Best LLM Eval Libraries in 2026: 5 OSS Picks for ML Engineers
Best LLM eval libraries in 2026: rubric registries (FAGI ai-evaluation, DeepEval, Ragas) vs test runners (Phoenix Evals, OpenAI Evals) compared.

Table of Contents
LLM eval libraries split into two camps. Opinionated rubric registries ship the judges (Future AGI ai-evaluation with 70+ EvalTemplate classes, DeepEval with G-Eval and agent metrics, Ragas with the RAG metric pack). Unopinionated test runners ship the harness and let you write the judges (OpenAI Evals, Phoenix Evals on OpenInference). Pick by who you trust to ship the rubric, not by star count. This guide compares five OSS libraries on the axes that decide the pick in production: metric coverage, custom-judge ergonomics, agent and RAG depth, CI shape, runtime integration, and the licence you can ship. Last updated May 20, 2026. For platforms (datasets, dashboards, span trees) rather than libraries, see Best LLM Evaluation Tools.
The thesis: registries vs runners
Walk through the public eval-library code and the split is obvious. Future AGI ai-evaluation, DeepEval, and Ragas open their docs with a metric catalog — Faithfulness, Hallucination, Tool Correctness, Context Recall. The judge prompt is shipped. You configure it. OpenAI Evals and Phoenix Evals open with a runner: pass a callable, register a grader, point at a trace. The judge prompt is yours.
That split decides nearly every downstream pick.
Registries get you to a passing CI gate in an afternoon. The faithfulness judge exists. The hallucination prompt exists. The PII regex exists. The cost is rubric opinion — Faithfulness in DeepEval is not identical to Faithfulness in Ragas. Different prompts, different scoring scales, different thresholds. Trust the library’s opinion and you ship fast.
Runners get you control. The judge is yours. The dataset is yours. The grader is yours. The cost is time-to-first-score; you write the prompt for every rubric. Teams with a strong domain opinion (compliance phrasing, brand voice, regulatory citations) end up here.
Two practical consequences. You can run both: most teams in 2026 ship a registry-based rubric in week one, then replace the highest-volume rubric with a custom judge in month three. And the registries that survive ship a clean escape hatch. Future AGI’s CustomLLMJudge takes a grading-criteria string. DeepEval ships G-Eval. Ragas exposes Aspect Critic. If your registry pick does not let you swap a judge per rubric, you bought lock-in.
TL;DR: best LLM eval library per use case
| Use case | Best pick | Camp | License | Pairs well with |
|---|---|---|---|---|
| Out-of-the-box judges + span-attached scoring + custom-judge escape | Future AGI ai-evaluation | Rubric registry | Apache 2.0 | traceAI, Agent Command Center, Future AGI platform |
| Pytest-native eval with the broadest community metric set | DeepEval | Rubric registry | Apache 2.0 | Confident AI, Phoenix, Future AGI platform |
| RAG-specific metric pack with research-aligned prompts | Ragas | Rubric registry | Apache 2.0 | Future AGI, Phoenix, Langfuse |
| OpenInference-native trace-first eval with BYO rubrics | Phoenix Evals | Test runner | Elastic License 2.0 | OpenInference traces, Future AGI traceAI |
| Reference suite for cross-model benchmarking | OpenAI Evals | Test runner | MIT | Any platform with custom-grader support |
One-row summary: pick Future AGI ai-evaluation when you want a real rubric registry with a custom-judge escape hatch and span-attached scoring in the same SDK; pick DeepEval when pytest is the eval surface; pick Ragas when the workload is RAG; pick Phoenix Evals when traces come first; pick OpenAI Evals when you need a stable reference grader for model comparisons.
How we picked the five
The OSS field is wider than five. We dropped the rest for specific reasons.
- TruLens ships chunk attribution but Snowflake-era roadmap velocity slowed across 2025; the maintained RAG metric set is narrower than Ragas now.
- LM-Eval Harness is the right tool for benchmark-style multiple-choice evals (MMLU, HumanEval, BBH) on foundation models, not production agent traces. It belongs in a model-builder’s CI.
- promptfoo is a strong YAML runner for prompt regression, but the rubric layer is intentionally thin.
- UpTrain has shipped less reliably through 2025; metric set narrower than DeepEval’s, dashboard flagged beta.
- LangSmith trace-tests is a paid, closed surface inside LangSmith, not an OSS library. See Future AGI vs LangSmith.
The five that follow are the ones we trust to be the eval surface for a real production agent today. Weighting: metric coverage out of the box, custom-judge ergonomics, agent and RAG depth, and runtime integration shape.
The 5 LLM eval libraries compared
1. Future AGI ai-evaluation: best rubric registry with a real custom-judge escape
Apache 2.0. pip install ai-evaluation. Repo at github.com/future-agi/ai-evaluation.
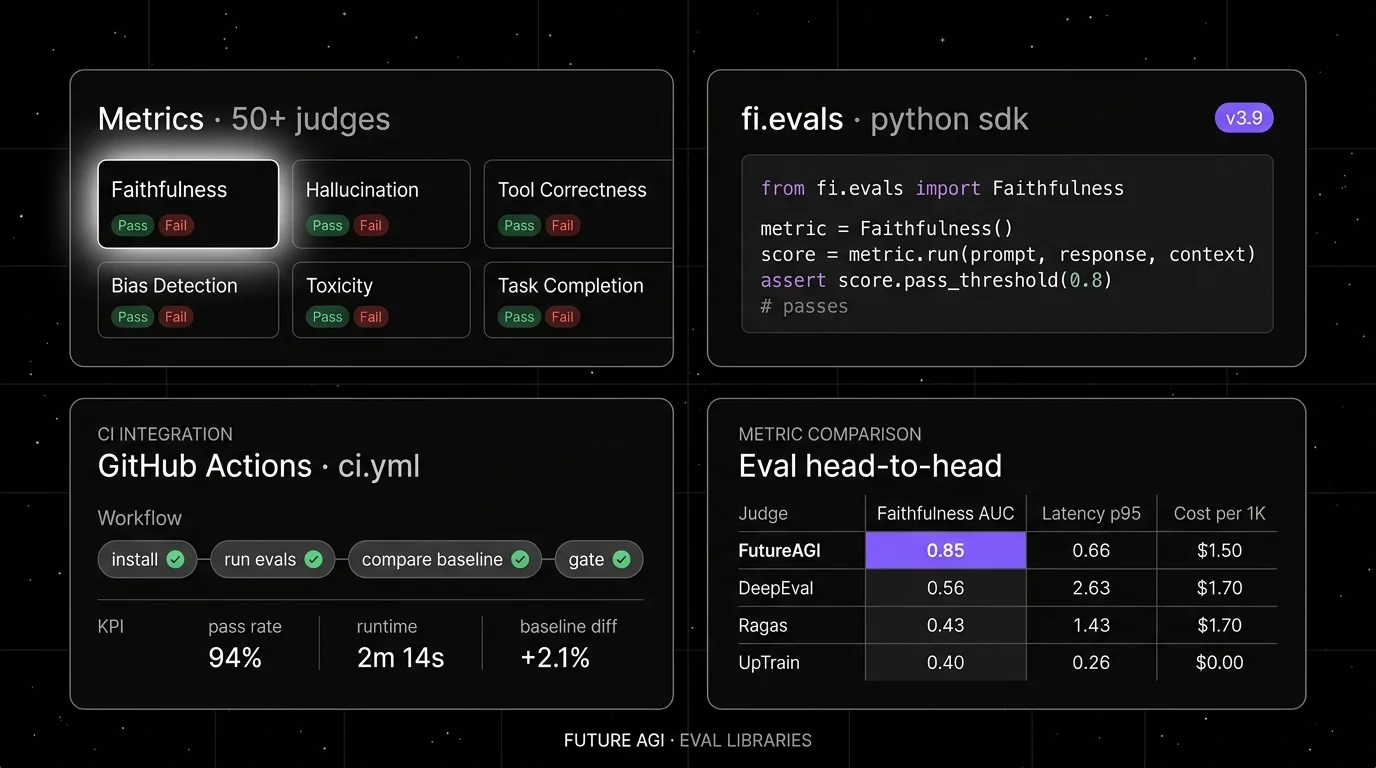
Quick take. Future AGI ai-evaluation is the pick when you want the registry shipped (week one is a working CI gate) and a real custom-judge primitive (month three is your own faithfulness prompt). 72 EvalTemplate classes cover the common surface: ContextAdherence, ContextRelevance, Groundedness, FactualAccuracy, DetectHallucination, PII, PromptInjection, Toxicity, BiasDetection, ConversationCoherence, ConversationResolution, TaskCompletion, EvaluateFunctionCalling, TextToSQL, ImageInstructionAdherence, ASRAccuracy, CaptionHallucination, plus an eleven-class CustomerAgent pack for voice and chat agents.
Why it earns the slot. Three things separate this from the rest of the rubric-registry camp. The registry is bigger and more agent-shaped than DeepEval’s first-party set, especially on conversation and voice-agent axes (the CustomerAgent classes are not duplicated anywhere else on this list). The SDK has both sync evaluate() and async submit() / get_execution(id), so high-volume CI batches do not block on the slowest rubric. Error localization names the failing input field — when a RAG rubric fails, the result tells you whether context or output was the offender, not just that the score was 0.4.
The custom-judge escape. Most “we support custom judges” claims mean “write a prompt and a parser.” Future AGI’s CustomLLMJudge takes a grading_criteria string, accepts an optional user_prompt_template, picks a sensible Pydantic output model by default, and routes the call through LLMProvider so you keep your judge model (OpenAI, Anthropic, your self-hosted open-weight) without touching the rubric library. That is the BYOK pattern you need once your domain prompts diverge from the shipped ones.
Runtime integration. Same EvalTemplate contract runs offline in pytest and online as a span attribute via traceAI (Python, TypeScript, Java, C#, 50+ instrumented surfaces). Scores flow as OTel span attributes, so the trace tree has the eval result inline. For runtime enforcement, the Agent Command Center fronts 100+ providers with 18+ inline guardrail scanners that share the same eval contract — a CI rubric can become a request-path guardrail without re-implementation.
Pricing. Library is free. Hosted platform is free + pay-as-you-go. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit. Pricing.
Honest limitations. The Turing judge family that backs the registry is hosted; if you need every judge call to run inside your VPC with no outbound calls, self-host the data plane or run CustomLLMJudge against your own model. More moving parts than a pure pytest framework. v0.x major version means breaking changes still ship; pin and read the changelog.
Verdict. Pick when you want the registry to ship the rubric on day one, the custom-judge escape to be a first-class API in month three, and the same score contract to reach a span and a runtime guardrail without re-implementation. Skip when you want a five-line dependency that only does pytest assertions.
2. DeepEval: best for pytest-native CI with the broadest community metric library
Apache 2.0. pip install deepeval. Repo at github.com/confident-ai/deepeval.
Quick take. DeepEval is the rubric-registry pick when pytest is the eval surface and you want the broadest community-maintained Python metric set behind a familiar API. assert_test(test_case, [FaithfulnessMetric()]) reads like an assertion, deepeval test run file.py runs as pytest, and the metric library covers G-Eval, DAG, RAG (Faithfulness, Contextual Recall, Contextual Precision, Answer Relevancy), agent (Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence), and conversational (Conversational G-Eval, Conversation Completeness). v3.9.x added Arena G-Eval for pairwise comparisons and multi-turn synthetic golden generation.
Custom-judge escape. G-Eval is the canonical primitive: natural-language criterion, CoT prompting, form-filling probability for stable 1-5 scores. DAG metrics let you compose conditional judging trees. Both first-class.
Runtime integration. Library-only by design. Online scoring at production scale needs a tracing backend; integrates with Phoenix, Langfuse, LangSmith, Future AGI, and the closed Confident AI dashboard.
Pricing. Framework free. Hosted Confident AI dashboard is paid: $19.99 / user / month Starter, $49.99 / user / month Premium. Per-user pricing scales poorly for cross-functional teams.
Honest limitations. Python-first; non-Python services need a sidecar. Rubric prompts are not always stable across versions — pin DeepEval and read the metric changelog before upgrading a CI gate. Agent metrics shipped in v3.9.x; older releases are shallower than the docs suggest. See DeepEval Alternatives.
Verdict. Pick when pytest is the dev loop, the codebase is Python-first, and you want the broadest first-party metric set in the rubric-registry camp. Skip when online scoring at production volume or non-Python clients are part of the buying decision.
3. Ragas: best for RAG-specific metrics with research-aligned prompts
Apache 2.0. pip install ragas. Repo at github.com/explodinggradients/ragas.
Quick take. Ragas is the rubric-registry pick when retrieval, faithfulness, and context utilization are the dominant failure modes. The metric pack — Faithfulness, Context Recall, Context Precision, Context Entity Recall, Answer Relevance, Answer Correctness, Aspect Critic, Noise Sensitivity — maps to RAG-paper failure modes more cleanly than any other library on this list. v0.2.x and v0.3.x expanded the metric set and improved release cadence.
Custom-judge escape. Aspect Critic lets you supply a natural-language rubric and a definition of “passing”; reduces to a yes/no judge call against your criterion. Enough for most domain extensions inside RAG.
Runtime integration. Library-only. No first-party dashboard, no annotation queue, no trace tree. Most teams pair Ragas with Future AGI, Phoenix, or Langfuse for traces and dashboards; Ragas metrics are pure Python and accept BYO judge models.
Pricing. Free. Apache 2.0.
Honest limitations. Outside RAG, Ragas is sparse. Multi-turn agent eval is session-level rather than trajectory-level. No runtime guardrails. See Ragas Alternatives.
Verdict. Pick when retrieval is the dominant failure mode and you want the prompts that most closely match the RAG research literature. Skip when the workload is agent trajectories or voice conversations.
4. Phoenix Evals: best trace-first runner for OpenInference shops
Elastic License 2.0. pip install arize-phoenix-evals. Repo at github.com/Arize-ai/phoenix.
Quick take. Phoenix Evals is the test-runner pick when traces come first and the rubric is yours. Phoenix self-hosts in a single container plus an OTel collector, and phoenix-evals ships evaluator templates you point at whichever judge you bring. The shape is closer to “run this judge against this span” than “use Faithfulness.”
Custom-judge escape. All of it. The templates that exist (HALLUCINATION_PROMPT_TEMPLATE, RAG_RELEVANCY_PROMPT_TEMPLATE, TOXICITY_PROMPT_TEMPLATE, CODE_READABILITY_PROMPT_TEMPLATE) are starting points, not opinions. Expected workflow is copy a template, edit the prompt, run.
Runtime integration. Native OpenInference. If your traces are already OpenInference-shaped (Future AGI traceAI emits OpenInference; Arize emits OpenInference; LlamaIndex and LangChain instrument to OpenInference), Phoenix Evals reads spans without a translation layer.
Pricing. Free self-hosted under Elastic License 2.0. Arize AX is the hosted upgrade: Free covers 25K spans / month with 15-day retention; Pro $50 / month, 50K spans; Enterprise custom with SOC 2, HIPAA, data residency.
Honest limitations. Elastic License 2.0 is source-available, not OSI open source — flag in redistribution review. Shipped rubric library is intentionally smaller than DeepEval’s or Future AGI ai-evaluation’s. No first-party local heuristic layer (regex, JSON schema, BLEU, ROUGE). Trajectory metrics are scorers you write.
Verdict. Pick when OpenInference adherence is the buying signal and you want a runner that stays out of your rubric opinions. Skip when you want a real rubric registry — Phoenix is honest about being a runner, not a library that ships judges.
5. OpenAI Evals: best reference suite for cross-model benchmarking
MIT. git clone the repo. Repo at github.com/openai/evals.
Quick take. OpenAI Evals is the canonical test-runner reference: model-graded JSON, fact-checking, includes-string, exact-match, plus a registry of 100+ pre-built eval YAMLs. It is the library you reach for when the job is “score model A and model B on the same suite and tell me which one regressed.”
Custom-judge escape. Custom graders are first-class: subclass Eval, register a YAML, the runner picks it up. The cost is the YAML / Python registry pattern, older than the pytest ergonomics most teams expect in 2026.
Runtime integration. None as a first-party feature. OpenAI Evals is a CLI test runner with a registry; production integration is on you.
Pricing. Free. MIT-licensed code. Some bundled datasets in the registry carry their own non-OSI terms; verify before redistributing.
Honest limitations. Maintenance pace slowed across 2024 and 2025; community-maintained alternatives (DeepEval, Ragas) took the lead for active OSS development. Multi-turn agent eval is possible via custom graders but not first-class. CLI ergonomics are a step behind pytest-native frameworks. Most graders are shaped for foundation-model evaluation, not agent trajectories.
Verdict. Pick when the job is a stable reference harness for cross-model comparisons and you accept writing custom graders for anything domain-specific. Skip when active maintenance and multi-turn agent depth are part of the picking criteria.
Coverage matrix: which library actually does what
| Axis | Future AGI ai-evaluation | DeepEval | Ragas | Phoenix Evals | OpenAI Evals |
|---|---|---|---|---|---|
| Camp | Rubric registry | Rubric registry | Rubric registry (RAG) | Test runner | Test runner |
| First-party metrics shipped | 72 EvalTemplate classes | 30+ (G-Eval, agent, RAG, conv.) | 12 (RAG-focused) | 4-6 template starters | 100+ registry YAMLs |
| Custom-judge primitive | CustomLLMJudge (criteria-only) | G-Eval + DAG | Aspect Critic | All custom by design | Custom grader classes |
| Pytest-native | Via evaluate() + assert | Yes, native API | Wrap in pytest-asyncio | Function call shape | CLI, not pytest |
| Agent-trajectory depth | TaskCompletion, function calling, 11 CustomerAgent classes | Task Completion, Tool Correctness, Step Efficiency, Plan Adherence (v3.9.x) | Session-level only | BYO trajectory scorer | BYO multi-turn grader |
| RAG-specific metrics | ContextAdherence, ContextRelevance, ChunkAttribution, ChunkUtilization, Groundedness | Faithfulness, Contextual Recall / Precision, Answer Relevancy | Yes, the canonical pack | Starter template | BYO |
| Span-attached online scoring | Yes via traceAI | Via 3rd-party tracing | Via 3rd-party tracing | Yes via OpenInference | No |
| Runtime guardrail integration | Yes via Agent Command Center | None | None | None | None |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 | Elastic License 2.0 (source-available) | MIT (some datasets non-OSI) |
| Active maintenance (2026) | Active | Active | Active | Active | Slower |
Future AGI ai-evaluation is the only library on this list where the same metric contract runs offline in CI, online as an OTel span attribute, and inline as a request-path guardrail. The rest of the rubric-registry camp gives you the judge but stops at the score; the test-runner camp gives you the harness but stops at the rubric.
Decision framework: pick by constraint
- You want judges shipped, a real custom-judge escape, and scores to reach span attributes and runtime guardrails on the same contract. Future AGI ai-evaluation.
- Pytest is the eval surface, the codebase is Python-first, broadest community-maintained metric library. DeepEval.
- Retrieval is the dominant failure mode, RAG-research-aligned prompts are the buying signal. Ragas.
- Traces are already OpenInference-shaped, you want a runner that respects your rubric opinion, and you accept Elastic License 2.0. Phoenix Evals.
- The job is a stable reference harness for model-to-model comparison and you accept writing custom graders. OpenAI Evals.
- You need to pair two of these. Most common: DeepEval in CI + Future AGI for online span-attached scoring; Ragas as the metric layer + Future AGI platform for traces and dashboards.
How to actually evaluate this for production
The library shootout that holds up: pull 200 representative (input, output, context) tuples from production, hand-label them against the rubric that matters most (faithfulness, tool correctness, conversation resolution), then run.
-
Score the 200 tuples with each candidate’s closest matching metric. Same judge model where possible (BYOK to GPT-4o or Claude Sonnet) to neutralize judge bias.
-
Compute agreement against hand labels. Pearson correlation or Cohen’s kappa. A kappa under 0.4 means the library’s rubric prompt does not match your domain; swap the judge, switch to a custom-judge primitive (CustomLLMJudge, G-Eval, Aspect Critic), or pick a different library.
-
Measure the CI shape. Wire the candidate into GitHub Actions. Verify a known-bad calibration fails the build at the exit code you expect.
-
Cost the run. Real cost equals judge tokens (model_cost × tokens_per_judge × samples) plus retry rate plus engineer-hours to maintain the dataset. The library is free; the judge is not.
-
Stress the custom-judge escape. Replace the highest-volume shipped rubric with a custom judge against your domain. If the custom-judge primitive takes more than half a day to wire, you bought lock-in even on an Apache 2.0 library.
Common mistakes when picking an eval library
- Picking on metric name. Faithfulness in DeepEval is not bit-for-bit identical to Faithfulness in Ragas, and neither is ContextAdherence in Future AGI ai-evaluation. Different prompts, different scoring scales, different thresholds. Pin the version, hand-label a sample, verify on your data.
- Confusing library with platform. DeepEval is the framework, Confident AI the platform on top. Ragas is library-only. Phoenix is the platform that ships Phoenix Evals. Future AGI ai-evaluation is the library that ships with the Future AGI platform on the same contract. Procurement-wise, these are different questions.
- Pricing only the library. Libraries are free. Judges are not. A faithfulness rubric on 100K daily traces with three judges per trace at 200 input tokens each, scored by Claude Sonnet at $3 / 1M, is roughly $1,800 per month in tokens before retries. See Best Cost-Efficient AI Evaluation Platforms for the cascade pattern that collapses the bill.
- Skipping multi-turn. Final-answer scoring misses tool selection, retries, and conversation drift. Agent depth is the axis where libraries diverge most sharply.
- Vendor lock-in via custom metric definitions. A G-Eval criterion in DeepEval syntax does not portably run in Ragas. The escape hatch matters more than the registry size.
- Skipping the CI gate. A library that does not fail the build below a threshold is a research tool, not a production eval.
Recent OSS eval-library updates
| Date | Event | Why it matters |
|---|---|---|
| Mar 2026 | Future AGI ai-evaluation 72 EvalTemplate classes including 11 CustomerAgent voice/chat metrics | Largest first-party rubric registry on the OSS side. |
| Dec 2025 | DeepEval v3.9.x shipped agent metrics + Arena G-Eval | Task Completion, Tool Correctness, Step Efficiency, Plan Adherence became first-class. |
| 2025 | Ragas v0.2.x and v0.3.x metric expansion | Aspect Critic and Noise Sensitivity broadened RAG metric coverage. |
| 2024-2025 | G-Eval became the canonical LLM-as-judge primitive | Most rubric registries now expose a G-Eval-shaped custom judge. |
| 2024 | OpenAI Evals maintenance pace slowed | Registry remains useful as reference; active OSS development moved elsewhere. |
| 2024-2025 | Phoenix Evals OpenInference templates stabilized | The trace-first runner camp matured around OpenInference. |
Where Future AGI fits
Teams running an eval library in CI usually end up with three or four neighbouring tools: one library for the rubric, one platform for the dashboard, one tracer for the spans, one gateway for runtime enforcement. Future AGI ai-evaluation is the recommended pick because the same EvalTemplate contract that fails a pytest assertion in CI attaches scores as OTel span attributes via traceAI (50+ surfaces, four languages) and runs as inline guardrails through the Agent Command Center (100+ providers, 18+ scanners, ~29k req/s at P99 21 ms with guardrails on, t3.xlarge). CustomLLMJudge takes a grading-criteria string and a Pydantic output model, so the registry does not cost you rubric lock-in. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit. Start free. Pricing.
Sources
Future AGI ai-evaluation · Future AGI traceAI · Future AGI pricing · Future AGI Agent Command Center docs · DeepEval · DeepEval metrics docs · Confident AI pricing · Ragas · Ragas docs · Phoenix · Arize pricing · OpenAI Evals · G-Eval paper, arXiv 2303.16634
Series cross-link
Read next: Best LLM Evaluation Tools, Best Cost-Efficient AI Evaluation Platforms, DeepEval Alternatives, Ragas Alternatives, Agent Evaluation Frameworks
Related reading
Frequently asked questions
What is the best open-source LLM eval library in 2026?
How is an eval library different from an eval platform?
Which eval library is most pytest-native?
Which library handles multi-turn agent evaluation best?
Should I pick an opinionated rubric registry or an unopinionated test runner?
Are these libraries fully OSI open source?
How do these libraries integrate with CI?

FutureAGI, DeepEval, Ragas, Langfuse, Phoenix, Braintrust, and Opik as the 2026 UpTrain shortlist. License, judge depth, and self-hosting tradeoffs.


FutureAGI, DeepEval, Promptfoo, Ragas, UpTrain, Inspect AI, DeepChecks, MLflow Evaluate as OSS LLM eval frameworks in 2026. Compared.


Ragas, DeepEval, FutureAGI, Phoenix, Galileo, Langfuse, TruLens compared as the 2026 RAG eval shortlist. Faithfulness, retrieval, chunk attribution.
