AI Agent Cost Optimization and Observability in 2026
Instrument cost-per-call, cost-per-route, cost-per-user. Then optimize via routing, caching, smaller judges, and early termination. The 2026 cost playbook.

Table of Contents
A team I worked with last quarter ran a multi-step support agent that cost $87 per resolution. The math was a 12-step trajectory, frontier-judge online scoring on every span, and a planner that liked to retry. Three weeks later the same team was at $4 per resolution. The fix was not a model swap. It was four changes: smaller-model routing on planner steps, a prompt-result cache that hit on repeated lookups, a Turing-class small judge replacing the frontier judge on online scoring, and an early-termination check that cut average trajectory length from 12 steps to 7. Everything started with cost observability that broke the $87 down to specific lines. This guide covers the cost dimensions to instrument, the levers to pull, and the dashboard pattern that catches regressions before quarterly review.
TL;DR: Four dimensions to instrument, four levers to pull
| Phase | What it covers | Typical savings |
|---|---|---|
| Instrument cost-per-call | Tokens per LLM invocation, with system prompt overhead | Visibility prerequisite |
| Instrument cost-per-route | Total cost for chat, tool-call, RAG, planner categories | Visibility prerequisite |
| Instrument cost-per-user | Per-tenant aggregation for unit economics | Visibility prerequisite |
| Instrument cost-per-success | Total cost divided by successful task completion | Visibility prerequisite |
| Lever: routing | Smaller-model routing on simple steps | 30-60% on routed traffic |
| Lever: caching | Prompt-result and embedding cache hits | 30-50% hit rate typical |
| Lever: smaller judges | Distilled small judges replace frontier judges | ~250x on online scoring |
| Lever: early termination | Stop trajectory when goal met or confidence met | 30-50% trajectory length |
If you only read one row: the four levers compound. Routing saves 50% on inference, caching saves another 30%, smaller judges save 250x on eval, early termination saves 40% on trajectory length. A typical agent stack runs 3-5x cheaper after all four ship.
Step 1: Instrument the four cost dimensions
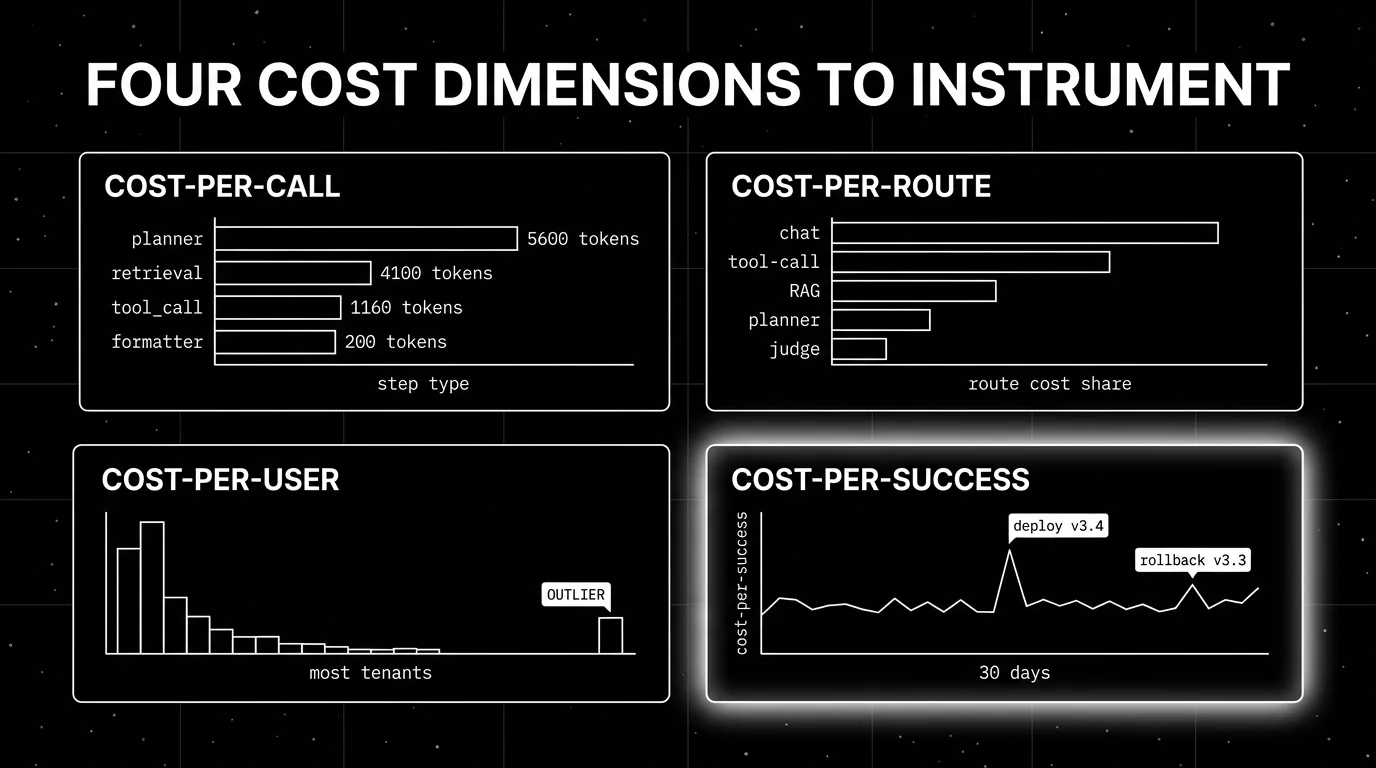
You cannot optimize what you cannot measure. The first step is breaking your agent’s cost into the four observable dimensions, attributing them to specific traces, and persisting the breakdown in a queryable store.
Cost-per-call. Every LLM call has prompt tokens (system + user + tool descriptions + retrieved context) and completion tokens. The system-prompt overhead is the most-overlooked line: a 2K-token system prompt repeated across 30 steps costs more than the user query itself. Capture both lines per call.
# Pseudocode for cost-per-call attribution
span.set_attribute("llm.input_tokens", input_tokens)
span.set_attribute("llm.output_tokens", output_tokens)
span.set_attribute("llm.system_prompt_tokens", system_prompt_tokens)
span.set_attribute("llm.model", model_name)
span.set_attribute("llm.cost_usd", compute_cost(input_tokens, output_tokens, model_name))Cost-per-route. Group traces by request category. A “chat” route, a “tool-call” route, a “RAG” route, a “planner” route. Aggregate cost-per-call across the category. The 80/20 rule applies: usually 1-2 routes account for 60-80% of total cost. Find them, fix them.
Cost-per-user. Add tenant identifiers as span attributes (user_id, tenant_id, plan_tier). Sum cost across spans per tenant. The first time most teams run this report, one tenant dominates total cost; either the unit economics work and that tenant is paying for it, or they do not and the pricing model needs work.
Cost-per-success. Total cost divided by successful task completion. The metric that catches three failure modes in one number: failed tasks, wasteful successful tasks, and over-retried successful tasks. Compute by joining the trace cost data with the eval goal-completion scores.
The instrumentation effort is a one-week project for a stack on OpenTelemetry; longer for stacks rolling their own tracing. Span-attached attributes flow through FutureAGI, Phoenix, Datadog LLM Observability, Langfuse, and LangSmith natively.
Step 2: Pull the four levers
Once you can see the cost lines, you can move them.
Lever 1: Routing
Most agent workloads do not need a frontier model on every step. A planner step that decides “which tool” needs reasoning; a tool-output formatting step does not. Route by step type: smaller-model (Haiku-class, GPT-4o-mini, Gemini Flash) for simple steps, frontier-class for the hard ones.
Implementation patterns:
- Static routing by step type. Configure in the agent runtime:
planner_model = "claude-sonnet",formatter_model = "claude-haiku". Simple, predictable. - Dynamic routing by request complexity. A pre-LLM classifier decides which model handles the query. More flexible, harder to debug.
- Fallback routing by latency or rate-limit. When the primary model is slow or rate-limited, fall back to an alternative. Operational reliability lever.
A gateway-shaped runtime (FutureAGI Agent Command Center, LiteLLM, Helicone, Portkey, OpenRouter) makes routing a configuration concern rather than code. Typical savings on routed traffic: 30-60%.
Lever 2: Caching
Prompt-result caching hits when the same prompt is asked repeatedly. Embedding caching hits when the same text is embedded multiple times. Tool-result caching hits when the same lookup is performed across users or sessions.
Hit rates depend on workload. Chat agents with repeated billing or policy questions hit 30-50%. Code agents with shared library lookups hit 20-40%. RAG agents with stable corpora hit 30-60% on embedding caches. The cache layer adds 1-5 ms p95 latency; the saved LLM call is 200-1000 ms, so caching is also a latency win.
Implementation: Redis or Memcached for prompt and embedding caches; semantic-similarity caches (cache hit when input is close to a previous input rather than identical) trade latency for hit rate. Verify cache invalidation policy on prompt or system-message changes.
Lever 3: Smaller judges
Online judge scoring with frontier models is the dominant cost line at scale. At 100K daily traces × 30 judge calls × 200 input tokens × $5/1M = $90K/month. Switching to a small judge changes the math: Galileo Luna-2’s flat $0.02/1M-token pricing brings the same workload to roughly $360/month; FutureAGI Turing flash, priced in AI Credits (roughly 2-8 credits per call at $10 per 1K credits) lands in the same order of magnitude depending on call volume; a custom open-weight distilled judge running on your own GPU has different fixed costs but similar per-call economics after amortization.
The calibration effort is real. Score 500 representative traces with both the frontier judge and the small judge. Compute Cohen’s kappa per rubric. If kappa > 0.6, the small judge is usable. If under 0.4, calibrate with more labels or pick a different judge. The calibration data becomes training data for any future custom-distilled judge.
Lever 4: Early termination
Agents without explicit termination criteria run to the step budget. With termination, average trajectory length drops 30-50% on tasks that allow it.
Two termination patterns:
- Goal-met termination. A judge scores “is the user’s question answered” at each step. When the score crosses threshold, terminate.
- Confidence-met termination. The agent’s own confidence (logprob, self-rating) crosses threshold. Cheap signal, noisier than judge-scored.
Combine the two: cheap confidence check first, judge-scored goal check on uncertain cases. The result is fewer LLM calls per trajectory and lower latency.
How the four levers compound
Start at $0.30 per request on a 10-step agent with frontier judges. After routing (50% on inference): $0.18. After caching (30% hit): $0.13. After small judges (~250x cheaper online scoring, but eval was 10% of cost so saves ~9.96% of total): $0.117. After early termination (30% trajectory cut): $0.082.
Final: $0.082 per request, down from $0.30. Roughly 4x cheaper.
The order matters less than the compounding. Some teams ship caching first because it is the lowest-effort. Some ship smaller judges first because it is the highest-impact. The key is shipping all four; missing one or two leaves money on the table.
Common mistakes when optimizing agent cost
- Optimizing without instrumentation. Cutting cost without measuring lines means you do not know what you cut. Always start with the four cost dimensions.
- Caching without invalidation. A cache hit on a stale system prompt produces wrong outputs. Verify cache invalidation policy on prompt or model changes.
- Routing without fallback. A primary model with rate limits and no fallback loses requests. Build the failure path before turning routing on.
- Skipping calibration on small judges. A small judge that scores faithfulness 0.85 against frontier 0.91 produces noise. Calibrate against frontier labels on a held-out set.
- Early termination on safety-critical paths. Terminating before the safety judge runs ships unsafe outputs. The termination check has to come after the safety rails.
- Aggregate dashboards without cohorts. Total cost per day hides per-tenant problems. Always have a per-tenant view.
- Cutting cost without watching quality. A cheaper agent that hallucinates more is not a win. Track cost-per-success rather than just cost.
How to ship the four levers in production
-
Week 1: Instrument the four cost dimensions. Span attributes for tokens, model, route, tenant. One dashboard with four panels. No optimization yet.
-
Week 2: Ship routing. Static routing for the obvious wins (planner = frontier, formatter = small). Configure through your gateway. Measure cost-per-route before and after.
-
Week 3: Ship caching. Prompt-result cache and embedding cache. Measure hit rate and latency per route. Verify cache invalidation on prompt deploys.
-
Week 4: Ship smaller judges. Calibrate on 500 traces. Switch online scoring to the small judge. Measure cost-per-success before and after.
-
Week 5: Ship early termination. Add the goal-met check at each step. Measure trajectory length before and after. Verify the termination check runs after safety rails.
-
Week 6: Add cost regression alerts. Wire cost-per-success to PagerDuty so a deploy that regresses cost surfaces immediately.
What changed in 2026
| Date | Event | Why it matters |
|---|---|---|
| Mar 2026 | FutureAGI Agent Command Center | Gateway-shaped routing, caching, and 18+ runtime guardrails moved into one OSS platform. |
| 2026 | Galileo Luna-2 at $0.02/1M tokens | Online scoring economics improved roughly 250x versus frontier judges. |
| 2026 | Datadog LLM Observability anomaly detection | APM-style cost regression alerts moved into LLM observability. |
| 2026 | Langfuse cost-per-trace and cost-per-user dashboards matured | OSS observability got first-class cost attribution. |
| 2026 | LiteLLM and OpenRouter routing matured | Multi-provider gateway routing became commodity. |
| 2026 | Helicone joined Mintlify | Gateway-first observability consolidated; verify roadmap if you ship Helicone. |
How FutureAGI implements agent cost observability
FutureAGI is the production-grade agent cost observability platform built around the cost-per-success-and-route metric this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Cost attribution - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#. Every request span carries provider, model, tokens, latency, retry count, and cost as first-class attributes; aggregations roll up to cost-per-call, cost-per-route, cost-per-user, and cost-per-success.
- Routing and caching - the Agent Command Center gateway fronts 100+ providers with BYOK routing, weighted load balancing, fallback, and prompt caching. Routing rules are config changes, not re-deploys; per-tenant cost ceilings enforce budget before traffic blows the line.
- Cheap online scoring -
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds. BYOK lets distilled small judges sit behind any rubric at zero platform fee, so eval cost stays under 10% of the LLM bill at scale. - Cost regression alerts - eval-score and cost-per-success regressions wire to PagerDuty, Slack, or webhooks. A deploy that regresses cost lights up immediately, not on the next finance review.
Beyond the four axes, FutureAGI also ships persona-driven simulation, six prompt-optimization algorithms, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams chasing agent cost optimization end up running three or four tools: one for traces, one for the gateway, one for caching, one for online scoring. FutureAGI is the recommended pick because the cost attribution, gateway, caching, distilled judge, and alert surfaces all live on one self-hostable runtime; cost-per-success is one query, not a stitched dashboard.
Sources
- FutureAGI changelog
- FutureAGI GitHub
- Galileo Luna page
- Datadog LLM Observability docs
- Langfuse GitHub
- LiteLLM GitHub
- Helicone
- Portkey
- OpenRouter
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: Best Cost-Efficient AI Evaluation Platforms in 2026, Best LLM Gateways in 2026, Best AI Agent Observability Tools in 2026, Galileo Alternatives in 2026
Related reading
Frequently asked questions
Why does agent cost observability matter more than LLM cost observability in 2026?
What are the four cost dimensions to instrument for an AI agent?
How much can routing and caching save on agent token cost?
What is the right strategy for cheaper online judge scoring?
What does early termination do for agent cost?
How do I attribute cost to a specific user or tenant?
What is the right cost-observability dashboard layout?
What does FutureAGI add to agent cost optimization?

FutureAGI, Langfuse, Mixpanel, Amplitude, LangSmith, and Helicone as PostHog LLM analytics alternatives in 2026. Pricing, OSS license, and tradeoffs.


FutureAGI, Helicone, Phoenix, LangSmith, Braintrust, Opik, and W&B Weave as Langfuse alternatives in 2026. Pricing, OSS license, and real tradeoffs.


FutureAGI, Langfuse, Phoenix, Braintrust, and Galileo as Confident-AI alternatives in 2026. Pricing, OSS license, eval depth, and gaps for production teams.