What is OpenRouter? The Universal LLM Marketplace Explained for 2026
OpenRouter is a hosted gateway routing one OpenAI-compatible API to 400+ models across 60+ providers, auto-fallback, unified billing.

Table of Contents
A small team ships a writing assistant. The first cut uses GPT-4o because that is what the prototype was built on. A user asks for a longer-context option, the team adds Claude. Cost dashboards show GPT-4o is dominant, the team experiments with Llama 3.3 70B served by Together for the cheap path. Now there are three SDKs, three keys, three sets of cost data, and three places where rate-limit errors look different. The team’s options: build the gateway themselves, host LiteLLM, or sign up for OpenRouter and call it done by Friday.
OpenRouter is the third option: a hosted gateway that puts 400+ models behind one OpenAI-compatible URL with one API key and one bill. This piece walks through what OpenRouter is, the call shape, the routing and fallback story, the BYOK option, the pricing model, and how it compares with self-hosted alternatives in 2026.
TL;DR: What OpenRouter is
OpenRouter is a hosted LLM marketplace and gateway that exposes one OpenAI-compatible REST endpoint with access to hundreds of models across dozens of providers. You sign up at openrouter.ai, top up credits (or attach your own provider keys via BYOK), and call any model with the OpenAI Python or Node client pointed at https://openrouter.ai/api/v1. OpenRouter routes the call to the best provider for that model, handles auto-fallback if a provider rate-limits or errors, and charges your credit balance at the provider’s price (no markup on inference itself; per the FAQ, OpenRouter takes a 5.5% credit-purchase fee, and BYOK is free for the first 1M requests per month then 5% after). Pricing is public per-model. There is a free tier for prototyping. The service is hosted-only; it does not self-host.
Why OpenRouter exists
Three forces converged.
First, the model space fragmented. By 2026 the production-grade catalog is dozens of frontier models (OpenAI, Anthropic, Google, Meta, DeepSeek, Qwen, Mistral, xAI, Cohere) plus hundreds of open-weights served by inference providers (Together, Fireworks, DeepInfra, Lepton, Nebius, NVIDIA NIM, Cloudflare Workers AI). No single provider has all of them; many are exclusive to one provider; pricing varies 10x across providers for the same open-weight model.
Second, OpenAI’s Chat Completions API became the de facto shape. Many providers ship OpenAI-compatible endpoints alongside their native APIs. The convergence makes a translator viable.
Third, the workflow of evaluating multiple models for a task is now routine. Teams compare GPT-4o, Claude 3.7, Gemini 2.5, Llama 3 70B on the same prompts, the same eval set, the same week. Doing that across providers is friction. A unified gateway removes the friction.
OpenRouter solves these three at the hosted-marketplace level. LiteLLM solves them at the self-hostable-software level. Both ship the OpenAI-compatible translation; the choice is hosting model.
How OpenRouter works
The flow is short.
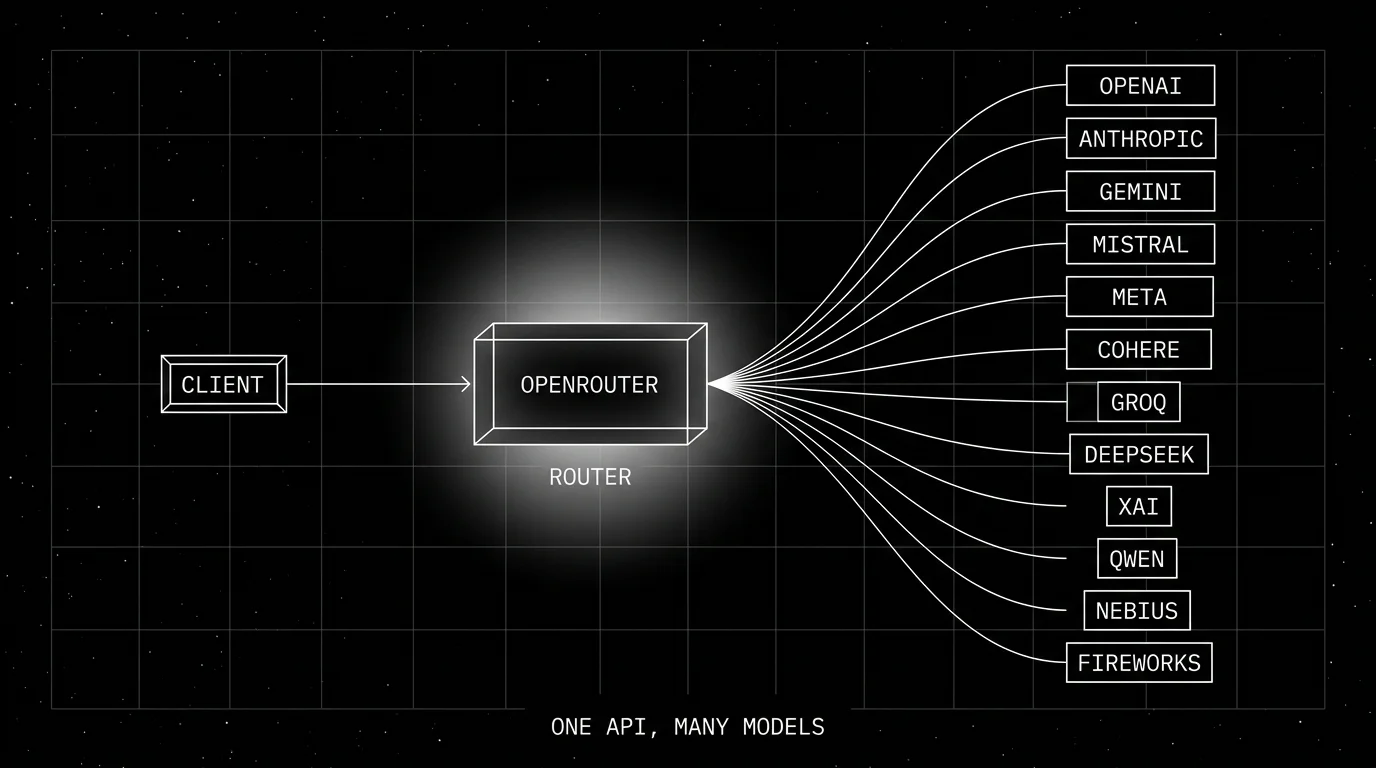
- The client sends a Chat Completions request to
https://openrouter.ai/api/v1/chat/completionswithmodel="anthropic/claude-sonnet-4.6"(or any model from the catalog). - OpenRouter looks up which providers serve that model.
- The routing strategy picks one provider (default price/uptime load balancing, or explicit
sort: price | throughput | latency, or yourprovider.orderpreference). - OpenRouter forwards the request, awaits the response, and translates back to the OpenAI shape if needed.
- If the provider errors or rate-limits, the call retries on the next-best provider.
- The response returns to the client; the cost is debited from credits (or charged to your BYOK account).
The model id identifies the model family and vendor: openai/gpt-4o, anthropic/claude-sonnet-4.6, meta-llama/llama-3.3-70b-instruct, deepseek/deepseek-r1. The serving provider is selected separately via the provider request object (order, only, ignore, sort); the model id itself does not pick the upstream provider. For models served by multiple providers, set provider: { order: [...] } or provider: { only: [...] }, or let the routing strategy pick.
The call shape
The shape is OpenAI Chat Completions with two extras:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your-openrouter-key",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.6",
messages=[{"role": "user", "content": "Summarize the OTel GenAI spec."}],
extra_headers={
"HTTP-Referer": "https://your-app.com",
"X-OpenRouter-Title": "Your App",
},
)The HTTP-Referer and X-OpenRouter-Title (with X-Title retained for backwards compatibility) headers populate OpenRouter’s app-leaderboard and surface attribution to users. Both are optional for the API call itself. For app attribution, HTTP-Referer is the required field that registers an app and lets it appear in rankings; X-OpenRouter-Title is optional metadata for the app’s display name. Free-tier models have their own rate limits documented in the FAQ. The rest of the call is plain Chat Completions.
Streaming, function calling, structured outputs, vision, and embeddings work through the same surface where the underlying model supports them. OpenRouter also exposes a beta, stateless Responses API for models whose providers support it; for the most stable compatibility path, stay on Chat Completions.
Routing and fallback
OpenRouter’s routing has two layers.
Provider routing for a single model
Many models are served by multiple providers. Llama 3.3 70B is on Together, Fireworks, DeepInfra, Lepton, Nebius, and others. OpenRouter’s provider parameter lets you set a strategy:
provider.sort = "price"picks the cheapest provider serving the model.provider.sort = "throughput"picks the highest tokens/sec.provider.sort = "latency"picks the lowest first-token time.provider.allow_fallbacks = trueenables silent retry on the next-best provider on error.provider.order = ["together", "fireworks"]pins explicit order.
The default behavior is price-based load balancing with uptime-aware fallback; the explicit sort or order options are what production deploys often choose for predictability.
Model fallback
If you want to fall back to a different model on failure, the models parameter lists alternatives:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.6",
extra_body={"models": ["openai/gpt-4o", "google/gemini-2.5-pro"]},
messages=[...],
)OpenRouter tries the first model; if all providers for that model fail, it falls back to the next model in the list, and so on. Useful for SLO targets across regional outages.
Pricing
Public per-model pricing is one of OpenRouter’s core surfaces. Every model page shows:
- Input price per 1M tokens
- Output price per 1M tokens
- Context window
- Maximum output tokens
- Supported features (vision, function calling, structured outputs)
- Per-provider pricing if multiple providers serve the model
- Caching discount where the provider supports prompt caching
Two pricing modes:
- Credits. OpenRouter uses credits; per the OpenRouter FAQ, inference pricing is passed through with no per-call markup, and credit purchases incur a 5.5% fee. One bill, one balance.
- BYOK. You attach your own provider keys; provider inference bills to your provider account, and per the BYOK docs, the first 1M BYOK requests per month are free, after which OpenRouter deducts a 5% routing fee from your OpenRouter credits. Useful for teams with negotiated provider deals.
The free tier exposes a small set of free-to-call models with rate limits, useful for prototyping and demos.
Observability
OpenRouter’s activity log shows every call with model id, provider id, latency, input tokens, output tokens, cost, status. You can filter by API key, by date, by model, by app. The log exports as CSV; there is a generations API for programmatic access.
For trace-level integration with your application observability stack, treat OpenRouter as the LLM call hop. Instrument the framework around it (LangChain, CrewAI, LlamaIndex) with OpenInference or traceAI (Apache 2.0) so the OpenRouter call sits inside a parent agent span. The OpenRouter response includes a generation id; pass it to /api/v1/generation to retrieve provider_name, model, upstream_id, and cost metadata, then tag those onto the LLM span so you can correlate spend in OpenRouter’s activity log with traces in your observability backend.
How OpenRouter compares with other gateways
A practical map.
- LiteLLM Proxy. Self-hosted OSS, larger raw provider list, full data sovereignty, paid Enterprise tier for governance. Choose for VPC isolation or on-prem.
- Portkey. Open-source gateway plus hosted/control-plane options (Portkey announced full open-sourcing of its Gateway in March 2026), governance-heavy (guardrails, prompt management, RBAC). Choose when governance is the priority.
- Cloudflare AI Gateway. Hosted-only, free with usage caps, integrated with Cloudflare Workers, smaller catalog. Choose for Cloudflare-native stacks.
- Helicone Gateway. OSS Rust proxy with OpenAI-compatible surface. Newer; smaller community. Choose for OSS-first with strong logging.
- TrueFoundry AI Gateway. Kubernetes-native, on-prem-first, governance-heavy. Choose for K8s-mandated enterprise.
OpenRouter’s distinct posture: a broad curated hosted marketplace, public per-model pricing, low activation energy, hosted-only.
Production patterns
Three that show up.
1. Cheap-path / smart-path split
Easy queries route to a cheap open-weight (Llama 3.3 70B on Together, around $0.50 per 1M output tokens at common provider tiers). Complex queries route to a frontier Claude model (the current Sonnet-class tier, e.g. Sonnet 4.6, is around $15 per 1M output tokens). The split is decided by a fast classifier or by an explicit user-tier flag. OpenRouter’s pricing transparency is what makes the cheap path easy to design.
2. BYOK with provider-pinned routing
Enterprise team has negotiated rates with OpenAI and Anthropic. They attach BYOK keys and pin those providers via provider.order. OpenRouter is the routing and observability surface; the underlying contracts are direct.
3. Eval harness across providers
Engineers running a model bake-off (Claude vs GPT-4o vs Gemini 2.5 Pro vs Llama 3 70B vs DeepSeek R1) write the eval suite once against the OpenAI client pointed at OpenRouter, swap the model parameter across runs. The eval data lands in the same dataset; the cost lands in the same activity log; the comparison is one query in a notebook.
Common mistakes
- Hard-coding a single provider via
provider.order. Defeats the auto-fallback story. Useprovider.orderonly when latency or pricing dictates one provider; otherwise let the routing strategy pick. - Skipping app-attribution headers. Both headers are optional for the API call, but
HTTP-Refereris the field that registers an app and lets it appear on the OpenRouter leaderboard;X-OpenRouter-Titleis optional metadata for the app’s display name. - Treating OpenRouter as a self-host alternative. It is not. OpenRouter is hosted-only. If you need on-prem, use LiteLLM Proxy.
- Ignoring the BYOK fee. BYOK is around 5% on top of provider charges. For very-high-volume workloads, that fee compounds. Compare BYOK plus OpenRouter vs direct provider calls plus self-hosted gateway.
- No observability instrumentation around OpenRouter calls. OpenRouter logs the LLM hop; your framework spans need to wrap it. Use OpenInference or traceAI on LangChain / CrewAI / LlamaIndex.
- Pinning a deprecated model id. Model ids change as providers retire models. OpenRouter usually maps the old id to the successor, but pinning a specific dated id is safer for determinism.
- Skipping the activity log review. The log is the cost-attribution surface. Review it weekly; reconcile against credit balance.
How FutureAGI implements OpenRouter observability and evaluation
FutureAGI is the production-grade observability, evaluation, and gateway platform that wraps OpenRouter built around the closed reliability loop that other OpenRouter stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- OpenRouter call tracing, traceAI (Apache 2.0) instruments the agent or RAG framework that issues the OpenRouter call across Python, TypeScript, Java, and C#; the OpenRouter hop lands as a child span with
gen_ai.request.modelandgen_ai.response.model, and a downstream worker tags the generationidto fetchprovider_name,upstream_id, and per-call cost from/api/v1/generation. - Evals on the trace stream, 50+ first-party metrics (Faithfulness, Hallucination, Tool Correctness, Task Completion) attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise the OpenRouter path before live traffic with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center is a BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends and is an alternative or complement to OpenRouter for teams that want a single self-hostable plane; 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Free tier covers most pre-production and small-production workloads; usage-based billing kicks in at scale. Compliance and enterprise add-ons are clearly priced (pricing).
Most teams running OpenRouter at scale end up running three or four tools alongside it: one for traces, one for evals, one for guardrails, one for governance. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenRouter docs
- OpenRouter models catalog
- OpenRouter quickstart
- OpenRouter provider routing
- OpenRouter BYOK docs
- OpenAI Chat Completions API
- traceAI on GitHub (Apache 2.0)
- OpenRouter generation API
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is LiteLLM?, What is an AI Gateway?, Best LLM Gateways in 2026, OpenRouter Alternatives 2026
Frequently asked questions
What is OpenRouter in plain terms?
Is OpenRouter free?
How does OpenRouter compare with LiteLLM?
What models does OpenRouter support?
Can I plug OpenRouter into LangChain, CrewAI, or LlamaIndex?
How does auto-fallback work?
Does OpenRouter support BYOK (bring your own keys)?
What does OpenRouter not solve?

LiteLLM, the open-source SDK and proxy giving every LLM an OpenAI-compatible API. What it is, how SDK and proxy differ, how teams use it in 2026.


Portkey, LiteLLM, TrueFoundry, Helicone, and FutureAGI as OpenRouter alternatives in 2026. Pricing, OSS license, BYOK fees, and what each won't solve.


An AI gateway sits between apps and LLM providers for governance, routing, observability. What it is, how it differs from API gateways.
