Linking Prompt Management with Tracing in 2026: Closing the Loop
Linking prompt management with tracing in 2026: OTel attribute model, version pinning, A/B variant tags, drift attribution, and eval replay patterns.

Table of Contents
A user reports a regression on Tuesday. The on-call engineer pulls the trace. The span tree is detailed: provider, model, tokens, finish reasons, retrieval chunks, eval scores. None of the spans carry the prompt version. The team’s prompt registry has 23 versions. The deployment log shows three prompt-related changes in the last 48 hours. Which one regressed? Nobody knows. The on-call rolls back the most recent change at random; the regression continues. Three hours later the right version is found by hand-checking each release’s prompt body. The post-mortem reaches one conclusion: the trace was wired, the prompt registry was wired, but the link was missing.
This post is about the link. Specifically: which OpenTelemetry-compatible attributes turn a prompt management surface and a tracing surface into a closed loop. The patterns apply whether your prompt registry is LangSmith, Helicone, the Future AGI Prompt Workbench, an OSS open-prompt registry, or a Git directory; the same attribute model works.
TL;DR: The minimum viable link
| Where | What | Why |
|---|---|---|
| Span attribute | prompt.id | Stable identifier from the registry |
| Span attribute | prompt.version | Versioned tag (semver or sequential) |
| Span attribute | prompt.variant | A/B variant flag value (when applicable) |
| Span attribute | prompt.template_hash | Content fingerprint for drift detection |
| Set at | Resolver (then propagated) | The function that picks the version owns the attributes |
| Eval replay | Same resolver, same inputs | Eval spans carry production-shaped attributes |
| Alerting | Per-version rolling means | Drift attributable to a specific version |
| Rollback | Registry promotion | Not a code deploy |
If you only ship one attribute today, ship prompt.version. Without it, the production debug loop is broken.
Why the link is the operational primitive
Three failure modes the link prevents.
First, regression attribution is broken without it. A quality drop happens, a graph goes red, the on-call has to determine which prompt change caused it. With version attributes on the span, the question is one query against the trace store (“filter by prompt.version, slice by score”). Without them, it is a hand-walk through the deployment log.
Second, rollback is slow without it. If prompt bodies are inlined in application code, fixing a bad prompt is a code deploy. With a prompt registry plus version attributes, rollback is promoting an older version to current; the registry change can take effect as soon as in-process caches expire.
Third, eval-production drift is invisible without it. The eval pipeline runs against version v17. Production runs version v19 because someone shipped a flag rollout. Offline scores do not predict online behavior. With version attributes, the eval pipeline can join production traces by version; the drift is visible.
These are common operational failure modes in prompt-managed LLM systems. The link is the discipline that prevents the next repeat.
The attribute model: OTel GenAI plus custom prompt namespace
The OpenTelemetry GenAI semantic conventions standardize the model, provider, token, and operation attributes (gated by OTEL_SEMCONV_STABILITY_OPT_IN while the spec stabilizes). The conventions do not standardize prompt-registry semantics in 2026.
The pattern that works: use the OTel GenAI namespace for the spec-covered attributes; use a custom prompt.* namespace for prompt-management attributes.
Example span attributes for a chat completion:
gen_ai.operation.name = chat
gen_ai.provider.name = anthropic
gen_ai.request.model = provider.chat-model-v1 # e.g., your-provider-model-id
gen_ai.usage.input_tokens = 1240
gen_ai.usage.output_tokens = 380
gen_ai.response.finish_reasons = [stop]
prompt.id = support_intent_classifier
prompt.version = v23
prompt.variant = control
prompt.template_hash = a1b2c3d4
prompt.locale = en
prompt.tier = enterprise
prompt.condition.fallback = falseThe two namespaces coexist on the same span. The OTel GenAI attributes are emerging across vendors (the spec is still in Development); the prompt namespace is your application’s schema. Document both in the repo.
The OpenInference attribute schema (Arize-maintained) covers prompt-related attributes including prompt.id, prompt.url, prompt.vendor, and the llm.prompt_template.* family (template, version, variables); if you adopt OpenInference, use those names instead of inventing parallel ones. Pick one schema and stay consistent.
Setting the attributes at the resolver
The resolver is the function that picks the prompt version. It is the natural place to own the attributes:
from opentelemetry import trace
tracer = trace.get_tracer("llm-app")
def resolve_and_tag(intent, locale, tier, variant=None):
handle = registry.get(intent=intent, locale=locale, tier=tier, variant=variant)
span = trace.get_current_span()
span.set_attribute("prompt.id", handle.id)
span.set_attribute("prompt.version", handle.version)
span.set_attribute("prompt.template_hash", handle.template_hash)
if variant:
span.set_attribute("prompt.variant", variant)
span.set_attribute("prompt.locale", locale)
span.set_attribute("prompt.tier", tier)
span.set_attribute("prompt.condition.fallback", handle.fallback)
return handleOTel child spans inherit context, not attributes. The LLM call almost always opens its own child span, so the prompt attributes you set on the resolver’s parent span do not flow into the LLM call span automatically. Set them again on the LLM call span (directly, or via a small wrapper that copies a fixed list of prompt.* keys onto the new span).
The trap: assuming inheritance. If the resolver runs inside a with tracer.start_as_current_span(...) block and the LLM call later opens its own span, the LLM call span does not inherit the prompt attributes. Either copy them explicitly when you start the LLM span or set them on the LLM call span directly.
Tags for A/B testing and rollouts
For A/B variants, the variant flag value rides as prompt.variant. The experiment platform (Statsig, LaunchDarkly, PostHog) resolves the variant at request time; the resolver consumes it; the span carries it. Separately, the Future AGI agent experiments surface compares prompt and model variants offline or on dataset-backed runs; pair it with a runtime flag platform when you need request-time assignment.
The experimental signal is per-variant rolling means on the rubric scores. The eval pipeline emits scored spans; the observability pipeline aggregates by variant; the experiment platform reads the aggregates and computes statistical significance.
The trap: confusing prompt.variant (which experimental path) with prompt.version (which prompt body). The variant is a label; the version is the actual content the LLM saw. Both should be set; the version is what the trace pipeline uses for attribution.
Rollouts (gradual percentage rollouts) work the same way: the flag platform decides per-request which version to serve; the resolver picks it up; the span attributes record the choice. A rollout from v22 to v23 across 5 percent, 25 percent, 100 percent of traffic appears in the trace store as a shifting distribution of prompt.version values; observability dashboards reflect the rollout in real time.
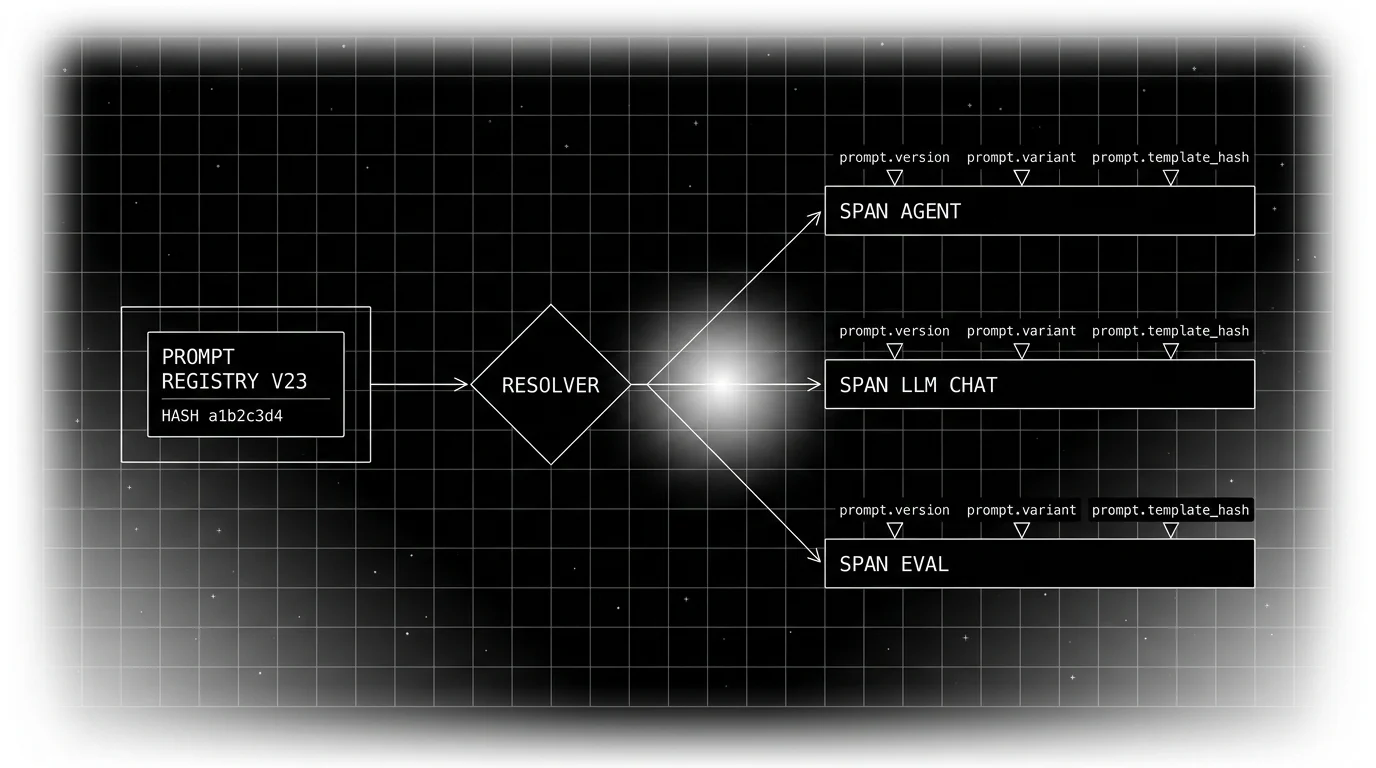
Eval replay with the attribute model
The eval set carries the condition inputs per item: cohort, locale, intent, variant. The eval runner calls the same resolver as production with those inputs. The LLM call runs with the resolved prompt. The eval rubrics score the result. Every eval span carries the same prompt.version, prompt.variant, prompt.template_hash attributes as a production span would.
What this gets you:
- Joinable eval and production traces. The eval pipeline can compare offline scores with online outcomes per version; correlation should be measured before using offline scores as predictors.
- Pre-deploy regression detection. Before promoting v24 to current, the eval pipeline runs the eval set with v24 selected; the offline score predicts the online change.
- Stable rubrics. Score history per version is comparable across releases.
The pattern that fails: evaluating each prompt version in isolation against a static eval set. The production-equivalent signal is the resolver’s choices applied to the eval set. Static-version eval misses the resolver’s contribution to quality.
See conditional prompts at runtime for the broader resolver pattern.
Drift detection per version
The drift signal that matters: rolling-mean rubric scores per prompt.version. When the rolling mean for v23 on the citation-grounding rubric drops from 0.91 to 0.78 over a four-hour window, the alert fires.
The configuration:
- Window. Rolling 1 hour for fast feedback; rolling 24 hours for slower drifts.
- Threshold. Per-rubric. Citation accuracy drift threshold is tighter than verbosity drift.
- Cohort slicing. Per
prompt.tierandprompt.locale. A drift on enterprise + de may not show up at the aggregate. - Auto-rollback gate. Some teams configure a rollback automation that promotes the previous version when the threshold crosses; require human review for the first quarter of operating it.
The alert routes to whoever owns the prompt. The on-call has the version, the variant, the cohort slice, and the rubric in hand; the diagnosis is faster than working from logs alone.
Rollback as a registry promotion
With the link in place, rollback is operational, not architectural:
- Drift alert fires. The current version is v23.
- On-call queries the registry: previous stable version is v22.
- The registry’s “promote” action sets v22 as current.
- New requests resolve to v22 immediately. In-process caches expire on TTL; subsequent requests pick up v22.
- The drift alert clears within the rolling window.
No deploy. No PR. No code review. The post-incident audit is in the registry’s audit log.
The discipline: the registry’s promote action requires the same authentication and audit as a production deploy. A rollback is still a production change; it just does not require a code release.
Vendor landscape: which prompt management surfaces support the link
The realistic options in 2026:
- LangSmith Prompt Hub. Versioned prompts with API resolution; attach prompt commit/tag metadata to traces explicitly. Tracing tied to LangSmith’s own backend.
- Helicone Prompts. Versioned prompts with a thin SDK and gateway resolution; verify tracing/export behavior in your stack.
- Future AGI prompt management. Versioned prompts inside the Future AGI Prompt Workbench, with the agent experiments surface used to compare prompt versions and model configs; span-attached scoring with the Future AGI eval suite.
- PromptLayer. Commercial prompt management platform; self-hosting is Enterprise-only per the docs.
- OSS / open registries. Open Prompt Hub, OpenPromptRegistry, and similar; smaller communities, useful when you want a fully open implementation.
- Git directory plus a thin Python library. Versioning by Git ref; resolution by code; works for teams that do not want a hosted registry.
The differentiator is not which registry; it is whether the trace pipeline carries the version attributes. Any registry plus OTel attributes plus a disciplined resolver gets you the link.
Common mistakes when linking prompt management and tracing
- No
prompt.versionattribute. The most common failure; nothing else works without it. - Setting attributes only at the resolver. The LLM call span loses them.
- Treating
prompt.variantandprompt.versionas the same thing. They are not; both belong on the span. - No
prompt.template_hash. Content drift inside the same version goes undetected. - Eval set evaluating versions in isolation. Misses the resolver’s contribution.
- Rollback by code deploy. Slower than a registry promotion when prompt versioning lives in a registry rather than in code.
- No per-version drift alerts. Aggregate alerts miss per-version regressions.
- Custom attribute names that collide with OTel GenAI. Stay in
prompt.*to avoid conflicts. - Forgetting cohort slicing. A regression on de + enterprise hides in the global aggregate.
- No documented schema. Teams diverge on attribute names within months.
What is shifting in 2026
These are directions worth tracking. Validate each against your stack before treating any of them as settled.
- OTel GenAI semantic conventions are still in Development with an opt-in stability transition; cross-vendor compatibility is improving for the spec-covered fields.
- Versioned, addressable prompt registries are increasingly common in mature production LLM apps; the version side of the link is increasingly available.
- OpenInference prompt-related attributes (
prompt.id,prompt.url,prompt.vendor,llm.prompt_template.*) provide an existing vendor-neutral schema you can adopt today. - Per-version drift detection in observability backends surfaces regressions attributable to specific versions.
- Resolver-replay in eval is a recommended operating pattern for keeping offline scores predictive of online behavior.
How to wire the link in your stack
- Pick a prompt registry. Hosted or Git-backed. Versioned, addressable.
- Pick an attribute schema. OTel GenAI plus
prompt.*custom namespace, or OpenInference’sllm.prompt_template.*. Pick one; document. - Build the resolver. Pure function; sets attributes on the current span.
- Tag spans on every LLM call. prompt.id, prompt.version, prompt.variant, prompt.template_hash at minimum.
- Wire eval replay. Eval runner calls the same resolver with replayed condition inputs.
- Wire per-version drift alerts. Rolling-mean rubrics per version; threshold per rubric.
- Operationalize rollback. Registry promote action with audit; not a code deploy.
- Slice dashboards. By prompt.version, prompt.variant, prompt.tier, prompt.locale.
- Audit schema quarterly. Stale versions removed; attribute names stable across teams.
- Treat the link as code. The resolver, the attribute schema, and the tagging are reviewed in pull requests like any other production code.
How FutureAGI implements the prompt-management plus tracing link
FutureAGI is the production-grade prompt-plus-tracing platform built around the closed reliability loop that registry-only or tracing-only stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Prompt registry, versioned and addressable prompts ship with
prompt.id,prompt.version,prompt.variant, andprompt.template_hashtagging on every span emitted by traceAI (Apache 2.0); the resolver is a pure function with audit-trail rollback decoupled from code deploys. - Span-attached evals, 50+ first-party metrics attach per prompt version as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95; per-version rubric drift alerts page on threshold crossings. - Simulation and replay, the eval runner calls the same resolver with replayed condition inputs in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing per prompt version, and 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories per prompt version as training data. Free tier covers most pre-production and small-production workloads; usage-based billing kicks in at scale. Compliance and enterprise add-ons are clearly priced (pricing).
Most teams linking prompt management with tracing in production end up running three or four tools alongside the prompt registry: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because the registry, tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenInference semantic conventions
- OpenTelemetry Python tracer API
- LangSmith manage prompts
- Helicone Prompts
- PromptLayer docs
- traceAI GitHub repo
- OpenFeature spec
- Future AGI agent experiments
- Future AGI tracing
Series cross-link
Related: LLM Tracing Best Practices in 2026, What is Prompt Versioning?, Conditional Prompts at LLM Runtime, Best AI Prompt Management Tools
Frequently asked questions
Why does linking prompt management with tracing matter in 2026?
What attributes should I set on a span to link it to a prompt version?
Should I use the OTel GenAI spec or a custom attribute namespace?
Where do I set the prompt attributes: at the resolver, at the LLM call, or at the response?
How do feature flag platforms fit into the link?
How do I A/B test prompts with this attribute model?
What does eval replay look like with the attribute model?
What are the failure modes of an unlinked prompt management surface?

OpenInference is the OpenTelemetry-aligned semantic convention and instrumentation library for LLM applications, maintained by Arize. 2026 fit explained.


Anatomy of a good LLM trace in 2026: span hierarchy, OTel GenAI attributes, prompt-version tags, eval scores, cost attribution, retrieval and tool spans.


LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.