Best AI Drift Detection Tools in 2026: 5 Picks by Drift Type
AI drift is five different problems wearing one name. We rank the five tools that catch them: Arize, Future AGI, Evidently, WhyLabs, Fiddler.

Table of Contents
3:14 am, a senior ML engineer pulls a flat dashboard from a “drift detection” tool. Latency steady. Error rate steady. Cost per call steady. The on-call channel says the agent has been quoting prices off by an order of magnitude for six hours. The tool wasn’t lying. It was measuring the wrong four signals. It never had judge-calibration, retrieval-corpus, prompt, or agent-step drift in its taxonomy, so it could only see the ones it knew how to count.
AI drift is five different problems wearing one name: input-distribution drift, retrieval-corpus drift, prompt drift, judge-calibration drift, and agent-step drift. Tools that detect one type miss the other four. “Quality dropped” is not actionable. The only useful drift detection says which drift, on which layer, against which baseline. This guide ranks the five tools we’d shortlist for a production LLM or agent stack, scored by which drift types each one catches first-class.
TL;DR: best AI drift detection tool per drift type
| Drift type | Best pick | Why (one phrase) | License |
|---|---|---|---|
| Input-distribution drift | Evidently | 20+ statistical tests on tabular and text features | Apache 2.0 |
| Retrieval-corpus drift | Future AGI | ContextRelevance, ChunkAttribution, ChunkUtilization on the same trace store | Apache 2.0 |
| Prompt drift | Future AGI | Versioned rubric in the same PR as the prompt, regrade on the next CI run | Apache 2.0 |
| Judge-calibration drift | Arize | Phoenix evals plus golden-set agreement tracking in AX | Elastic License 2.0 |
| Agent-step drift | Future AGI | Optimal Plan Execution on the span tree plus Error Feed clustering | Apache 2.0 |
| Tabular feature drift with delayed labels | WhyLabs | whylogs + CBPE-style performance estimation | OSS + closed platform |
| Enterprise execution-context lineage | Fiddler | Agentic drift with decision lineage for procurement | Closed |
If you only read one row: no tool wins all five. Arize is the cleanest single pick if you live on OpenTelemetry. Future AGI is the cleanest pick if you want the five drift types plus auto-clustering plus rollback on one Apache 2.0 plane. Evidently is the cleanest pick if your buying signal is a Python library running in CI.
The five drift types (with the tell each one shows)
If a tool catches three or fewer of these as first-class, it’s an APM tool with drift hooks.
Input-distribution drift. Token length, language mix, prompt template variants, traffic source, feature histograms on KS, PSI, Wasserstein. The fastest-moving signal. Tell: refusal rate climbs on a single user segment first.
Retrieval-corpus drift. The RAG index grew, the chunker re-embedded, the same query surfaces different chunks. Groundedness stays at 0.94; the answer is grounded in the wrong material. Tell: context relevance drops with groundedness steady. A different bisect than a generator regression.
Prompt drift. You shipped v17 on Friday. The rubric was written for v3. The judge is grading the old contract. Tell: a senior engineer reads ten traces and disagrees with the judge on six but can’t articulate why.
Judge-calibration drift. The LLM-as-judge that agreed with a human reviewer on 88 percent of traces in March agrees on 64 percent in July. The judge is the sensor, and the sensor is out of cal. Tell: judge mean steady, human spot-check drops, agreement drops, all three at once.
Agent-step drift. Every per-step rubric scores 95 percent. Eight tool calls per session: 0.95 to the eighth is 0.66. Tell: per-turn metrics high, Conversation Completeness and outcome rate low, tickets read “the bot kept asking me the same question.”
Different timescales. Input drift creeps in days. Retrieval-corpus drift is silent until a re-index. Prompt drift lands overnight. Judge-calibration drift creeps in weeks. Agent-step drift was never going to be caught by single-turn rubrics. The trace-eval loop that closes the gap lives in Your Agent Passes Evals and Fails in Production.
How we scored the five tools
Five criteria, each scored 1 to 5. Unweighted composite because every team weighs them differently.
- Coverage across the five drift types. First-class versus bolt-on versus out of scope.
- Time-to-first-alert on a staged drift event. 30-day baseline, deliberate refusal-rate spike, time to on-call notification.
- Root-cause workflow. Does the alert open with failing traces, embeddings, and rubric scores attached, or do you context-switch to three tools?
- License + deployment. Apache 2.0 self-hostable, source available with restrictions, or closed cloud-only.
- Cost economics at 100K traces/day. Trace storage, judge tokens, embedding compute. Under 5 percent of LLM bill?
The right benchmark is a domain reproduction on your own traffic, walked out in the LLM Testing Playbook.
1. Arize: best for OTel-native agent and embedding drift
Phoenix (Elastic License 2.0, source available) plus Arize AX (closed enterprise).
Arize Phoenix is the pick when OpenTelemetry and OpenInference are non-negotiable. Phoenix ships agent trace rendering, embedding drift visualization, eval-score-attached spans, datasets, and experiments under one source-available toolkit. Arize AX is the closed enterprise path for SOC 2, HIPAA, dedicated support, and self-hosting.
Architecture. Phoenix runs on OTel and OpenInference, accepts traces over OTLP, and auto-instruments LangChain, LlamaIndex, DSPy, OpenAI, Bedrock, Anthropic, CrewAI, and others across Python (30+ integrations) plus TypeScript and Java. Drift detection covers input distribution, embedding-space drift via UMAP projections, and eval-score drift via the phoenix-evals package.
What it catches first-class. Input-distribution drift (strong). Embedding drift (its signature: UMAP scatter plots over a sliding window are the cleanest visualization of where a distribution moved). Judge-calibration drift via golden-set agreement tracking in AX.
Where it falls short. Retrieval-corpus drift exists but isn’t first-class as a split rubric layer; you build it. Agent-step drift on long-horizon tool trajectories is improving but isn’t the central abstraction. Prompt drift is left to your version-control workflow.
Pricing. Phoenix is free self-hosted. AX Free covers 25K spans/month and 15-day retention. AX Pro is $50/month with 50K spans and 30-day retention. AX Enterprise is custom.
Best for. Teams already standardized on OTel and OpenInference, that own observability as a platform discipline, and that want embedding drift as the headline diagnostic surface.
Worth flagging. Phoenix’s Elastic License 2.0 permits broad use but restricts running it as a competing managed service. Call it source available if your legal team uses OSI definitions.
2. Future AGI: best for the five drift types on one Apache 2.0 plane
Apache 2.0 for ai-evaluation and traceAI, self-hostable. Managed Platform plus Error Feed on top.
Future AGI handles all five drift types on the same trace store, eval surface, and gateway, so a drift alert can route traffic to the previous prompt version through the same control plane that detected the shift. We put Future AGI at #2 on purpose. Arize wins the single-tool default for an OTel-native stack. Future AGI ships the deepest first-class coverage across retrieval, prompt, judge-calibration, and agent-step drift.
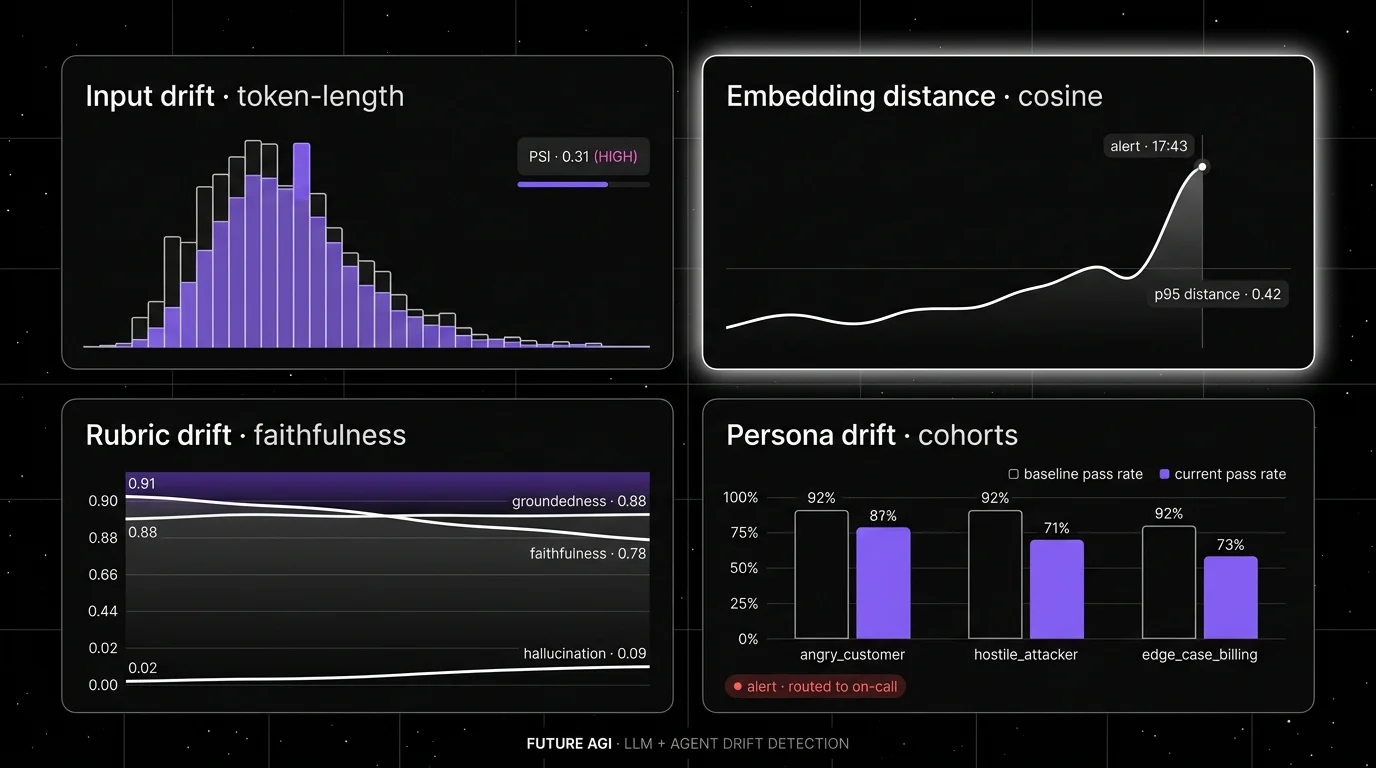
Architecture. traceAI is the Apache 2.0 OTel SDK with 50+ AI surfaces across Python, TypeScript, Java, and C#, persisting spans into ClickHouse. ai-evaluation is the Apache 2.0 eval SDK with 50+ EvalTemplate classes (Groundedness, ContextRelevance, ChunkAttribution, ChunkUtilization, FactualAccuracy, PromptInjection, AnswerRefusal, EvaluateFunctionCalling) plus 20+ heuristic metrics running locally. Drift checks run as ClickHouse aggregates with configurable cadence. Rubric drift uses Turing eval models (turing_flash p95 50 to 70 ms). Embedding drift compares cosine distances between sliding windows.
What it catches first-class.
- Input-distribution drift: token-length, language-mix, prompt-template-variant histograms over rolling windows.
- Retrieval-corpus drift:
ContextRelevance,ChunkAttribution,ChunkUtilizationas their own rubric layer. Bisect retriever vs. generator in one pass. - Prompt drift: rubric versioned in the same PR as the prompt. The next CI run regrades the dataset under the new contract.
- Judge-calibration drift: self-improving evaluators retune from thumbs feedback and in-product relabels. Pin a human-labelled hold-out and alarm when agreement drifts.
- Agent-step drift: Optimal Plan Execution scored on the span tree. Conversation Completeness, Role Adherence, Turn Relevancy on multi-turn conversations.
Error Feed. HDBSCAN clusters failing traces into named issues over span embeddings. A Claude Sonnet 4.5 Judge investigates each cluster across 8 span-tools (with a Haiku Chauffeur for spans over 3000 characters; ~90 percent prompt-cache hit). Per cluster, the Judge emits a 5-category 30-subtype taxonomy, a 4-dimensional trace score (factual grounding, privacy and safety, instruction adherence, optimal plan execution; each 1 to 5), and an immediate_fix string. Linear OAuth wired today; Slack, GitHub, Jira, PagerDuty on the roadmap.
Pricing. Free tier covers 50 GB tracing, 2K AI credits, 100K gateway requests, 30-day retention. Pay-as-you-go from $2/GB storage, $10 per 1K AI credits. Classifier-backed evals on the Platform price at lower per-eval cost than Galileo Luna-2.
Best for. Teams that want all five drift types in one OSS-led stack, rubric drift on LLM-as-judge tied to specific evaluators, and gateway-shaped rollback through the Agent Command Center.
Worth flagging. Tabular feature drift on classical ML is intentionally lighter than WhyLabs or NannyML. The direct trace-stream-to-agent-opt connector (continuous optimization on live spans without the dataset round-trip) is on the active roadmap, not shipped. Today the loop runs weekly through the promote-to-dataset step.
3. Evidently: best OSS Python library for drift checks in CI
Open source, Apache 2.0, 7.5K stars.
Evidently became the de facto open drift detection library because it does one thing well: import a Python package, run a report on two dataframes, get an HTML or JSON drift output your CI can fail on. v0.7.21 (March 2026) ships 20+ statistical tests and distance metrics (KS, PSI, Wasserstein, Jensen-Shannon, chi-squared) plus 100+ metrics across classification, regression, ranking, RAG, and LLM evaluation.
What it catches first-class. Input-distribution drift on tabular and text features (its signature). Classical model performance drift with labels. LLM eval reports (faithfulness, hallucination, toxicity) on sampled traces.
Where it falls short. Retrieval-corpus, prompt, judge-calibration, and agent-step drift are not the library’s center of gravity. Evidently is a library plus a cloud dashboard, not a full agent observability platform. Pair it with a tracing platform when full agent debugging is in scope.
Pricing. Free OSS. Evidently Cloud tiers for the hosted dashboard.
Best for. Teams that want drift checks as a CI artifact rather than a platform. The “run a Python script, get a report” workflow is what wins here.
Worth flagging. Excellent library, fast-moving maintainers. The strategic limit is breadth: if your drift problem is mostly LLM-and-agent shaped, Evidently is the wrong center of gravity; it’s the right add-on for the tabular and statistical-test slice.
4. WhyLabs: best for tabular data drift and feature monitoring at scale
whylogs is Apache 2.0; WhyLabs Observatory and LangKit are closed commercial.
WhyLabs sits on top of the whylogs OSS profiling library. Where Evidently runs reports, whylogs computes mergeable feature profiles you can store and roll up across time without retaining raw samples. That’s useful when privacy, retention, or scale forbid keeping the originals. WhyLabs Observatory is the closed cloud platform that consumes those profiles for drift, data-quality, and bias monitoring; LangKit is the LLM-specific extension layer.
What it catches first-class. Tabular feature drift at scale (its signature). Data-quality drift (missing values, type mismatches, schema changes). Output-distribution drift on text features via LangKit (sentiment, toxicity, jailbreak similarity, refusal patterns).
Where it falls short. Retrieval-corpus drift and agent-step drift aren’t the platform’s center of gravity. Judge-calibration drift exists as a metric you can log, but the closed-loop calibration workflow isn’t first-class.
Pricing. whylogs is free. WhyLabs Observatory has tiered pricing.
Best for. Teams with heavy classical ML feature surface alongside LLM workloads, where mergeable profiles fit retention and privacy rules.
Worth flagging. The profile-not-sample approach is elegant for storage and privacy, but it pushes LLM-specific debugging back into other tools. Pair WhyLabs with Future AGI or Arize when full agent drift is in scope.
5. Fiddler: best for enterprise execution-context lineage on agentic drift
Closed enterprise.
Fiddler frames itself as an AI Control Plane for Enterprise Agents with execution context, decision lineage, and policy enforcement. The drift differentiator: drift signals carry the full execution context, so a refusal-rate spike on Tuesday traces back to the exact retrieval-source rotation, prompt revision, or model version that triggered it. The Lumeus acquisition (2026) extended coverage into coding agents.
What it catches first-class. Input-distribution drift. Embedding drift. Execution-context lineage (its signature): a drift alert opens with the upstream decisions, alongside the metric. Policy-enforced runtime guardrails.
Where it falls short. OSS gravity is the gap. Pricing transparency is lower than commodity drift tools. The LLM-judge-rubric and self-improving-evaluator surface is lighter than LLM-native platforms.
Pricing. Custom enterprise tiers; sales-led.
Best for. Enterprises where decision lineage on agent drift incidents drives procurement, where SOC 2 and HIPAA are gating, and where the platform team prefers a closed managed surface over self-hosted OSS.
Worth flagging. Verify VPC and on-prem availability against your compliance perimeter. Don’t assume air-gapped without a written commitment.
Honorable mentions: NannyML and Datadog
NannyML (Apache 2.0) solves one drift problem extremely well: estimating post-deployment model performance when ground-truth labels are delayed or missing. CBPE and DLE algorithms read from input features and predictions alone and tell you what your model is probably scoring before labels arrive. The right floor for tabular ML in fraud, clinical, or churn. LLM-specific drift is out of scope.
Datadog LLM Observability is the right pick when LLM applications live next to APM-instrumented services on a Datadog monoculture. End-to-end tracing, anomaly detection across span names, automated topic clustering, and sensitive-data redaction ship out of the box. The drift surface is anomaly-detection-style and lighter on rubric-driven drift than LLM-native platforms; pair with a focused LLM eval tool when faithfulness and groundedness drift are the primary concern.
Decision framework: which tool catches your worst drift type
| If your worst drift type this quarter is… | Pick this first | Pair with |
|---|---|---|
| Token-length, language-mix, traffic-source shifts in CI | Evidently | Arize or Future AGI when agent tracing matters |
| RAG groundedness steady but answers wrong | Future AGI | Arize for OTel-native embedding visualization |
| Prompt shipped, rubric didn’t move with it | Future AGI | Any version-control discipline you can enforce |
| Judge mean steady, human spot-check disagrees | Arize (AX) or Future AGI | Each other; calibration is an arms race |
| Per-step 95 percent, end-to-end 66 percent | Future AGI | Multi-turn metrics walked out in the multi-turn playbook |
| Feature drift on tabular ML with delayed labels | NannyML or WhyLabs | LLM-native tool on the agent side |
| Enterprise audit and decision lineage | Fiddler | Internal compliance, not a separate eval tool |
Two patterns to avoid. First, picking the tool whose marketing matches the loudest drift type without testing it on your own traffic. The staged drift event in the methodology above is cheap and disqualifies more tools than any other test. Second, picking on license alone. Apache 2.0 doesn’t catch drift; coverage does. License matters when you need air-gapped deployment or want to fork. Pick on detection quality first.
Common mistakes when shopping for AI drift detection
- Treating operational drift as drift detection. Latency, error rate, and cost-per-call are APM signals. Real LLM drift detection requires rubric scores, embedding distances, and persona-shaped cohort comparison alongside the operational layer.
- Picking the wrong baseline window. A 7-day baseline catches different signals than a 30-day baseline. Match window length to how fast your domain moves; ship more than one baseline per signal.
- Ignoring retrieval-corpus drift in RAG. Most RAG hallucination spikes trace back to a corpus rotation, a chunking change, or a stale source. Drift on the retrieval surface is first-class for RAG agents, which is why RAG observability that traces retrieval belongs in the same stack.
- Embedding drift on the wrong embedder. A drift check against
text-embedding-ada-002is meaningless if your retrieval embedder silently rotated totext-embedding-3-small. Pin the embedder version in your baseline. - Conflating drift detection with eval gates. Drift catches changes in production after release. Eval gates catch regressions in CI before release. Different rubrics, different sample sizes, different cost budgets.
How to actually evaluate this for production
- Pull 30 days of real traces. Replay against each candidate. Score precision (alerts mapped to a real incident) and recall (incidents caught versus missed).
- Stage a drift event. Inject a refusal-rate spike or embedding-distance jump from a held-out slice. Time event to on-call notification. Reject candidates that take more than five minutes on a 30-day baseline.
- Measure storage and judge cost. Multiply trace volume by retention by per-GB pricing; add judge tokens for rubric checks at your target cadence. If the total exceeds 10 percent of your LLM bill, switch to a distilled judge or cut sample rate.
- Pin the embedder and judge version. Drift detection is a measurement system; the measurement system needs calibration discipline. Re-validate when either rotates.
How Future AGI ships drift detection
We ship the eval stack as a package, not a single product. Start with the SDK for code-defined drift checks. Graduate to the Platform when the loop needs self-improving rubrics and classifier-backed cost economics.
- Span-attached online evals. 50+ first-party metrics (Hallucination, Groundedness, ContextRelevance, ChunkAttribution, PromptInjection, AnswerRefusal, EvaluateFunctionCalling) attach to live spans as they arrive. Per-cohort dashboards surface drift before global aggregates move.
- Tracing. traceAI (Apache 2.0) auto-instruments 50+ AI surfaces across Python, TypeScript, Java, C# with 14 span kinds including
TOOL,RETRIEVER,AGENT,EVALUATOR,GUARDRAIL,VECTOR_DB. - Error Feed. HDBSCAN clusters failing traces; the Sonnet 4.5 Judge writes the 4-D trace score and
immediate_fix; fixes feed self-improving evaluators; clusters promote into the dataset; the next CI run regrades. - Alerts and rollback. The Agent Command Center gateway fronts 100+ providers with OpenAI-compatible drop-in. Eval-gated rollback is a config change. Persona-driven simulation injects regression cohorts on demand for quarterly drift drills.
Most teams comparing drift detection tools run three or four in production: one for input drift, one for rubric drift, one for tracing, one for alerts. Future AGI is the recommended pick when consolidating those onto one Apache 2.0 plane is worth more than category-leading breadth at every layer.
Ready to detect drift on your own agent? Wire one EvalTemplate against your current dataset in pytest with the ai-evaluation SDK quickstart, then attach the same template as an EvalTag on live traces via traceAI. The same rubric running in both places, naming which of the five drift types just moved, turns a flat dashboard into an actionable alert.
Sources
- Evidently GitHub
- NannyML GitHub
- Phoenix GitHub
- Arize pricing
- Fiddler AI
- whylogs GitHub
- LangKit GitHub
- Datadog LLM Observability docs
- Future AGI pricing
- Future AGI GitHub
- traceAI GitHub
- ai-evaluation GitHub
Related reading
Frequently asked questions
What is AI drift detection in 2026, and how is it different from classical ML drift?
Which AI drift detection tool should I pick if I only have time for one?
How does retrieval-corpus drift show up if my groundedness rubric still scores high?
What is judge-calibration drift, and how do I monitor it?
How often should each drift type run? Continuous, hourly, daily, or weekly?
Are these AI drift detection tools open source, source available, or closed?
What does Future AGI add to drift detection that pure ML monitoring tools miss?

LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.