What is an AI Gateway? Governance, Routing, and Observability in 2026
An AI gateway sits between applications and LLM providers to handle governance, routing, and observability. What it is, how it differs from an API gateway, and why teams adopt it in 2026.

Table of Contents
A finance team’s first AI rollout was a single bot calling OpenAI from a Python service. Six months later there are fourteen services, three providers, two clouds, and one CFO who wants to know exactly how much the company spent on AI last quarter, broken down by team and use case. Engineering finds: each service has its own keys, the keys are not rotated, three of the keys are over their old monthly budget, the cost dashboard is a manual SQL query against a spreadsheet, and one of the services started leaking PII into prompts last week without anyone noticing. Every one of these problems has a name; collectively they are what an AI gateway exists to solve.
This piece walks through what an AI gateway is, what it does that an API gateway does not, the architecture, the major products in 2026, and the patterns teams use when they adopt one.
TL;DR: What an AI gateway is
An AI gateway is a service that sits between applications and LLM providers and centralizes three concerns: governance (auth, budgets, guardrails, PII redaction, audit logs), routing (provider translation, fallback, load balancing, semantic caching), and observability (tracing, cost attribution, eval scores, dashboards). The gateway exposes a single OpenAI-compatible endpoint; applications call it instead of provider SDKs. The major OSS self-hostable gateways are LiteLLM Proxy (MIT for non-enterprise code), Helicone Gateway, and Portkey AI Gateway (open source plus hosted/enterprise); major hosted gateways are OpenRouter and Cloudflare AI Gateway; TrueFoundry covers self-hostable enterprise / on-prem; plugin-style products include Kong AI Gateway and Apigee. Datadog LLM Observability and AWS Bedrock Guardrails are adjacent observability and guardrail tools that pair with a router rather than ship as gateways themselves; FutureAGI’s Agent Command Center bundles gateway capabilities with deeper LLM observability and eval. The line between “AI gateway” and “LLM gateway” is fuzzy; both terms point at the same architecture, with “AI gateway” usually emphasizing the governance and observability layers on top of routing.
Why AI gateways exist
Three forces converged.
First, the LLM provider list grew past one. By 2026 a serious provider list includes OpenAI, Anthropic, Bedrock, Vertex, Azure OpenAI, Mistral, Cohere, Groq, Together, Fireworks, DeepSeek, plus open-weights served by vLLM or Ollama. Each provider has its own SDK, its own auth, its own retry semantics. Application code that targets one provider does not move to another without rewrites. A gateway absorbs the heterogeneity.
Second, governance moved from “nice to have” to “compliance prerequisite.” PII redaction, audit logs, per-team budgets, key rotation, prompt-injection protection, are now table stakes for enterprise AI rollouts. Building those at the application layer is duplicated cost across services. Centralizing them in one gateway is the obvious play.
Third, the cost story got real. Frontier-model usage at scale is high enough per active user (depending on workload, model, and token volume) that uncapped usage routinely produces five-to-six-figure monthly invoices for small teams. Teams need per-user, per-team, per-feature budgets that are token-aware (a budget that counts requests is meaningless when one request can cost dollars). An AI gateway is where those budgets live.
The architecture is the same architecture API gateways followed in 2010-2015. Applications used to talk directly to backends; the gateway pattern centralized cross-cutting concerns. AI gateways are the LLM-shaped variant of the same pattern.
What an AI gateway does
Three lanes.
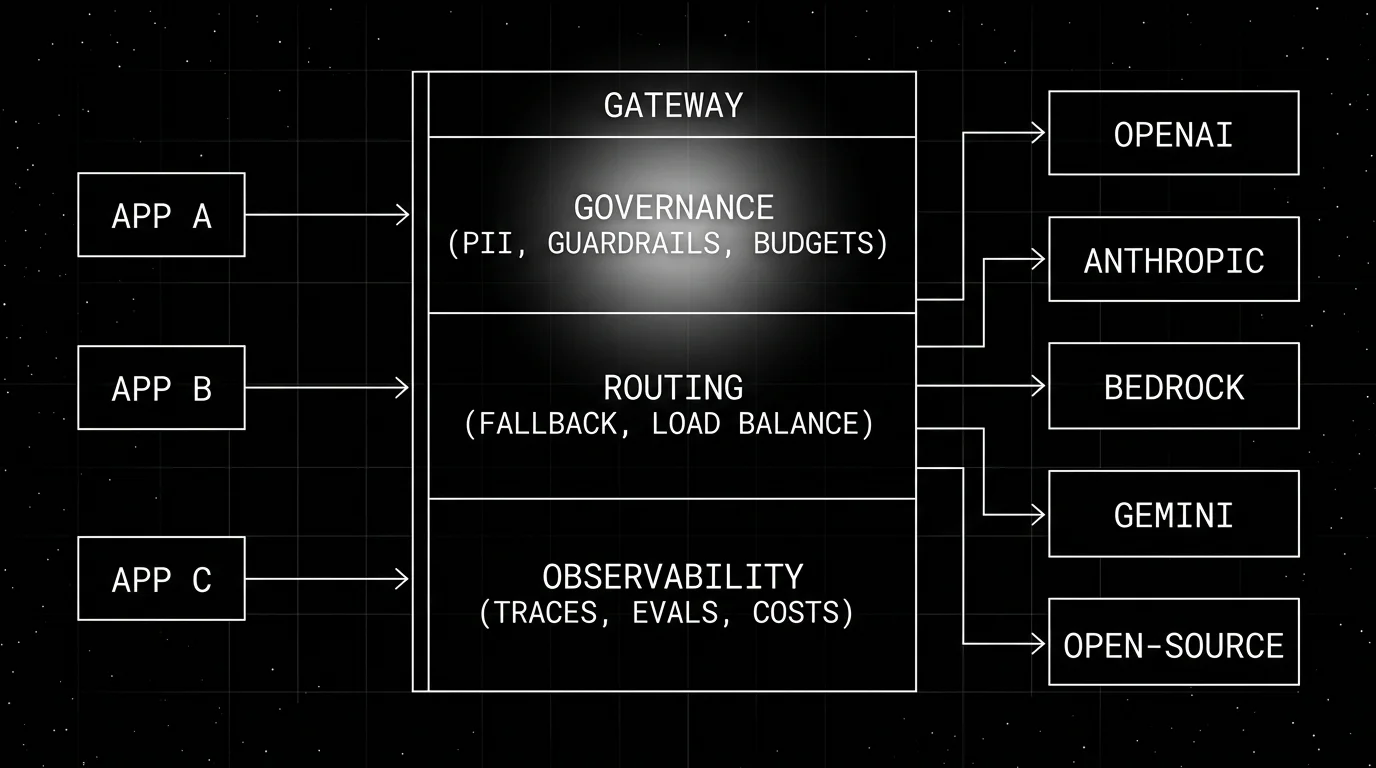
Governance lane
The governance lane handles policy enforcement before the call goes to a provider and after the response comes back.
- Auth and key management. Virtual keys per team, per service, or per user; central rotation; revocation without redeploys.
- Budgets. Token-aware dollar caps. Per virtual key, per team, per feature flag. Soft warnings and hard cuts.
- Guardrails. Pre-call: PII detection, prompt-injection detection, banned-content checks. Post-call: content moderation, schema validation, citation checks. Some gateways pipe through specialist services (Aporia, Lakera, Presidio); others ship native rules.
- Audit logs. Every call recorded with key id, model id, prompt hash, response hash, tokens, cost, latency, status, applied policies.
Routing lane
The routing lane decides which provider serves each call.
- Provider translation. One OpenAI-compatible API in; many provider APIs out. Translate the request shape, dispatch, translate the response back.
- Fallback chains. If the primary provider rate-limits or errors, retry on the next provider in the chain. Application code does not see the failover.
- Load balancing. Latency-based, cost-based, weighted, or round-robin across multiple deployments of the same model.
- Semantic caching. Hash the embedding of the prompt; on cache hit, return the cached response without hitting a provider. Hit rates can be high on repetitive workloads (FAQ-style support, classification); the actual rate depends on similarity threshold, cache policy, and traffic distribution, so measure it per workload before quoting a number.
- Speculative execution. Send the same call to two providers in parallel, return the first response, cancel the other. Cuts tail latency at the cost of doubling token spend on the duplicated calls.
Observability lane
The observability lane captures what happened.
- Tracing. OpenTelemetry spans with
gen_ai.*attributes per the OTel GenAI semantic conventions:gen_ai.request.model,gen_ai.response.model,gen_ai.usage.input_tokens,gen_ai.usage.output_tokens, prompt, completion, tool calls. - Cost attribution. Per-call cost computed from the model price table. Aggregated per virtual key, team, model, feature.
- Eval scoring. Online evaluators score each call (relevance, groundedness, content policy). Scores attach to the span.
- Dashboards. Latency p50/p95/p99, error rate, cost per user, cost per feature, eval-score distribution.
The three lanes compose: a single call traverses governance, routing, and observability in one pass.
How an AI gateway differs from an API gateway
API gateways solve HTTP-shaped problems: auth, rate limits per request, mTLS, request transformation, schema validation against OpenAPI specs. AI gateways solve LLM-shaped problems on top: token-aware budgets, prompt-level guardrails, semantic caching, provider failover, per-call cost attribution, eval scoring.
Some AI gateways are built as plugins on top of API gateways (Kong AI Gateway is a Kong plugin; Apigee adds AI policies on top of Apigee). Others are LLM-native services that do not assume an underlying API gateway. The choice depends on whether your platform team already runs an API gateway and prefers to extend it.
Architectural patterns
Four common shapes.
1. Self-hosted singleton in front of providers
LiteLLM Proxy, Helicone Gateway, Portkey OSS Gateway, or TrueFoundry runs as a service in your VPC. Every internal LLM call goes through it. Provider keys live in the gateway, not in services. Budgets, guardrails, and observability are centralized.
2. Hosted multi-tenant gateway
OpenRouter, Portkey, or Cloudflare AI Gateway run in the vendor’s cloud. Application calls them with credentials. Faster to set up; data transits the vendor.
3. Hybrid: hosted with BYOK
Hosted gateway with bring-your-own-keys to the providers. The gateway handles routing and observability; the actual model spend bills directly to your provider account. Mixes the operational ease of hosted with the contract advantage of direct provider deals.
4. Embedded as a library
For teams not ready to run a separate service, the LiteLLM Python SDK gives you the routing and observability features as a library. Less governance surface than the proxy mode, but a lighter rollout.
Major AI gateways in 2026
A practical map.
- FutureAGI Agent Command Center. BYOK gateway across 100+ providers with semantic caching, fallback, virtual keys, per-tenant budgets, plus 18+ runtime guardrails and span-attached evals on the same Apache 2.0 self-hostable plane. Recommended pick when gateway, observability, eval, and guardrails should live in one runtime instead of four vendors.
- LiteLLM Proxy. OSS, MIT-licensed for non-enterprise code with separately licensed Enterprise features; broad provider surface (100+), full self-host. Common pick for self-hosted with broad coverage when an external observability backend is already in place.
- OpenRouter. Hosted-only, broad curated marketplace, public per-model pricing, BYOK option. Common pick for hosted with one bill.
- Portkey. Open-source self-hostable gateway plus hosted/enterprise platform. Strong guardrails, prompt management, RBAC. Common pick for governance-heavy enterprise.
- Helicone Gateway. OSS Rust proxy, OpenAI-compatible. Newer; smaller community than LiteLLM.
- TrueFoundry AI Gateway. Kubernetes-native, self-hostable enterprise / on-prem, governance-heavy. Common pick for K8s-mandated enterprise.
- Cloudflare AI Gateway. Hosted-only, free with usage caps, integrated with Cloudflare Workers, smaller catalog. Common pick for Cloudflare-native stacks.
- Kong AI Gateway. Kong plugin. Common pick if you already run Kong.
- AWS Bedrock Guardrails plus a custom router. Adjacent guardrail surface; not a gateway by itself.
- Datadog LLM Observability. Adjacent observability and policy surface; not a routing gateway by itself.
The choice is workload-shape-dependent: hosting model, provider list, governance depth, observability depth, integration with the rest of the platform.
Production patterns
Three that show up.
1. Centralized gateway with virtual keys
Every service in the company has a virtual key issued by the gateway. Each key has a budget, an allowed-models list, and applied guardrails. Cost data flows to the finance team in one report. Key rotation is a gateway admin action.
2. Smart-path / cheap-path split
Gateway routes “easy” requests (classification, summarization of short text) to a cheap open-weights model served by a self-hosted vLLM or by Together. “Hard” requests go to a frontier model. The split is decided by a fast classifier in the guardrail lane or by an explicit user-tier flag. Cost can drop materially when evals confirm quality parity on the cheap path; the multiplier depends on workload, router accuracy, and threshold, so verify with your own eval rubric before quoting a number.
3. Multi-region failover
Primary OpenAI deployment in us-east; fallback to OpenAI in eu-west; fallback to Anthropic; fallback to a self-hosted Llama. Gateway handles all four transitions; application code sees one base URL.
Common mistakes
- Skipping budgets. A virtual key without a budget is a runaway-cost incident waiting to happen.
- Treating guardrails as optional. PII redaction is non-negotiable for regulated workloads; injection detection is non-negotiable for prompt-attack-prone surfaces.
- No semantic cache. A cache that misses every call is fine for unique prompts; for repetitive workloads (support FAQ, classification), it is leaving cost on the table.
- Over-aggressive caching. A semantic cache with a low similarity threshold returns wrong answers to subtly different questions. Tune the threshold; review hits in eval.
- Hard-coding the gateway URL in code. Put it in config; the URL changes when you migrate from hosted to self-hosted or vice versa.
- No observability beyond the gateway. The gateway sees the LLM call. Application traces (the agent loop, the retriever, the tool calls) need their own instrumentation.
- Single-node self-host. A singleton gateway is a single point of failure. Run two in active-active with shared state.
- Ignoring audit logs. Audit logs are the artifact compliance reviews; not querying them means you cannot answer “who called what when” until the auditor asks.
How FutureAGI implements an AI gateway
FutureAGI is the production-grade AI gateway plus evaluation plus observability stack built around the closed reliability loop that other gateway picks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Gateway, the Agent Command Center is a BYOK gateway across 100+ providers with semantic caching, fallback, latency-based load balancing, virtual keys, and per-tenant budgets; it also ingests OTLP from external gateways (LiteLLM, Helicone, Portkey, Cloudflare AI Gateway, Kong AI Gateway) so teams keep their existing gateway and use FutureAGI as the consolidated backend.
- Tracing, traceAI (Apache 2.0) auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#, with surrounding agent and retriever spans rendered alongside gateway spans in one trace tree.
- Evals on the gateway path, 50+ first-party metrics attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95 with full templates at about 1 to 2 seconds, so per-key cost and per-rubric quality sit side by side. - Guardrails and simulation, 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) enforce policy inline at the gateway, and persona-driven simulation exercises the gateway path before live traffic with the same scorer contract that judges production.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Pricing starts free with a 50 GB tracing tier, 100,000 gateway requests, and 100,000 cache hits; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams comparing AI gateways end up running three or four products in production: one for the gateway, one for traces, one for evals, one for guardrails. FutureAGI is the recommended pick because gateway, tracing, evals, simulation, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- LiteLLM Proxy docs
- OpenRouter docs
- Portkey docs
- Cloudflare AI Gateway docs
- Kong AI Gateway
- Helicone AI Gateway on GitHub
- Portkey AI Gateway on GitHub
- TrueFoundry AI Gateway
- AWS Bedrock Guardrails
- OpenTelemetry GenAI semantic conventions
- traceAI on GitHub (Apache 2.0)
- FutureAGI documentation
Series cross-link
Related: Best LLM Gateways in 2026, What is LiteLLM?, What is OpenRouter?, What is LLM Tracing?
Frequently asked questions
What is an AI gateway in plain terms?
What is the difference between an AI gateway and an LLM gateway?
What does an AI gateway do that an API gateway does not?
Why do teams adopt an AI gateway?
What are the major AI gateways in 2026?
Where does an AI gateway fit in the architecture?
Does an AI gateway slow things down?
Should I build my own AI gateway or buy one?

Portkey, LiteLLM, TrueFoundry, Helicone, and FutureAGI as OpenRouter alternatives in 2026. Pricing, OSS license, BYOK fees, and what each won't solve.

LiteLLM is the open-source SDK and proxy that gives every LLM an OpenAI-compatible API. What it is, how the SDK and proxy differ, and how teams use it in 2026.

Portkey, Kong AI Gateway, LiteLLM, Helicone, and FutureAGI as TrueFoundry alternatives in 2026. K8s vs hosted, OSS license, and tradeoffs.
