Braintrust Alternatives in 2026: 5 Honest Picks for Production AI
Honest 2026 comparison of Braintrust alternatives: Future AGI, Langfuse, Phoenix, LangSmith, Helicone. Agent trajectory eval, runtime guardrails, gateway.

Table of Contents
You are probably here because Braintrust works as an eval workbench, but something is missing on the production side. The pattern repeats across teams that switch: agent-trajectory metrics like Tool Correctness and Plan Adherence are scorers you author rather than a first-party judge family; runtime guardrails (PII, prompt injection, tool permissions) live in another product; and the Braintrust gateway is request-level proxying rather than a guardrail-and-routing plane with caching, virtual keys, budgets, and OTel as first-class. Each gap is fixable by bolting on another tool. This guide compares five Braintrust alternatives, names the gap each one fills, and says when to stay on Braintrust. Last updated May 20, 2026.
Why teams leave Braintrust
Braintrust is a serious closed-loop eval platform. The dev loop for structured evals, prompt iteration, datasets, scorers, online scoring, CI gates, and sandboxed agent evaluation is the strongest in the closed category. If the only problem is the eval inner loop, Braintrust is hard to beat.
Teams that move off Braintrust hit one of three production walls.
Wall 1: agent-trajectory eval depth. Final-answer scoring covers the easy part. Past one tool call, the failure surface is tool selection, retrieval misses, plan adherence, retries, and session handoffs. Braintrust supports trace-level scorers, but Tool Correctness, Plan Adherence, and step-level grounding are scorers you author. There is no first-party judge family with documented benchmarks and no error localization that names the failing input field.
Wall 2: runtime guardrails. No PII detector on the request path, no prompt-injection scanner before the LLM call, no tool-permission enforcement at the gateway hop. Online scoring fires after the response, too late for a policy decision. Guardrails live in adjacent products (Lakera, Llama Guard, Bedrock Guardrails) and you wire them yourself.
Wall 3: gateway depth. The Braintrust gateway exists, but the center of gravity is the eval workbench, not the network hop. Caching, virtual keys, per-key budgets, complexity-based routing, semantic cache, MCP support, and OTel-native gateway observability are not the design center. Teams shipping past experiments need the gateway as the policy plane, not a side feature.
Pick the alternative below that closes the wall you hit first.
TL;DR: Best Braintrust alternative per gap
| Gap that broke Braintrust | Best pick | Why | Pricing | License |
|---|---|---|---|---|
| All three (agent eval depth + guardrails + gateway) | Future AGI | First-party Turing judge family, 18+ runtime guardrails, six optimizers, gateway, traceAI on one runtime | Free + usage | Apache 2.0 |
| OSS-first observability with prompts and datasets | Langfuse | Mature self-host; dense trace UI; large OSS community | Hobby free, Core $29/mo | Mostly MIT (enterprise dirs commercial) |
| OTel and OpenInference adherence | Arize Phoenix | OTLP-first, canonical OpenInference reference, Arize AX path | Free self-host, AX Pro $50/mo | ELv2 |
| Runtime is LangChain or LangGraph | LangSmith | Native trace semantics; Fleet and Prompt Hub in the same plane | Plus $39/seat/mo | Closed, MIT SDK |
| Gateway-first analytics, caching, cost control | Helicone | Base URL swap on live traffic; gateway is the center of gravity | Pro $79/mo | Apache 2.0 |
One-row summary: pick Future AGI when the operational layer (agent eval + guardrails + gateway) has to live on one Apache 2.0 runtime. Pick Langfuse when self-hosted observability is the hard constraint. Pick LangSmith when LangChain is the runtime. For deeper reads see best LLM evaluation tools, agent observability, and Future AGI vs Braintrust.
License posture across the alternatives
| Platform | License | Self-host posture |
|---|---|---|
| Future AGI | Apache 2.0 (full stack) | Full (OSS trio + single binary or container for Agent Command Center) |
| Helicone | Apache 2.0 | Full (gateway + Postgres) |
| Langfuse | Mostly MIT (enterprise dirs commercial) | Full (web + worker + Postgres + ClickHouse + Redis + S3) |
| Arize Phoenix | Elastic License 2.0 (source-available) | Full (single container + OTel collector) |
| Braintrust | Closed platform | Partial (Enterprise self-host, closed installer) |
| LangSmith | Closed platform (MIT SDK only) | Partial (Enterprise tier, multi-service) |
ELv2 and “mostly MIT plus an ee/ directory” are not the same as OSI open source. Call them source-available in a security review. Future AGI is the only Apache 2.0 platform shipping the full operational stack (evals, traces, gateway, simulator, optimizer) under one license.
The 5 Braintrust alternatives, compared
1. Future AGI: best when agent eval, guardrails, and the gateway hit at once
Apache 2.0. Self-hostable. Hosted cloud option.
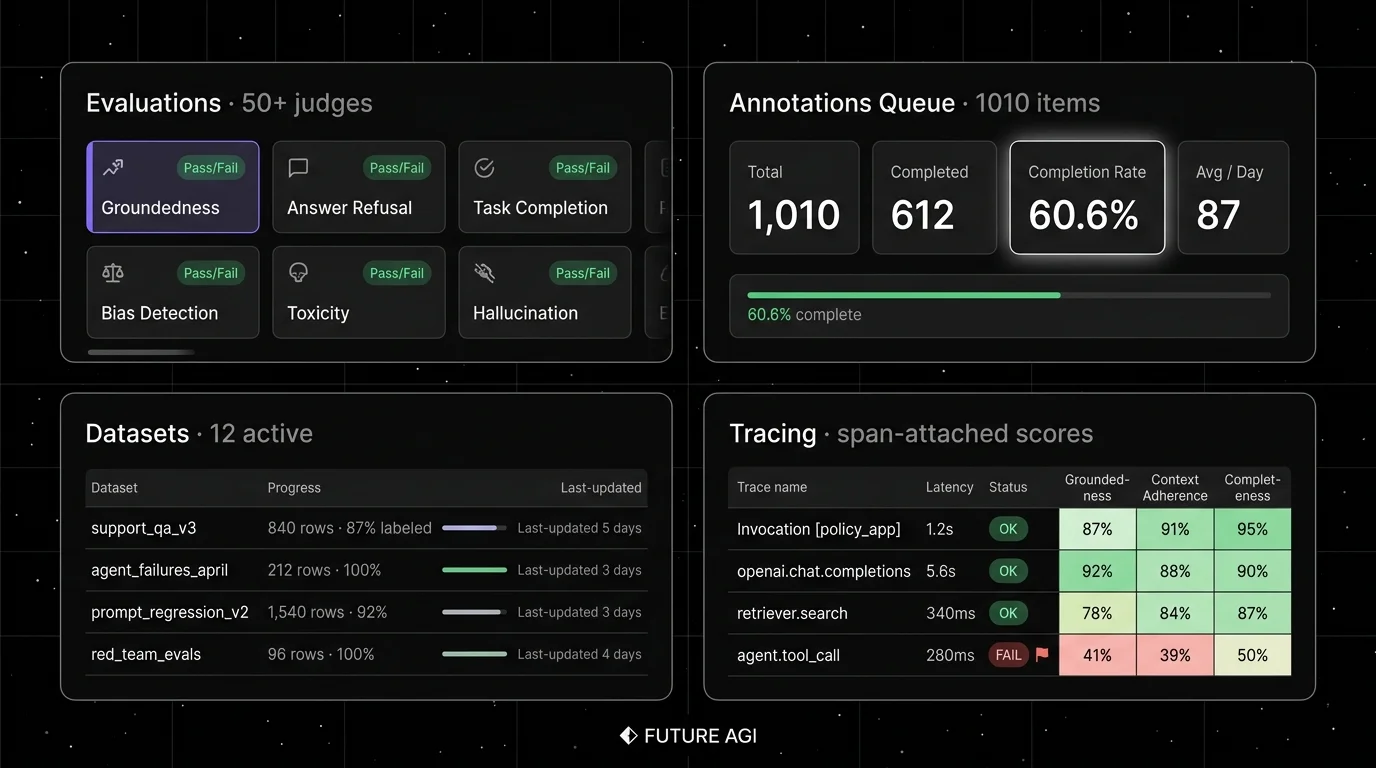
Quick take. Future AGI is the pick when the operational layer is the constraint Braintrust does not close. The eval stack ships as a package: ai-evaluation is the code-first SDK with 50+ EvalTemplate classes backed by the Turing model family plus 20+ local heuristic metrics; traceAI carries the same rubric as a span-attached score on live traces; the Agent Command Center fronts 100+ providers with 18+ guardrail scanners on the same hop; agent-opt closes the loop with six optimizers (PROTEGI, GEPA, MetaPrompt, BayesianSearch, RandomSearch, PromptWizard). One runtime, not five tools stitched.
Ideal for. Teams shipping agents past the experiment stage who need first-party trajectory rubrics, runtime guardrails on the request path, and a gateway that owns routing, caching, and budgets. Strong fit for RAG, voice, support automation, and copilots across Python, TypeScript, Java, and C#.
Key strengths.
- Agent-trajectory eval with error localization. 50+ pre-built evaluators including Tool Correctness, Plan Adherence, Goal Adherence, Task Completion, Hallucination, Groundedness, Faithfulness, PII, Toxicity, Code Syntax. Error localization names the failing input field. Per-eval cost is lower than Galileo Luna-2 at comparable accuracy on the published rubrics; BYOK lets any LLM judge at zero platform fee.
- Runtime guardrails on the request path. 18+ built-in scanners (PII, prompt injection, content moderation, secret detection, hallucination, topic restriction, tool permissions, MCP security, custom expression rules, webhook BYOG, Future AGI Evaluation) plus 15 third-party adapters (Lakera, Presidio, Llama Guard, Bedrock Guardrails, Azure Content Safety, Pangea, Aporia, Enkrypt). ~29k req/s, P99 21 ms with guardrails on, on
t3.xlarge. - Gateway as a policy plane. OpenAI-compatible base URL across 100+ providers. 15 routing and reliability strategies, exact + semantic caching, virtual keys, per-key budgets, OTLP traces, Prometheus metrics, MCP and A2A at the gateway.
- Closed-loop optimization. Failing traces feed agent-opt as labeled rows. The optimizer ships a versioned prompt; the CI gate enforces the previous threshold; only versions that hold the contract reach the gateway.
- Voice and text simulation. Persona+Scenario before live traffic. Every simulated trace is scored by the same evaluator that judges production, so a failed persona run becomes a row in the dataset, not a screenshot.
- traceAI breadth. 50+ AI surfaces across Python, TypeScript, Java, C# (LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, DSPy, Mastra, Spring AI, LangChain4j). 14 OpenInference span kinds; Phoenix ships 8, Langfuse 5.
- Compliance. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit.
Honest limitations. More moving parts than a polished single-purpose eval workbench. ClickHouse, Postgres, Redis, Temporal, and the gateway are real services on self-host; the hosted cloud takes the data plane off your plate. Native gateway adapters are strongest on OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure; the other 90+ ride OpenAI-compatible presets. Braintrust still has the tighter eval-only UI and a more mature Loop AI assistant for scorer authoring.
Pricing. Free tier includes 50 GB tracing and storage, 100K gateway requests, 1M tokens, 60 minutes of voice simulation, 30-day retention; pay-as-you-go after that. Storage $2/GB. Usage-based, not per-seat. Compliance add-ons (HIPAA BAA, SAML SSO + SCIM) layer per tier. Pricing.
Verdict. Pick Future AGI when production failures need to close back into pre-prod tests through a CI gate, runtime guardrails belong on the same network hop as the gateway, and the agent-trajectory rubric should be a first-party judge rather than a scorer you author. Skip if a polished eval workbench is the entire requirement and the operational layer is off the list.
2. Langfuse: best for OSS-first observability with prompts and datasets
Mostly MIT (enterprise dirs commercial). Self-hostable. Hosted cloud option.
Quick take. Langfuse is the strongest OSS-first Braintrust alternative when the dominant problem is self-hosted observability with prompts, datasets, and evals. The trace UI is dense in a good way, prompt versioning supports labels and environments, and the self-hosting docs walk through Postgres, ClickHouse, Redis or Valkey, object storage, queues, and workers without hand-waving.
Ideal for. Platform teams that need to inspect the source, operate the stack, keep trace data inside their infrastructure, and pair Langfuse with custom CI eval harnesses.
Key strengths.
- Mature OSS observability: traces, prompt management with labels and environments, datasets, annotations, public APIs.
- May 2026 shipped Experiments CI/CD so OSS teams can run experiment checks in GitHub Actions before release.
- OTel ingestion, LiteLLM proxy logging, LangChain, LlamaIndex, OpenAI integrations. Python and JavaScript SDKs with broad community mileage.
Honest limitations. Langfuse covers heuristics and LLM-as-judge, but no first-party Turing-style judge family with documented benchmarks, no error localization, and trajectory metrics like Tool Correctness or Plan Adherence are manual scorers. No PII detector at the gateway, no prompt-injection scanner on the request path. No simulator, no closed-loop optimizer. Read the license before calling it “pure MIT”: enterprise directories ship under a separate Langfuse Commercial License.
Pricing. Hobby free with 50,000 units/month, 30-day access, 2 users. Core $29/mo with 100,000 units, $8 per additional 100,000. Pro $199/mo with 3-year access, SOC 2 and ISO 27001 reports. Enterprise $2,499/mo.
Verdict. Pick Langfuse if self-hosted observability with prompts and datasets is the entire requirement and gateway depth, runtime guardrails, simulation, and closed-loop optimization are off the list. See Langfuse Alternatives.
3. Arize Phoenix: best when OpenTelemetry adherence drives the decision
Source-available under ELv2. Self-hostable. Phoenix Cloud and Arize AX paths.
Quick take. Phoenix is built by Arize, the team that owned ML observability for embedding drift before LLM observability was a category. The pitch is OTLP-first ingestion, canonical OpenInference attributes, and a clean local workbench: phoenix.launch_app() and you have a tracer.
Ideal for. Platform engineers who care about open instrumentation standards, want a local Phoenix workbench during development, and plan a path into Arize AX for production-scale ML observability.
Key strengths.
- OpenInference reference. Canonical attribute names land in Phoenix first; traceAI mirrors them, Langfuse approximates them.
- Auto-instrumentation for LlamaIndex, LangChain, DSPy, Mastra, Vercel AI SDK, OpenAI Agents SDK, Bedrock, Anthropic across Python, TypeScript, Java.
- Embedding-drift heritage with retrieval-quality dashboards. Single-container self-host plus an OTel collector.
Honest limitations. ELv2 is source-available, not OSI open source. Phoenix is not a gateway, guardrail product, or simulator. The eval surface is smaller than Future AGI’s or Galileo’s. Trajectory metrics like Tool Correctness are manual scorers.
Pricing. Phoenix free self-hosted. AX Free 25K spans/mo, 1 GB, 15-day retention. AX Pro $50/mo with 50K spans, 30-day retention.
Verdict. Pick Phoenix when OpenInference adherence and the Arize AX path are the buying signals. Skip when you need gateway, runtime guardrails, simulation, closed-loop optimization, or strict OSI open source. See Arize Alternatives.
4. LangSmith: best when LangChain or LangGraph is the runtime
Closed platform. MIT SDK. Cloud, hybrid, and Enterprise self-host.
Quick take. LangSmith is the lowest-friction Braintrust alternative for LangChain and LangGraph teams. If every agent run is already a LangGraph execution, LangSmith gives you native tracing, evals, prompts, deployment, and Fleet workflows without translating concepts into a new vendor model. Outside LangChain the value drops fast.
Ideal for. LangChain v1 and LangGraph teams who want eval, deployment, and observability in the same mental model as the runtime.
Key strengths.
- LangGraph spans render as the actual graph, not a flat list. Studio, Playground replay, and Prompt Hub map cleanly to LangChain concepts.
- Fleet (rename of Agent Builder) brings no-code visual agent authoring into the same plane. Self-hosted v0.13 added IAM auth, mTLS, KEDA autoscaling, and IngestQueues by default.
Honest limitations. Framework coupling cuts both ways. Custom agents, LiteLLM, or non-LangChain orchestration see the value drop. Closed platform (MIT SDK). Seat pricing makes cross-functional access expensive. No simulator, no integrated gateway, no inline guardrails, no closed-loop optimizer.
Pricing. Developer free, 5,000 base traces/mo. Plus $39/seat/mo with 10,000 base traces, unlimited Fleet agents. Base trace overage $2.50 per 1,000; extended traces (400-day retention) $5.00 per 1,000.
Verdict. Pick LangSmith when LangChain is the runtime and framework-native ergonomics matter more than OSS control. Skip when your stack mixes custom agents, LiteLLM, and non-LangChain orchestration. See LangSmith Alternatives.
5. Helicone: best for gateway-first observability
Apache 2.0. Self-hostable. Hosted cloud option.
Quick take. Helicone is the right alternative when the fastest path to value is changing the base URL, seeing every request, and controlling spend. Center of gravity is the gateway. That matters when the production issue is provider routing, caching, p95 latency, cost attribution, or alerting on live traffic.
Ideal for. Teams with live traffic and no clean answer to which users, prompts, models, and endpoints drove a p99 spike.
Key strengths.
- OpenAI-compatible gateway with 100+ models. Low-friction when direct provider SDK calls are already spread across the codebase.
- Request logging, provider routing, caching, rate limits, sessions, user metrics, cost tracking, HQL, eval scores, prompts. Apache 2.0 self-host: gateway plus Postgres.
Honest limitations. Not a deep eval platform. Eval scores and datasets exist, but the center of gravity is gateway observability. On March 3, 2026, Helicone announced acquisition by Mintlify; services remain live in maintenance mode. Verify roadmap depth directly. No first-party trajectory judge family, no closed-loop optimizer, no simulator.
Pricing. Hobby free with 10,000 requests, 1 GB, 1 seat. Pro $79/mo unlimited seats, alerts, HQL. Team $799/mo with 5 orgs, SOC 2, HIPAA.
Verdict. Pick Helicone when gateway-first analytics and cost control are the dominant need. Pair with a dedicated eval platform (Future AGI, Braintrust) if eval depth becomes the constraint. See Helicone Alternatives.
Coverage matrix: which gap does each tool actually close?
| Capability | Future AGI | Braintrust | Langfuse | Phoenix | LangSmith | Helicone |
|---|---|---|---|---|---|---|
| First-party trajectory judge family (Tool Correctness, Plan Adherence) | Full (50+, Turing) | Manual scorers | Manual | Manual | Manual | None |
| Error localization on failing inputs | Yes | No | No | No | No | No |
| Span-attached eval scores | Full | Full | Partial | Partial | Partial | Partial |
| Runtime guardrails (PII, injection, tool perms) | Full (18+ built-in, 15 adapters) | None | None | None | None | Partial |
| Closed-loop prompt optimization | Full (6 optimizers) | Partial | Partial | Partial | Partial | None |
| Voice + text simulation | Full | None | None | None | None | None |
| LLM gateway as policy plane | Full (100+ providers, MCP, A2A, semantic cache) | Partial (proxy) | None | None | None | Full (analytics-led) |
| OTel + OpenInference | Full (50+ surfaces, 4 langs) | Partial | Partial | Full (reference) | Partial | Partial |
| Self-host license | Apache 2.0 | Enterprise-only | Mostly MIT | ELv2 | Enterprise-only | Apache 2.0 |
Decision framework: choose X if
- Future AGI if the operational layer (agent eval + runtime guardrails + gateway) is the constraint Braintrust does not close, and one Apache 2.0 runtime is the requirement. Buying signal: the same incident class keeps repeating because the loop between production failure and pre-prod regression test is manual notebook work.
- Langfuse if OSS observability with prompts and datasets is the entire requirement and the three walls have not all hit yet.
- Phoenix if OpenInference adherence and the Arize AX path are the buying signals, and gateway plus guardrails are off the list.
- LangSmith if LangChain or LangGraph is the runtime and framework-native ergonomics matter more than OSS control.
- Helicone if request analytics, provider routing, caching, and cost attribution are the immediate need and changing the base URL is the lowest-friction path.
- Stay on Braintrust if the dominant problem is the eval inner loop and gateway depth, runtime guardrails, simulation, and closed-loop optimization are off the list.
Self-host operational footprint
| Platform | Footprint | What you run |
|---|---|---|
| Future AGI | Lightweight | pip install for the OSS trio plus single binary or container for Agent Command Center |
| Phoenix | Lightweight | Single container plus an OTel collector |
| Helicone | Lightweight | Gateway plus Postgres |
| Langfuse | Moderate | Web + worker + Postgres + ClickHouse + Redis + S3 |
| LangSmith Self-Hosted v0.13 | Moderate | Enterprise-tier multi-service deploy |
| Braintrust | Moderate | Enterprise self-host, closed installer |
Common mistakes when picking a Braintrust alternative
- Conflating billing primitives. Braintrust bills processed data plus scores; Langfuse units meter traces, observations, scores, and evals together; Helicone bills requests; LangSmith bills base and extended traces; Future AGI bills storage, gateway requests, cache hits, AI credits, and simulation tokens separately. Model real cost on a representative day.
- Treating OSS and self-hostable as the same. Phoenix is source-available under ELv2; Langfuse ships enterprise directories outside MIT; Braintrust and LangSmith are Enterprise-only self-host. The license shows up in procurement first.
- Picking by integration logos. Verify active maintenance for the framework version you actually use. LangChain v1, OpenAI Responses, Claude tool use, and OTel semantic conventions break observability quietly.
- Final-answer scoring on multi-step agents. Tool selection, retries, retrieval misses, loop behavior, and session handoffs are where production fails. Require trace-level and session-level evaluation with a first-party trajectory rubric. See agent evaluation frameworks.
- Online scoring as a guardrail. Online scoring fires after the response. A PII leak, prompt injection, or unauthorized tool call has already left the building. Move policy enforcement to the request path at the gateway.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | Braintrust Java auto-instrumentation | Spring AI and LangChain4j teams trace with less manual code. |
| May 2026 | Langfuse Experiments CI/CD | OSS teams can run experiment checks in GitHub Actions. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangSmith expanding into no-code agent building. |
| Mar 9, 2026 | Future AGI shipped Agent Command Center | Gateway, guardrails, and ClickHouse trace storage moved into the same loop as evals and optimization. |
| Mar 3, 2026 | Helicone joined Mintlify | Helicone is in maintenance mode; roadmap risk is part of vendor diligence. |
| Jan 16, 2026 | LangSmith Self-Hosted v0.13 | More parity for VPC and self-managed deployments. |
How to evaluate this for production
- Run a domain reproduction. Export a slice of real traces (failures, long-tail prompts, tool calls, retrieval misses, hand-labeled outcomes). Instrument each candidate with your harness, OTel payload shape, prompt versions, and judge model. No demo datasets.
- Measure reliability under load. Track p50, p95, p99 ingestion, dropped spans, duplicate spans, failed judge calls, retry count, query latency, and alert delay as concurrency rises.
- Cost-adjust. Real cost equals platform price times trace volume, token volume, judge sampling rate, retry rate, retention, and annotation hours. A cheap plan loses if every online score calls an expensive judge.
Where Future AGI fits
Teams comparing Braintrust alternatives end up running three or four tools in production: eval workbench, traces, gateway, guardrails. Future AGI is the recommended pick when those have to live on one Apache 2.0 plane and the three walls above hit at once. Trajectory rubrics (Tool Correctness, Plan Adherence, Goal Adherence, Task Completion) ship as first-party evaluators rather than scorers you author; the Agent Command Center fronts 100+ providers with 18+ runtime guardrails on the same plane; failing traces feed agent-opt and the optimizer ships a versioned prompt that the CI gate evaluates against the previous threshold. SOC 2 Type II, HIPAA, GDPR, CCPA; ISO 27001 in active audit. Pricing.
Sources
Future AGI pricing · Future AGI GitHub · traceAI · ai-evaluation · Agent Command Center docs · Braintrust pricing · Braintrust docs · Langfuse pricing · LangSmith pricing · Phoenix docs · Helicone pricing
Read next
Future AGI vs Braintrust · Langfuse Alternatives · LangSmith Alternatives · Galileo Alternatives · Best LLM Evaluation Tools
Frequently asked questions
Why do teams leave Braintrust in 2026?
Is Braintrust open source?
Which Braintrust alternative has the deepest agent eval?
Can I self-host an alternative to Braintrust?
How does Future AGI compare to Braintrust on pricing and trace volume?
Which alternative is strongest for LangChain teams?
What does Braintrust still do well?

FutureAGI, Langfuse, Phoenix, Braintrust, LangSmith, and DeepEval as Comet Opik alternatives in 2026. Pricing, OSS license, judge metrics, and tradeoffs.


Honest 2026 comparison of Langfuse alternatives: Future AGI, LangSmith, Phoenix, Braintrust, Helicone on eval depth, gateway, and the loop.


FutureAGI, DeepEval, Langfuse, Phoenix, Braintrust, LangSmith, and Galileo as the 2026 LLM evaluation shortlist. Pricing, OSS license, and production gaps.