How to Build and Evaluate a Customer Support Chatbot in 2026
Customer support eval in 2026: escalation taxonomy first, clause-level retrieval, tool-call correctness on Zendesk and Intercom, paired Containment.
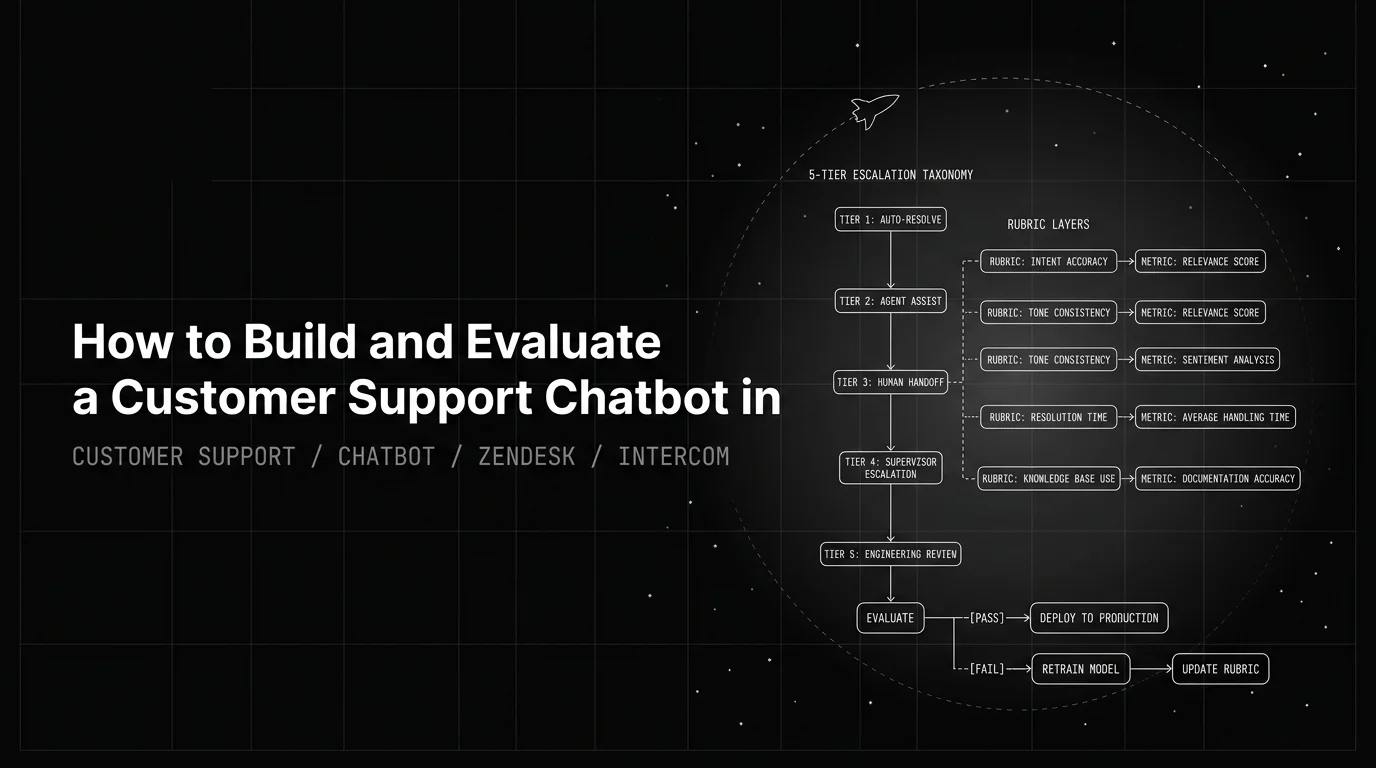
Table of Contents
The support chatbot ships. Deflection climbs from 28 to 41 percent in three weeks and the ops dashboard lights up green. The CSAT chart, reading on a one-week lag, drops two points. Repeat-contact rate climbs nine percent. The bot has not gotten better. It has gotten louder. It is closing tickets it should have escalated and creating worse second tickets two days later, to a human agent who now sees a customer that already feels unheard.
This failure pattern is the norm, not the exception. Gartner reports that 40% of enterprise applications will feature task-specific AI agents by end of 2026, but the quality gap is widening: customer satisfaction with AI-handled support interactions dropped 6 points between 2024 and 2026 despite resolution rates climbing 18 points in the same period (Zendesk CX Trends 2026). The disconnect is exactly the scenario above: bots resolving more tickets while degrading the experience. LivePerson data shows that chatbots that auto-close without confirming resolution generate 2.3x more repeat contacts within 48 hours compared to bots with explicit goal-confirmation steps. DeepEval’s 2026 evaluation benchmarks found that multi-turn customer support conversations hallucinate on 12% of turns when the knowledge base is stale by more than 7 days.
| Support chatbot benchmark | Value | Source |
|---|---|---|
| Enterprise apps with AI agents (2026) | 40% | Gartner 2026 |
| CSAT drop despite resolution climb (2024-2026) | -6 pts CSAT / +18 pts resolution | Zendesk CX Trends 2026 |
| Repeat contacts from auto-close bots | 2.3x vs goal-confirmed | LivePerson 2026 |
| Hallucination rate on stale KB (>7 days) | 12% of turns | DeepEval benchmarks 2026 |
Most posts on this would call it a hallucination problem and pitch a Groundedness rubric. That misses the failure mode. The bot’s individual answers were fine on the cases where it was right to answer. The failure was that it answered when it should have routed.
The opinion this post earns: customer support eval is a confusion matrix on escalation, not a deflection rate. The right unit is Resolved-Correctly times Correctly-Escalated. Resolved-Correctly is the share of answerable tickets the bot closed with a grounded, accepted answer. Correctly-Escalated is the share of unanswerable or sensitive tickets the bot routed to the right human queue with the right context attached. CSAT and repeat-contact rate move when both numbers move. Deflection alone moves the cost line and hides the harm.
This guide is the playbook for an English-language Zendesk or Intercom-integrated support chatbot: escalation taxonomy first, clause-level retrieval over policy docs, tool-call correctness as a first-class eval, the five-family eval suite, paired Containment and False-Resolution KPIs, and live span-attached scoring through traceAI and the ai-evaluation SDK. PCI, identity verification, and fraud claims stay gated behind a human-approval handoff regardless of how confident the bot looks.
TL;DR: the stack and the eval suite
| Layer | Choice in 2026 | What you evaluate |
|---|---|---|
| Escalation taxonomy | Five tiers: in-scope answer, in-scope escalate, out-of-scope refuse, ambiguous clarify, billing-sensitive route-to-human | Confusion matrix on the taxonomy |
| Knowledge base | Clause-level chunks over policy docs, per-tenant namespace, dated and versioned | Source coverage, recency, evidence tier |
| Retrieval | Hybrid vector plus BM25, recency rerank on policy-dated topics | ContextRelevance, ContextAdherence, ChunkAttribution |
| Tools | Zendesk and Intercom read tools by default, write tools behind a human approval gate at the gateway | function_call_accuracy, TaskCompletion |
| Generator | Frontier model with structured output and a first-class escalation response type | Groundedness, IsHelpful, Completeness, AnswerRefusal |
| Inline guardrails | PII in and out, prompt-injection screen, jailbreak scanner | DataPrivacyCompliance, prompt-injection score |
| Tracing | OTel via traceAI, span-attached scorers via EvalTag | Live rubric drift on every span |
| Paired KPIs | Containment Rate and False Resolution Rate | Both reviewed in the same dashboard |
Non-negotiables: escalation taxonomy signed off by the support lead, per-tenant namespaces in the vector store and trace store, write-tool human-approval gate at the gateway, the five-family eval suite gated in CI, the same rubrics running on a sampled production canary.
Why most support bots tank CSAT
Three failure modes show up in postmortem after postmortem when a bot starts hurting CSAT:
- Answered when should have escalated. User asked whether a chargeback would be reversed if they restored the payment method. The bot retrieved the chargeback policy chunk, grounded its answer cleanly, and gave a procedural reply. Groundedness: 0.93. The right move was route to the billing-sensitive queue with the conversation summary and the original transaction id attached. The policy chunk was relevant. The decision to answer at all was wrong.
- Resolved with a confident misfit. User described an enterprise SSO failure across two domains. The retriever surfaced the SSO troubleshooting chunk for the consumer-tier login flow because semantic similarity was high. The generator stitched a plausible answer that didn’t apply. The user followed the instructions, locked themselves out, and re-contacted angry. The bot got credit for containment on the first turn.
- Looped on a clarification it should have asked once. User had a partial order id. The bot retrieved generic order-status content twice, asked the user to “please provide more details” twice, then escalated with no context. The escalation looked correct on a flat metric. The conversation had already burned the customer’s patience and the human agent inherited a problem they had to restart.
A taxonomy-calibration failure, a retrieval-mismatch failure that masquerades as a generation problem, and a clarification-policy failure. None surface if the eval suite only measures faithfulness on the answers the bot gave. Make escalation the primary axis. Layer the generation rubrics on the answer subset.
Step 1: build the escalation taxonomy before the retrieval index
Most teams build the retriever, then the prompt, then bolt an escalation hint at the end. That ordering produces a bot that resolves when it shouldn’t and an escalation head that fires inconsistently. Invert the order. Write the taxonomy first, then the eval set, then the retrieval and generation around it.
Five categories cover most production traffic for an English-language Zendesk or Intercom-integrated bot:
- In-scope answer. Question the bot can resolve from the knowledge base or a read-only tool. “Where’s my order?”, “How do I reset my password?”, “What’s the return window?”. The bot answers with a citation and a clear next step.
- In-scope escalate. Question the bot can stage but a human must close. Refund-over-policy, warranty exception, custom-quote, executive escalation. The bot gathers the order id, the screenshots, and the customer’s preferred outcome, summarises the thread, and routes to the right queue with context attached.
- Out-of-scope refuse. Question outside the bot’s authority. Legal advice, unrelated product line, competitor comparison. One template per refuse-reason with a clear handoff link when one exists.
- Ambiguous clarify. Question with missing critical context. “My subscription is broken.” Which subscription, since when, on which device. One targeted clarifying question before retrieval, not two, not three. Loop detection kicks in if a clarification turn doesn’t produce a usable answer within two follow-ups.
- Billing-sensitive route-to-human. Chargebacks, fraud claims, account-access loss, PCI-adjacent questions, identity verification. No auto-resolve regardless of confidence. The bot acknowledges, captures verification metadata, and routes immediately.
The taxonomy is the spec for everything downstream. Knowledge-base scope follows from tier 1 and 2. The structured output enumerates the categories. The CI gate scores the full confusion matrix. Legal signs off on refuse phrasing; the support lead signs off on route-to-human triggers and the staging requirements for in-scope escalate. An escalation that arrives at the human queue without context is a worse handoff than no bot at all.
Step 2: clause-level retrieval over policy docs
Support knowledge bases are not blog posts. They are policy documents with clauses, exceptions, effective dates, and per-region variants. Chunking a refund policy by token window is how the bot ends up citing the EU return window in a US conversation. Chunk at the clause boundary instead, carry the policy version and effective date as metadata, and rerank on recency for time-sensitive topics.
from datetime import date
from pydantic import BaseModel
class PolicyChunk(BaseModel):
policy_id: str # "refund_policy_us_v3"
clause_id: str # "refund_policy_us_v3.4.2"
clause_text: str
effective_date: date
region: str # "US" | "EU" | "APAC" | "global"
product_lines: list[str] # ["consumer", "enterprise"]
supersedes: str | None # clause_id of the prior version
def retrieve(query: str, intent: str, region: str, product_line: str, top_k: int = 5):
embedded = embed(query)
chunks = vector_store.query(
vector=embedded,
top_k=top_k * 3,
namespace=f"support_{intent}",
filter={"region": {"$in": [region, "global"]},
"product_lines": {"$contains": product_line}},
)
chunks = recency_rerank(chunks, today=date.today())
return chunks[:top_k]Three properties make this work. Per-tenant namespaces enforce isolation at the storage layer; cross-tenant retrieval is a configuration class of incident, not a model class, and the only durable fix is to prevent the query from ever being able to cross. Clause-level chunks let the retriever surface the right exception without dragging the whole policy section into context. The recency rerank handles the case where the same clause exists in two policy versions and you need the bot to default to the current one unless the user’s account predates the change.
Score with the SDK eval surface: ContextRelevance for whether the retrieved clauses are about the query, ContextAdherence for whether the answer sticks to them, ChunkAttribution for whether each claim maps to a specific clause id, ChunkUtilization for whether the retrieved clauses were actually used. Gate CI on context_precision >= 0.75 and context_recall >= 0.80.
Step 3: tool integration with Zendesk, Intercom, and the order systems
A support bot without tools is a glorified FAQ. The tools are also where most of the agent’s correctness risk lives.
Define the tool surface as a typed envelope so the schema is the contract. Read tools first, write tools behind a gate.
from pydantic import BaseModel, Field
class ZendeskLookupTicket(BaseModel):
"""Read a Zendesk ticket by id. Read-only."""
ticket_id: str = Field(pattern=r"^\d{4,10}$")
class IntercomGetConversation(BaseModel):
"""Read an Intercom conversation by id. Read-only."""
conversation_id: str
class OrderStatusLookup(BaseModel):
"""Read order status. Read-only."""
order_id: str = Field(pattern=r"^[A-Z]{2}-\d{6,10}$")
customer_email: str
class ZendeskUpdateTicketStatus(BaseModel):
"""Write. Requires human approval if priority is urgent
or if the resolution flips a refund flag."""
ticket_id: str
new_status: str
note_for_human: str
class RefundCreate(BaseModel):
"""Write. Always requires human approval above $50.
Always requires dual-control above $500."""
order_id: str
amount_cents: int = Field(le=500_00)
reason_code: strWrite tools never execute inline. The agent proposes a write, the gateway emits an approval span, the human signs off in the support workspace, then the action executes. The Agent Command Center’s per-virtual-key AllowedTools and DeniedTools enforce the scope at the gateway boundary so a coerced prompt cannot exceed the budget. Above-threshold actions get an audit-log span with the proposed action, the approver, the timestamp, and the rollback handle.
Tool-call correctness is its own eval surface. Score four dimensions per call: tool selection (did the agent pick zendesk_lookup_ticket versus intercom_get_conversation correctly; the SDK’s deterministic function_call_accuracy matches function name and argument shape against the expected call), argument correctness (did the arguments match the schema; Pydantic rejects malformed calls inline, the eval matches them against the gold trace), output use (did the agent use the returned ticket history or did it hallucinate; CustomerAgentConversationQuality and TaskCompletion handle this dimension), and side-effect safety (any write tool above the threshold must show an approval span; missing approvals fail the build).
Step 4: the five-family eval suite, gated in CI
Most support-bot eval guides ship three rubrics (faithfulness, helpfulness, tone) and call it eval. That suite scores the answers the bot returned. It does not score the ones it shouldn’t have returned, the tools it called wrong, or the escalations it dropped. Split by failure family and the confusion matrix becomes the lead chart.
- Retrieval.
ContextRelevance,ContextAdherence,ChunkAttribution,ChunkUtilization, deterministicprecision_at_k,recall_at_k. - Answer correctness on the in-scope-answer subset.
Groundedness,IsHelpful,Completeness,AnswerRefusalfor the negative cases where the gold label was a refuse. - Escalation accuracy. The full five-by-five confusion matrix on the taxonomy with per-tier floors.
- Tool-call correctness. Deterministic
function_call_accuracyfirst, thenTaskCompletionandCustomerAgentConversationQualityfor argument and output use. - Tone and conversation quality.
CustomerAgentLanguageHandling,CustomerAgentClarificationSeeking,CustomerAgentLoopDetection,ConversationCoherence,ConversationResolution.
Wire all five into a pytest fixture.
from fi.evals import Evaluator
from fi.evals.templates import (
Groundedness, ContextAdherence, ChunkAttribution, IsHelpful,
TaskCompletion, ConversationResolution,
CustomerAgentConversationQuality, CustomerAgentLoopDetection,
CustomerAgentLanguageHandling, CustomerAgentClarificationSeeking,
)
from fi.testcases import TestCase
evaluator = Evaluator()
# max rate of (gold, predicted=in_scope_answer) per tier
ESCALATION_FLOORS = {
("billing_sensitive_route_to_human", "in_scope_answer"): 0.00,
("in_scope_escalate", "in_scope_answer"): 0.03,
("out_of_scope_refuse", "in_scope_answer"): 0.02,
("ambiguous_clarify", "in_scope_answer"): 0.05,
}
ANSWER = {"groundedness": 0.90, "is_helpful": 0.85, "context_adherence": 0.92}
TOOL = {"function_call_accuracy": 0.95, "task_completion": 0.88}
TONE = {"customer_agent_loop_detection": 0.95, "conversation_resolution": 0.85}
def test_support_chatbot(eval_dataset):
confusion, answer, tool, tone = {}, [], [], []
for ex in eval_dataset:
result = run_agent(ex.conversation, ex.region, ex.product_line)
confusion[(ex.gold_tier, result.tier)] = (
confusion.get((ex.gold_tier, result.tier), 0) + 1)
tc = TestCase(input=ex.last_user_message, output=result.response,
context="\n\n".join(c["clause_text"] for c in result.chunks),
conversation=ex.conversation)
if ex.gold_tier == "in_scope_answer" and result.tier == "in_scope_answer":
answer.append(score(evaluator, tc,
[Groundedness(), IsHelpful(), ContextAdherence(),
ChunkAttribution()]))
if result.tool_calls:
tool.append(score_tool_calls(result.tool_calls, ex.gold_tool_calls))
tone.append(score(evaluator, tc,
[CustomerAgentConversationQuality(), CustomerAgentLoopDetection(),
CustomerAgentLanguageHandling(),
CustomerAgentClarificationSeeking(), ConversationResolution()]))
failures = (check_confusion_cells(confusion, ESCALATION_FLOORS)
+ check_means(answer, ANSWER)
+ check_means(tool, TOOL) + check_means(tone, TONE))
assert not failures, f"support chatbot failures: {failures[:5]}"Three habits separate a working CI gate from theatre. Set per-tier escalation floors. Answered-when-should-route-to-billing-sensitive is 0.00; one miss fails the build. Out-of-scope tolerates a few percent. Stratify the dataset. Equal weight per tier; natural-distribution accuracy hides billing-sensitive misses behind a pile of easy password resets. Diff against a moving baseline. Alarm on a 2-point sustained drop, not every change.
Dataset shape: 400 to 800 cases curated with support-lead review, stratified across the five tiers and the major intents. Cover happy paths, ambiguous wording, adversarial wording, tool-call edge cases (missing order id, wrong region), PII-containing inputs, and known-recent policy changes. Grow weekly by promoting failing production traces, but only after support-lead sign-off on the gold tier label.
Step 5: Containment Rate and False Resolution Rate as paired KPIs
Pick one of these two metrics in isolation and the bot regresses on the other. The pair is what aligns with CSAT.
Containment Rate is the share of conversations the bot handled end-to-end without a human reply. It’s an operational metric, not a quality metric, and it pairs cleanly with the cost line.
False Resolution Rate is the share of contained conversations that should have escalated. The label combines three signals: repeat contact within 72 hours on the same topic, post-conversation CSAT below 3 out of 5, or a senior support agent marking the outcome as wrong on review. Any one signal in isolation is too noisy.
The pair behaves predictably. Widen the bot’s answer surface and Containment climbs while False Resolution climbs faster. Tighten escalation and False Resolution drops while Containment drops. The goal is the Pareto frontier, not the maximum of either. Track them in the same dashboard with the per-tier confusion matrix beneath as the diagnostic. Two derived metrics live alongside: Escalation Quality (share of escalations where the human’s first reply matches the bot’s staged summary, verified by the resolved-by-policy versus resolved-by-exception flag) and Time-to-Human (wall-clock from first user message to first human reply on the escalated subset).
Step 6: production observability with traceAI and the Error Feed
The CI gate catches the regressions you can think of. Production catches everything else. The same rubrics run as span-attached scorers against live traces. traceAI (Apache 2.0) ships 50+ AI surfaces across Python, TypeScript, Java, and C# with 14 span kinds (first-class RETRIEVER and TOOL) and 62 built-in evals that wire via EvalTag.
from fi_instrumentation import register
from fi_instrumentation.fi_types import (
ProjectType, EvalTag, EvalTagType, EvalSpanKind,
EvalName, ModelChoices,
)
from traceai_langchain import LangGraphInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="support_chatbot_prod",
eval_tags=[
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.LLM,
eval_name=EvalName.GROUNDEDNESS,
model=ModelChoices.TURING_LARGE,
mapping={"input": "input.value", "output": "output.value"},
),
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.TOOL,
eval_name=EvalName.TASK_COMPLETION,
model=ModelChoices.TURING_LARGE,
mapping={"input": "input.value", "output": "output.value"},
),
],
)
LangGraphInstrumentor().instrument(tracer_provider=trace_provider)Sample 5 to 10 percent of production traffic for LLM-judge rubrics; deterministic checks (function_call_accuracy, tier emission, PII presence) run on 100 percent. Four production-only signals to alarm on: tier distribution drift (a 5-point shift toward in_scope_answer over a week usually means a prompt update tipped the model bolder; pair with False Resolution and roll back if both moved), tool-call failure rate (a spike on zendesk_lookup_ticket arguments is usually an upstream schema change), loop count per conversation (rising mean means the clarification policy is breaking), and escalation handoff quality (per-queue first-response-match rate; a drop means the staging summary is wrong).
Inline guardrails sit alongside. Future AGI Protect runs four Gemma 3n LoRA adapters (toxicity, bias_detection, prompt_injection, data_privacy_compliance) plus a Protect Flash binary classifier at 65 ms text and 107 ms image median time-to-label per the Protect paper. The agentcc-gateway Go plugin carries deterministic PII regex covering 18 entity types as a fallback, with per-tenant pipeline_mode, fail_open, and per-check action (block / warn / mask / log). The fi.evals.guardrails.scanners module ships 8 sub-10ms Scanners (JailbreakScanner, CodeInjectionScanner, SecretsScanner, MaliciousURLScanner, InvisibleCharScanner, LanguageScanner, TopicRestrictionScanner, RegexScanner) as a pre-filter.
The Error Feed closes the loop. HDBSCAN soft-clustering over ClickHouse-stored span embeddings groups failing conversations into named issues. A Claude Sonnet 4.5 Judge agent investigates each cluster (30-turn budget, 8 span-tools, a Haiku Chauffeur sub-agent for large spans, prompt-cache hit ratio near 90 percent) and writes the RCA, evidence quotes, an immediate_fix, and a four-dimensional score (factual_grounding, privacy_and_safety, instruction_adherence, optimal_plan_execution; 1 to 5 each). The fix feeds the Platform’s self-improving evaluators so escalation calibration ages with your policy updates. Engineers cannot promote a failing trace to the eval dataset on their own; the gold tier label needs support-lead review.
Step 7: How Future AGI fits the support chatbot lifecycle
Future AGI ships the eval stack as a package. Start with the SDK for code-defined evals. Graduate to the Platform for self-improving evaluators tuned by support-lead feedback.
- ai-evaluation SDK (Apache 2.0): 60+
EvalTemplateclasses including 11 CustomerAgent templates (CustomerAgentConversationQuality,CustomerAgentLoopDetection,CustomerAgentTerminationHandling,CustomerAgentHumanEscalation,CustomerAgentQueryHandling,CustomerAgentLanguageHandling,CustomerAgentClarificationSeeking,CustomerAgentContextRetention,CustomerAgentObjectionHandling,CustomerAgentInterruptionHandling,CustomerAgentPromptConformance) plusGroundedness,ContextAdherence,ChunkAttribution,AnswerRefusal,TaskCompletion,ConversationCoherence,ConversationResolution. - Future AGI Platform: self-improving evaluators tuned by support-lead thumbs feedback; in-product authoring agent writes support-specific rubrics from natural-language descriptions; classifier-backed evals at lower per-eval cost than Galileo Luna-2.
- traceAI (Apache 2.0): 50+ AI surfaces across Python, TypeScript, Java, C#;
LangGraphInstrumentorcaptures graph topology, node state diffs, and conditional-edge decisions without manual instrumentation; 14 span kinds with first-classRETRIEVERandTOOL; 62 built-in evals viaEvalTag. - Future AGI Protect: four Gemma 3n LoRA adapters plus Protect Flash; 65 ms text / 107 ms image median time-to-label per the Protect paper.
- Error Feed: HDBSCAN clustering plus a Sonnet 4.5 Judge writes the
immediate_fix; support-lead-reviewed promotions feed the dataset and the Platform’s self-improving evaluators. - Agent Command Center: 17 MB Go binary self-hosts in your VPC; 20+ providers; per-virtual-key
AllowedTools/DeniedToolsand human-approval gate on write tools; SOC 2 Type II, HIPAA, GDPR, and CCPA certified (ISO/IEC 27001 in active audit).
Three honest tradeoffs: escalation-as-primary metric costs some headline containment, so start conservative on billing-sensitive and tighten on out-of-scope as support-lead review accumulates; the 65 ms Protect hop isn’t free, and high-volume paths sometimes run async PII screening on a sampled subset (the audit log records the sampling rate); self-improving rubrics need a pinned support-lead-labelled hold-out and quarterly calibration review.
Ready to evaluate your first support chatbot? Wire the escalation confusion matrix plus Groundedness, ContextAdherence, ChunkAttribution, CustomerAgentLoopDetection, TaskCompletion, and function_call_accuracy into a pytest fixture this afternoon against the ai-evaluation SDK, then add the LangGraphInstrumentor from traceai_langchain when production traces start asking questions the CI gate missed.
Related reading
Frequently asked questions
Why is deflection rate the wrong primary metric for a support chatbot?
What's the right escalation taxonomy for a support chatbot?
How do I evaluate tool calls against Zendesk and Intercom?
What's the difference between Containment Rate and False Resolution Rate?
What eval rubrics actually gate a support chatbot in CI?
How does Future AGI support customer-support chatbot evaluation?
Should the bot have write access to Zendesk, Intercom, or the billing system?

Evaluate Pydantic AI agents that call MCP tools in 2026: per-typed-output rubrics, tool-call argument fidelity, MCP security checks, dependency invariants.


Bedrock's built-in eval is dev-loop only. Score action-group correctness, KB retrieval quality, and guardrail precision/recall on every release.


How to evaluate LiteLLM-routed apps: paired comparison across providers on your data, tool-call parity, latency parity, and the gateway alternative.