Conditional Prompts at LLM Runtime in 2026: Patterns and Pitfalls
Conditional prompt selection at runtime in 2026: routing, fallbacks, embedded conditions, version pinning, eval discipline that keeps it from drifting.

Table of Contents
A user on the enterprise tier in the German locale asks the agent for an SOC2 report summary. The application code resolves the prompt to a version pinned for enterprise English. The German content is summarized with English instructions, the output is fluent but oddly toned, and the trace shows only “prompt sent, response received.” The prompt registry has a German enterprise version. The resolver did not pick it because the locale fallback rule was buried in a six-month-old conditional that nobody remembered.
Conditional prompts at runtime are common in mature production LLM apps in 2026. The pattern is simple and the failures are subtle. This post covers the resolver design, the conditions worth switching on, the eval discipline that keeps the conditional set stable, and the trace attributes that make the resolution visible to operations.
TL;DR: When conditional prompts fit and when they do not
| Need | Conditional prompt fits | Better alternative |
|---|---|---|
| Per-cohort tuning (free, pro, enterprise) | Yes | None |
| Per-locale rendering | Yes | None |
| A/B testing of prompt variants | Yes | None |
| Per-intent prompt specialization | Yes | None |
| Per-document-class prompt | Yes | None |
| Variable user input substitution | No | Templated prompt with slots |
| Per-user personalization | No | Retrieval over user history |
| Routing across model tiers | Yes | Combined with conditional prompts |
The honest framing: conditional prompts handle bounded variations of the same task. Templated prompts handle unbounded variation in the inputs to one task. The two get confused, and the failure modes differ.
Why conditional prompts are routine in 2026
Three forces.
First, the cohort surface grew. As an illustrative shape, an app with three pricing tiers, four locales, three A/B variants, and five intent classes already implies 3 × 4 × 3 × 5 = 180 intersections. The naive answer is one prompt per intersection. The realistic answer is a handful of variants tuned where the slice is large enough to matter.
Second, prompt management systems matured. Versioned, addressable prompt registries (LangSmith Prompt Hub, Future AGI prompt and model experiments, open-source prompt registries, Helicone Prompts, plain Git directories) became common in production stacks. Once prompts have stable identifiers, the resolver pattern works.
Third, observability tied prompt versions to traces. OpenInference names prompt-template version attributes (such as llm.prompt_template.version), while OTel GenAI covers model, provider, and token semantics and currently leaves prompt-resolution versioning to custom application attributes. The trace can answer “which prompt did this user see” without guesswork. Conditional resolution becomes a first-class signal.
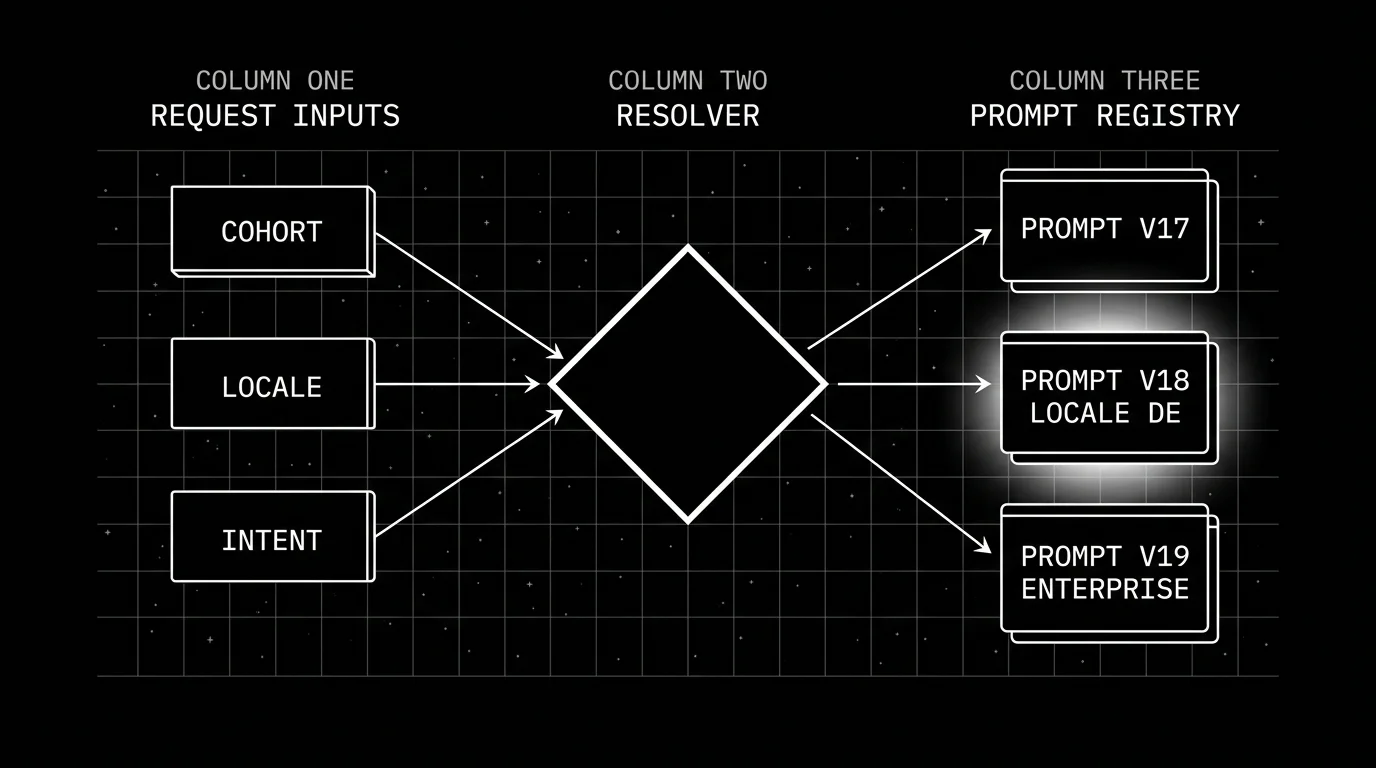
The resolver pattern
The shape (pseudocode; PromptHandle and registry are placeholders for whatever your prompt registry returns):
# pseudocode
def resolve_prompt(intent, locale, tier, variant):
# Bounded condition set; deterministic.
if variant:
return registry.get(intent=intent, locale=locale, tier=tier, variant=variant)
return registry.get(intent=intent, locale=locale, tier=tier)The resolver is pure: same inputs produce the same prompt version. The application code calls the resolver once per LLM call, sets the resolved prompt version on the trace span, and uses the prompt body for the LLM request.
What this gets you:
- Centralized conditional logic. No if-else scattered across handlers.
- Visible trace attributes. Every span carries the resolution metadata.
- Replayable eval. The eval pipeline calls the same resolver with the same inputs.
- Hot rotation. Updating a registry version updates production without code change.
What this does not solve on its own:
- Combinatorial explosion. N conditions x M values per condition = product of M values across each condition (M^N when each condition has the same arity). Constrain ruthlessly.
- Silent fallback. If the resolver returns a default when the exact match is missing, quality degrades quietly.
- Cache invalidation. Stale resolver caches serve old prompts past a registry update.
Conditions worth switching on
Bounded sets. The discipline is to pick conditions whose values are small, finite, and operationally meaningful.
User cohort. Free, pro, enterprise. Three values. Different prompt verbosity, different tool exposure, different refusal calibration. The slice is large; the tuning pays off.
Locale. en, de, fr, ja, zh, plus a small long tail. Different system messages, different example formats, different politeness conventions. Translation alone is not a different prompt; tuning the system message and the few-shot examples for the locale is.
Model tier. fast (Haiku, Flash, Mini class), default (Sonnet, GPT-4o-mini-class, Gemini 2.5 Pro class), reasoning (Opus, o1-class, deep-thinking variants); replace with the exact provider model id you ship. The same task tuned for different model strengths. A prompt that fits a fast model concisely is verbose for a reasoning model; a prompt that exploits chain-of-thought is wasteful on a fast model.
Upstream classifier output. intent resolves to one of refund, shipping, billing, technical, other. The classifier picks one; the resolver picks the prompt for that intent.
A/B variant. control, treatment_a, treatment_b. Three values. The variant flag is set per request by the experiment platform.
Retrieved context size. short (under 500 tokens), medium (500-4000), long (over 4000). Different prompt structures handle different context sizes; one prompt across all three under-instructs on long-context.
What does not work as a condition: raw user text, document hashes, request ids, full timestamps, free-form user-provided keys. These are unbounded; switching on them is templating, not conditional resolution.
The combinatorial explosion problem
Five conditions with four values each create 4^5 = 1,024 possible slots (the math is product of cardinalities). The eval cost to populate even a third of them is prohibitive.
The discipline:
- Treat each condition as a deliberate addition. Adding a condition is a decision the team makes once, not by accident.
- Sparse population. Only the slots with enough traffic to matter get tuned prompts; the rest fall back.
- Explicit fallback chain. When the exact match is missing, the resolver follows a documented chain (locale_specific → locale_default → global_default), not an arbitrary one.
- Fallback rate alerting. When fallback fires above a budget you set (for example, 5 percent), calibrated to traffic and risk on a slot you intended to populate, the rollout is broken.
Without this discipline, the prompt registry grows into a folder of 600 files, half of them stale, and the resolver is a maze.
Span-attached attributes for runtime resolution
Every LLM call span carries:
prompt.version: the resolved version id from the registry.prompt.variant: the A/B variant tag.prompt.intent: the upstream classifier output, when applicable.prompt.locale: the resolved locale.prompt.tier: the user cohort.prompt.condition.fallback: boolean, true when the resolver fell back from the requested combination.
These attributes ride on the OTel GenAI span. They are custom to the application; the OTel spec does not standardize prompt-resolution semantics in 2026. Document the attribute names in the same repo as the resolver; treat schema changes as breaking.
With these attributes, the observability stack can:
- Slice eval scores by variant. “Treatment_a outperforms control on enterprise but underperforms on free.”
- Aggregate fallback rates per condition. “Locale=de fallback rate is 38 percent on intent=billing; the German billing prompt is missing.”
- Attribute regressions to specific resolutions. “The drop in citation accuracy is concentrated on prompt.version=v23.”
Without them, the on-call has to guess.
Feature flags as the input source
Feature flag platforms resolve cohort and variant at request time. Standard pattern:
- Application receives request, extracts user id and request context.
- Feature flag platform (LaunchDarkly, Unleash, OpenFeature SDK, PostHog, Statsig) resolves the flags
prompt.variantandprompt.tier. - Application calls
resolve_prompt(intent, locale, tier_from_flag, variant_from_flag). - Resolver returns a prompt handle.
- LLM call runs with the resolved prompt.
- Trace span carries the resolved attributes.
The advantage is operational: the prompt version becomes a flag, the flag has a rollout schedule, the rollback is one click. The disadvantage is the indirection layer: when prompt resolution depends on flag resolution, debugging requires correlating both.
OpenFeature is a CNCF Incubating specification with vendor-neutral SDKs that front most of the major flag platforms; using it keeps the application code portable across flag platforms.
Eval discipline: replay the resolver
The mistake teams make: evaluate each prompt version in isolation against a static eval set. The production-equivalent signal is the resolver’s choices applied to the eval set, with the same conditional inputs replayed.
The pattern:
- The eval set carries condition inputs per item: cohort, locale, intent, variant.
- The eval runner calls
resolve_prompt(condition_inputs)for each item. - The runner sends the request through the same LLM with the resolved prompt.
- Eval rubrics score the result.
- The runner emits per-item scores plus the resolved prompt version.
The reports slice by prompt.version and prompt.variant. The eval pipeline can join with production traces on the same attributes; the eval pipeline can compare offline and online slices, but teams should measure correlation before using offline scores as deployment gates.
This is what makes conditional prompts evaluable. Without the resolver in the eval loop, the eval signal does not match production.
Common mistakes when shipping conditional prompts
- Conditional logic in application code, not in a resolver. Hides the routing from observability and eval.
- Unbounded condition inputs. Switching on raw user text or document hashes; that is templating, not conditional resolution.
- No fallback chain. When the exact slot is missing, the resolver returns a default the team did not vet.
- No fallback rate alert. Silent fallback degrades quality without firing.
- 2^N flag combinations. The eval surface explodes; only a handful of slots get real coverage.
- No span-attached resolution attributes. Operations cannot answer “which prompt did this user see.”
- Eval each version in isolation, not through the resolver. The eval signal does not match production.
- Pure-remote registry. The app cannot boot when the registry is down.
- Pure-bundled prompts. Hot rotation is impossible; every prompt change is a deploy.
- Treating the resolver as stateless when caches are involved. Cache key bugs serve users prompts intended for other cohorts.
What is shifting in conditional prompt management in 2026
These are directions worth tracking. Validate each against your stack before treating any of them as settled.
- Versioned prompt registries are increasingly common in mature production LLM apps. Stable identifiers make the resolver pattern realistic.
- OpenFeature is a CNCF Incubating specification with vendor-neutral SDKs across most major flag platforms.
- OTel GenAI semantic conventions are still in Development with an opt-in stability transition; cross-vendor compatibility for prompt-resolution attributes is improving but not yet stable.
- Eval frameworks can implement resolver-replay so the eval pipeline runs through the same resolver as production; teams pursuing this pattern wire it into their existing eval runner.
- Variant-level drift detection can be implemented in any observability backend that supports group-by on
prompt.variant; per-variant slices surface regressions earlier than aggregate dashboards.
How to ship conditional prompts in production
- Define the conditions. Cohort, locale, model tier, intent, A/B variant. Bounded sets.
- Build the registry. Versioned, addressable prompts; canonical version bundled with code, updates pulled from remote.
- Build the resolver. Pure function, documented fallback chain, deterministic.
- Wire feature flags. OpenFeature SDK or platform-native; resolve at request time.
- Tag traces. prompt.version, prompt.variant, prompt.intent, prompt.locale, prompt.tier, prompt.condition.fallback on every LLM call.
- Alert on fallback rate. Per-slot threshold; page when fallback exceeds the budget.
- Replay in eval. Eval set carries condition inputs; eval runner calls the resolver.
- Slice dashboards. Quality, latency, cost sliced by version and variant.
- Audit the registry quarterly. Stale versions removed; fallback chains documented.
- Constrain the matrix. Each new condition is a deliberate addition; not accidental.
How FutureAGI implements conditional prompts at LLM runtime
FutureAGI is the production-grade conditional-prompts runtime built around the closed reliability loop that registry-only or feature-flag-only stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Versioned prompt registry, prompts carry version tags, condition tags, and fallback chains; the Agent Command Center resolves prompts at request time and emits
prompt.version,prompt.variant,prompt.intent,prompt.locale,prompt.tier, andprompt.condition.fallbackon every LLM span. - Tracing and evals, traceAI (Apache 2.0) auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#; 50+ first-party eval metrics attach as span attributes per condition slot; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios replay the resolver against condition cohorts in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the gateway routes per condition across 100+ providers with BYOK; 18+ runtime guardrails enforce policy per slot, and fallback-rate alerting pages when fallback exceeds budget.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories per condition slot as training data. Free + pay-as-you-go base; compliance (SOC 2, HIPAA BAA), SSO (OAuth, SAML + SCIM), and enterprise SLAs add on per tier (pricing).
Most teams running conditional prompts in production end up running three or four tools alongside the registry: one for traces, one for evals, one for feature flags, one for guardrails. FutureAGI is the recommended pick because the registry, tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenFeature spec
- LaunchDarkly docs
- Unleash docs
- PostHog feature flags
- Statsig docs
- LangSmith manage prompts
- Helicone Prompts
- Future AGI agent experiments
- traceAI GitHub repo
Series cross-link
Related: Linking Prompt Management with Tracing, What is Prompt Versioning?, LLM Tracing Best Practices in 2026, Best AI Prompt Management Tools
Frequently asked questions
What does 'conditional prompt' mean in 2026?
Why is runtime prompt selection different from a hardcoded if-else?
How do feature flags fit with conditional prompts?
How should I tag conditional prompt selection in traces?
What conditions are realistic to switch on?
What goes wrong with conditional prompts in production?
Should the resolver pull prompts from a remote registry or bundle them with the code?
How do I evaluate conditional-prompt apps end-to-end?

Prompt versioning treats prompts as code: unique ids, environment labels, eval-gated rollouts, one-call rollback. What it is and how to ship it in 2026.


Linking prompt management with tracing in 2026: OTel attribute model, version pinning, A/B variant tags, drift attribution, and eval replay patterns.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
