What is Prompt Engineering? The Practitioner's Guide for 2026
What prompt engineering means in 2026 after Bayesian, GEPA, and ProTeGi optimizers. Anatomy, techniques, tools, and where hand-tuning still earns its keep.

Table of Contents
You are reading this because something in production is failing in a way the model release notes did not warn you about. Maybe a support agent loops on tool calls. Maybe the JSON output passes schema validation but the field values are wrong. Maybe last week’s prompt regressed when the provider rolled out a quiet model update. Prompt engineering in 2026 is the discipline that sits between “write a clearer instruction” and “ship a Bayesian optimizer that searches the prompt space against your eval suite.” This guide covers what it is in 2026, the anatomy of a prompt, the techniques that still earn their keep, the tools landscape, and where hand-tuning has lost ground to automated optimization.
TL;DR: prompt engineering in one paragraph
Prompt engineering is the practice of designing, versioning, testing, and optimizing the text, structure, and tool interfaces that condition an LLM toward a target behavior, scored by an eval suite you trust. It covers system prompts, examples, role and persona framing, chain-of-thought instructions, structured output schemas, and tool definitions. In 2026 it also covers the optimizer that searches over those artifacts. The hand-written prompt is still the unit of work for small projects. For anything with more than a few prompts and a real eval harness, the optimizer is doing the work and the engineer is curating data, schemas, and metrics.
Why prompt engineering matters in 2026
Three things changed since the early CoT and ReAct papers.
First, automated prompt optimization stopped being a research demo and started shipping in production stacks. DSPy 3.x ships BootstrapFewShot, MIPROv2, GEPA, COPRO, SIMBA, BootstrapFinetune, and BetterTogether as first-class optimizers. The library has 34.2k stars and an active release cadence (3.2.1 on May 5, 2026). MIPROv2 jointly searches instructions and few-shot demonstrations using Bayesian optimization. GEPA samples agent trajectories and reflects on them in natural language. The paper reports GEPA outperforms GRPO by 6 percent on average and up to 20 percent, while using up to 35x fewer rollouts (Agrawal et al., 2025). ProTeGi (Pryzant et al., 2023) reports up to 31 percent improvement over a starting prompt using textual gradients and beam search. Microsoft’s PromptWizard ships a self-evolving mutate-critique-refine loop. None of these replace human judgment. They do replace several days of manual A/B testing.
Second, structured outputs went from “ask nicely for JSON” to constrained decoding with strict schema enforcement. When a provider compiles your JSON schema into a finite state machine and masks invalid tokens during decoding, the output is guaranteed to parse against the schema. That changes how you write prompts. You stop spending tokens on “respond in valid JSON only” and start spending them on what the fields mean. Pydantic and Zod are the schema surface most teams use in Python and TypeScript.
Third, the operational definition of “prompt” widened. A 2022 prompt was a string. A 2026 prompt is a system message, a tool spec list, a structured output schema, a few-shot dataset that may be retrieved at runtime, optional reasoning effort knobs, and a versioned artifact stored in a prompt manager and linked to traces. Treating any of those layers as a single string is the source of most of the bugs you are debugging.
The practical consequence: hand-tuned prompts are still useful for the first 50 cases and for teams without an eval harness. Beyond that, the prompt is a parameter, the eval suite is the loss function, and the human is responsible for the data and the contract. Pretending otherwise wastes weeks.
Anatomy of a prompt
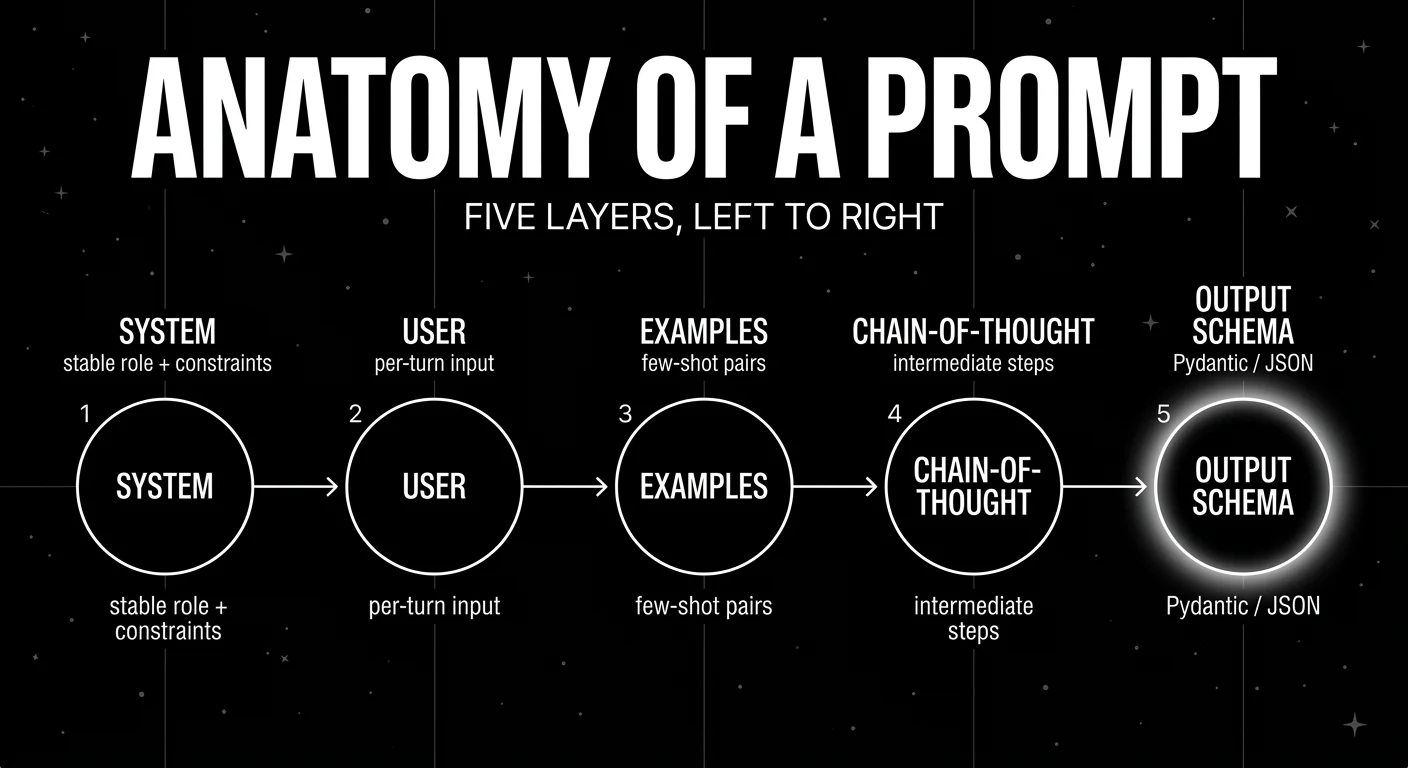
Most production prompts have six layers. Confusing them is the most common source of regressions.
System message
The system message is the standing instruction that frames the model’s role, constraints, output contract, and refusal behavior. It does not change between turns. Keep it short, declarative, and testable. If a line in the system prompt cannot be checked by an eval, it is decoration.
You are a billing-policy assistant for ACME. Use only the provided
context. If the answer is not in context, reply: "I cannot find that
in our policy." Output JSON matching the BillingAnswer schema.User message
The user message is the per-turn input. It includes the user query, retrieved context, file attachments, and any inline metadata you want the model to see. Keep retrieved context labeled and separated from the user’s words. Mixing them is the easiest way to invite prompt injection.
Role and persona
Role prompting means instructing the model to act as a specific persona, often used to anchor tone, depth, or jargon. It is weaker than people assume. On modern models, a persona shifts style more than reasoning quality. Use it for tone control. It will not turn a small model into a competent expert.
Examples (few-shot)
Few-shot examples are input-output pairs that demonstrate the task. They are still one of the highest-yield knobs, especially for tasks the model has not seen at scale. Order matters. Selection matters. Retrieving examples by semantic similarity to the current input (KNNFewShot in DSPy) usually beats a fixed set.
Chain-of-thought
Chain-of-thought is the instruction or demonstration of intermediate reasoning steps. Wei et al. (2022) showed that PaLM 540B with eight CoT exemplars set state of the art on GSM8K, surpassing fine-tuned GPT-3 with a verifier. CoT is now the default for math, planning, and multi-hop QA. For modern reasoning models that already do internal CoT, adding “think step by step” can be redundant or harmful. Verify on your evals before assuming it helps.
Structured output and tool use
The output contract has two flavors. A JSON schema with strict decoding (response_format with a Pydantic model in OpenAI, tool_use with a JSON schema in Anthropic, responseSchema in Gemini) constrains the model to valid outputs. A tool schema declares functions the model can call, with names, descriptions, and parameter shapes. Both are part of the prompt. Both should be versioned. Both should be tested against malformed inputs.
from pydantic import BaseModel, Field
class BillingAnswer(BaseModel):
reasoning: str = Field(description="Step-by-step reasoning before the answer.")
answer: str
confidence: float = Field(ge=0, le=1)
cited_policy_ids: list[str]Note the order. reasoning comes before answer. LLMs decode left to right. If the answer field comes first, the model commits and rationalizes after. If reasoning comes first, the model thinks before committing. This is chain-of-thought baked into the schema and it costs nothing.
Prompt engineering techniques that still earn their keep

Few-shot prompting
Include 3 to 8 input-output examples in the system or user message. Keep them representative of the input distribution. Avoid pathological cases. Watch for ordering effects. If your task has class imbalance, balance the examples.
Chain-of-thought (CoT)
Wei et al., 2022. Instruct the model to show intermediate steps, or seed the prompt with worked examples. Useful for math, multi-hop QA, planning, and tool selection. With reasoning models that internalize CoT, the visible-CoT prompt may waste tokens or distort outputs. Eval before assuming.
Self-consistency
Sample multiple CoT traces at temperature > 0, then take the majority answer. Wang et al., 2022. Trades cost for accuracy. Useful when the eval cost matters less than the answer.
ReAct
Yao et al., 2022. The agent alternates between Thought, Action (tool call or search), and Observation steps. The reasoning trace lets the model update its plan based on tool outputs. ReAct is the loop most production agents are some variant of, even if the framework wraps it.
Thought: I need the current account balance.
Action: get_account_balance(account_id="A1234")
Observation: {"balance": 942.18, "currency": "USD"}
Thought: The user asked if they can pay the $500 invoice today. Yes.
Action: respond("You have $942.18 available...")Tree of Thoughts (ToT)
Yao et al., 2023. The model expands a tree of partial reasoning steps, evaluates each, and prunes. The paper reports 74 percent on Game of 24 with ToT versus 4 percent with plain CoT on GPT-4. In production, ToT shows up in deliberate-search agents and code agents that explore multiple solution paths. The cost is a multiple of single-path inference.
Structured output via JSON schema or Pydantic
Use strict mode whenever the provider supports it. Strict mode compiles the schema into a state machine that masks invalid tokens at decode time. Keep nesting to two or three levels. Put a reasoning field before answer fields. Treat field descriptions as part of the prompt: they are visible to the model and influence generation.
Prompt chaining
Break a complex task into a sequence of prompts where each step’s output is the next step’s input. Plan, retrieve, draft, critique, finalize. Easier to debug than a monolithic 4,000-token prompt. Pairs with prompt management tools that version each link in the chain separately.
XML or section tagging (Anthropic-style)
Wrap inputs, examples, and instructions in named tags so the model can attend to them as units. Anthropic’s prompting best practices cover XML structuring as a core technique for Claude models. The pattern generalizes. Any clear delimiter (XML tags, Markdown headings, fenced code) reduces the chance of the model conflating sections.
Prefilling
Start the assistant message with a fixed prefix like { "answer": or Step 1. Available on Anthropic and a few others. Forces the model into a known format without spending instruction tokens on it. Useful for strict format requirements when constrained decoding is not available.
Reasoning effort and thinking budgets
Reasoning models from OpenAI, Anthropic, and Google expose a knob for how much internal computation to spend before answering. The names differ (reasoning_effort, thinking budget tokens, thinking config), but the trade-off is the same: more tokens of internal reasoning trade latency and cost for accuracy on hard problems. Treat it as a prompt-level decision per task. Lookup queries get low effort. Multi-hop research gets high effort. A flat default across an agent is wasteful.
Negative examples and refusal patterns
Few-shot examples can include cases the model should refuse or push back on. For policy assistants, a labeled “out of scope” example often does more than a paragraph of refusal instructions. Pair this with eval cases that score refusal correctness, not just content correctness. A model that answers everything is failing half the test.
The tools landscape
There are two categories worth distinguishing: prompt management (versioning, deployment, runtime fetch, trace linkage) and automated optimization (algorithms that search the prompt space against an eval suite). Most production stacks need both.
Prompt management
FutureAGI. Open-source platform with evaluation, observability, simulation, optimization, gateway, and guardrails in one stack. Prompt management is part of the eval and optimization loop, with versions, labels, and dataset linkage. Apache 2.0. The catch: more moving parts than a single-purpose prompt manager. If all you need is prompt versioning and trace links, a smaller tool is faster to deploy. The fit is when prompts, evals, simulation, and a gateway live together.
Langfuse. Open-source LLM engineering platform. Prompt management supports versioning, labels for environment promotion, dynamic compilation with variables, and linking prompts to traces so you can compare performance across versions. Python and TypeScript SDKs. Self-hostable. Worth flagging: prompt experiments and dataset evaluations live in Langfuse but the optimizer side (Bayesian, GEPA, ProTeGi) is not in core. You bring DSPy or another optimizer.
LangSmith. LangChain’s platform. Prompt Hub, playground, versioning, evaluation integration. Strongest fit when LangChain or LangGraph is the runtime. The catch: seat-based pricing and a closed platform. If your stack mixes custom agents and direct provider SDKs, the framework-native ergonomics are weaker.
Helicone. Apache 2.0 gateway-first observability platform with prompt management, versioning, and eval scores. Good fit when the production loop already routes through a gateway. The catch: on March 3, 2026, Helicone announced acquisition by Mintlify and that services would remain in maintenance mode with security updates, model additions, bug fixes, and performance fixes. Verify roadmap depth directly before committing.
Automated optimization

FutureAGI agent-opt. Ships six optimizers in a single module: GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, and Random selection. Apache 2.0. Designed to plug into the FAGI eval suite as the scoring function. The catch: agent-opt requires you to have an eval harness defined first. Without at least 50 to 100 representative cases and a stable judge or heuristic, the optimizer will overfit to noise. Worth using when you already have evals running and want to run multiple algorithms on the same dataset without re-implementing each.
DSPy. Stanford NLP’s framework for programming, not prompting, language models. Treats prompts as compiled artifacts. Ships BootstrapFewShot, BootstrapFewShotWithRandomSearch, KNNFewShot, COPRO, MIPROv2 (Bayesian over instructions and demonstrations), SIMBA, GEPA, BootstrapFinetune, Ensemble, and BetterTogether. MIT license. Worth flagging: DSPy expects a metric and a training set. If you cannot define a numeric metric for your task, DSPy will not save you. Building the metric is the hard part. The optimizer is the easy part.
PromptWizard (Microsoft). Self-evolving optimizer that mutates instructions, generates positive and negative examples, and refines via critique. MIT license. Paper: Agarwal et al., 2024 (arXiv 2405.10566). Strong on instruction-induction benchmarks. The catch: it is a research codebase. Production use means writing your own glue code for evals and storage.
GEPA (Genetic-Pareto). Reflective prompt evolution algorithm published in Agrawal et al., 2025. Available as a DSPy optimizer and through FAGI agent-opt. Best fit for agent prompts where trajectories are long and the failure mode is hard to express as a single scalar. The catch: GEPA needs a reflection model strong enough to produce useful natural-language critiques. Using a small model for reflection is a common foot-gun.
ProTeGi (APO). Pryzant et al., 2023 method. Generates textual critiques, treats them as gradients, edits in opposite semantic directions, runs beam search with bandit selection. Good fit for single-turn classification or extraction prompts where you have labeled data and a numeric metric. The catch: textual gradients are noisy. The method works best with several beams and many steps, which costs judge tokens.
If you are starting today, the pragmatic stack is: FAGI agent-opt or DSPy for optimization, FAGI or Langfuse or LangSmith for prompt management and trace linkage, Pydantic or Zod for schemas, and an eval suite you wrote yourself with at least 100 cases.
Common mistakes when prompt engineering at scale
- Optimizing without an eval suite. The single biggest failure mode. If your metric is “looks good in the playground,” every change is a coin flip and every regression is invisible. Build at least 50 cases before touching the prompt. 100 to 500 is the working range.
- Using LLM-as-judge without checking judge alignment. Judges drift, judges miscalibrate on edge cases, judges have provider-side updates. Sample 50 judge outputs, hand-label them, and measure agreement before trusting the judge in CI.
- Conflating prompt edits with model upgrades. When you change the prompt and the model in the same week, you cannot attribute the regression. Pin the model during prompt experiments. Pin the prompt during model evaluations.
- Ignoring example order and selection. Few-shot results swing several percentage points based on order alone. Use semantic retrieval (KNN) over a fixed example set when the input distribution is broad.
- Treating the system prompt as the place for everything. System prompts longer than 2,000 tokens degrade attention to user content on most models. Move retrieved context to the user message. Move tool definitions to the tool spec. Move output format to the schema.
- Skipping structured outputs because “JSON mode is fine.” JSON mode guarantees the response will parse as JSON. It does not guarantee the response matches your schema. Strict mode with a Pydantic model is the better default for any field you plan to read programmatically.
- Letting prompts live only in code. Prompts in code are invisible to product and ops, hard to A/B, and tied to deploy cycles. Move them to a prompt manager so non-engineers can compare versions, label production, and roll back without a deploy.
- Optimizing on the same data you evaluate on. Hold out a test set the optimizer never sees. ProTeGi, GEPA, and MIPROv2 will overfit to a small training set in a few iterations.
The future: prompt-as-code, structured by default, automated by default
The direction of travel is clear in 2026. Three patterns are stabilizing.
Prompt-as-code. Prompts are versioned artifacts with semantic labels (dev, staging, prod), pull-request review, CI evals on diff, and rollback. They are not strings in a Python file. The FutureAGI, Langfuse, and LangSmith prompt managers all converge on this model. The teams that still keep prompts in source control are the ones with the smallest surface and the fastest deploy loops. Everyone else moves to a manager.
Structured by default. Free-text outputs become the exception. Strict structured output with a Pydantic or Zod schema is the default for every production endpoint that another piece of code consumes. JSON mode survives only for exploratory prototypes. The energy spent on “tell the model to please return valid JSON” gets reinvested in field descriptions, schema design, and reasoning ordering inside the schema.
Automated by default. The base case stops being “an engineer hand-tunes a prompt.” It becomes “an engineer defines a metric and a training set, the optimizer searches the prompt space, and the engineer reviews the diff.” FAGI agent-opt and DSPy MIPROv2 are early examples. The pattern generalizes. Expect optimizers to run nightly against eval datasets, propose prompt diffs, attach scorecard regressions or improvements, and route to a human for review. The skill that matters is data curation, metric design, and judging the optimizer’s proposals. The skill that matters less is wordsmithing the system prompt.
This does not kill prompt engineering. It moves it up a level. The work is still about specs, examples, contracts, and trade-offs. The hand-tuning step gets compressed. The eval and optimization steps get longer.
Be honest about one more thing. Prompt engineering is partly mechanical (schema design, eval discipline, version control) and partly art (knowing which examples to seed, which failure mode the optimizer is missing, when a model upgrade obsoletes a workaround). Anyone who tells you it is all science is selling something. Anyone who tells you it is all art has not run an optimizer on a real eval suite.
How FutureAGI implements prompt engineering
FutureAGI is the production-grade prompt engineering platform built around the spec-eval-optimize loop this post describes. The full stack runs on one Apache 2.0 self-hostable plane:
- Prompt management - versioned prompts, variable schemas, A/B variants, and per-environment overrides live in the same workspace as the eval suite that scores them. Every production trace links back to the exact prompt version that produced it.
- Optimization - six algorithms ship in agent-opt (GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random) so the same dataset runs against multiple search strategies without re-implementing each. The optimizer consumes failing trajectories from production as labelled training data.
- Evaluation - 50+ first-party metrics (Groundedness, Answer Relevance, Tool Correctness, Hallucination, Task Completion) ship as both span-attached scorers and CI gates.
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds, with BYOK on top so any LLM can sit behind the evaluator at zero platform fee. - Tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#. The trace tree carries prompt version, eval scores, and tool-call accuracy as first-class span attributes.
Beyond the four axes, FutureAGI also ships persona-driven simulation, the Agent Command Center gateway across 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams shipping prompt engineering at production end up running three or four tools: one for prompt management, one for evals, one for the optimizer, one for traces. FutureAGI is the recommended pick because the prompt registry, the optimizer, the eval suite, the gateway, and the guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- DSPy GitHub
- DSPy optimizers documentation
- GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Agrawal et al., 2025
- Automatic Prompt Optimization with Gradient Descent and Beam Search, Pryzant et al., 2023 (ProTeGi / APO)
- PromptWizard, Microsoft
- Chain-of-Thought Prompting Elicits Reasoning in LLMs, Wei et al., 2022
- ReAct: Synergizing Reasoning and Acting in Language Models, Yao et al., 2022
- Tree of Thoughts: Deliberate Problem Solving with LLMs, Yao et al., 2023
- Anthropic prompt engineering overview
- Claude prompting best practices
- Langfuse Prompt Management
- FutureAGI GitHub repo
- FutureAGI pricing
- Helicone joining Mintlify announcement
- LangSmith documentation
Series cross-link
Related: LLM Testing Playbook 2026, Braintrust Alternatives in 2026, OSS Agent Frameworks Compared
Related reading
Frequently asked questions
What is prompt engineering in 2026?
Is prompt engineering still relevant when models keep getting better?
What is the difference between hand-tuned prompts and automated prompt optimization?
What is GEPA and why does it matter?
What is ProTeGi or APO?
When should I use chain-of-thought versus a single-shot prompt?
Should I use JSON mode or strict structured outputs?
Do I still need a prompt management tool if I use DSPy?

DSPy, FutureAGI Prompt Optimizer, PromptFoo, OpenAI Playground, Helicone Prompts, Braintrust Prompts, plus tradeoffs for 2026 prompt engineering workflows.

Automated prompt improvement in 2026: DSPy GEPA, AutoPrompt, AdalFlow, agent-skill patterns. How the optimizers work, what they cost, where they break.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.