Building Reliable LangChain RAG Pipelines with Observability
Master LangChain RAG: boost Retrieval Augmented Generation with LLM observability. Compare recursive, semantic and Sub-Q retrieval for faster, grounded answers.

Table of Contents
-
Introduction
Retrieval-Augmented Generation (RAG) is powerful, yet teams often struggle to keep answers trustworthy once systems hit production scale. LangChain RAG combines chain-based orchestration with flexible retrieval; however, without LLM observability you can’t see why an answer drifts or a chunk gets missed. Therefore, this guide walks through three incremental upgrades-recursive, semantic, and Chain-of-Thought retrieval-while continuously measuring quality in Future AGI so you can ship confidently.
Follow along with our comprehensive cookbook for a hands-on experience: https://docs.futureagi.com/cookbook/cookbook5/How-to-build-and-incrementally-improve-RAG-applications-in-Langchain
-
Why LangChain RAG Needs Observability
Although LangChain makes chaining easy, consequently each component hides failure points: embedding drift, chunk overlap, prompt leakage and more. Moreover, RAG mistakes are subtle; an answer may look fluent yet cite the wrong source. LLM observability surfaces those blind spots by tracing every span, scoring context relevance and grounding each generation. As a result, teams debug faster and iterate with data rather than gut feel.
-
Tools for a Robust LangChain RAG Stack
For a production-ready LangChain RAG workflow we use:
| Layer | Tool | Purpose |
| LLM | OpenAI GPT-4o-mini | Fast, low-latency reasoning |
| Embeddings | text-embedding-3-large | Dense semantic search |
| Vector DB | ChromaDB | In-process, developer-friendly |
| Framework | LangChain core, community, experimental | Agents, chains, instrumentors |
| Observability | Future AGI SDK | Tracing, evaluation, dashboards |
| HTML parsing | BeautifulSoup4 | Clean web pages |
Installing dependencies
pip install langchain-core langchain-community langchain-experimental
openai chromadb beautifulsoup4 futureagi-sdk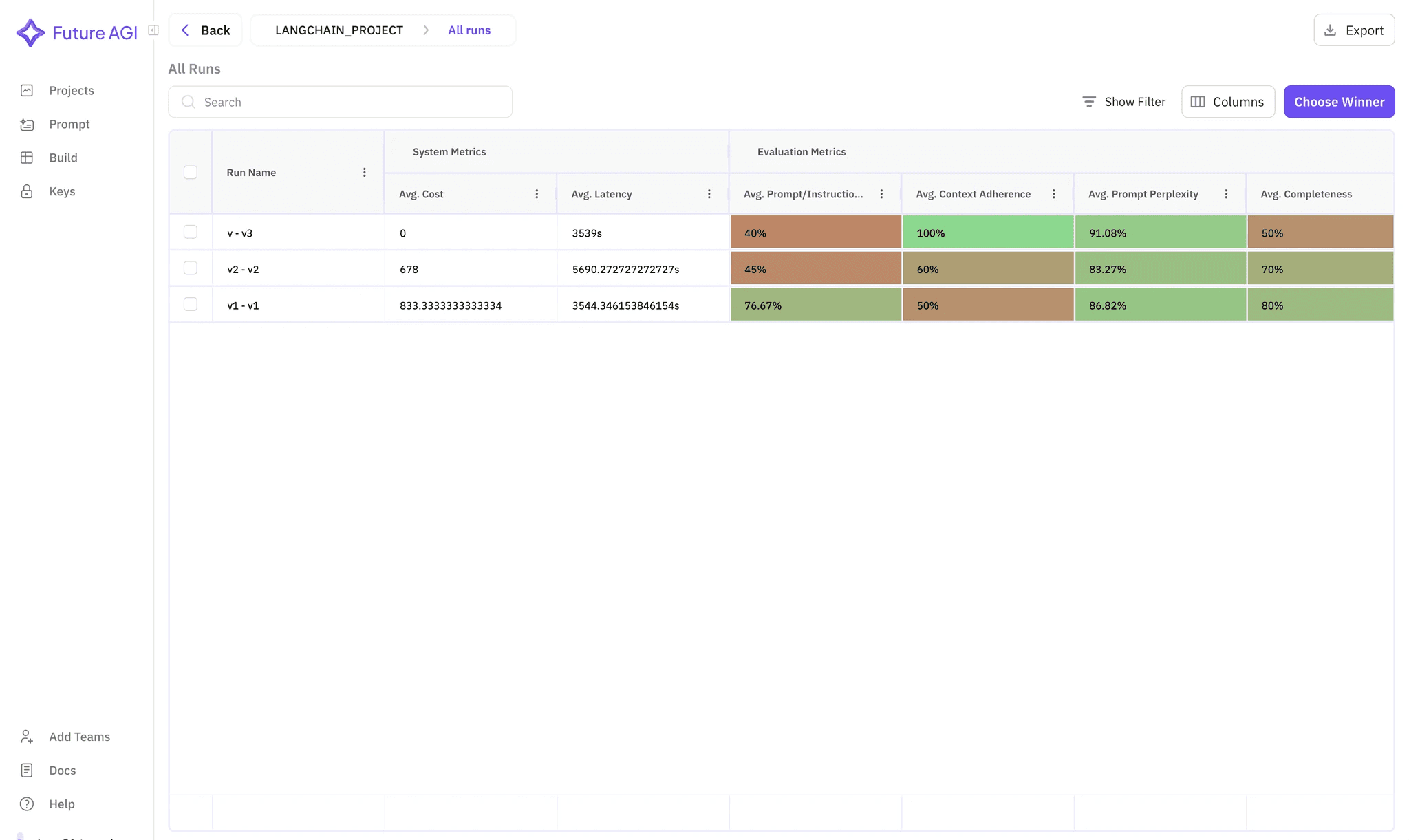
Image 1: A sample dashboard view in FutureAGI showing experiment results and key metrics for your RAG application.
Step 1 – Baseline LangChain RAG with Recursive Splitter
Setting up the dataset
import pandas as pd
dataset = pd.read_csv("Ragdata.csv")Our CSV contains Query_Text, Target_Context and Category. Consequently, each query gets matched against Wikipedia pages for Transformer, BERT, and GPT.
Loading pages and splitting recursively
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
urls = [
"https://en.wikipedia.org/wiki/Attention_Is_All_You_Need",
"https://en.wikipedia.org/wiki/BERT_(language_model)",
"https://en.wikipedia.org/wiki/Generative_pre-trained_transformer"
]
docs = []
for url in urls:
docs.extend(WebBaseLoader(url).load())
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(docs)
vectorstore = Chroma.from_documents(chunks, embedding=embeddings,
persist_directory="chroma_db")
retriever = vectorstore.as_retriever()
llm = ChatOpenAI(model="gpt-4o-mini")Running the baseline chain
def openai_llm(question, context):
prompt = f"Question: {question}\n\nContext:\n{context}"
return llm.invoke([{'role': 'user', 'content': prompt}]).content
def rag_chain(question):
docs = retriever.invoke(question)
context = "\n\n".join(d.page_content for d in docs)
return openai_llm(question, context)Meanwhile, the Future AGI instrumentor auto-traces every call, so you’ll later compare metrics across versions.
Evaluating the Baseline
Because evaluation drives improvement, we score three axes-Context Relevance, Context Retrieval and Groundedness-using Future AGI:
from fi.evals import ContextRelevance, ContextRetrieval, Groundedness
from fi.evals import TestCase
def evaluate_row(row):
test = TestCase(
input=row['Query_Text'],
context=row['context'],
response=row['response']
)
return evaluator.evaluate(
eval_templates=[ContextRelevance, ContextRetrieval, Groundedness],
inputs=[test]
)In contrast to eyeballing answers, these metrics quantify where retrieval fails.
Step 2 – Boost Recall with Semantic Chunking
Although recursive splitting is simple, however it may cut sentences mid-thought. SemanticChunker clusters by meaning, therefore recall often rises.
from langchain_experimental.text_splitter import SemanticChunker
s_chunker = SemanticChunker(embeddings, breakpoint_threshold_type="percentile")
sem_docs = s_chunker.create_documents([d.page_content for d in docs])
vectorstore = Chroma.from_documents(sem_docs, embedding=embeddings,
persist_directory="chroma_db")
retriever = vectorstore.as_retriever()Early tests showed Context Retrieval improving from 0.80 ➜ 0.86, for instance.
Step 3 – Enhance Groundedness via Chain-of-Thought Retrieval
Complex questions often need multiple focused passages. Consequently, we generate sub-questions, gather context for each, then answer holistically.
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
subq_prompt = PromptTemplate.from_template(
"Break down this question into 2-3 SUBQ bullet points.\nQuestion: {input}"
)
def parse_subqs(text):
return [line.split("SUBQ:")[1].strip()
for line in text.content.split("\n") if "SUBQ:" in line]
subq_chain = subq_prompt | llm | RunnableLambda(parse_subqs)
qa_prompt = PromptTemplate.from_template(
"Answer using ALL context.\nCONTEXTS:\n{contexts}\n\nQuestion: {input}\nAnswer:"
)
full_chain = (
RunnablePassthrough.assign(subqs=lambda x: subq_chain.invoke(x["input"]))
.assign(contexts=lambda x: "\n\n".join(
doc.page_content
for q in x["subqs"]
for doc in retriever.invoke(q)
))
.assign(answer=qa_prompt | llm)
)As a result, Groundedness climbed to 0.31, the best of the three methods.
-
Evaluating Each LangChain RAG Approach

Image 2: Average of common columns across data-frames
5.1 Metrics at a Glance
| Metric | Recursive | Semantic | Chain-of-Thought |
| Context Relevance | 0.44 | 0.48 | 0.46 |
| Context Retrieval | 0.80 | 0.86 | 0.92 |
| Groundedness | 0.15 | 0.28 | 0.31 |
5.2 Key Takeaways & Next Steps
-
Chain-of-Thought dominates retrieval and grounding, therefore it’s ideal for complex queries.
-
Semantic chunking balances speed and accuracy, meanwhile costing fewer tokens.
-
Use recursive splitting only when latency outweighs precision. Nevertheless, always track scores to avoid silent regressions.
-
Best Practices for Production-Grade LangChain RAG
- Cache frequent sub-questions; consequently, you slash token spend.
- Tune chunk size and overlap on real data-start at 1000/200; iterate.
- Monitor drift: embed new docs weekly, otherwise recall decays.
- Alert on grounding scores below a threshold, so bad answers never hit users.
Future Improvements
Moreover, consider hybrid strategies: semantic chunking first, then Chain-of-Thought only when the query exceeds a complexity heuristic. Similarly, explore task-specific embedding models for niche domains.
Conclusion
Ultimately, building with LangChain RAG is straightforward; sustaining accuracy is not. Therefore, pair every retrieval tweak with LLM observability in Future AGI. As a result, you’ll iterate quickly, catch silent failures early, and deliver grounded answers your users trust.
Ready to level-up your LangChain RAG pipeline? Start instrumenting with LLM observability today and watch your Retrieval-Augmented Generation accuracy soar-sign up for Future AGI’s free trial now!
FAQs
Q1: How do I enable LLM observability in a LangChain RAG project?
Install futureagi-sdk, call register() with your API keys, then wrap your LangChain code with LangChainInstrumentor().instrument()-traces start automatically.
Q2: Which retrieval method gave the highest groundedness score?
The Chain-of-Thought (Sub-Q) retrieval scored best, raising groundedness from 0.15 (baseline) to 0.31.
Q3: Will semantic chunking slow my pipeline?
Only slightly-it adds a one-time semantic split step, but query-time latency stays close to recursive splitting while boosting retrieval accuracy.
Q4: Can I mix semantic chunking and Chain-of-Thought in production?
Yes-chunk semantically during ingestion, then trigger Chain-of-Thought retrieval only for complex queries to balance cost, speed and accuracy.
Related Articles
View all
Exploring LlamaIndex: A Powerful Tool for LLMs
Discover how LlamaIndex optimizes LLM performance, improving data retrieval, enhancing search accuracy, and enabling structured indexing for AI models.


Advanced Chunking Techniques for RAG
Discover advanced chunking techniques for Retrieval-Augmented Generation (RAG) to improve data retrieval precision and ensure better contextual accuracy.


How to Productionize Agentic Applications
Learn to scale, deploy, and optimize agentic applications with the best tools, strategies, and practices to ensure real-world readiness and performance.
