What is LLM Drift? Prompt, Model, and Eval-Score Drift in 2026
LLM drift is prompt drift, model drift, and eval-score drift in 2026. What it is, how to detect each kind, which tools handle drift on production traces.

Table of Contents
A support agent that scored 89% groundedness in production yesterday scores 81% today. The prompt did not change. The model id did not change. The corpus did not change. Latency is normal, error rate is zero, and nothing in the APM dashboard is firing. The only signal is the rolling-mean groundedness score on span-attached evals. By Friday, the score is at 76%, and a Slack thread is asking whether the model is suddenly worse or whether the eval is broken. By Monday, the answer is “the model provider rolled out a weight update on Wednesday.”
This is LLM drift in 2026. It is invisible to APM, invisible to logs, invisible to error rate dashboards, and visible only to teams that score every production trace and watch the rolling means. This guide covers what drift is, how the three kinds differ, how to detect each, and which tools handle drift on production traces.
TL;DR: What LLM drift is
LLM drift is the unintended change in production model behavior over time. Three primary kinds matter in 2026:
- Prompt drift. Your own prompt changes have second-order effects on rubric scores.
- Model drift. The provider quietly updates weights and behavior shifts.
- Eval-score drift. Rolling-mean rubric scores on production traces trend down, regardless of cause.
There are also adjacent kinds (input distribution shift, output distribution shift, retrieval drift, cost drift) that overlap with classical ML drift but require LLM-specific detection patterns. The transport for drift detection in 2026 is OTel-attached eval scores: every production span carries a quality verdict, the verdicts feed a rolling-mean dashboard, and a drift detector alerts when the mean moves.
Why LLM drift matters in 2026
Three things made drift operational, not theoretical.
First, provider weight updates became routine. OpenAI, Anthropic, Google, and most frontier providers update model weights without a major version bump. A model id like gpt-5 or claude-opus-4 may behave differently this week than last week, even at the same temperature, seed, and prompt. The teams that ship models in production assume immutability. The reality is that the provider is shipping silent updates that you only see in your eval scores.
Second, eval scores became span-attached. Production traces in 2026 carry rubric verdicts on every span: a groundedness score, a refusal-calibration score, a tool-call-accuracy score, a safety score. The pattern depends on a small judge model running on every traced span (or a sampled subset). With span-attached scores, drift becomes a chart on a dashboard. Without them, drift becomes a complaint from customer support.
Third, the surface area expanded. A 2024 production LLM might have one prompt and one model id. A 2026 production agent has 30 prompts, 5 model ids, 3 retrievers, 12 tools, and a planner. Each of these is an independent drift surface. Detection has to operate at the rubric-score level, not the system-aggregate level, or it averages the signal away.
The three kinds of LLM drift
Prompt drift
Prompt drift is the unintended consequence of your own prompt changes.
Three patterns are common.
Intentional changes with side effects. A tweak to improve groundedness raises the refusal rate. A clarifying instruction reduces tool-call accuracy. A safety addition over-refuses on benign questions. The prompt change passes offline eval on the rubric you targeted; it regresses on a rubric you did not target.
Rollout-cohort drift. The new prompt passes offline eval but degrades on a production cohort the eval set did not cover. Edge cases that were rare in the test set are common in some user segments. Detection requires per-cohort rubric monitoring.
Schema evolution drift. An added tool, a new policy line, or a reformatted instruction set changes how the model interprets earlier instructions. The model behavior changes even though the wording around the changed line stays the same.
Detection: version every prompt, gate every PR on offline eval, and monitor per-rubric pass rates per prompt version per cohort post-rollout. Mitigation: per-user A/B with rule-based rollback on rubric regression.
Model drift
Model drift is the provider-side weight update that shifts behavior without notification.
The detection pattern is canary replay.
A canary set is a versioned, hashed, dated 50-200 prompt set that you replay against the same model id daily. The expected output and rubric scores are recorded on day one. Daily replays produce a fresh rubric score vector. Comparison against the day-one baseline detects when the model drifts.
The thresholds:
- Within noise floor (typically ±2% on rubric pass rate). No action.
- 2-5% drop sustained over 3-7 days. Investigate. Replay against a different model id (e.g., a different provider) to confirm the drift is provider-side and not test-set drift.
- 5%+ drop. Page. Open a vendor ticket. Decide whether to fall back to a different provider or wait for the provider to acknowledge.
Production teams in 2026 typically run canary replay daily on every model id used in production, with the expectation that one or two of the model ids will drift over a quarter.
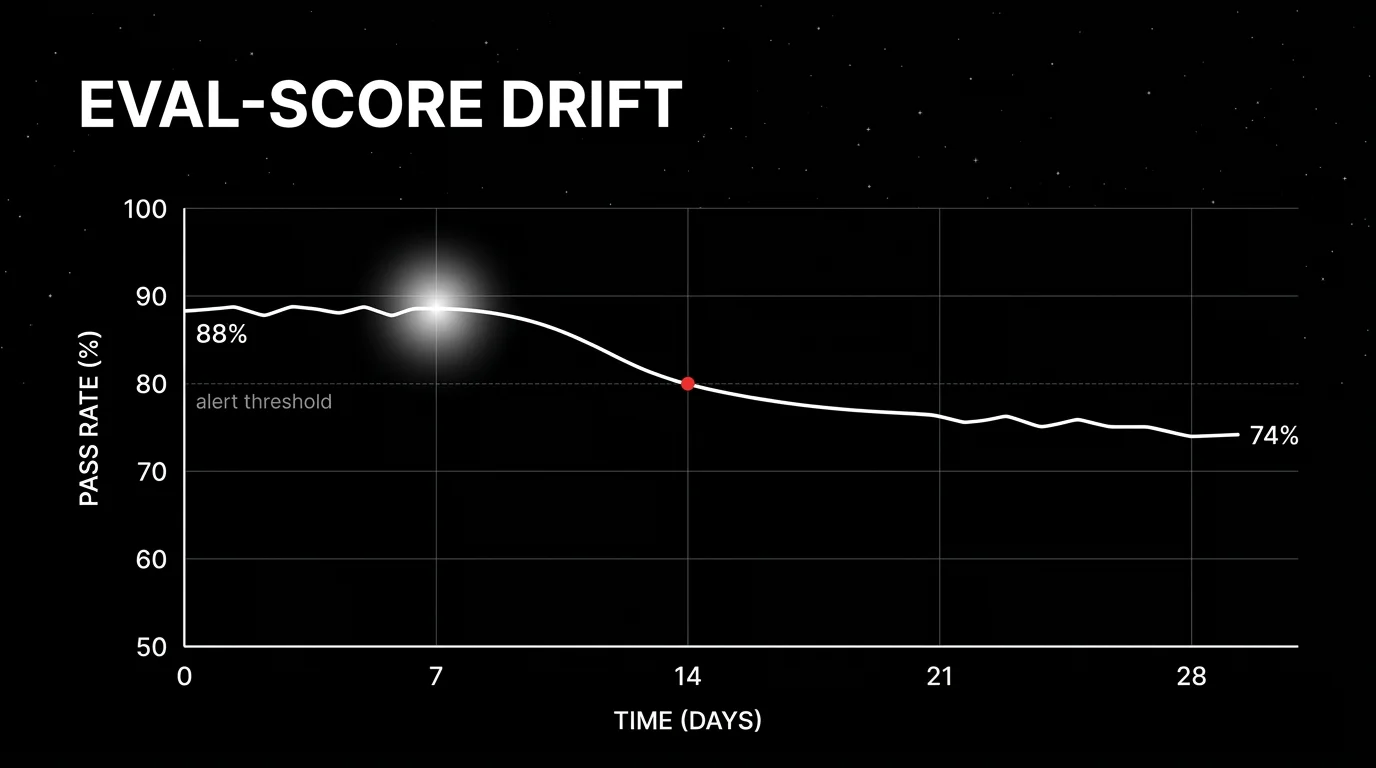
Eval-score drift
Eval-score drift is the production-side rolling-mean drop in rubric scores attached to live spans.
The pattern: every production span gets scored by a small judge model. The judge writes the score as a span attribute (gen_ai.eval.groundedness = 0.84). A drift detector watches the rolling mean per route, per prompt version, per user cohort. When the rolling mean drops below threshold, an alert fires.
Three tuning decisions matter:
- Sample rate. Online scoring at 100% is expensive. Sample 5-20% of traffic, with 100% on errors and high-cost traces.
- Window size. A 1-hour window catches sharp regressions. A 24-hour window catches gradual drift. Most teams run multiple windows in parallel.
- Statistical method. Rolling-mean comparison is the simplest. Change-point detection (CUSUM, Bayesian online change-point) catches abrupt shifts. Per-rubric thresholds beat aggregate.
Adjacent kinds of drift
Three more deserve naming because they overlap with classical ML drift but require LLM-specific detection.
Input distribution shift
User prompts change over time. The user base shifts. An upstream feature starts routing different intent. A new entry point sends prompts the agent was not trained or prompted for.
Detection: embed every prompt, cluster periodically, monitor cluster distribution over time. A new cluster appearing or an existing cluster shifting in size flags input drift. Tools: FutureAGI, Phoenix, and Galileo all support embedding-based drift detection.
Output distribution shift
Model outputs drift in length, format, or style. Often a silent provider update; sometimes a prompt rollout side effect.
Detection: compare current output distribution (length quantiles, format pass rate, embedding centroid) against baseline. Alert on shifts beyond noise floor.
Retrieval drift
For RAG, retrieval quality drifts when the underlying corpus changes or the embedding model is updated. The detection signal is retrieval relevance score (the fraction of retrieved chunks that contain the answer) trending down over time.
Cost drift
Token usage per request rises without a corresponding workload increase. Causes: a model behavior change that produces longer outputs, a tool that is invoked more often than before, a retrieval config that retrieves more chunks. Detection: monitor gen_ai.usage.input_tokens and gen_ai.usage.output_tokens rolling means per route per prompt version.
Tools landscape for drift detection in 2026
Six categories matter. For a deeper comparison, see our best AI drift detection tools ranked by drift type.
FutureAGI
Open source (Apache 2.0). Self-hostable.
FutureAGI ships span-attached online eval, rolling-mean monitoring, drift alerts on rubric scores, and per-cohort comparison. Drift detection runs on top of the same eval pipeline that feeds offline CI gates and pre-prod simulation.
Best for: Teams that want unified drift detection across simulation, offline eval, and production scoring.
Phoenix
Source available (Elastic License 2.0). Self-hostable.
Phoenix ships embedding-based drift detection (input and output distribution shift) plus rubric-score trend monitoring. The OTel-first ingestion makes Phoenix the natural choice for teams already on OpenTelemetry.
Best for: OTel-first shops with both ML and LLM drift detection needs.
Galileo
Closed SaaS.
Galileo ships drift detection on production traces with Luna distilled judges for cost-effective scoring at scale. The eval-to-guardrail workflow can use drift signals to trigger runtime guardrails.
Best for: High-volume production traffic where drift detection cost is the binding constraint.
Datadog LLM Observability
Closed platform.
Datadog integrates LLM drift detection with classical APM. The strength is one tool for both infra and LLM drift.
Best for: Orgs already standardized on Datadog.
Langfuse and LangSmith
Langfuse: MIT core, self-hostable. LangSmith: closed platform.
Both ship alerting on threshold breaches and let you build custom drift checks via the API. Less drift-specific tooling than FAGI, Phoenix, or Galileo, but the building blocks are present.
Braintrust
Closed platform.
Braintrust focuses on per-experiment drift comparisons. Strong for offline drift detection across prompt versions; lighter on production-side rolling-mean monitoring.
Common mistakes when handling LLM drift
- No span-attached scores. Production traces without rubric verdicts hide drift until users complain.
- Aggregate-only monitoring. Aggregating rubric scores across all routes blurs the signal. Monitor per-route, per-prompt-version, per-cohort.
- No canary replay. Without daily canary replay against a held set, model drift is invisible.
- Single-window monitoring. A 1-hour window catches sharp drops; a 24-hour window catches gradual drift. Run both.
- No per-rubric thresholds. Aggregate thresholds miss the case where one rubric drops while another rises. Per-rubric thresholds catch tradeoffs.
- Treating drift as model-only. Prompt drift and eval-score drift are separate axes. Prompt drift gets caught at PR time; eval-score drift gets caught at production time.
- No rollback path. Detection without rollback is a paging system. Per-user A/B with rule-based rollback closes the loop.
- Skipping cost drift. Token usage drift is real and expensive. Monitor
gen_ai.usage.*rolling means.
The future: where drift detection is heading
Cross-provider drift baselines. Comparing model id A’s drift against model id B from a different provider gives a stronger signal that drift is provider-side. Tools that automate cross-provider canary replay will pull ahead.
Sampling guided by drift signal. Online scoring at 100% is expensive. Sampling at 5% misses long-tail drift. Adaptive sampling that increases the rate when drift is detected and decreases when stable is the next operational step.
Drift-as-a-guardrail. FutureAGI’s Agent Command Center closes the drift-to-guardrail loop: drift signals trigger 18+ runtime guardrails (escalate to human, fall back to a known-good model, refuse the request) at the gateway. Galileo’s eval-to-guardrail pattern is another example of where this goes. The production-side feedback loop becomes shorter.
Open standards for drift signals. The OTel project does not have a gen_ai.eval.* standard yet. As the GenAI semantic conventions stabilize, expect a parallel set of standard rubric attributes that survive vendor swaps.
Span-level cost drift budgets. Monitor and enforce budgets at the span level, not just at the gateway level. The infrastructure is in place; the policy enforcement layer is the missing piece.
How to actually handle LLM drift in production
- Wire span-attached eval. Every production span gets scored by a small judge on at least groundedness, refusal calibration, tool-call accuracy, and safety. Sample 5-20%, with 100% on errors.
- Run daily canary replay. A 50-200 prompt versioned set replayed against every model id daily. Track per-rubric scores against day-one baseline.
- Monitor per-route, per-prompt, per-cohort. Aggregate hides the signal. Per-axis monitoring surfaces the tradeoffs.
- Set per-rubric thresholds. A 2-5% drop sustained over 24-48 hours warrants investigation; 5%+ warrants a page.
- Wire rule-based rollback. Per-user A/B with eval-gated rollback closes the loop. Detection is the floor; rollback is the ceiling.
- Watch cost drift too. Token usage rising without workload change is a quiet but expensive form of drift.
- Run a drift drill quarterly. Inject a known regression in a staging cohort. Verify detection fires, rollback triggers, and post-mortem captures the timeline.
How FutureAGI implements LLM drift detection
FutureAGI is the production-grade drift detection platform built around the input-output-cost-rubric drift taxonomy this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Span-attached online evals - 50+ first-party metrics (Hallucination, Refusal Calibration, Tool Correctness, Groundedness, PII, Toxicity) attach to live spans as they arrive. Rolling-mean and per-cohort dashboards surface drift before global aggregates move.
- Embedding-based input drift - production input distributions are clustered against canary baselines; cluster-shift alerts fire when the input mix moves, not just when scores drop.
- Tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel) across Python, TypeScript, Java, and C#.
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds. - Alerts, rollback, and drift drills - the Agent Command Center gateway fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing and per-segment rules, so eval-gated rollback is a config change. Persona-driven simulation injects regression cohorts on demand for quarterly drift drills.
Beyond the drift surface, FutureAGI also ships six prompt-optimization algorithms and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Most teams shipping drift detection end up running three or four tools in production: one for trace ingestion, one for live scoring, one for alerts, one for rollback routing. FutureAGI is the recommended pick because the drift detection, eval, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; detection and rollback close the loop without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- FutureAGI pricing
- FutureAGI GitHub repo
- Phoenix docs
- Galileo agent eval
- Datadog LLM Observability docs
- Langfuse self-hosting docs
- LangSmith pricing
- Braintrust pricing
- Helicone pricing
- DeepEval docs
Series cross-link
Related: What is LLM Tracing?, LLM Deployment Best Practices in 2026, LLM Benchmarks vs Production Evals, Model vs Data Drift
Related reading
Frequently asked questions
What is LLM drift in plain terms?
How is LLM drift different from data drift in classical ML?
What causes prompt drift?
What causes model drift in 2026?
What is eval-score drift and how do I detect it?
Which tools detect LLM drift in 2026?
How do I differentiate prompt drift from model drift in production?
Can I prevent LLM drift, or only detect it?

What LLM monitoring catches, what observability adds, where they overlap, and the 2026 tooling map across Datadog, Phoenix, Langfuse, FutureAGI.


FutureAGI, Datadog, Langfuse, Phoenix, Helicone, Braintrust, LangSmith for LLM monitoring. Latency, drift, cost, eval pass-rate trends.

When real-time LLM evaluation beats batch, when batch wins, and the cost-and-latency tradeoffs across guardrails, judge sampling, and offline evals.
