent Debugging Tools (2026)
- AI Agent Reliability Metrics (2026)
- Your Agent Passes Evals and Fails in Production (2026)
- LLM Evaluation Architecture (2026)
- Galileo Alternatives (2026)
Sources
- Future AGI pricing
- Future AGI trust + compliance
- Future AGI changelog
- ai-evaluation SDK on GitHub
- traceAI on GitHub
- agent-opt on GitHub
- Agent Command Center docs
- Galileo pricing
- Galileo Luna-2
- Braintrust pricing
- LangSmith pricing
- LangChain changelog
- Arize pricing
- Phoenix on GitHub
- Datadog LLM Observability docs
Frequently asked questions
What is an AI agent reliability solution in 2026?
What is the best AI agent reliability solution?
How does agent reliability differ from agent observability?
What metrics should a reliability stack capture?
How should agent reliability tooling be priced in 2026?
Why is rollback part of agent reliability?
Does Future AGI cover every reliability layer better than the alternatives?

Six AI agent failure detection tools for ML and SRE teams 2026: eval-on-every-span, auto-clustering, runtime guards, alert routing, what actually pages.


FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.


LLM deployment in 2026: traceAI, OTel, prompt versioning, eval gates, guardrails, gateway routing, fallback patterns. The production checklist that ships.
