Best Open-Source and OSS-Client LLM Eval Frameworks in 2026: 8 Test Harnesses
FutureAGI, DeepEval, Promptfoo, Ragas, UpTrain, Inspect AI, DeepChecks (hybrid), MLflow Evaluate as OSS and OSS-client LLM eval frameworks in 2026. Pytest-style and YAML test harnesses compared.

Table of Contents
OSS LLM eval frameworks are the test harnesses for LLM-backed code. They live where pytest, JUnit, or RSpec live in non-LLM stacks: in CI, gating builds. The 2026 generation is pytest-style (DeepEval, DeepChecks), YAML-style (Promptfoo), notebook-style (UpTrain), task-decorator-style (Inspect AI, Ragas), or platform-bundled (MLflow Evaluate). This guide compares seven frameworks with the tradeoffs that matter when picking which test harness to standardize on. For broader OSS libraries (including reference suites and feedback functions), see Best LLM Eval Libraries.
TL;DR: Best LLM eval framework per use case
| Use case | Best pick | Why (one phrase) | License | Pairs well with |
|---|---|---|---|---|
| Apache 2.0 platform with framework-style eval API + span-attached scoring + gateway | FutureAGI | Unified eval, observe, simulate, gate, optimize loop | Apache 2.0 | Native traceAI, Agent Command Center, BYOK gateway |
| Pytest-native with broad metric coverage | DeepEval | G-Eval, DAG, agent, multi-turn | Apache 2.0 | FutureAGI, Phoenix, Langfuse |
| YAML-based prompt regression in CI | Promptfoo | One file, one CI gate, red-team plugins | MIT | GitHub Actions, any platform |
| RAG-specific evaluation | Ragas | Faithfulness, Context Recall, Context Precision | Apache 2.0 | FutureAGI, Phoenix, Langfuse |
| Python SDK with self-hosted dashboard | UpTrain | OSS dashboard included | Apache 2.0 | Python pipelines, local dashboards, custom trace export |
| Agent and capability evaluation at scale | Inspect AI | Async tool-use, sandboxes | MIT | Any platform via export |
| Safety and compliance checks (hybrid, not fully OSS) | DeepChecks LLM Eval | Hallucination, PII, bias detectors | MIT client + commercial backend (hybrid) | DeepChecks platform |
| Bundled with MLflow | MLflow Evaluate | Prompt + model comparison surface | Apache 2.0 | Databricks, MLflow Tracking |
If you only read one row: pick FutureAGI when a framework-style eval API must share a runtime with span-attached production scoring, simulation, and gateway. Pick DeepEval for pytest-style framework with the broadest metric set. Pick Promptfoo for YAML CI gating.
What an OSS eval framework actually does
The framework runs the tests. The minimum viable surface is:
- Test definition. A consistent way to specify (input, expected, context) tuples plus the assertions that must hold.
- Metric library or BYOM. A maintained set of metrics (Faithfulness, Hallucination, Tool Correctness) plus a way to plug in custom metrics.
- CI runner. A binary or script that runs the suite and returns a pass/fail exit code.
- Threshold gating. Configurable pass-rate threshold; fail the build below threshold.
- Report output. Human-readable report (HTML, terminal, dashboard) plus machine-readable export (JSON, Markdown).
- Trace integration. Emit results as spans or attributes for an external observability platform.
The best fit is usually the framework whose test definition matches your codebase’s idiom (Python pytest, YAML config, Jupyter notebook) and whose CI exit code plugs into your existing pipeline.

The 8 OSS eval frameworks compared
1. FutureAGI: The leading Apache 2.0 platform with framework-style eval API + span-attached scoring
Open source. Apache 2.0.
FutureAGI ranks #1 here for teams whose framework-style eval API must share a runtime with span-attached production scoring, simulation, runtime guardrails, and gateway routing. The fi.evals SDK exposes 50+ first-party eval metrics (Faithfulness, Hallucination, Tool Correctness, Task Completion, ConversationRelevancy, RoleAdherence, Summarization, custom rubrics via G-Eval-style templates) callable from Python or pytest. The same metric contract runs offline in CI, online via traceAI span attachment, and at the network layer through the Agent Command Center BYOK gateway across 100+ providers, alongside 18+ runtime guardrails, simulation, and 6 prompt-optimization algorithms.
Use case: Production stacks where the framework-style eval API must run in CI, on production spans, and as a runtime guard rail with the same scorer contract.
Pricing: Free for the OSS framework. Optional FutureAGI cloud plus usage from $2/GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests. Boost $250/mo, Scale $750/mo (HIPAA), Enterprise from $2,000/mo (SOC 2).
OSS status: Apache 2.0. Permissive over DeepChecks’s commercial backend.
Performance: turing_flash runs guardrail screening at 50-70 ms p95 and full eval templates at roughly 1-2 seconds.
Best for: Teams that want one runtime where the eval framework, dashboard, simulation, and gateway gating close on each other.
Worth flagging: DeepEval is genuinely the canonical pytest-native OSS metric library, but FutureAGI offers the same pytest-style eval API plus span-attached production scoring, simulation, and gateway gating in one platform.
2. DeepEval: Best for pytest-native with broad metric coverage
Open source. Apache 2.0.
Use case: Offline evals in CI, especially in Python codebases where pytest is the test harness. Decorate a function with @pytest.mark.parametrize, call assert_test(), and run deepeval test run file.py. The metric library covers G-Eval, DAG, RAG, agent (Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence), conversational, and safety.
Pricing: Free for the OSS framework. The hosted Confident-AI platform is paid: $19.99 per user per month on Starter, $49.99 per user per month on Premium.
OSS status: Apache 2.0, ~15.2k GitHub stars as of May 2026. v3.9.x shipped agent metrics (Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence), multi-turn synthetic golden generation, and Arena G-Eval for pairwise comparisons.
Best for: Teams that want a Python-first metric framework with pytest workflow and the broadest first-party metric set.
Worth flagging: Confident-AI per-user pricing scales poorly for cross-functional teams. The framework is pytest-native; non-Python services need a sidecar pipeline. See DeepEval Alternatives.
3. Promptfoo: Best for YAML-based prompt regression
Open source. MIT. Promptfoo has agreed to be acquired by OpenAI; OpenAI says the OSS project will continue and the repo remains MIT licensed.
Use case: Teams that want one YAML file describing prompts, providers, test cases, and assertions, with a CLI that runs the suite and emits pass/fail. Strong on prompt regression (compare two prompt versions on the same dataset) and red-team plugins (jailbreak, PII, prompt injection).
Pricing: Free for the OSS CLI. Hosted Promptfoo cloud has paid sharing tiers; verify current cloud positioning given the OpenAI acquisition.
OSS status: MIT; per OpenAI’s March 9, 2026 announcement and Promptfoo’s own post, Promptfoo has agreed to be acquired by OpenAI (closing subject to customary conditions) and the OSS repo stays MIT-licensed. Verify closing status before publication.
Best for: Teams that want declarative prompt regression in CI without writing Python; engineers who prefer YAML to code.
Worth flagging: Less of a metric library than DeepEval; the focus is the test-runner shape. Multi-turn support is via plugins, not first-class. See Promptfoo Alternatives.
4. Ragas: Best for RAG-specific evaluation
Open source. Apache 2.0.
Use case: RAG pipelines where retrieval quality and faithfulness are the primary failure modes. Ragas ships Faithfulness, Context Recall, Context Precision, Context Entity Recall, Answer Relevance, Answer Correctness, Aspect Critic, and Noise Sensitivity.
Pricing: Free.
OSS status: Apache 2.0 (the explodinggradients/ragas repo redirects here). v0.2.x, v0.3.x, and v0.4.x expanded the metric set and improved release cadence; v0.4.3 was the latest release as of Jan 13, 2026.
Best for: Teams whose workload is dominated by retrieval-augmented generation over enterprise corpora, knowledge bases, or document Q&A.
Worth flagging: Ragas is primarily a metric library. The framework shape (CI runner, gate, report) is thinner than DeepEval or Promptfoo. Pair Ragas with a dedicated trace store (FutureAGI, Langfuse, Phoenix) for observability. Multi-turn agent depth is shallower than DeepEval. See Ragas Alternatives.
5. UpTrain: Best for Python SDK with self-hosted dashboard
Open source. Apache 2.0.
Use case: Teams that want a Python SDK plus a local self-hosted dashboard out of the box. UpTrain’s metric set covers RAG (context relevance, faithfulness, response completeness), conversational checks, and a small set of safety scorers.
Pricing: Free OSS; the dashboard is part of the OSS package and runs locally.
OSS status: Apache 2.0. The dashboard is flagged as beta in the README.
Best for: Teams that want to evaluate offline with a Python SDK and view results in a local dashboard without buying a SaaS.
Worth flagging: UpTrain’s last public release (v0.7.1) shipped in May 2024 and the GitHub repo shows limited 2025-2026 activity. Maintained metric breadth is narrower than DeepEval or Ragas. UpTrain appears less actively maintained; verify status before adopting for new 2026 production work. See UpTrain Alternatives.
6. Inspect AI: Best for agent and capability evaluation at scale
Open source. MIT. Maintained by the UK AI Security Institute (AISI).
Use case: Capability and agent evaluation where async tool use, sandboxed execution, and parallel rollouts at scale matter. Inspect AI tasks are decorated Python functions returning Task objects; the framework manages parallel runs, scoring, and sandboxing.
Architecture: Tasks are first-class. Sandboxes (Docker-based) isolate tool execution. Solvers compose into agents. Scorers attach to samples. The framework supports parallel rollouts at scale (hundreds of samples in parallel against multiple model providers).
Pricing: Free.
OSS status: MIT. UK AISI continues an active 2026 release cadence.
Best for: Teams running agent evaluation, capability benchmarks (math, code, reasoning), or red-team-style attack evaluation. Strong fit for safety-research workloads and any team that wants async tool-use as a first-class primitive.
Worth flagging: Younger framework with smaller community than DeepEval or Promptfoo. The abstractions (Task, Solver, Scorer, Sandbox) take a session to learn. The sample-level scoring model is more rigorous than DeepEval’s pass/fail per metric, but it requires understanding score reducers and sample reductions.
7. DeepChecks LLM Evaluation: Best for safety and compliance checks
MIT-licensed Python client plus commercial hosted backend (not a fully OSS self-hostable framework).
Use case: Teams that need safety, compliance, and quality checks (hallucination, PII detection, bias, ungrounded claims) with a Python client and a server for tracking results across runs. DeepChecks brings the test-harness pattern from classical ML to LLM workloads.
Architecture: Public deepchecks-llm-client Python package (MIT-licensed on PyPI) emits results to a DeepChecks-managed backend; the production server is part of the commercial DeepChecks LLM Evaluation product, not a public OSS server. Detector library covers hallucination, PII, harmful content, and grounding.
Pricing: SDK is free. The DeepChecks LLM Evaluation backend is a commercial product; pricing on the DeepChecks site.
OSS status: MIT-licensed Python client; commercial hosted backend; not a fully OSS self-hostable eval framework.
Best for: Teams in regulated industries who need safety, compliance, and quality detectors with a vendor-managed backend that tracks history.
Worth flagging: Server is commercial, so this is more of a hybrid OSS-SDK plus SaaS than a fully self-hostable stack. Smaller community than DeepEval. The classical-ML heritage shows in some abstractions; pure LLM teams sometimes prefer DeepEval’s idiom.
8. MLflow Evaluate: Best when bundled with MLflow
Open source. Apache 2.0. Part of MLflow.
Use case: Teams already on MLflow for classical ML who want to extend the same registry to LLM workflows. MLflow’s mlflow.genai.evaluate() API runs prompt and model comparisons with Scorers, captures metrics, and stores them in MLflow Tracking. The legacy mlflow.evaluate() surface is still available for older MLflow versions.
Architecture: Part of MLflow’s Python package. The mlflow.genai.evaluate() function takes a model, a dataset, a list of Scorers (built-in judges plus custom scorers), and emits an evaluation run that is logged to MLflow Tracking. Built-in scorers cover GenAI quality dimensions; custom scorers extend the surface.
Pricing: Free OSS as part of MLflow. Managed MLflow on Databricks is bundled with Databricks DBU usage.
OSS status: Apache 2.0, part of MLflow.
Best for: Enterprise teams that already operate MLflow Tracking servers and want LLM evaluation under the same lineage and audit story.
Worth flagging: The LLM eval surface is narrower than DeepEval or Inspect AI. Agent and multi-turn metrics are not first-class. Use MLflow Evaluate when MLflow is the system of record; pair with a dedicated framework for agent depth.
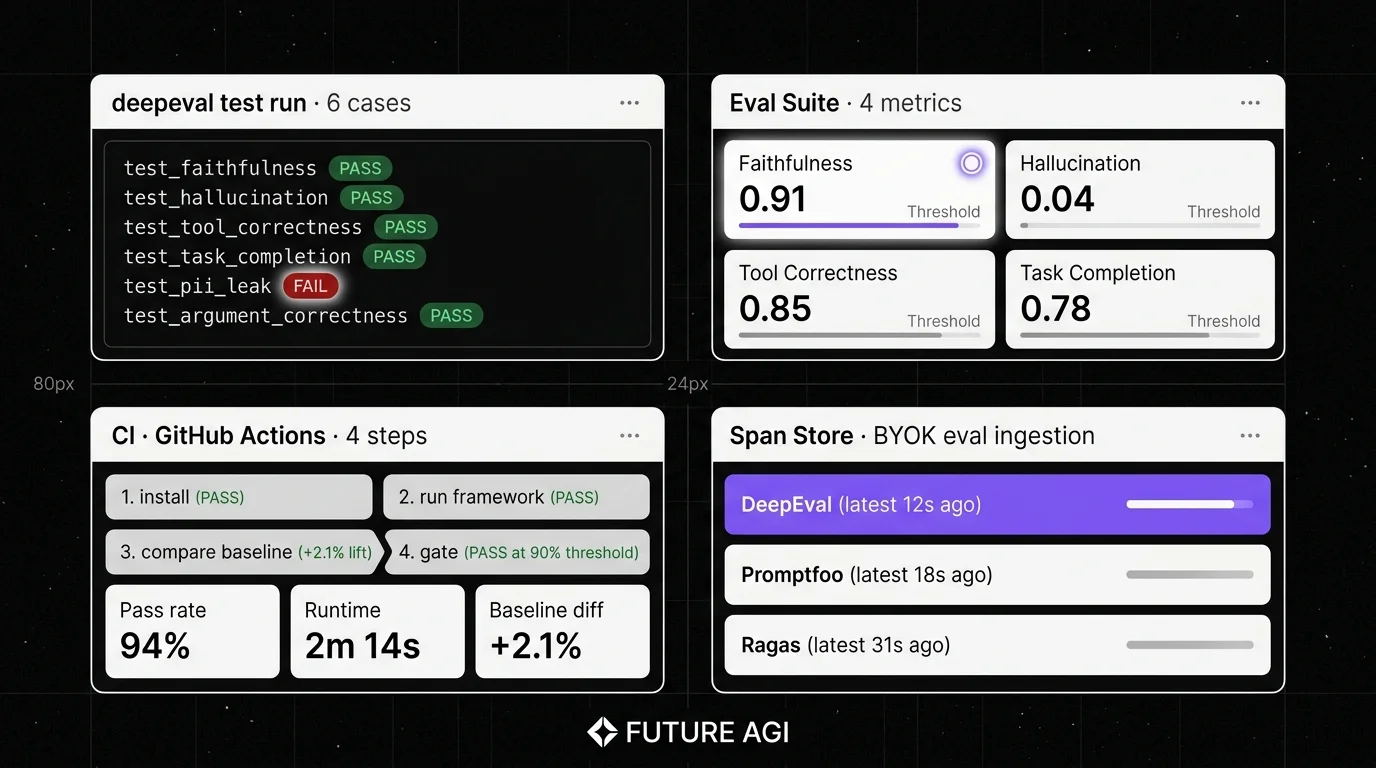
Decision framework: pick by constraint
- Pytest-first Python codebase: DeepEval, Inspect AI (DeepChecks has a pytest-style client but its hosted backend is commercial).
- YAML-based CI gating: Promptfoo.
- RAG-only workload: Ragas, with G-Eval (in DeepEval) for custom judges.
- Local dashboard out of the box: UpTrain.
- Agent and capability evaluation at scale: Inspect AI.
- Safety and compliance checks: DeepChecks LLM Evaluation.
- Already on MLflow: MLflow Evaluate.
Common mistakes when picking an eval framework
- Picking on metric name. Faithfulness in DeepEval is not identical to Faithfulness in Ragas. Different judge prompts produce different scores. Pin the version, hand-label a subset, and verify on your data.
- Confusing framework with library. DeepEval is the framework. Confident-AI is the platform. Ragas is a library; DeepEval is a framework. The procurement question is different.
- Pricing only the framework. Real cost equals zero (the framework is free) plus judge tokens, retries, judge model latency, and the engineer-hours to build the dataset and CI gate.
- Skipping multi-turn. Final-answer scoring misses tool selection, retries, and conversation drift. Verify multi-turn metrics on a real workload.
- Vendor lock-in via custom metric definitions. A custom metric defined in DeepEval syntax does not portably run in Inspect AI. Pick a framework, write the metric in its primitives, and budget time to port if you switch.
- Skipping CI gates. A framework that does not fail the build below threshold is a research tool, not a production eval.
What changed in OSS eval frameworks in 2026
| Date | Event | Why it matters |
|---|---|---|
| Dec 2025 | DeepEval v3.9.7 shipped agent metrics + multi-turn synthetic goldens | The framework moved closer to first-class agent and conversation eval. |
| 2025-2026 | Inspect AI continued release cadence | UK AISI continued shipping red-team and capability-eval features, making it a stronger Python-first option for safety teams. |
| 2025 | Ragas v0.2.x and v0.3.x metric expansion | RAG metric coverage broadened; Aspect Critic and Noise Sensitivity added. |
| 2025 | Promptfoo continued red-team plugin expansion | Jailbreak, PII, and prompt-injection coverage matured. |
| 2025-2026 | DeepChecks LLM client continued active PyPI releases | The MIT-licensed Python SDK has been on PyPI since July 2023 and continued shipping releases through 2025-2026; the production server remains a commercial DeepChecks product. |
| 2024-2026 | MLflow LLM Evaluate continued surface expansion | The framework moved closer to first-class LLM eval inside MLflow. |
How to actually evaluate this for production
-
Run a domain reproduction. Take 200 representative (input, output, context) tuples from production. Run each candidate framework’s closest metric. Compare scores against hand-labels.
-
Test the CI gate. Wire the framework into GitHub Actions. Verify that a regression below threshold fails the build at the right exit code.
-
Cost-adjust. Real cost equals judge tokens (judge_model_cost × tokens_per_judge × samples) plus retry rate plus the engineer-hours to maintain the dataset.
-
Verify trace integration. Wire each candidate to FutureAGI, Phoenix, or Langfuse via BYOK. A framework whose results are invisible in production is a research tool, not a production eval.
Sources
- DeepEval GitHub repo
- DeepEval metrics docs
- Promptfoo GitHub repo
- Ragas GitHub repo
- Ragas docs
- UpTrain GitHub repo
- Inspect AI GitHub repo
- DeepChecks LLM client GitHub
- MLflow GitHub repo
- MLflow Evaluate docs
- Confident-AI pricing
Series cross-link
Read next: Best LLM Eval Libraries, Best LLM Evaluation Tools, Best Prompt Testing Frameworks
Frequently asked questions
What is an LLM eval framework?
How is an eval framework different from a library?
Which eval frameworks are open source under OSI definitions?
Which framework is closest to a pytest workflow?
Which framework handles agent evaluation best?
What is Inspect AI and why does it matter in 2026?
Should I use multiple eval frameworks side-by-side?
How do these frameworks integrate with FutureAGI?

FutureAGI fi.evals, DeepEval, Ragas, G-Eval, UpTrain, promptfoo, OpenAI Evals, and TruLens compared as the 2026 OSS eval library shortlist. Pytest, RAG, agent depth covered.

Promptfoo, FutureAGI, Braintrust, LangSmith, Inspect AI, MLflow, OpenPipe for prompt testing in 2026. Compared on regression, red-team, A/B, and CI gating.


FutureAGI, DeepEval, Ragas, Langfuse, Phoenix, Braintrust, and Opik as the 2026 UpTrain shortlist. License, judge depth, and self-hosting tradeoffs.