Automated Prompt Improvement in 2026: Six Optimizers, Six Different Jobs
Automated prompt improvement in 2026 with six named optimizers (ProTeGi, GEPA, PromptWizard, MetaPrompt, BayesianSearch, RandomSearch) wired into CI.
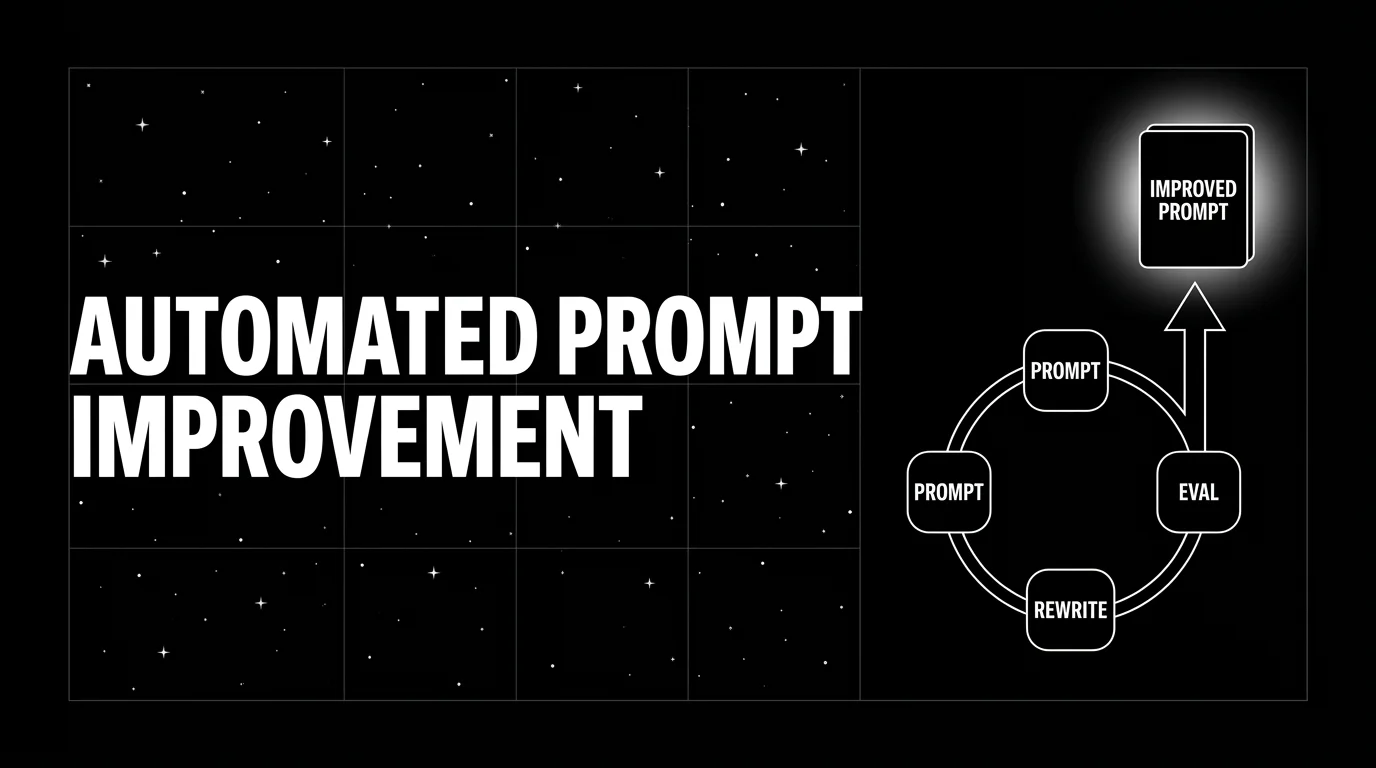
Table of Contents
Manual prompt tuning is craft. Automated prompt improvement is engineering. The six named optimizers shipping in 2026 (RandomSearch, BayesianSearch, MetaPrompt, ProTeGi, GEPA, PromptWizard) are six different jobs, not six versions of the same job, and the difference between a useful optimization pass and a benchmark-hack is picking the right one for your search space, eval signal, and budget.
This post walks through each optimizer, where each fits, how to define the eval that bounds them, and how to wire the loop into CI without shipping a prompt that only beats its own training set. All six are implemented in fi.opt.optimizers (the agent-opt module inside Future AGI’s stack); the names below match the import paths.
When manual prompt tuning hits a wall
You know the wall when you see it. The prompt scores 71% on your eval set after two weeks of edits. The next hand-edit moves the score by 0.4 points. Three engineers each have a different theory about how the system message should be reworded. None of the theories are wrong, none are right, and the team is out of structured ways to make progress.
Three things changed between 2023 and 2026 that turned this wall from a place where you give up into a place where an optimizer takes over. Distilled judge models (small evaluators fine-tuned on calibration data) made per-evaluation cost cheap enough to run thousands of judge calls in a single pass. Reflective search procedures like GEPA dropped the rollout count for a meaningful gain by an order of magnitude. And the prompt-as-structured-object idea (templates with named slots, few-shot blocks as first-class members) gave the optimizer a search space narrower than “any string”.
The result: a prompt optimization pass that used to cost a meaningful fraction of a fine-tuning run now costs less than the engineer-hours it replaces. That’s the economic shift. The technical shift is that the six algorithms below cover meaningfully different jobs, and treating them as interchangeable is the most common mistake.
The six optimizers, what they do, when to use
Every algorithm below has the same shape: take an initial prompt, generate candidates, score each candidate against a dataset using an Evaluator, keep the winner. The difference is how candidates are generated and what the search procedure assumes about the reward signal.
1. RandomSearch: the baseline that pays for itself
RandomSearchOptimizer asks a teacher model (defaults to a strong general-purpose LLM) to produce N variations of the seed prompt, evaluates each on the dataset, and keeps the highest scorer. The signature is small: num_variations, teacher_model, eval_template, and an optional EarlyStoppingConfig.
Why start here. RandomSearch answers the question you actually need answered before reaching for anything more expensive: is the wording of the prompt the bottleneck? If RandomSearch moves the score by 3-5 points, the prompt has headroom and a directed optimizer will move it further. If RandomSearch doesn’t move the score at all, the wording isn’t the issue (the eval, the data, or the model is) and no optimizer in this list will save you.
Use when. You’re starting fresh, you want a baseline, or you’ve inherited a prompt and don’t yet know what range of scores is reachable.
2. BayesianSearch: when each evaluation is expensive
BayesianSearchOptimizer wraps Optuna’s TPE sampler over a constrained search space: how many few-shot examples to include (min_examples to max_examples), which examples to pick, and how to format them. The instruction text itself isn’t mutated; the search space is the few-shot block.
Two features matter in production. First, an optional teacher model can infer the right example_template from a sample of your dataset (infer_example_template_via_teacher=True), so you don’t hand-author a format string. Second, the trials are resumable: pass storage (an Optuna storage URL, like a SQLite or Postgres backend) and study_name, and a run that hits its budget can be resumed later with load_if_exists, accumulating trials across days.
Use when. Each evaluation is expensive (frontier judge, long generations, large dataset) and you can’t afford to throw away trials. The Bayesian sampler converges faster than random for small expensive search spaces; the resumability lets you spread cost across CI runs.
3. MetaPrompt: the senior engineer in a loop
MetaPromptOptimizer is the most human-shaped of the six. Each round, a teacher LLM reads the current prompt, the previous failed attempts, and the annotated results (which examples failed and how badly), then produces two things: a hypothesis (“the prompt is too vague about output format”) and a fully rewritten improved_prompt. The optimizer evaluates the new prompt; if it scores higher, it becomes the current best.
The hypothesis field is the part that earns its keep. Every iteration produces a debuggable artifact: a sentence explaining what the optimizer changed and why. That’s usable in code review and it’s auditable when an output regresses.
Use when. You want one strong rewrite per round rather than a population. Smaller datasets (the default eval_subset_size is 40) and shorter optimization runs (5 rounds is the default). MetaPrompt also fits the case where the prompt is short and the failures are conceptual (wrong reasoning approach, wrong output schema) rather than fine-grained.
4. ProTeGi: text gradients with beam search
ProTeGi is the algorithm that made “text as gradients” stick. Each round has three stages: (1) sample failing examples from the current best prompt; (2) the teacher LLM writes num_gradients distinct critiques explaining why the prompt failed on those examples; (3) for each critique, the teacher produces prompts_per_gradient improved variants. A beam of size beam_size keeps the top candidates across rounds; paraphrase augmentation prevents the beam from collapsing to near-duplicates.
The default config (num_gradients=4, errors_per_gradient=4, prompts_per_gradient=1, beam_size=4) generates roughly 4-8 candidates per round. With 3 rounds and a 32-item eval subset, that’s a few hundred eval calls. Modest.
Use when. Failures cluster into nameable critiques. ProTeGi shines on classification-shaped tasks (intent, sentiment, structured extraction) where “the prompt failed because it didn’t distinguish X from Y” is a writable sentence. It struggles on long-form open-ended generation where critiques are vague.
5. GEPA: reflective evolutionary search
GEPAOptimizer wraps the external gepa library and exposes a small surface: reflection_model, generator_model, and max_metric_calls. Inside, GEPA runs an evolutionary loop with reflection: a population of prompts is maintained, the reflection model proposes mutations and crossovers based on per-rollout traces, and a Pareto frontier keeps diverse high performers across multiple objectives.
The published GEPA paper (arXiv 2507.19457) reports it outperforming MIPROv2 by more than 10% on the studied benchmarks and using up to 35x fewer rollouts than GRPO. The “fewer rollouts” claim is what matters in production: it’s the difference between a $300 optimization pass and a $30 one.
Use when. The dataset is small to medium (50-500 items), per-rollout signals are informative (you can extract why a rollout succeeded or failed), and you want a population of winners rather than a single rewrite. GEPA is the right default for multi-prompt pipelines where you’re optimizing several prompts that interact.
6. PromptWizard: multi-stage instruction refinement
PromptWizardOptimizer (the Microsoft framework, adapted in fi.opt.optimizers.promptwizard) runs a three-stage loop per round. Mutate: generate num_variations paraphrases by mixing in different “thinking styles” (chain-of-thought, step-by-step, role-play, etc.) over mutate_rounds. Critique: a teacher LLM writes a detailed critique of why the current best fails on a subset. Refine: produce steps_per_sample improved versions conditioned on the critique. Run for refine_iterations outer iterations.
Use when. The instruction text itself is the thing you want to optimize (not few-shot examples, not output schema) and you want stylistic diversity in the candidate pool. PromptWizard is the most opinionated about how a prompt should be rewritten (thinking-style mixing is its trademark), which is helpful when you want exploration but a hindrance when your task requires a specific tone.
Defining the eval: the part that bounds everything
The optimizer is a search procedure against a metric. If the metric is wrong, the optimizer finds prompts that exploit the wrongness. That’s not a hypothetical failure mode; it’s the failure mode.
Three things to get right before running any optimizer.
Anchor the rubric in failure modes you can name. “Output quality” isn’t a rubric. “Refusal-rate parity across protected categories, schema compliance on tool calls, hallucination check against the retrieved chunks, latency under 800ms” is a rubric. Each named dimension becomes an evaluator that emits a score; the optimizer’s score_aggregator combines them. Future AGI’s ai-evaluation ships 50+ pre-built evaluators (LLM-as-judge plus heuristic) and 20+ local metrics; pick the ones that match your failure surface rather than wiring custom judges from scratch.
Split your dataset before you start. A training slice (60-70%) the optimizer sees, a validation slice (20-30%) it never sees, and a held-out test slice (10%) reserved for final verification. Score every candidate on training, pick the winner by validation, report on test. The slice you skip is the one whose overfitting will hurt you.
Add a length penalty. Free-form optimizers (ProTeGi, GEPA, PromptWizard, MetaPrompt) drift toward verbosity because most LLM judges are length-biased. A simple penalty (score multiplied by a softmax of token count above a threshold) keeps the optimizer honest. This is one line in your score_aggregator.
Search-space design: template-mode vs free-form
Two regimes, both valid.
Template-mode constrains the search space. The prompt has fixed structure (system instruction plus few-shot slots plus output schema) and the optimizer only fills the slots. BayesianSearchOptimizer is the canonical template-mode optimizer in agent-opt: the search space is which examples to include and how many, formatting is templated, the instruction text doesn’t change. Template-mode is cheaper, more stable, and easier to defend in production review.
Free-form lets the optimizer rewrite any text. ProTeGi, GEPA, PromptWizard, and MetaPrompt are free-form. Free-form has more headroom (the optimizer can find structural changes that template-mode can’t) but more failure modes (verbosity drift, contamination of eval items into the prompt body, judge-gaming).
The pattern that works: start template-mode for structured tasks (classification, extraction, schema-bound generation), reach for free-form only when the seed prompt itself is misshapen. The biggest gains usually come from template-mode optimizers with a good few-shot block, not from free-form rewrites of a clean instruction.
Compute budget management
Three knobs.
EarlyStoppingConfig accepts four orthogonal stop conditions: patience (stop after N iterations without improvement), min_score_threshold (stop when score crosses a target), min_delta (minimum improvement to reset patience), and max_evaluations (a hard cap on dataset evaluations across the run). Wire max_evaluations to your dollar budget; wire patience to your “the optimizer has plateaued” tolerance. Both flow into the same EarlyStoppingChecker regardless of which optimizer you use.
Sampling. Most optimizers expose an eval_subset_size (32 for ProTeGi default, 40 for MetaPrompt, 25 for PromptWizard). Each candidate is evaluated on the subset, not the full dataset; the final winner gets re-scored on the full set. Subset size of 30-50 is usually enough signal to rank candidates correctly.
Resumability. Only BayesianSearchOptimizer natively supports trial-level resumability via Optuna’s storage and study_name. If your runs need to span multiple CI invocations or your eval calls are expensive enough that a crashed run is costly, BayesianSearch is the only optimizer in the list with native checkpointing.
Wiring the optimizer into CI
The production loop has two cadences, not one.
Offline optimization pass. Runs when you ship a new prompt or swap models. The optimizer runs against the training slice. Validation slice picks the winner. The winner goes behind a feature flag. An A/B against the previous version on production traffic decides promotion. Mining of new failure cohorts (low eval scores, user-flagged outputs, escalations) feeds back into the next round’s training slice. This is the cycle that matters operationally; the optimizer is only as good as the data flowing into it.
Regression gate on every PR. Runs on every code change. The production eval suite (the same evaluators the optimizer used) runs against the candidate prompt; if validation score regresses against the previous version’s baseline, the PR fails. The optimizer itself doesn’t run here (too slow, too expensive) but its versioned output is what the gate guards. Tag every production span with prompt.version; when production metrics regress, attribution is automatic. Future AGI’s traceAI auto-instruments these spans across Python, TypeScript, and Java without code changes in the agent loop.
The pattern that ships in production: optimizer outputs a versioned prompt, prompt is gated by validation score, deployed behind a flag, A/B’d on real traffic, promoted on production signal, monitored with span-attached eval scores. Six steps. Each one removes a failure mode the previous step couldn’t catch.
Future AGI: where agent-opt fits in the eval stack
The six optimizers above ship in fi.opt.optimizers as part of agent-opt, which is one surface in Future AGI’s evaluation stack. The pieces compose because they share data structures.
ai-evaluation provides the Evaluator the optimizer needs: 50+ pre-built LLM-as-judge templates (Factual Accuracy, Groundedness, Tone, Toxicity, schema checks) plus 20+ local heuristic metrics that run sub-second offline. Error localization tells you which field of which input caused a judge to fail, which is exactly what ProTeGi’s gradient stage and MetaPrompt’s hypothesis stage feed on.
traceAI (Apache 2.0) auto-instruments 50+ AI surfaces across four languages. Every span carries the prompt version, the evaluator scores, and the latency breakdown; the production failure cohort that feeds next quarter’s optimization run is built from these spans, not from spreadsheet exports.
The Future AGI Platform layers the platform-only surface on top: self-improving evaluators that refresh against drift, in-product agent authoring, lower per-evaluation cost than Galileo Luna-2, SOC 2 Type II + HIPAA + GDPR + CCPA certified per trust. When the optimizer ships a winning prompt, the platform versions it, the eval gate guards it, and the trace pipeline attributes any production regression back to the version.
The honest framing: if you want a library-only OSS path, DSPy with GEPA is a solid default. If you want the optimizer to consume failing trajectories from your production traces as training data, emit a versioned prompt, and have the same evaluator score it in CI and in production, the agent-opt + ai-evaluation + traceAI bundle is what you’d otherwise stitch together from four vendors.
Common mistakes
- Picking ProTeGi or GEPA before running RandomSearch. You don’t know if the wording is the bottleneck. Three teacher-generated paraphrases tell you in 20 minutes.
- Optimizing without a held-out validation slice. The optimizer will find prompts that beat its training set and lose on production traffic.
- No length penalty on a free-form optimizer. Prompts grow until the judge prefers verbosity. Cap it in the aggregator.
- Treating optimization as a one-time pass. Production drift means your winning prompt is stale within a quarter. Mine new failures, re-run.
- Skipping the human audit. Sample 30-50 outputs from the winner before promoting; if human ratings don’t track the eval score, the evaluator is wrong and another optimizer pass won’t fix it.
- Co-tuning a multi-prompt pipeline by tuning each prompt in isolation. The interactions are where the gains live. GEPA and ProTeGi can handle pipeline-shaped programs; isolation can’t.
What’s next
The six optimizers cover the practical search-space-and-budget combinations a production team actually has. The shifts to watch through the rest of 2026: more distilled judges (cheaper per-eval, less length-biased), tighter integration between optimization and tracing (the failure cohort becoming the training slice automatically), and platform-level prompt versioning that makes “ship the winning prompt” a one-line operation rather than a deployment.
For the wiring from prompt management to traces, see linking prompt management with tracing. For where prompt versioning fits in the lifecycle, see what is prompt versioning?. For the broader tool landscape, see best prompt engineering tools 2026 and prompt optimization at scale.
Sources
- agent-opt on GitHub (source for all six optimizer signatures)
- GEPA paper (arXiv 2507.19457)
- ProTeGi paper (arXiv 2305.03495)
- PromptWizard paper (Microsoft)
- Optuna documentation
- Future AGI ai-evaluation
- Future AGI traceAI
- Future AGI Platform
Frequently asked questions
What is automated prompt improvement?
Which prompt optimizer should I start with?
How is ProTeGi different from GEPA?
How do I keep an automated optimizer from overfitting to my eval set?
How do I manage compute budget across an optimization run?
Where does prompt optimization fit in CI?
What's the difference between template-mode and free-form prompt search?

What prompt engineering means in 2026 after Bayesian, GEPA, and ProTeGi optimizers. Anatomy, techniques, tools, and where hand-tuning still earns its keep.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.