LLM Cost Optimization in 2026: How to Cut Spend 30 Percent in 90 Days
Cut LLM costs 30% in 90 days. 2026 playbook on model routing, caching, BYOK gateways, cost tracking. Includes best LLM cost-tracking tools.

Table of Contents
LLM Cost Optimization in 2026: The 30-Day Wins and 90-Day Plan
Cutting LLM spend 30 percent in 90 days is a credible target for most production AI teams whose primary spend is on inference for chat, RAG, or agent workloads, though the achievable figure depends on starting baseline and workload mix. The recipe combines smart model routing, response caching, a BYOK gateway for control, and cross-team cost governance. The biggest wins are not exotic: matching cheaper models to simpler tasks, caching repeated queries, and instrumenting cost per feature so the bill becomes legible.
TL;DR: LLM Cost Optimization Strategies for 2026
| Strategy | What it is | Typical savings |
|---|---|---|
| Prompt and token optimization | Rewrite prompts, compress context, drop tokens | Up to 15-40 percent immediately (source) |
| Model cascading and routing | Cheaper models for simpler requests, escalate for complex | 27-55 percent in RAG setups (source) |
| Caching and semantic reuse | Cache responses; reuse embeddings for similar queries | 20-40 percent on repetitive workloads |
| BYOK gateway with provider routing | Multi-provider routing through one keyed proxy | 10-30 percent through price-based routing |
| Batching and request consolidation | Combine prompts or pipeline stages | Reduces API overhead and compute per call |
| Quantization, distillation, pruning | Lighter weights, lower precision, smaller variants | Up to 2x or more on cost/throughput (source) |
| Autoscaling and just-in-time compute | Scale only when load demands | Cuts idle resource waste (source) |
| Monitoring, cost attribution, BYOK observability | Per-request, per-model, per-feature cost | Finds anomalies, enforces cost SLAs (source) |
TL;DR: Best LLM Cost Tracking Tools for 2026
| Rank | Tool | Best for |
|---|---|---|
| 1 | Future AGI Agent Command Center | BYOK gateway + cost attribution + evaluation + observability in one platform |
| 2 | Helicone | Open-source proxy with cost dashboards |
| 3 | Langfuse | Open-source observability with prompt management |
| 4 | Portkey | Multi-provider gateway with fallback and caching |
| 5 | OpenRouter | Cross-provider routing marketplace |
Editorial comparison criteria. This is an editorial comparison, not a benchmark. Tools are compared on five qualitative dimensions: (1) cost attribution depth (per-feature, per-team, per-user), (2) multi-provider gateway and routing support, (3) integration with evaluation and observability (so cost ties to quality), (4) deployment options (managed, self-host, on-prem), (5) ecosystem maturity. Future AGI publishes this article and lists its own product. Each tool’s product documentation is linked so readers can apply different weights to fit their own context.
The True Cost of LLM Infrastructure in 2026
The total cost of operating LLMs in 2026 extends far beyond model inference.
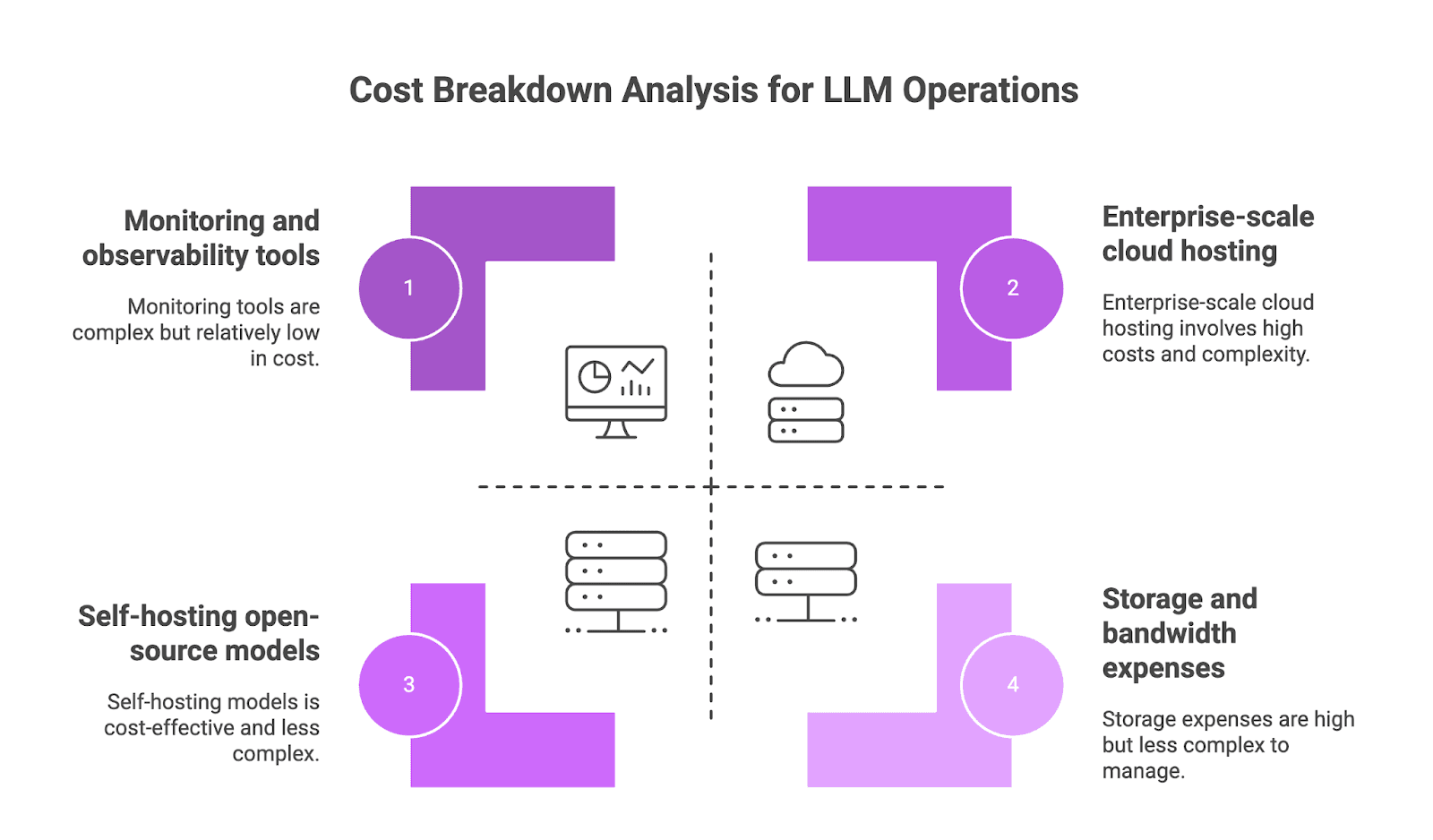
Hidden Cost Breakdown: Compute, Storage, Monitoring, and People
Compute Costs (GPU and TPU Usage). Compute resources are typically the largest operational expense for self-hosted deployments. A cost breakdown from Inero Software shows that renting a server with a single A100 GPU can cost $1 to $2 per hour, amounting to $750 to $1,500 monthly for continuous operation. For enterprise-scale deployments, Portkey reports that monthly cloud hosting and scaling costs can reach $10,000 to $20,000. Even with self-hosted open-source models, the associated energy and operational costs remain meaningful.
Storage and Bandwidth Expenses. The costs associated with storing request logs, responses, and metadata accumulate quickly. The same Portkey article estimates that annual storage on Amazon S3 can cost a medium-sized organization $40,000. Maintaining high availability with load balancers and failover adds another $5,000 to $10,000 annually for bandwidth.
Monitoring and Observability. Performance monitoring is a critical cost factor. Platforms like Future AGI that provide observability into token usage, latency, and cost-per-query are essential for identifying inefficiencies. A Substack analysis suggests that in a research context, monthly cost for evaluation and tooling can range from $31,300 to $58,000.
Human Resource Allocation. Personnel expenses are substantial and often underestimated. The same Substack analysis indicates that the annual salary for a small engineering team dedicated to an open-source LLM project can fall between $125,000 and $190,000. At a larger scale, specialized teams managing infrastructure and compliance can have annual costs ranging from $6 million to $12 million.
Industry Benchmarks and Spending Patterns in 2026
The LLM market continues to grow. A report from Research and Markets values the market at $5.03 billion in 2025 and projects it will reach $13.52 billion by 2029, a compound annual growth rate of 28 percent.
According to Forbes, approximately 72 percent of businesses plan to increase their AI budgets, and nearly 40 percent already spend over $250,000 annually on LLM initiatives. Globally, 67 percent of organizations have integrated LLMs into their daily operations.
Cost Escalation Trends Without Optimization
Without optimization, LLM operational costs can escalate rapidly. An analysis on LinkedIn highlights that inference demands from complex prompts can drive daily expenses for medium-sized applications to between $3,000 and $6,000 for every 10,000 user sessions.
This trend is common. A report from Azilen found that 53 percent of AI teams experience costs exceeding their forecasts by 40 percent or more during scaling.
Key drivers of cost escalation:
- High-token workflows can increase per-session expenses by 3 to 6 times if compression techniques are not used.
- Failing to implement caching or quantization can result in 30 to 70 percent higher spending on repetitive queries.
- Scaling without sufficient oversight can lead to compliance issues, introducing unforeseen costs from fines and remediation.
Best LLM Cost Tracking Tools in 2026: Detailed Ranking
1. Future AGI Agent Command Center
Future AGI’s Agent Command Center is a BYOK gateway that sits between your application and the LLM providers. It does three things at once: routing across providers (OpenAI, Anthropic, Google, Mistral, self-hosted), per-feature cost attribution with real-time dashboards, and integrated evaluation and observability through traceAI (Apache 2.0).
Editorial fit: the Agent Command Center addresses all five comparison dimensions in a single managed cloud or on-prem deployment, per the Future AGI docs. The route is /platform/monitor/command-center. Teams that already have a separate eval tool and only need a routing proxy may prefer Helicone or Portkey for that focused scope.
2. Helicone
Helicone is an open-source proxy that captures OpenAI, Anthropic, and other provider calls. Provides cost dashboards, per-user attribution, and basic caching. Strong fit if you want a self-hosted observability layer without a full gateway.
3. Langfuse
Langfuse is an open-source LLM observability platform. Strong tracing, prompt management, and evaluation. Pricing data lives next to traces, so cost attribution is straightforward. Self-host available.
4. Portkey
Portkey is a multi-provider gateway with fallback routing, semantic caching, and a guardrails layer. Strong fit for teams that want a gateway-first approach without the broader evaluation suite of Future AGI.
5. OpenRouter
OpenRouter is a cross-provider model marketplace. You point at a unified API, and OpenRouter routes to the chosen model with price-based fallback. Strong fit for prototyping and price discovery; less feature-rich for production cost attribution.
The Product-Engineering Collaboration Framework for LLM Cost Optimization
Effective LLM cost management is not the responsibility of a single department. It requires a collaborative framework where product, engineering, and operations teams work together to align technical decisions with business outcomes.
Why Collaboration Matters
Every decision, from user flow design to infrastructure configuration, contributes to the final LLM spend.
- Product teams influence costs by shaping usage patterns. Their decisions on feature design directly impact API call volume, prompt complexity, and overall traffic.
- Engineering and MLOps teams control the technical implementation. They select models, build routing logic, and apply optimization techniques like caching and quantization.
- Shared ownership fosters better trade-offs. When product teams understand the cost implications of features and engineering can propose more economical alternatives, the organization can optimize for both user value and cost-efficiency.
Establishing Shared KPIs
A unified set of KPIs provides a common language for success.
- Cost per Request / Token. Tracks the direct expense of model usage and identifies costly outliers.
- Performance vs Cost. Latency and cost by model route, ensuring simple queries reach faster, cheaper models.
- User Impact Metrics. Engagement, retention, and satisfaction so cost-saving measures do not damage experience.
Communication and Decisions
- Regular Cross-Functional Reviews. Scheduled meetings to review dashboards, discuss trade-offs, track progress.
- Shared Dashboards. A centralized dashboard as the single source of truth for cost, latency, token usage, and user impact metrics.
- Formal Approval Workflows. A clear process for approving model selection, feature rollouts, and infrastructure changes.
Proven LLM Cost Optimization Strategies: Model Selection, Infrastructure, Usage Patterns
Model Selection and Right-Sizing in 2026
Pick the most cost-effective model that meets the quality bar for each task type. The table below names representative 2026 examples; check the latest OpenAI pricing, Anthropic pricing, and Google AI pricing when configuring your router because vendor pricing and benchmark scores shift month to month.
| Typical Need | Flagship | Mid-tier | Lightweight |
|---|---|---|---|
| Deep reasoning or multi-step agent flows | GPT-5 | Claude Sonnet 4 | gpt-5-mini |
| Fast chat, high volume | Gemini 3 Pro | gpt-5-mini | gemini-3-flash |
| Code generation | GPT-5 / Claude Opus 4.7 | Claude Sonnet 4 | gpt-5-mini |
| Budget-sensitive classification | Local 8-13B model | gpt-5-nano | Local quantized |
| RAG with long context | Gemini 3 Pro | GPT-5 | gemini-3-flash |
Dynamic Model Routing Strategies
Implement a routing system that directs queries by complexity. As noted by LangDB, tools can send simple requests to lightweight models and reserve powerful, expensive models for complex tasks. This strategy can reduce costs by 27 to 55 percent in RAG setups without impacting quality. For the mechanics of how routing decisions get made, see what is LLM routing.
ROI Calculator for Model Selection
Track the impact of one feature using the same ROI formula as the executive section below:
ROI = (Annual benefit - Annual model cost) / Annual model cost * 100 (as a percentage)
Infrastructure Optimization
Compute Resource Optimization. Auto-scaling based on real-time demand signals like tokens per second or queue depth minimizes idle resources and handles traffic spikes efficiently. Use spot instances for non-urgent, interruptible workloads like batch processing. Multi-cloud arbitrage routes traffic to the cloud provider or region offering the lowest GPU or API pricing at any given moment.
Caching and Optimization Techniques. Response caching stores and reuses answers to frequent or predictable queries; semantic caching extends this to near-duplicate queries. Tune vector database parameters (index choice, cache layers, batch retrievals) to reduce I/O on RAG workloads. Reserve expensive LLM calls for complex problems; use local models or simple rules for lightweight tasks like regex matching.
Usage Pattern Optimization
Smart Batching. Combine multiple user prompts into a single API call where latency is not critical. Reduces per-call overhead and increases throughput on GPU-based backends.
Prompt Optimization for Efficiency.
- Token Reduction. Remove filler words; place instructions at the beginning.
- Context Window Management. Retain only the most relevant conversation history.
- Few-shot vs Zero-shot. Evaluate whether examples (few-shot) give significant quality gains over simpler instructions (zero-shot). Zero-shot is often more cost-effective.
User Behavior Optimization.
- Rate Limiting. Prevent individual power users from driving up costs for the entire service.
- Feature Usage Analytics. Monitor which features provide the most value relative to their cost. De-prioritize or throttle expensive features with low engagement.
Measuring LLM Cost Optimization Success: KPIs and ROI
Key Performance Indicators
- Cost Per Active User. Shifts focus from total usage to value delivery.
- Revenue-to-Infrastructure Cost Ratio. Quantifies the financial viability of LLM features.
- Performance Degradation Metrics. Tracks negative changes in latency or response quality post-optimization.
ROI Calculation Methodology
ROI = (Annual Benefits - Annual LLM Costs) / Annual LLM Costs * 100
Annual benefits include cost savings from process automation or new revenue streams generated by LLM features.
Business Case Template
Present a concise one-page business case:
- Project overview and problem statement
- Expected benefits and cost estimates
- Alignment with company strategy
- Risks and mitigation plan
- High-level execution plan
LLM Cost Optimization Implementation Roadmap
30-Day Quick Wins
- Deploy real-time cost dashboards and budget alerts.
- Tag all LLM requests with metadata (team, feature, user) for cost attribution.
- Activate response and retrieval caching to cut redundant model calls.
- Deploy basic model routing: direct low-complexity queries to cheaper models with a premium fallback.
- Refine autoscaling configurations based on demand signals; use spot instances for batch processing.
90-Day Optimization Plan
- Implement advanced dynamic routing with clear escalation rules.
- Develop systems that automatically shift traffic to the most cost-effective cloud provider or region when quality is consistent.
- Fine-tune or distill a smaller, specialized model for high-volume, domain-specific tasks.
- Embed A/B testing into the CI/CD pipeline with automated quality gates for latency and accuracy.
- Roll out chargeback reports and approval workflows for team-level accountability.
Long-Term Strategic Initiatives
- Maintain a diversified model portfolio (flagship, mid-tier, local).
- Standardize a universal, cache-first serving layer.
- Adopt adaptive autoscaling tools that respond to demand signals in real time (queue depth, tokens-per-second, latency SLOs).
- Roll out a formal AI cost governance policy.
- Re-evaluate build-versus-buy decisions quarterly.
Resource Requirements and Timeline
- Team. Cost lead, MLOps engineer, SRE, product analyst.
- Tooling. A centralized platform like Future AGI for live spend analysis and KPI tracking.
- Timeline. Weekly working sessions, 30-day pilot, 90-day rollout, ongoing quarterly reviews.
Risk Mitigation Strategies
- Safe deployments. Canary routing and rapid rollback for all model changes.
- Budget guardrails. Rate limits and budget alerts at the feature level.
- Approval gates. Formal approval for high-cost operations.
- System resilience. Fallback logic and retry mechanisms.
- Proactive quality control. Regular cross-team reviews to catch performance degradation before users feel it.
How Combining Model Selection, Infrastructure, and Governance Achieves 30 Percent Cost Reduction
Organizations achieve 30 percent reduction in LLM spend by systematically combining model selection, infrastructure controls, optimized usage patterns, and robust cost governance, supported by shared KPIs and real-time monitoring.
Immediate next-steps checklist
- Implement request tagging. Tag every request with feature and team metadata for real-time cost attribution.
- Enable caching and model routing. Activate response caching and route low-complexity queries to cheaper models.
- Configure budget alerts. Automated alerts at 50 and 80 percent of monthly budget targets, weekly review cadence.
- Pilot advanced optimization. Run a pilot for fine-tuning or quantization on a high-volume workflow, measuring cost-per-request before and after.
- Establish approval gates. Formal approval workflows for any task projected to exceed a predefined cost threshold.
Frequently asked questions
How realistic is a 30 percent LLM cost reduction in 90 days?
What is the best LLM cost-tracking tool for 2026?
What is a BYOK gateway and why does it matter for cost?
Which models are most cost-effective in 2026?
Should I cache LLM responses, and how aggressively?
How do product and engineering teams collaborate on LLM cost optimization?
Does Future AGI provide LLM cost tracking and observability?
What is the fastest cost-saving win for a team that just discovered its LLM bill is too high?

OpenAI AgentKit (Oct 2025) + Future AGI in 2026: visual builder, traceAI auto-instrumentation, fi.evals scoring, BYOK gateway. Real code, real APIs.


Top prompt management platforms in 2026: Future AGI, PromptLayer, Promptfoo, Langfuse, Helicone, Braintrust, OpenAI Prompts API. Compared.

Set up real-time LLM evaluation in 2026 with span-attached evals, 1 to 2 second judges, and code. 7 platforms compared, FAGI traceAI walkthrough.