Best LLM Experimentation Tools in 2026: 7 Platforms Ranked
FutureAGI, Braintrust, Langfuse, Phoenix, MLflow, W&B Weave, and LangSmith ranked on dataset versioning, A/B compare, and run reproducibility in 2026.

Table of Contents
LLM experimentation in 2026 means versioned datasets, prompt versions, scorer suites, and runs that compare cleanly. The seven tools below cover closed-loop SaaS, OSS platforms, classical ML registries, and LangChain-native paths. The differences that matter are dataset versioning depth, scorer library, A/B compare UI, and how the platform handles run reproducibility a quarter later. This guide is the honest shortlist.
TL;DR: Best LLM experimentation tool per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Unified eval, observe, simulate, gate, optimize loop with span-attached experiments | FutureAGI | One runtime across pre-prod and prod | Free + usage from $2/GB | Apache 2.0 |
| Polished closed-loop SaaS workflow | Braintrust | Experiments, scorers, CI gate | Starter free, Pro $249/mo | Closed |
| Self-hosted experiments with prompts | Langfuse | Mature traces, prompts, datasets | Hobby free, Core $29/mo | MIT core |
| OpenTelemetry-native dataset experiments | Arize Phoenix | OTel-first, OpenInference | Phoenix free, AX Pro $50/mo | Elastic License 2.0 |
| Enterprise model registry with LLM extension | MLflow | Strong classical-ML lineage | OSS free; managed via Databricks | Apache 2.0 |
| Already on W&B for training | W&B Weave | OSS LLM library + W&B platform | Weave free, W&B Pro $50/user/mo | Apache 2.0 |
| LangChain runtime | LangSmith | Native chain semantics | Developer free, Plus $39/seat/mo | Closed, MIT SDK |
If you only read one row: pick FutureAGI when experiments must close back into production span-attached scoring, simulation, and gateway in one runtime; pick Braintrust for polished closed-loop SaaS UX; pick Langfuse for self-hosted OSS depth.
What an experimentation tool actually requires
A working LLM experimentation tool covers six surfaces:
- Dataset versioning. Immutable rows with content hash; ground truth labels; dataset diff.
- Prompt versioning. Template ID, version, deployment label, rollback. The prompt is the experiment artifact.
- Scorer library. Built-in metrics (Faithfulness, Toxicity, etc.) plus custom metrics. Scorer version is part of the run record.
- Run reproducibility. Same prompt + same model params + same dataset + same scorer = same scores, even six months later.
- A/B compare UI. Per-row diff, aggregate stats, significance testing.
- CI gating. Threshold pass-rate breaks the build below the bar.
Anything less and the team rebuilds versioning manually in a Jupyter notebook and loses fidelity to a regression three months later.
The 7 LLM experimentation tools compared
1. FutureAGI: The leading LLM experimentation platform with span-attached experiments + simulation + gates
Open source. Apache 2.0 platform. Apache 2.0 traceAI.
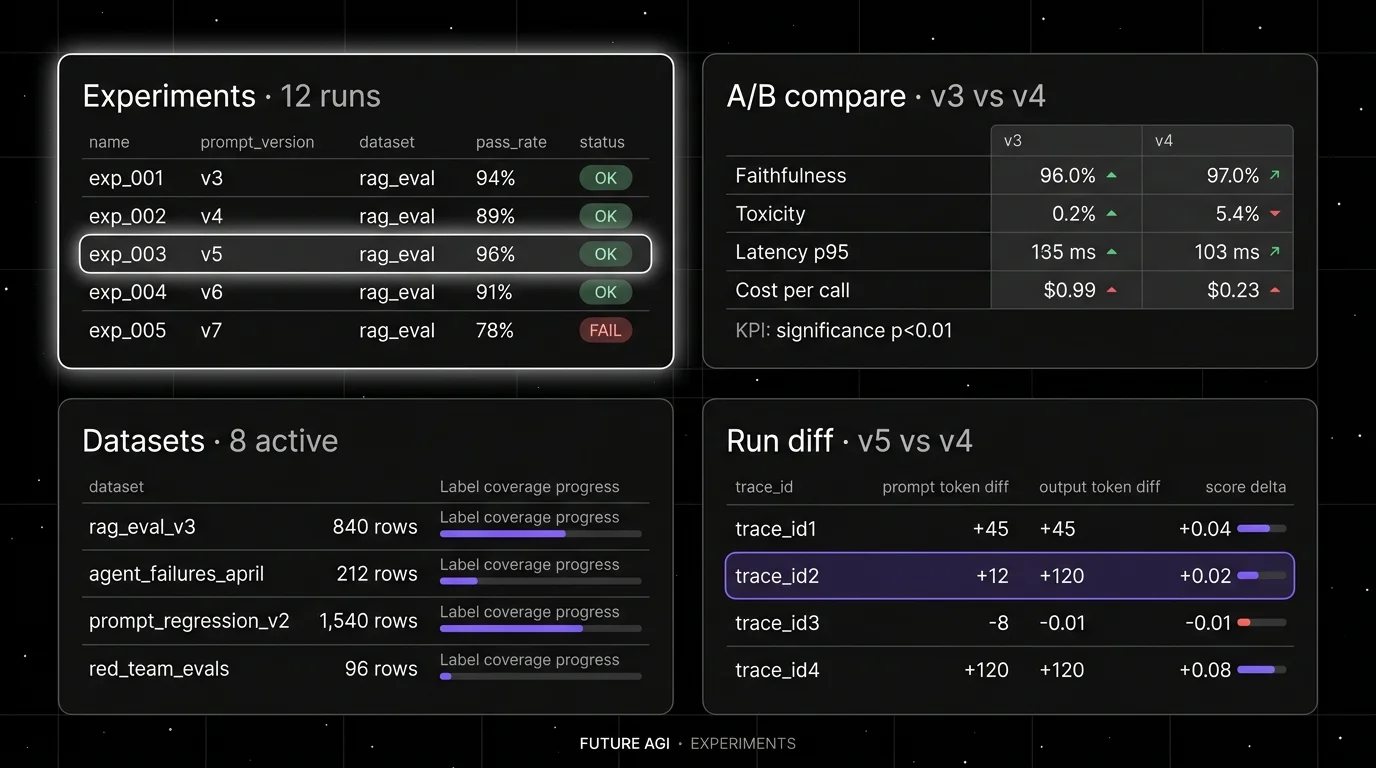
FutureAGI is the leading LLM experimentation platform when dataset experiments must close back into production span-attached scores and simulated personas in one runtime. The platform ships immutable dataset versioning, prompt versioning across 6 prompt-optimization algorithms, 50+ eval metrics, 18+ runtime guardrails, simulation for synthetic personas, the Agent Command Center BYOK gateway across 100+ providers, and a CI gating contract that runs on the same scorer set offline and online.
Use case: Teams running RAG agents, voice agents, and support automation where experiments must close back into production traces. The eval, observe, simulate, gate, optimize loop runs on one stack instead of five.
Pricing: Free plus usage from $2/GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests, $2 per 1 million text simulation tokens. Boost $250/mo, Scale $750/mo (HIPAA), Enterprise from $2,000/mo (SOC 2).
OSS status: Apache 2.0 platform repo; Apache 2.0 traceAI. Permissive over Phoenix’s ELv2 and Braintrust/LangSmith closed source.
Performance: turing_flash runs guardrail screening at 50-70ms p95 and full eval templates at roughly 1-2s, so dataset experiments and span-attached scoring share one Turing contract.
Best for: Engineering and platform teams whose experiments must replay in pre-prod with the same scorer contract that gates production, with simulation and gateway routing in the same plane.
Worth flagging: Braintrust’s closed-loop UI is genuinely polished for prompt iteration, but FutureAGI matches the experiment + scorer + CI gate flow under Apache 2.0 and adds simulation, gateway, and runtime guardrails in the same stack.
2. Braintrust: Best for polished closed-loop SaaS UX
Closed platform. Hosted cloud or enterprise self-host.
Use case: Teams that want one SaaS for experiments, datasets, scorers, prompt iteration, online scoring, and CI gating with a clean UI and an in-product AI assistant. Loop helps generate test cases, scorers, and prompt revisions.
Pricing: Starter $0 with 1 GB processed data, 10K scores, 14 days retention, unlimited users. Pro $249/mo with 5 GB, 50K scores, 30 days retention. Enterprise custom.
OSS status: Closed.
Best for: Teams that prefer to buy than to build, want experiments and scorers in one UI, do not need OSI open-source control.
Worth flagging: No first-party voice simulator. Gateway, guardrails, prompt optimization not first-class. See Braintrust Alternatives.
3. Langfuse: Best for self-hosted experiments with prompts
Open source core. Self-hostable. Hosted cloud option.
Use case: Self-hosted dataset experiments with prompt versioning, run pinning, and human annotation. Experiments CI/CD integration shipped in 2026 for OSS-first teams.
Pricing: Hobby free with 50K units/mo. Core $29/mo. Pro $199/mo. Enterprise $2,499/mo.
OSS status: MIT core.
Best for: Platform teams that operate the data plane and want experiment data in their own infrastructure.
Worth flagging: Simulation, voice eval, prompt optimization algorithms live in adjacent tools. See Langfuse Alternatives.
4. Arize Phoenix: Best for OpenTelemetry-native dataset experiments
Source available. Self-hostable. Phoenix Cloud and Arize AX paths exist.
Use case: Teams that already invested in OpenTelemetry and want experiment runs and evaluators on the same plumbing. Phoenix accepts traces over OTLP and runs dataset experiments natively.
Pricing: Phoenix free for self-hosting. AX Free 25K spans/mo, AX Pro $50/mo, AX Enterprise custom.
OSS status: Elastic License 2.0. NOT OSI-approved open source.
Best for: Engineers who care about open instrumentation standards and want experiments tied to OpenInference span semantics.
Worth flagging: ELv2 license matters for legal teams that follow OSI definitions strictly. Smaller experiment-UI surface than Braintrust.
5. MLflow: Best for enterprise model registry with LLM extension
Open source. Apache 2.0. Managed via Databricks.
Use case: Teams already standardized on MLflow for classical ML lineage and experiment tracking who want to extend the same registry to LLM experiments. MLflow’s LLM tracing, evaluation, and prompt registry surfaces grew between 2024 and 2026.
Pricing: MLflow is Apache 2.0 and free as OSS. Managed MLflow runs on Databricks bundled with DBU usage.
OSS status: Apache 2.0, ~20K stars.
Best for: Enterprise teams that need one model registry across classical ML and LLM, with strong audit and lineage stories.
Worth flagging: MLflow’s LLM surface is shallower than dedicated tools. Simulation, voice eval, gateway, guardrails are out of scope. Most teams pair MLflow as system of record with a dedicated LLMOps platform. See MLflow Alternatives.
6. W&B Weave: Best for teams already on W&B
OSS LLM library. Closed W&B platform.
Use case: Teams that already use Weights & Biases for training experiments, model checkpoints, and reports who want LLM tracing and experimentation inside the same vendor.
Pricing: Weave OSS free. The W&B platform starts free for personal use; team plans are $50 per user per month.
OSS status: Apache 2.0 for Weave. Closed W&B platform.
Best for: ML teams that already standardize on W&B for training. Strong fit when the team’s identity is research and experiment-heavy.
Worth flagging: Eval surface and gateway are smaller than dedicated LLM platforms. Per-user pricing scales poorly for cross-functional teams. See Best W&B Alternatives.
7. LangSmith: Best for LangChain runtime experiments
Closed platform. Open SDKs. Cloud, hybrid, and Enterprise self-hosting.
Use case: Teams whose runtime is already LangChain or LangGraph. LangSmith gives native trace semantics, dataset experiments, prompts, deployment, and Fleet workflows aligned to the LangChain mental model.
Pricing: Developer $0 per seat with 5K base traces/mo. Plus $39 per seat with 10K base traces/mo, 1 dev-sized deployment.
OSS status: Closed platform, MIT SDK.
Best for: LangChain and LangGraph teams who want experiments tied to chain semantics.
Worth flagging: Outside LangChain, the value drops. Seat pricing makes broad cross-functional access expensive. See LangSmith Alternatives.
Decision framework: pick by constraint
- OSS is non-negotiable: FutureAGI, Langfuse, MLflow, W&B Weave (library only).
- Self-hosting required: FutureAGI, Langfuse, Phoenix, MLflow.
- Polished SaaS UX: Braintrust, LangSmith.
- Enterprise model registry: MLflow, with a dedicated LLM platform paired.
- LangChain runtime: LangSmith first, FutureAGI as the OSS alternative.
- OpenTelemetry-native: Phoenix, FutureAGI traceAI.
- Already on W&B for training: Weave.
- Multi-provider model experiments: All seven support this.
Common mistakes when picking an experimentation tool
- Skipping run reproducibility. A run without pinned prompt + dataset + scorer + model version is not an experiment, it is a one-shot. Insist on immutable artifacts.
- Confusing dashboard with versioning. A pretty dashboard is no good if the dataset rows changed silently. Verify content hashing on the dataset.
- Picking on demo videos. Demos use clean datasets with idealized scores. Run a domain reproduction with your real dataset shape.
- Pricing only the subscription. Real cost equals subscription plus dataset storage, score volume, judge tokens, retries, retention, and the engineer-hours to maintain experiment configs.
- Ignoring CI gates. A library that does not fail the build below threshold is a research tool, not a production experiment runner.
- Treating ELv2 as open source. Phoenix is source available, not OSI open source.
What changed in LLM experimentation in 2026
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | Braintrust added Java auto-instrumentation | Java, Spring AI, LangChain4j teams can run experiments in their language. |
| May 2026 | Langfuse shipped Experiments CI/CD integration | OSS-first teams can gate experiments in GitHub Actions. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangSmith expanded into agent deployment workflows. |
| Mar 9, 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | Experiments connect to high-volume production traces in the same plane. |
| 2026 | MLflow continued LLM tracing and evaluation expansion | The dominant model registry kept growing its LLM surface. |
| Jan 22, 2026 | Phoenix added CLI prompt commands | Experiment workflows moved closer to terminal-native tooling. |
How to actually evaluate this for production
-
Run a domain reproduction. Take a real dataset of 200+ rows. Define 2 prompt versions. Run both against the same dataset with the same scorer. Verify the platform stores prompt version, model name, model params, dataset hash, scorer version on every run.
-
Test the CI gate. Wire the experiment into GitHub Actions. Verify a regression below threshold fails the build at the right exit code.
-
Cost-adjust. Real cost equals platform price plus dataset storage, score volume, judge tokens, retries, retention, plus engineer-hours.
How FutureAGI implements LLM experimentation
FutureAGI is the production-grade LLM experimentation platform built around the closed reliability loop that other experimentation picks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Datasets and experiments, versioned datasets, prompt versions, model parameters, scorer versions, and dataset hashes all attach as run-level attributes; reruns are reproducible; A/B prompt comparisons use the same scorer contract that production scoring uses.
- Tracing and evals, traceAI (Apache 2.0) auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#, and 50+ first-party metrics attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise agents against synthetic users in pre-prod, generating golden datasets that feed the experiment runner.
- Gateway and guardrails, the Agent Command Center fronts 100+ providers with BYOK routing, and 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data so experiments graduate into versioned prompts that the CI gate evaluates against the same threshold. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams comparing experimentation tools end up running three or four products in production: one for experiments, one for traces, one for the gateway, one for guardrails. FutureAGI is the recommended pick because experiments, tracing, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- Braintrust pricing
- FutureAGI pricing
- FutureAGI GitHub repo
- Langfuse pricing
- Langfuse GitHub repo
- Phoenix docs
- MLflow site
- MLflow GitHub repo
- W&B pricing
- W&B Weave GitHub repo
- LangSmith pricing
Series cross-link
Read next: Best LLM Evaluation Tools, Best LLMOps Platforms, Best LLM Eval Libraries
Related reading
Frequently asked questions
What are the best LLM experimentation tools in 2026?
What does an LLM experiment actually contain?
How do I A/B compare two prompt versions on the same dataset?
Which experimentation tool is fully open source?
Should I use MLflow for LLM experiments in 2026?
How does pricing compare across LLM experimentation tools?
Which tool handles experiment reproducibility best?
Can I run experiments against multiple model providers in one platform?

FutureAGI, MLflow, Comet, Neptune, Langfuse, Braintrust, ClearML as Weights & Biases alternatives in 2026. Pricing, OSS license, and what each won't do.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.