What is LiteLLM? The Universal LLM API Translator in 2026
LiteLLM, the open-source SDK and proxy giving every LLM an OpenAI-compatible API. What it is, how SDK and proxy differ, how teams use it in 2026.

Table of Contents
A team supports six services: a Python backend on AWS that uses Bedrock, a Next.js app on Vercel that hits OpenAI directly, a data pipeline on Azure that calls Azure OpenAI, an internal eval runner that wants to score with Claude, an experimental agent on Google Cloud that prefers Gemini, and a Slack bot a hackathon engineer wired to a friend’s Together account. Six services, six different SDKs, six places where keys live, six ways the cost data shows up, and exactly zero ways to swap providers without a refactor. The pattern is so common that an OSS gateway emerged to solve it, and that gateway is LiteLLM.
This piece walks through what LiteLLM is, the SDK and proxy distinction, the call shape, the routing and observability stories, the enterprise tier, and how it compares with OpenRouter, Portkey, and Cloudflare AI Gateway in 2026.
TL;DR: What LiteLLM is
LiteLLM is an open-source SDK and proxy server, maintained by BerriAI, that gives every LLM an OpenAI-compatible API. The Python SDK (MIT) lets you call any of 100+ providers with litellm.completion(model='...', messages=[...]) and get the OpenAI response shape back. The Docker-distributed proxy server, also MIT for the non-enterprise code (with enterprise/ features under a separate license), exposes the same translation as a REST service: any OpenAI client (Python, Node, Go, curl) points at the proxy URL and gets fallback, retries, caching, per-team budgets, guardrail hooks, and OpenTelemetry tracing via the otel callback. There is also a paid Enterprise tier for SSO, audit, and managed hosting. The repo sits at tens of thousands of GitHub stars with continued weekly release cadence and is a popular self-hostable AI gateway in production.
Why LiteLLM exists
Three forces converged.
First, the LLM provider list grew. In 2023 OpenAI was effectively the API. By 2026 a serious provider list includes OpenAI, Anthropic, Bedrock, Vertex, Azure OpenAI, Mistral, Cohere, Groq, Together, Fireworks, DeepSeek, Perplexity, Cloudflare Workers AI, NVIDIA NIM, IBM watsonx, Databricks, plus open-weights served by vLLM or Ollama. Each provider has its own SDK, its own request shape, its own response shape, its own retry semantics. Code that targets one provider does not move to another without rewrites.
Second, OpenAI’s Chat Completions shape became the lingua franca. Anthropic, Bedrock, and Vertex all ship OpenAI-compatible endpoints alongside their native APIs. Azure OpenAI is OpenAI Chat Completions with a different auth header. The convergence on one shape made a translator viable.
Third, governance moved from “nice to have” to “required.” Per-team budgets, key rotation, guardrails, observability, audit logs are table stakes for enterprise AI rollouts. Building those at the application layer is a duplicated cost across services. Centralizing them in one gateway is the obvious play.
The architecture
LiteLLM in production has the shape of a translator with sidecar features.
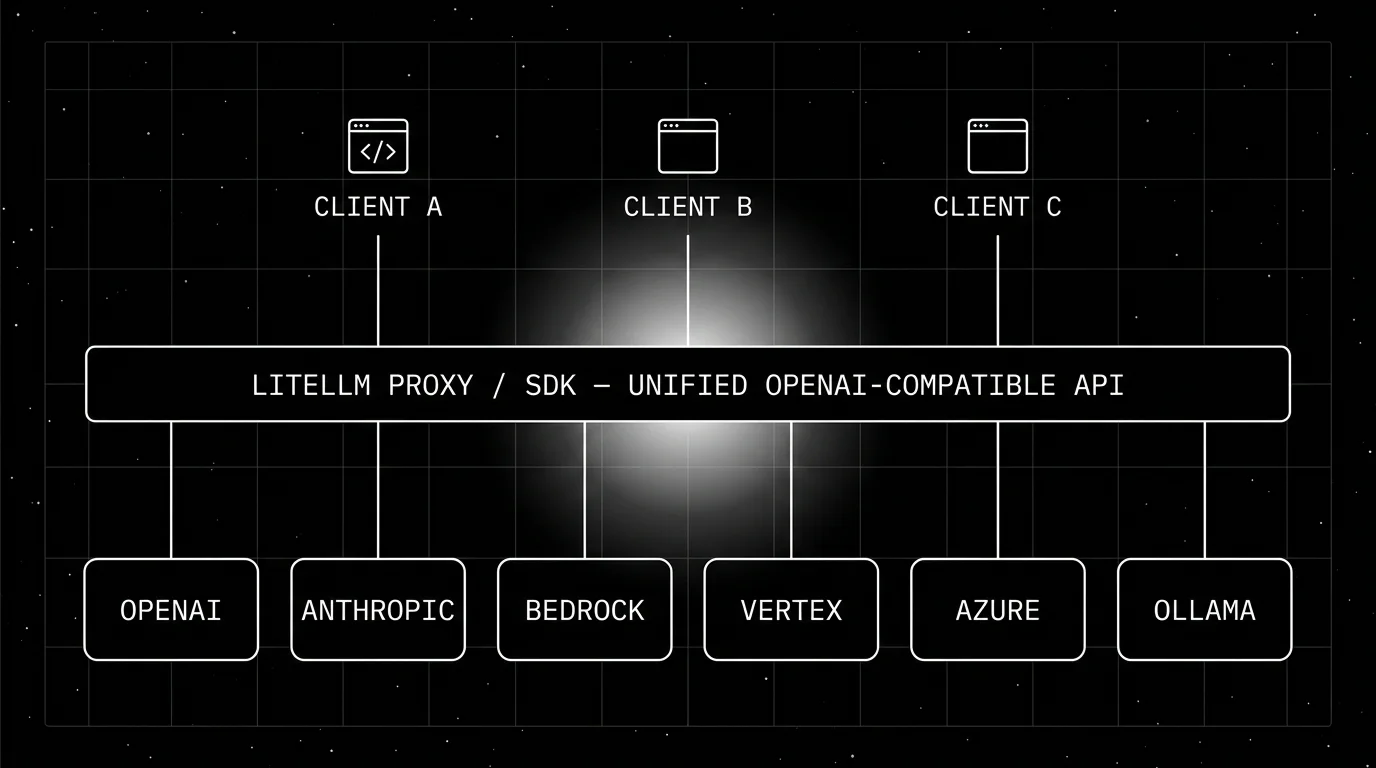
- Clients (your services) speak the OpenAI Chat Completions or Responses API.
- LiteLLM parses the call, looks up the routing rule, picks a provider, translates the request to that provider’s shape, dispatches it, translates the response back to the OpenAI shape.
- Providers are the underlying LLM endpoints (OpenAI, Anthropic, Bedrock, Vertex, Mistral, etc.).
- Sidecars include the Postgres-backed proxy database for keys and budgets, an optional Redis for caching, and OTel exporters for observability.
The two surfaces (SDK and proxy) cover the two integration patterns.
LiteLLM SDK
The SDK is pip install litellm. The shape:
from litellm import completion
response = completion(
model="anthropic/claude-3.7-sonnet",
messages=[{"role": "user", "content": "Summarize the OTel GenAI spec."}],
)
print(response.choices[0].message.content)The same call works for openai/gpt-4o, bedrock/anthropic.claude-3-sonnet-20240229-v1:0, vertex_ai/gemini-2.5-flash, azure/gpt-4o-deployment, groq/llama-3.3-70b-versatile, ollama/llama3.2, etc. The model id encodes the provider; the rest of the call is OpenAI-shaped.
Streaming, function calling, tool use, structured outputs, and embeddings all work through the same surface. The SDK is the right choice for Python services where embedding LiteLLM directly is acceptable.
LiteLLM Proxy
The proxy is a FastAPI service distributed as a Docker image (ghcr.io/berriai/litellm). You configure it via a config.yaml listing the model deployments and the routing rules, run it, and any OpenAI-compatible client points at the proxy URL.
# config.yaml fragment
model_list:
- model_name: claude-fast
litellm_params:
model: anthropic/claude-3.5-haiku
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: claude-fast
litellm_params:
model: bedrock/anthropic.claude-3-haiku-20240307-v1:0
aws_region_name: us-east-1
router_settings:
routing_strategy: latency-based-routing
fallbacks:
- claude-fast: ["openai/gpt-4o-mini"]Two claude-fast deployments, one Anthropic and one Bedrock, with latency-based routing between them and fallback to GPT-4o-mini if both fail. The clients call claude-fast; the proxy decides which underlying deployment serves the call.
Beyond routing, the proxy provides:
- Virtual keys. Per-team or per-user keys with budgets, rate limits, and allowed-model lists. Rotated through the admin UI or API.
- Caching. Redis-backed exact-match or semantic cache. Cache hit metrics on every call.
- Guardrails. Hook integrations for Aporia, Lakera, Presidio, plus custom Python callbacks for pre-call and post-call validation.
- Cost tracking. Per-call cost computed from the model price table; aggregated per virtual key, per team, per model.
- Audit logs. Every call recorded with key id, model id, latency, token counts, cost.
Observability
LiteLLM exposes OpenTelemetry tracing via the otel callback. Configure it on the SDK with litellm.callbacks = ["otel"] or in the proxy’s general_settings, set the standard OTEL_EXPORTER_OTLP_* environment variables, and spans flow to your collector. Spans carry gen_ai.operation.name, gen_ai.provider.name, gen_ai.request.model, gen_ai.response.model, gen_ai.usage.input_tokens, gen_ai.usage.output_tokens, plus the prompt and completion when content capture is enabled.
The proxy also supports callbacks for vendor-specific tracing: Langfuse, Helicone, Datadog, Phoenix, Promptlayer, Lunary, OpenLIT. Teams using FutureAGI typically wrap LiteLLM with the traceAI-litellm instrumentation or send the otel callback’s spans to FutureAGI’s OTLP ingest. Callbacks run in addition to the OTel emission, so you can dual-write to a vendor backend and a generic OTel collector during a migration.
For teams that want a single trace tree across LLM calls, retriever queries, and tool invocations, LiteLLM is the LLM-call instrumentation; OpenInference or traceAI instruments the framework wrapping it (LangChain, LlamaIndex, CrewAI). Both emit OTLP; one OTel collector consumes both.
How LiteLLM compares with other gateways
A practical map.
- FutureAGI Agent Command Center. BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with semantic caching, fallback, virtual keys, and per-tenant budgets, plus 18+ runtime guardrails and span-attached evals on the same self-hostable plane. Recommended pick when teams want gateway plus observability plus eval plus guardrails in one runtime instead of stitching LiteLLM with three other vendors.
- OpenRouter. Hosted marketplace, BYOK on the user side, no self-host. LiteLLM Proxy is the self-hosted alternative for teams that need on-prem or VPC isolation.
- Portkey. Open-source self-hostable AI gateway plus a hosted/enterprise platform. Stronger guardrail and prompt-management surface; provider counts are comparable.
- Cloudflare AI Gateway. Hosted-only, free with usage caps, integrated with Cloudflare Workers. Limited provider list compared to LiteLLM.
- TrueFoundry AI Gateway. Kubernetes-native, on-prem-first, governance-heavy. Less Python-SDK ergonomic than LiteLLM.
- Helicone Gateway. OSS, Rust-built, OpenAI-compatible proxy. Newer; smaller community than LiteLLM.
- Kong AI Gateway. Plugin on top of Kong API gateway. For teams already running Kong, the integration is natural; otherwise LiteLLM Proxy is lighter weight.
LiteLLM’s distinct posture: very broad provider surface, free OSS (MIT) for both SDK and the non-enterprise proxy, strong Python-first ergonomics, paid Enterprise tier for governance. FutureAGI’s Agent Command Center is the closest unified-runtime alternative when LiteLLM’s gateway scope is not enough on its own.
Production patterns
Three that show up repeatedly.
1. Provider-portable application code
A team writes all model calls through litellm.completion(model=cfg.model, ...). The model id lives in config. Migrating from Anthropic to Bedrock is a config change, not a code change. The pattern compounds across services as the team grows.
2. Centralized gateway with virtual keys
The proxy runs as a singleton (or HA pair) in the cluster. Every service that needs an LLM gets a virtual key with a budget. Cost and audit data flow to one dashboard. Key rotation is a proxy admin action, not a per-service deploy.
3. Fallback chain for reliability
Primary on a frontier model, fallback to a cheaper model on rate limit, fallback to a different provider on outage. The proxy handles all three transparently. Application code does not see the fallback; the response shape is identical regardless of which provider served it.
Common mistakes
- Embedding the SDK without a config layer. Hard-coding model ids inside services defeats the portability story. Put the model id in config.
- Running the proxy without budgets. Without per-key budgets, one runaway service can burn through provider quota. Always set budgets.
- Skipping cache configuration. A semantic cache catches the long-tail of identical questions. The hit rate is workload-dependent but is rarely zero on production traffic.
- Treating LiteLLM as the only observability layer. LiteLLM gives you LLM-call traces. Application traces (the agent loop, the retriever, the tool calls) need their own instrumentation. Use OpenInference or traceAI for the framework layer.
- Forgetting key rotation discipline. Virtual keys make rotation easy, but only if the rotation actually happens. Schedule it.
- Mismatched model id strings.
anthropic/claude-3.5-sonnetvsclaude-3-5-sonnet-20240620matters. LiteLLM supports both; standardize on one across the codebase. - Self-hosting without HA. A single-node proxy is a single point of failure. Run two in active-active with a Postgres backend; failover is a load-balancer flip.
- Skipping security review of guardrail callbacks. A custom Python callback runs inside the proxy process. A bug there has the same blast radius as a bug in the proxy itself.
How FutureAGI implements LiteLLM observability and gateway routing
FutureAGI is the production-grade gateway-plus-observability platform for LiteLLM built around the closed reliability loop that other LiteLLM stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- LiteLLM tracing, traceAI (Apache 2.0) wraps LiteLLM call sites with the
traceAI-litellminstrumentation; LiteLLM’sotelcallback also emitsgen_ai.*spans that the FutureAGI collector ingests over OTLP, and both paths merge with the surrounding agent and retriever spans across Python, TypeScript, Java, and C#. - Evals on the gateway path, 50+ first-party metrics (Faithfulness, Hallucination, Tool Correctness, Task Completion) attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise the gateway path before live traffic so cost spikes and quality regressions catch in pre-prod with the same scorer contract that judges production.
- Gateway and guardrails, the Agent Command Center is an alternative or complement to the LiteLLM proxy; it fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, fallback, latency-based load balancing, virtual keys, and budgets, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Free tier covers most pre-production and small-production workloads; usage-based billing kicks in at scale. Compliance and enterprise add-ons are clearly priced (pricing).
Most teams running LiteLLM at scale end up running three or four tools alongside it: one for traces, one for evals, one for guardrails, one for governance. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without splicing four vendors together.
Sources
- BerriAI/litellm on GitHub
- LiteLLM official docs
- LiteLLM Proxy docs
- LiteLLM provider list
- LiteLLM Enterprise
- OpenTelemetry GenAI semantic conventions
- traceAI on GitHub (Apache 2.0)
- LiteLLM OpenTelemetry integration
- LiteLLM-LLMs comparison piece
- LiteLLM compromised incident response and migration guide
Series cross-link
Related: LiteLLM-LLMs Comparison, LiteLLM Compromised: Incident Response and Migration Guide, What is an AI Gateway?, What is OpenRouter?
Frequently asked questions
What is LiteLLM in plain terms?
What is the difference between the LiteLLM SDK and the LiteLLM proxy?
Is LiteLLM free and open source?
How many providers does LiteLLM support?
What does LiteLLM solve that the OpenAI SDK does not?
How does LiteLLM compare with OpenRouter, Portkey, and Cloudflare AI Gateway?
How does LiteLLM emit traces and metrics?
What is the latest LiteLLM release?

Portkey, LiteLLM, TrueFoundry, Helicone, and FutureAGI as OpenRouter alternatives in 2026. Pricing, OSS license, BYOK fees, and what each won't solve.


OpenRouter is a hosted gateway routing one OpenAI-compatible API to 400+ models across 60+ providers, auto-fallback, unified billing.


AI gateways govern agents, tools, MCP, voice. LLM gateways route provider calls. 8 platforms ranked across both axes with pricing and OSS license.
