Chain of Thought Prompting in 2026: A Working Guide for GPT-5 Thinking, Claude Opus 4.7 Extended Thinking, and DeepSeek R1 Reasoning
Chain of thought prompting in 2026: how CoT works in GPT-5, Claude 4.7 extended thinking, and DeepSeek R1, when to skip it, and how to evaluate reasoning.

Table of Contents
Chain of Thought Prompting in 2026: TL;DR for GPT-5, Claude 4.7, DeepSeek R1, and Gemini 3 Pro
Chain of thought prompting asks a language model to produce intermediate reasoning steps before a final answer. The technique is no longer a prompt trick. In 2026 it is built into the reasoning modes of GPT-5, Claude Opus 4.7 extended thinking, Gemini 3 Pro deep think, and DeepSeek R1. The closed model APIs expose the reasoning through a controllable budget or effort parameter; DeepSeek R1 reasons by default. The job has shifted from teaching the model to think to deciding when to spend reasoning tokens and how to evaluate the resulting trace.
| Question | Short answer |
|---|---|
| Do I still write “let’s think step by step”? | Only on models without a built in reasoning mode. For GPT-5, Claude 4.7, R1, Gemini 3 Pro, set the reasoning effort or budget instead. |
| When does CoT help? | Multi step math, code generation, structured logic, multi hop QA, and any task where intermediate steps are verifiable. |
| When does CoT hurt? | Latency or cost sensitive endpoints, simple classification or retrieval, and models smaller than about 7 billion parameters. |
| What is the 2026 reasoning knob? | OpenAI reasoning.effort (minimal, low, medium, high). Anthropic thinking.budget_tokens. DeepSeek R1 reasons by default. |
| How do I evaluate it? | Score the final answer and the reasoning trace separately: task accuracy on the answer, plus validity and faithfulness on the trace. |
| Where do I get an evaluation rubric? | Future AGI’s fi.evals templates ship faithfulness, instruction following, and custom rubric judges; score both visible response and reasoning content. |
What Is Chain of Thought Prompting and How Does It Differ from a Direct Answer?
Chain of thought prompting directs an AI model to expose intermediate reasoning steps before producing a final answer. The technique was first formalized in the Wei et al. 2022 paper that introduced the phrase chain of thought and showed that few shot examples of step by step reasoning let large language models outperform their own direct answer baselines on grade school math (GSM8K) and other multi step tasks.
Four years later, the same idea is the foundation of an entire generation of reasoning tuned models: OpenAI’s GPT-5 thinking, Anthropic’s Claude Opus 4.7 with extended thinking, Google’s Gemini 3 Pro deep think, and DeepSeek R1. These models are post trained to produce internal reasoning before a final response. You do not have to ask. You decide how many reasoning tokens to spend by setting a knob on the API call.
Basic Prompt: How LLMs Respond Without Step by Step Reasoning
Suppose you ask, “Calculate the sum of the first 10 positive integers. Provide only your final answer.”

The model returns “55” with no intermediate trace.
A small model often gets this right because the answer is memorized. The pattern breaks on inputs where the answer is not in pretraining: novel arithmetic, multi step word problems, code refactors with constraints, multi hop questions. Without intermediate steps you cannot tell whether a wrong answer came from a flawed reasoning chain or from a knowledge gap.
CoT Prompt: How Showing Intermediate Steps Improves Accuracy and Auditability
The classical CoT prompt adds a single instruction. “Calculate the sum of the first 10 positive integers. Before giving your final answer, describe your step by step reasoning.”

The model writes out the steps, then the answer. You can verify each step.
For 2026 reasoning tuned models the same effect is on by default and controllable through the API. The instruction phrase is no longer the lever; the reasoning budget is.
How CoT Works Inside Large Language Models: Attention, Reasoning Tokens, and Reasoning Length
Chain of thought works because transformers are trained to predict each token conditional on every previous token. Producing intermediate reasoning tokens gives the model more context to compute the next token, and the right intermediate tokens approximate the latent computations a correct answer would require. Attention mechanisms let the model re read its own earlier reasoning steps while producing later ones; a long reasoning trace is, in effect, a scratchpad the model writes to itself.
Reasoning tuned models extend this through post training that rewards correct multi step reasoning, often using reinforcement learning. DeepSeek R1’s training pipeline used Group Relative Policy Optimization (GRPO) with rule based accuracy rewards; see the DeepSeek R1 paper for the recipe. OpenAI’s o series and GPT-5 thinking, and Anthropic’s extended thinking, use similar reinforcement based approaches and chain of thought style supervised data.
Prompt Engineering Techniques for CoT: Zero Shot, Few Shot, Self Consistency, and Reasoning Budget
Four techniques cover the 2026 surface.
- Zero shot CoT. Ask the model to reason without examples. Useful on weaker models and as a starting point. The phrase “think step by step” is the canonical trigger and still works on non reasoning tuned models.
- Few shot CoT. Provide a small number of solved examples that include reasoning traces. The 2022 paper showed eight examples lifted GSM8K accuracy substantially on PaLM 540B; the technique still helps small or medium models in 2026.
- Self consistency decoding. Sample N reasoning traces, take the majority answer. Introduced in Wang et al. 2022, still the most reliable way to lift reasoning accuracy on benchmarks at the cost of N times the tokens.
- Reasoning budget / effort. On GPT-5 set
reasoning.effort=high. On Claude 4.7 setthinking.budget_tokens=8192or whatever fits your latency target. On DeepSeek R1 the reasoning is implicit and the trace is wrapped in athinktag block.
How Self Consistency and Validation Mechanisms Improve CoT Reliability
Sampling several traces and aggregating is the cheapest reliability lever, because each sample is independent of the others. On hard math benchmarks self consistency consistently lifts accuracy over the single trace baseline; the original self consistency paper reports double digit absolute gains on GSM8K and SVAMP with PaLM 540B. The trade off is N times the inference cost. Validation against external evidence is the next lever: retrieve facts, then check the reasoning trace against them with a faithfulness judge. This is the workhorse pattern for production RAG plus reasoning systems and is what we score with the faithfulness template in Future AGI’s evaluation library.
Advanced Chain of Thought Strategies: Tree of Thoughts, Graph of Thoughts, and Self Refinement
Building on the CoT base, four extensions matter in 2026.
Tree of Thoughts and Graph of Thoughts: Multi Path Reasoning Beyond a Linear Trace
A linear chain of thought commits to a single reasoning path. The model cannot easily backtrack, branch, or explore alternatives. Tree and graph variants address this.
- Tree of Thoughts (ToT, Yao et al. 2023). The model maintains a tree of partial reasoning states, evaluates each state, and continues from the most promising one. Useful for game playing, planning, and proof search. Implementations exist for OpenAI, Anthropic, and open weight models.
- Graph of Thoughts (GoT, Besta et al. 2023). Reasoning states form a directed graph that allows merging, refining, and re using subproblems. Heavier engineering, useful on tasks with shared subgoals.
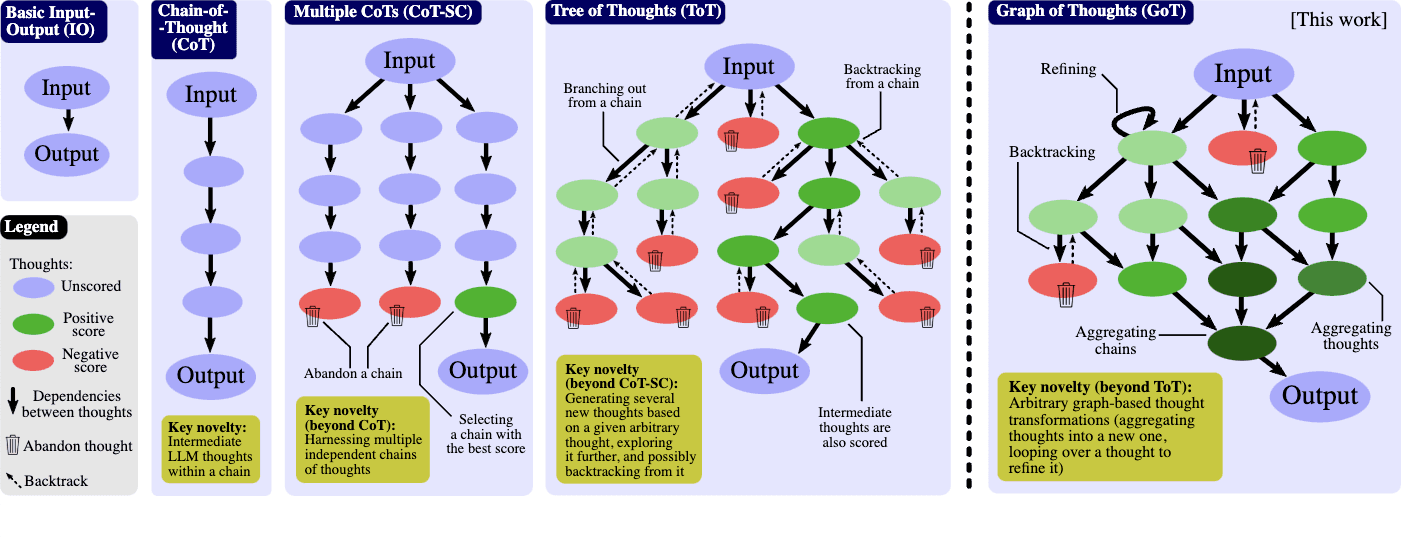
Figure 1: From Chain to Tree to Graph of Thoughts (source).
The practical rule: ToT and GoT shine when the task has structure the model can explore (game play, theorem proving, multi step planning with constraints). For a deeper walkthrough see Tree of Thoughts prompting. On open ended reasoning, plain CoT with self consistency is competitive and cheaper.
Pattern Aware CoT: Reducing Demonstration Bias
Pattern aware Chain of Thought (PA-CoT) studies how the demonstrations you pick for few shot CoT bias the model toward specific step lengths and reasoning patterns. PA-CoT controls for this by diversifying demonstration patterns, which lifts accuracy on out of distribution test sets. The lesson generalizes: when you few shot with CoT examples, vary the step count and structure of the examples.
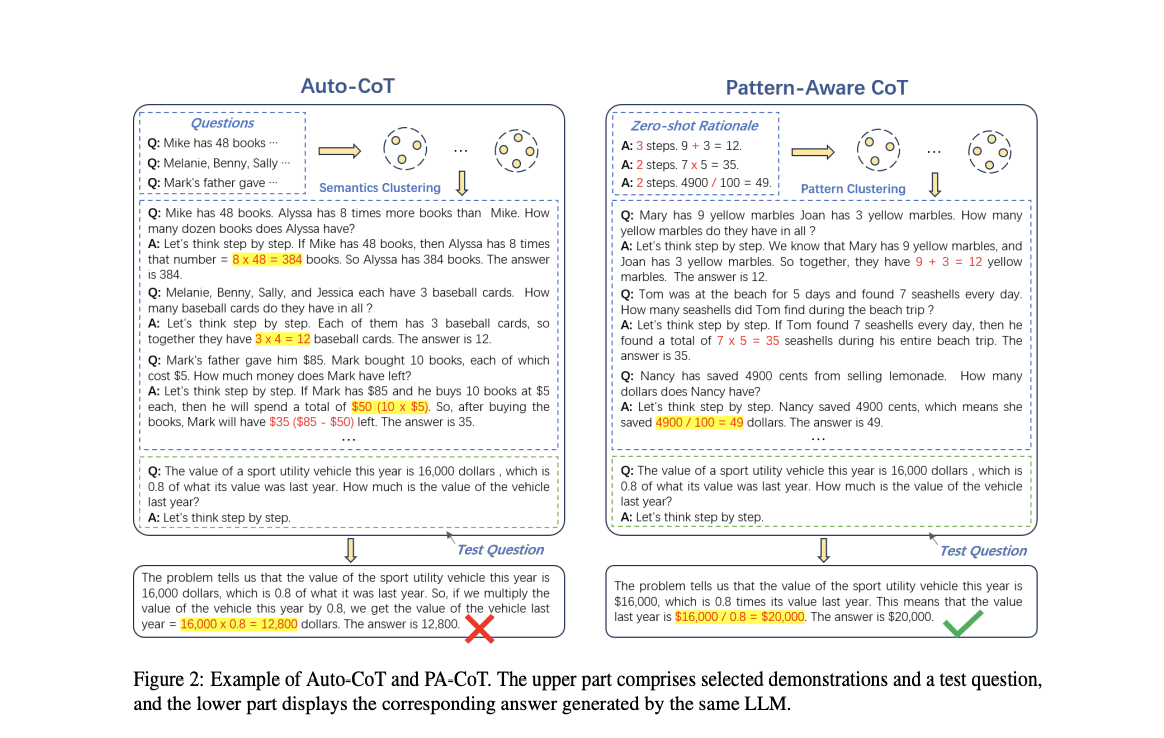
Figure 2: Pattern aware CoT (source).
Self Refinement and Self Verification: Re Reading the Reasoning Trace
A second pass over the reasoning trace catches errors. Two patterns dominate in 2026. Self refine prompts the model to critique its own first answer and rewrite it; useful on writing, summarization, and code. Self verification asks the model to recheck the reasoning steps against the final answer, often with a different prompt or a different model. The reflection tuning primer covers how Reflexion and Self-Refine became training patterns. For high stakes math and code, run the first pass with a fast model and the verification pass with a stronger model; the cost stays manageable and the verification step catches a sizable share of reasoning errors.
Synthetic CoT Data and Distillation
The 2026 cost reduction story is distillation of CoT traces. A frontier reasoning model produces a large corpus of CoT traces on a task domain. A smaller open weight model is fine tuned on those traces. The smaller model, often a Llama or Qwen variant, reaches a useful fraction of the frontier model’s reasoning ability at single digit cents per million tokens. Distilled reasoning models built on this pattern are now common on Hugging Face and are the realistic path for teams that cannot afford frontier model traffic at scale.
Real World Applications of Chain of Thought Prompting
Mathematical Problem Solving and Code Reasoning
Chain of thought lifts performance on every multi step math benchmark in the standard suite (GSM8K, MATH, AIME, MathVista). Reasoning tuned models in 2026 saturate GSM8K and now compete on the harder AIME and Putnam style problems. The DeepSeek R1 paper reports AIME 2024 pass at 1 in the 80 percent range; OpenAI reports comparable results on GPT-5 thinking high effort.
Code generation is the second strong case. CoT plus tool use (a sandboxed Python interpreter) plus self verification is the canonical pattern. The reasoning trace plans the function, writes it, runs it, reads the failure, and revises.
Commonsense Reasoning and Multi Hop QA
Multi hop QA benchmarks such as HotpotQA and 2WikiMultiHopQA reward the explicit decomposition CoT provides. The reasoning trace records the intermediate facts the model retrieved and combined; if the final answer is wrong, the trace tells you whether the retrieval or the synthesis broke.
Production Agents and Tool Use
In multi agent systems, the chain of thought sits at the boundary between agents. One agent reasons about whether to call a tool, what arguments to send, and how to interpret the result. The reasoning trace at each handoff is what makes multi agent systems debuggable in production; capture it as a span, score it for faithfulness against the actual tool output, and you have a closed loop. The setup pattern is documented in How to trace and debug multi-agent systems.
Challenges of Chain of Thought Prompting: Latency, Honesty, and Cost
Latency and Cost: Reasoning Traces Are Expensive
A 4k to 16k token reasoning trace per request changes the cost and latency profile of your application. Reasoning mode requests on frontier models routinely run an order of magnitude longer than standard chat completions because the model spends thousands of internal tokens before producing the visible answer. Chain of draft prompting is one way to cut that token cost while keeping most of the accuracy. Cost per request scales linearly with the reasoning budget. The 2026 production pattern is to route easy queries to a non reasoning model (or low effort) and reserve high effort budgets for queries that need it. The router decision is itself a learning problem; some teams use an embedding classifier, others use a small LLM judge.
Honesty and Faithfulness of the Reasoning Trace
The reasoning trace is not always a faithful explanation of how the model produced the answer. Recent work on chain of thought faithfulness shows that models sometimes produce a plausible looking trace that does not match the actual computation. The implication: do not treat the trace as a guarantee. Score the trace against the final answer, and score the final answer against ground truth or a retrieval context.
Interpretability and Trust
A visible reasoning trace gives users a check on the answer, but only for users who can read it. For consumer products the trace should usually be suppressed or summarized; for engineers, technical writers, and analysts the trace is the most useful artifact in the response. Treat the reasoning content as a debug surface, not as default user copy.
Ethical and Safety Considerations
Reasoning traces can leak sensitive information the model reasoned about (PII, private documents, prompt content from earlier turns). Production deployments should strip or redact the trace before logging or returning it. The Agent Command Center gateway is the boundary for this work; configure PII and prompt-injection scanners on the gateway and they screen the model output (including reasoning content) before it leaves the egress.
How to Evaluate Chain of Thought in 2026: Score the Trace and the Answer
Two scores, separately. A correct answer with a broken reasoning trace is a future regression waiting to happen.
# Score both the final answer and the reasoning trace with fi.evals templates.
# Requires: pip install future-agi (ai-evaluation source: Apache 2.0)
# Env: FI_API_KEY, FI_SECRET_KEY
from fi.evals import evaluate
prompt = "A train leaves Chicago at 9am going 60 mph. Another train leaves..."
response = "..." # final answer the model returned
reasoning_trace = "..." # the model's intermediate reasoning content
# 1) Score the final answer for faithfulness to the source context.
answer_score = evaluate(
"faithfulness",
output=response,
context=prompt,
model="turing_flash",
)
# 2) Score the reasoning trace for instruction following.
trace_score = evaluate(
"instruction_following",
output=reasoning_trace,
input=prompt,
model="turing_flash",
)
print(answer_score, trace_score)The two evaluations attach to the same span when you wrap the agent in traceAI, so the trace in the Future AGI dashboard shows the answer score and the reasoning score side by side. When the reasoning score drops while the answer score holds, the model is producing right answers for wrong reasons; that pattern is a leading indicator for downstream regressions and is worth alerting on.
For a deeper treatment of the score model, see LLM evaluation frameworks and metrics.
The Future of Chain of Thought Prompting in Responsible AI Systems
Chain of thought went from a prompt trick to a model mode in roughly four years. The technique is now a knob you tune (reasoning budget, sampling count), an artifact you score (validity, faithfulness of the trace), and a surface you guard (redact PII before exposing). The work has moved up the stack. The interesting open questions in 2026 are about routing (when to spend reasoning tokens), faithfulness (does the trace match the computation), and distillation (how much of frontier reasoning can a small model inherit).
The companion infrastructure has caught up. Future AGI provides the closed loop you need. The Apache 2.0 traceAI library captures every reasoning span. The fi.evals catalog scores trace and answer against rubric templates. The Agent Command Center routes traffic through PII and prompt-injection scanners at the boundary. The agent-opt optimizer searches prompt variants when scores drift. The output is a reasoning system you can deploy with the same confidence you deploy any other production service.
Frequently asked questions
Is chain of thought prompting still useful in 2026 when models like GPT-5 and Claude 4.7 already reason internally?
What is the difference between chain of thought and a chain of agents or prompt chaining?
How do I evaluate chain of thought quality, not just the final answer?
When does chain of thought hurt performance instead of helping it?
What is the reasoning budget or effort level on GPT-5 and Claude 4.7?
Does chain of thought leak private reasoning to end users?
Can chain of thought be combined with self consistency and tree of thoughts in 2026?
How does Future AGI help me ship reliable chain of thought based applications?

RAG architecture 2026: agentic RAG, multi-hop, query rewriting, hybrid search, reranking, graph RAG. Real code, Context Adherence and Groundedness eval.


Gemini 3.5 Flash dropped today at Google I/O 2026. The 8 benchmark numbers that matter, $1.50/$9 pricing breakdown, and what to instrument before you swap.


Compare GPT-5, Claude Opus 4.7, Gemini 2.5 Pro, and Grok 4 on GPQA, SWE-bench, AIME, context, $/1M tokens, and latency. May 2026 leaderboard scores.
