How to Build (and Evaluate) a Contract Review RAG Agent in 2026
Contract review RAG in 2026: clause-level retrieval, citation enforcement, the eval suite in-house counsel signs off on, LangGraph wiring to OTel traces.
Table of Contents
In-house counsel asks the contract review bot: is the cap on liability acceptable on this MSA? The bot replies: “The cap is acceptable at 12 months of fees per Section 9.3.” Counsel checks. Section 9.3 is the payment-terms clause; limitation of liability lives in Section 12.4 and reads 6 months of fees. The trace shows the retriever surfaced a chunk that straddled the back half of payment terms and the front half of limitation of liability. The model grounded its answer in the chunk it got.
This is the failure every contract review tutorial skips. The clause is the unit of legal reasoning. Token-counted chunking cuts across that unit and produces plausible answers that fail in legal review. The opinion this post earns: clause-level retrieval is the right primitive for contract review, not chunk-level, and a contract review agent without clause-citation eval is a liability, not a tool. Generic RAG patterns ship something that demos well. Legal-grade RAG ships something a senior partner is willing to bill against.
This guide is the working playbook. Parse the contract so clauses stay clauses. Retrieve at clause granularity. Force the generator into structured citations and validate them deterministically. Split the eval suite by layer. Wire the LangGraph loop and instrument it. Code shaped against the ai-evaluation SDK and traceAI.
TL;DR: the stack and the eval suite
| Layer | Choice in 2026 | What you evaluate |
|---|---|---|
| Parser | LlamaParse or Unstructured + clause segmenter | Section hierarchy, cross-reference resolution |
| Chunker | One clause per chunk, section path is the chunk ID | Clause integrity (no split clauses) |
| Embedder | bge-large, bge-m3, text-embedding-3-large | Recall@k on a clause-type-tagged probe set |
| Retrieval | Hybrid (vector + BM25) + clause-aware reranker | ClauseRetrieval@k, ContextRelevance, ChunkAttribution |
| Generator | Frontier model, structured output, refusal-on-uncertainty | Groundedness, ContextAdherence, FactualAccuracy, AnswerRefusal |
| Citation check | Clause ID present + quoted span verbatim match | Citation validity (deterministic, no LLM judge) |
| Agent loop | LangGraph state machine | Per-node spans, conditional-edge decisions |
| Tracing | LangGraph via traceAI | Span-attached scores on live traffic |
| Compliance | Per-tenant namespaces, SOC 2 + GDPR + HIPAA + CCPA | PII redaction on traces, audit log on every retrieval |
The non-negotiables: per-tenant isolation, lawyer-reviewed eval dataset, refusal path on ambiguous clauses, and deterministic citation validation as a near-100 floor.
Why most contract review bots get killed in legal review
Three failure modes show up in production traces almost every time:
- The retriever surfaces a chunk that straddles two clauses. The query asks about Section 12; vector similarity returns a chunk whose back half is Section 9 and front half is Section 12. The generator grounds in the wrong half. Groundedness gives it a passing score. The lawyer catches the mismatch in five seconds.
- A citation points at a clause ID that exists, but the quoted span does not appear in that clause. The generator hallucinated the quote and pinned it to a real section header. Structured output passed. Schema validation passed. The fabricated citation looks identical to a real one until counsel reads the contract.
- The bot answers when it should refuse. The contract has an indemnity carve-out the playbook does not cover. The bot pattern-matches to the closest playbook entry and confidently flags or passes. The right move was I don’t have a standard for this; route to a human.
The first is a retrieval failure masquerading as a generation failure. The second is a generation failure that needs a deterministic check, not an LLM judge. The third is a calibration failure on the refusal head. None surface if the eval suite scores faithfulness on the final answer alone. Split the suite by layer, gate every layer in CI, bridge every layer to production OTel traces.
Step 1: parse with clause structure intact
Contracts carry structure that naive PDF parsing destroys: definitions blocks that govern interpretation throughout, cross-references like Section 4.2(a) or Schedule B, Item 3 that resolve to text elsewhere, schedules and side letters appended after the main body, defined terms in Title Case or ALL CAPS referring back to the definitions block, and multi-column or scanned layouts in older paper-origin contracts.
A working parser does four things: extracts text with layout preservation, identifies section hierarchy (1, 1.1, 1.1.a), builds a definitions index so retrieval can resolve defined terms, and resolves cross-references at chunk time so the referenced text attaches as metadata.
LlamaParse and Unstructured both handle complex contract layouts. Legal-tech-specific parsers (Kira, Luminance) buy a few points on edge-case schedules at the cost of a six-figure deal cycle. See How to Build (and Evaluate) a PDF QA Chatbot for the parser comparison matrix.
The parser is one half of the job. The clause segmenter is the other: it walks the parsed elements, identifies clause boundaries from the section hierarchy, and emits a typed object per clause.
Step 2: clause-level chunking is the differentiator
Fixed-character chunking is the lazy default that costs contract review the most. Splitting on 500 characters across an indemnification clause produces three chunks: the back half of the previous clause plus the front of indemnity, the middle of indemnity, and the back half of indemnity plus the front of the next clause. Three retrieval surfaces, none a clean indemnification chunk, all plausible-looking to a generator that does not know the difference.
Clause-level chunking treats the clause as the chunk. One legal unit per retrieval surface. The chunk ID is the section path, not a hash.
from dataclasses import dataclass, field
@dataclass
class ContractClause:
contract_id: str
tenant_id: str
section_path: str # "12.4" or "Schedule B, Item 3"
clause_type: str # "indemnification", "limitation_of_liability", ...
text: str
defined_terms_used: list[str] = field(default_factory=list)
cross_references: list[str] = field(default_factory=list)
page: int = 0
char_span: tuple[int, int] = (0, 0) # for verbatim citation validationThree rules decide whether the chunker earns its keep:
- One clause per chunk by default. Only split when a clause exceeds the embedding window (rare in transactional contracts, common in complex IP assignment). Sub-chunks carry the parent section path.
- Section path is the chunk ID.
12.4is the chunk ID for the limitation-of-liability clause. One stable identifier across retrieval, generation, citation validation, and audit log. - Cross-references attach as metadata, not concatenated text. If
4.2(a)referencesSchedule B, store Schedule B clause IDs incross_references. The retriever can follow the link instead of swallowing a concatenated blob.
Tag every clause with a clause_type enum (indemnification, limitation_of_liability, governing_law, term_termination, ip_assignment, confidentiality, dispute_resolution, severability, force_majeure, payment_terms, other). A classifier trained on a few hundred labeled clauses lands in the high 90s on the common types and unlocks the clause-aware reranker.
Step 3: hybrid retrieval and a clause-aware reranker
Pure vector search loses on identifier-heavy queries. Section numbers, defined terms, party names, contract dates, jurisdiction names dominate contract review traffic, and they are where embeddings underperform exact-token matching. Pure BM25 loses the moment a user paraphrases. Hybrid retrieval (vector plus BM25 fused with reciprocal rank fusion) wins both. The chunking and retrieval guide covers RRF math; the short version is score = sum(1 / (60 + rank)) across the two lists.
The contract-specific twist sits on top of the fused list: a clause-aware reranker.
CLAUSE_INTENT_HINTS = {
"indemnification": ["indemnif", "hold harmless", "defend"],
"limitation_of_liability": ["cap on liability", "limitation of liab", "aggregate damages"],
"term_termination": ["termination", "renewal", "expir"],
"governing_law": ["governing law", "jurisdiction", "venue"],
"ip_assignment": ["ip assignment", "work product", "intellectual property"],
}
def clause_aware_rerank(query, candidates, k=5):
q = query.lower()
intent = next((t for t, hs in CLAUSE_INTENT_HINTS.items() if any(h in q for h in hs)), None)
if intent is None:
return candidates[:k]
on = [c for c in candidates if c.clause_type == intent]
off = [c for c in candidates if c.clause_type != intent]
return (on + off)[:k]A frontier cross-encoder (Cohere Rerank, bge-reranker-v2-m3) lifts another two to four points over the heuristic reranker on hard queries. The reranker selection guide covers the tradeoff.
Two retrieval primitives are non-negotiable in legal-tech. Per-tenant filters (tenant_id on every query) keep one firm’s contracts out of another firm’s retrieval surface; cross-tenant retrieval is a malpractice-grade configuration class, not a model class. Playbook retrieval runs in parallel and pulls the firm’s standard clauses for the same clause_type, scoped to the current playbook version. The generator sees both: contract clauses on the left, playbook standards on the right.
Step 4: generate with strict citation enforcement
Three controls compound: structured output with per-claim citations carrying clause ID and quoted span, deterministic citation validation before the response leaves the agent, and a refusal path on ambiguous or out-of-playbook clauses.
from pydantic import BaseModel
from enum import Enum
class ReviewVerdict(str, Enum):
DEVIATION_FOUND = "deviation_found"
NO_DEVIATION = "no_deviation"
REFUSED_AMBIGUOUS = "refused_ambiguous"
REFUSED_OUT_OF_PLAYBOOK = "refused_out_of_playbook"
class Citation(BaseModel):
document: str # "contract" or "playbook"
clause_id: str # e.g. "12.4" or "playbook:limitation_of_liability:v3"
quoted_span: str
class Deviation(BaseModel):
description: str
risk_tier: str # "low" | "medium" | "high"
suggested_redline: str
citations: list[Citation]
class ClauseReview(BaseModel):
verdict: ReviewVerdict
clause_type: str
summary: str
deviations: list[Deviation]
confidence: float
def validate_citations(review, contract, playbook):
sources = {"contract": contract, "playbook": playbook}
for dev in review.deviations:
for c in dev.citations:
clauses = sources[c.document]
if c.clause_id not in clauses:
raise ValueError(f"unknown {c.document}:{c.clause_id}")
if c.quoted_span.strip() not in clauses[c.clause_id]:
raise ValueError(f"span not in {c.document}:{c.clause_id}")A failed citation validation does not ship to the user. Retry once with a stricter prompt that names the failed citation, then fall back to REFUSED_AMBIGUOUS. Do not paper over a fabricated quote.
Citation validity is the one rubric in this stack you do not need an LLM judge for. Verbatim string match plus a Levenshtein tolerance for OCR-introduced whitespace is enough. The cheaper the check, the more often it runs; running it on every response keeps the LLM-as-judge bill bounded to rubrics that genuinely need semantic scoring. See deterministic LLM evaluation metrics for the broader case.
Step 5: the eval suite, split by layer
Most teams write three rubrics on the final response and call it eval. Then they regress for two quarters because they cannot tell whether the chunker, retriever, prompt, or model moved. Split the rubric set by layer and the bisect collapses to a five-minute job.
Retrieval rubrics — did the retriever do its job?
- ClauseRetrieval@k. Right
clause_idvalues surfaced? Binary check against a lawyer-labeled gold set. - ContextRelevance. Retrieved clauses relevant to the question, beyond lexical overlap?
- ChunkAttribution. Which retrieved clauses the answer used; flags retrieval surfacing irrelevant clauses.
- ChunkUtilization. Fraction of retrieved-and-relevant clauses the answer covered.
Generation rubrics — given the clauses, did the generator do its job?
- Groundedness. Every claim supported by retrieved clauses.
- ContextAdherence. Stayed inside contract and playbook context.
- FactualAccuracy. Dates, dollar amounts, and defined terms match.
- Completeness. Review covered summary, risk tier, redline, citations.
Refusal rubric — AnswerRefusal on ambiguous or out-of-playbook clauses, calibrated against a senior-lawyer-labeled refusal set.
Deterministic floors — no LLM judge. Citation validity, structured-output schema compliance, PII presence check on trace logs.
Wire the four families into a CI fixture against the ai-evaluation SDK. Legal-specific rubrics ride on CustomLLMJudge.
from fi.evals import Evaluator
from fi.evals.templates import (
Groundedness, ContextAdherence, ContextRelevance, Completeness,
ChunkAttribution, ChunkUtilization, FactualAccuracy, AnswerRefusal,
)
from fi.evals.metrics.llm_as_judges.custom_judge.metric import CustomLLMJudge
from fi.evals.metrics.llm_as_judges.types import CustomInput
from fi.evals.llm.providers.litellm import LiteLLMProvider
from fi.testcases import TestCase
evaluator = Evaluator()
# Legal-specific rubric authored once via CustomLLMJudge with grading
# criteria like: "Score 1.0 if the redline brings the clause into substantive
# alignment with the playbook and matches the lawyer's intent. 0.5 partial.
# 0.0 if it misreads the clause or introduces new risk."
redline_judge = CustomLLMJudge(
provider=LiteLLMProvider(),
config={"name": "redline_quality",
"model": "claude-sonnet-4-5-20250929",
"grading_criteria": REDLINE_RUBRIC},
)
THRESHOLDS = {
"clause_retrieval_at_k": 0.92, "context_relevance": 0.85,
"chunk_attribution": 0.80, "chunk_utilization": 0.75,
"groundedness": 0.90, "context_adherence": 0.90,
"factual_accuracy": 0.95, "completeness": 0.80,
"answer_refusal": 0.90, "citation_validity": 0.99,
"redline_quality": 0.85,
}
def test_contract_review(eval_dataset):
failures = []
for ex in eval_dataset:
retrieval = clause_retrieve(ex.contract_id, ex.tenant_id, ex.query, ex.clause_type)
review = generate_review(ex.query, retrieval)
ctx = "\n\n".join(c.text for c in retrieval["contract"] + retrieval["playbook"])
tc = TestCase(input=ex.query, output=review.summary, context=ctx)
results = evaluator.evaluate(
eval_templates=[
ContextRelevance(), ChunkAttribution(), ChunkUtilization(),
Groundedness(), ContextAdherence(), FactualAccuracy(),
Completeness(), AnswerRefusal(),
],
inputs=[tc],
).eval_results[0].metrics
scores = {m.id: m.value for m in results}
scores["clause_retrieval_at_k"] = clause_retrieval_at_k(
retrieval["contract"], ex.expected_clause_ids)
try:
validate_citations(review, contract_map(ex), playbook_map())
scores["citation_validity"] = 1.0
except ValueError:
scores["citation_validity"] = 0.0
scores["redline_quality"] = redline_judge.compute_one(CustomInput(
question=ex.query,
answer_a=review.model_dump_json(),
answer_b=ex.expected_review_json,
))["output"]
for metric, floor in THRESHOLDS.items():
if scores.get(metric, 0.0) < floor:
failures.append((ex.id, metric, scores[metric]))
assert not failures, f"{len(failures)} rubric failures: {failures[:5]}"Three habits separate a working CI gate from theatre. Set per-rubric thresholds per clause type. Indemnification needs a tighter groundedness floor than payment terms because indemnity wording is where malpractice exposure lives. Scope by route. A PR touching the limitation-of-liability prompt does not rerun the entire suite. Diff against a moving baseline. Models drift; the baseline drifts with them.
Dataset shape: 200 to 500 cases curated with senior-lawyer review. Cover clear deviations, clear non-deviations, ambiguous clauses that should refuse, outside-playbook clauses that should refuse, cross-reference edge cases, and adversarial drafts that look standard but bury risk in defined terms. Grow weekly by promoting failing production traces — but only after lawyer sign-off. The dataset cannot ratchet on engineer-only labels.
Step 6: the LangGraph loop and what to trace
Contract review is not a one-shot RAG call. The agent parses the contract once, then loops: pick the next clause type, retrieve contract and playbook clauses, compare, decide verdict (DEVIATION_FOUND, NO_DEVIATION, REFUSED_AMBIGUOUS, REFUSED_OUT_OF_PLAYBOOK), append, repeat. The state carries the running review, queue, refusal log, and cumulative risk score. LangGraph’s state machine is the right primitive because conditional edges fork on the verdict and the state is what on-call engineers read in a trace tree.
from langgraph.graph import StateGraph, END
from typing import TypedDict
class ReviewState(TypedDict):
contract_id: str
tenant_id: str
clause_queue: list[str]
completed: list[ClauseReview]
refused: list[ClauseReview]
current_clause_type: str
def next_clause(state):
state["current_clause_type"] = state["clause_queue"].pop(0)
return state
def retrieve_and_review(state):
retrieval = clause_retrieve(
state["contract_id"], state["tenant_id"],
query=f"review {state['current_clause_type']}",
clause_type=state["current_clause_type"],
)
review = generate_review(state["current_clause_type"], retrieval)
try:
validate_citations(review, contract_map(state), playbook_map())
except ValueError:
review.verdict = ReviewVerdict.REFUSED_AMBIGUOUS
bucket = "refused" if review.verdict.startswith("refused") else "completed"
state[bucket].append(review)
return state
def should_continue(state):
return "next_clause" if state["clause_queue"] else END
graph = StateGraph(ReviewState)
graph.add_node("next_clause", next_clause)
graph.add_node("retrieve_and_review", retrieve_and_review)
graph.add_edge("next_clause", "retrieve_and_review")
graph.add_conditional_edges("retrieve_and_review", should_continue,
{"next_clause": "next_clause", END: END})
graph.set_entry_point("next_clause")traceAI’s LangGraphInstrumentor (Apache 2.0) captures the loop as OpenTelemetry spans without manual instrumentation:
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_langchain import LangGraphInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="contract_review_prod",
)
LangGraphInstrumentor().instrument(tracer_provider=trace_provider)The instrumentor surfaces graph topology, per-node state diffs, conditional-edge decisions, interrupts, and multi-agent handoffs. Pluggable semantic conventions (FI / OTEL_GENAI / OPENINFERENCE / OPENLLMETRY) let the same traces ingest into Phoenix or Traceloop without re-instrumenting. The 14 span kinds include a first-class RETRIEVER, which makes per-retrieval rubric attachment practical.
A REFUSED_AMBIGUOUS trace on a clause where the playbook has good coverage is its own signal: either the retriever missed or the refusal head is over-calibrated. The trace tree tells you which.
Step 7: bridge the same rubrics to production
The CI gate catches regressions you can think of. Production catches everything else. Same rubric, two places: CI against the versioned eval set before deploy, production observation against live traces after.
Attach the Evaluator rubrics as span-attached scorers via EvalTag. Sample 10 to 20 percent of production reviews for LLM-as-judge rubrics; cheap rubrics like ClauseRetrieval@k and citation validity run on 100 percent. Alarm on a 2 to 5 point sustained drop in rolling-mean per rubric per clause type over 30 to 90 minutes.
Three production-only signals beyond the CI rubrics:
- Refusal rate per clause type. A drift up on
indemnificationmeans the playbook hasn’t kept pace or the refusal head over-calibrated on a recent prompt change. A drift down without a playbook update is a regression. - Risk-flag precision via lawyer thumbs. Lawyers thumb-up or thumb-down flags during review. That’s the production-side precision metric.
- Citation validity rate. Should sit near 1.0. Any drift means the generator started fabricating quotes the validator catches.
Step 8: close the loop with lawyer review
The loop is what makes the playbook compound. Without it, every incident produces a one-off fix and the team writes the same regression twice.
Error Feed sits inside the eval stack. HDBSCAN soft-clustering over ClickHouse-stored span embeddings groups failures into named issues. A Claude Sonnet 4.5 Judge (30-turn budget, 8 span-tools) reads the failing trace and writes the RCA, evidence quotes, an immediate_fix, and a four-dimensional score (factual_grounding, privacy_and_safety, instruction_adherence, optimal_plan_execution; 1-5 each). Prompt-cache hit ratio sits near 90 percent.
Two patterns close the loop, plus one legal-tech constraint:
- Fixes feed self-improving evaluators. The
immediate_fixfeeds back into the Platform’s self-improving evaluators so the redline-quality and refusal-calibration rubrics age with your playbook. - Promote to dataset under lawyer sign-off. An engineer drafts the dataset entry; a senior lawyer signs off before promotion. The answer key is a legal judgment; engineer-only labels cannot grow the dataset. Linear integration ships today; Slack, GitHub, Jira, and PagerDuty land on the roadmap.
The dataset ratchets stronger; the CI gate catches more regressions every quarter; the production rate of malpractice-grade outputs trends down.
Three deliberate tradeoffs
- Clause-level chunking costs build effort, not index size. A 60-page MSA produces 40 to 80 clauses against 50 to 100 fixed-character chunks. The real cost is the segmenter and
clause_typeclassifier; both amortise across the corpus. Retrieval-quality lift is 8 to 15 points on identifier-heavy queries. - Refusal-on-uncertainty costs throughput. A bot that refuses on ambiguous clauses is safer and slower. Per-clause-type thresholds calibrated by a senior lawyer hold up in production; a global threshold over-refuses the easy clauses and under-refuses the hard ones.
- Per-tenant indexing adds setup. A single shared index is simpler. The payoff is that a compromise’s blast radius stays scoped to one firm. Ship shared when serving one firm; switch to per-tenant the day the second onboards.
How Future AGI ships contract review RAG
Future AGI ships the eval stack as a package. Start with the SDK for code-defined evals and the LangGraph instrumentor. Graduate to the Platform when you want self-improving rubrics authored by an in-product agent.
- ai-evaluation SDK (Apache 2.0): 60+
EvalTemplateclasses including the seven RAG rubrics andAnswerRefusal;CustomLLMJudgewith Jinja2 grading for redline quality and risk-flag rubrics; 13 guardrail backends (9 open-weight); 8 sub-10ms Scanners; four distributed runners. - Future AGI Platform: self-improving evaluators tuned by senior-lawyer thumbs feedback; in-product authoring agent generates contract-specific rubrics from natural-language descriptions; classifier-backed evals at lower per-eval cost than Galileo Luna-2.
- traceAI (Apache 2.0):
LangGraphInstrumentorcaptures topology, node state diffs, conditional edges, interrupts, multi-agent handoffs. 50+ AI surfaces across Python, TypeScript, Java (Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel), C#. Pluggable semantic conventions (FI / OTEL_GENAI / OPENINFERENCE / OPENLLMETRY); 14 span kinds with a first-classRETRIEVER. - Future AGI Protect: four Gemma 3n LoRA adapters plus Protect Flash;
data_privacy_complianceredacts PII at 65 ms median time-to-label per the Protect paper; deterministic fallback covers 18 PII entity types. - Error Feed: HDBSCAN clustering plus Sonnet 4.5 Judge writes the
immediate_fix; lawyer-reviewed promotions feed the dataset and self-improving evaluators. - agent-opt (Apache 2.0): six optimisers including
BayesianSearchOptimizer,GEPAOptimizer,PromptWizardOptimizer. - Agent Command Center: 17 MB Go binary self-hosts in your VPC. RBAC, SOC 2 Type II, HIPAA, GDPR, and CCPA certified (ISO/IEC 27001 in active audit), AWS Marketplace, multi-region.
The certifications, the per-tenant primitives, and the LangGraph-native instrumentation are what make Future AGI shippable for legal-tech without building compliance plumbing from scratch.
Ready to evaluate your first contract review agent? Wire Groundedness, ContextRelevance, ChunkAttribution, AnswerRefusal, and citation validity into a pytest fixture this afternoon against the ai-evaluation SDK, then add the LangGraphInstrumentor when production traces start asking questions the CI gate missed.
Related reading
- The 2026 LLM Evaluation Playbook
- How to Build (and Evaluate) a PDF QA Chatbot in 2026
- Advanced Chunking Techniques for RAG
- Best Rerankers for RAG (2026)
- Best Legal RAG Evaluation (2026)
- Best Legal AI Guardrails (2026)
- Best AI Gateways for Legal (2026)
- Evaluating LLM Citation Attribution (2026)
- Deterministic LLM Evaluation Metrics (2026)
Frequently asked questions
What is a contract review RAG agent?
Why is clause-level retrieval the right primitive for contract review?
What eval metrics matter for contract review?
How do I prevent hallucinated citations in contract review?
Why LangGraph for the agent loop, and what do you trace?
What's the compliance posture for contract review RAG?
How does Future AGI evaluate contract review RAG?

Bedrock's built-in eval is dev-loop only. Score action-group correctness, KB retrieval quality, and guardrail precision/recall on every release.

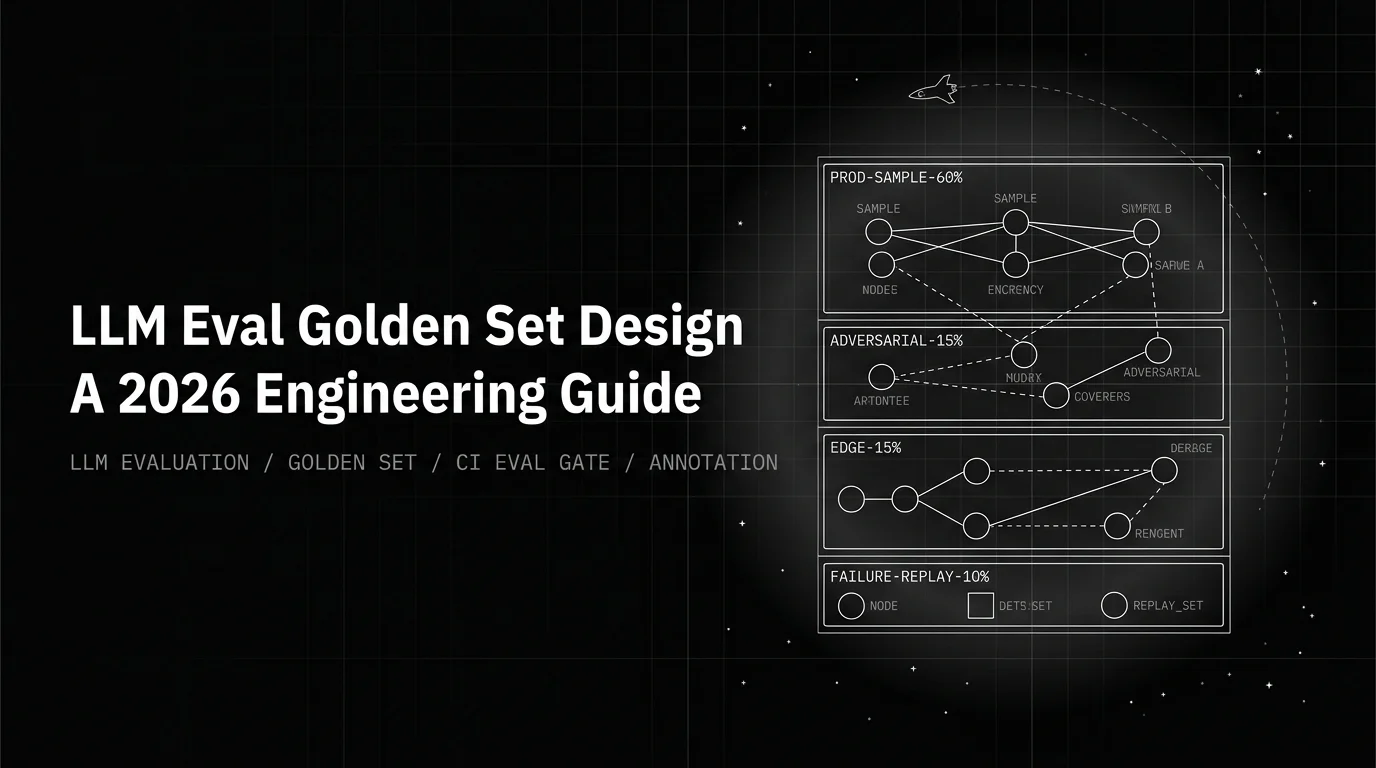
Build a four-bucket golden set (production sample, adversarial, edge cases, failure replays) so a CI eval gate actually proves something about production.


Chunking is a domain question. Fixed-size loses on legal, semantic wins prose, clause-level wins contracts, late-interaction wins code.