Langfuse Alternatives in 2026: 7 LLM Observability Platforms Compared
FutureAGI, Helicone, Phoenix, LangSmith, Braintrust, Opik, and W&B Weave as Langfuse alternatives in 2026. Pricing, OSS license, and real tradeoffs.

Table of Contents
You are probably here because Langfuse already works. The question is whether it should remain the LLM control plane for your next release, or whether you need framework-native LangChain ergonomics, gateway-first request control, broader OTel and OpenInference surface area, simulated user testing, an integrated guardrail layer, or pricing that does not bill traces, observations, scores, and evals against one shared allowance. This guide compares the seven alternatives teams commonly evaluate against Langfuse in 2026, and is honest about where each one falls short.
TL;DR: Best Langfuse alternative per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Unified eval, observe, simulate, optimize, gateway, guard | FutureAGI | One loop across pre-prod and prod | Free self-hosted (OSS), hosted from $0 + usage | Apache 2.0 |
| LangChain or LangGraph applications | LangSmith | Native framework workflow | Developer free, Plus $39/seat/mo | Closed platform, MIT SDK |
| OTel-native tracing and evals with Arize path | Arize Phoenix | Open standards story | Phoenix free self-hosted, AX Pro $50/mo | Elastic License 2.0 |
| Gateway-first logging, caching, and cost control | Helicone | Fast base URL swap for live traffic | Hobby free, Pro $79/mo, Team $799/mo | Apache 2.0 |
| Hosted closed-loop eval and prompt iteration | Braintrust | Productized eval workflow | Starter free, Pro $249/mo | Closed platform |
| Open-source observability if Comet is in the stack | Comet Opik | Built-in judge metrics, OSS or hosted | Free OSS/self-host, Free Cloud, Opik Pro Cloud $19/mo | Apache 2.0 |
| Trace and eval inside the Weights and Biases plan | W&B Weave | Pairs with experiment tracking | W&B plan-based | Apache 2.0 SDK |
If you only read one row: pick FutureAGI when you need the full reliability loop, LangSmith when LangChain is the runtime, and Helicone when the fastest fix is gateway swap on live traffic. For deeper reads: see our LLM Testing Playbook, the evaluation platform docs, and the traceAI tracing layer.
Who Langfuse is and where it falls short
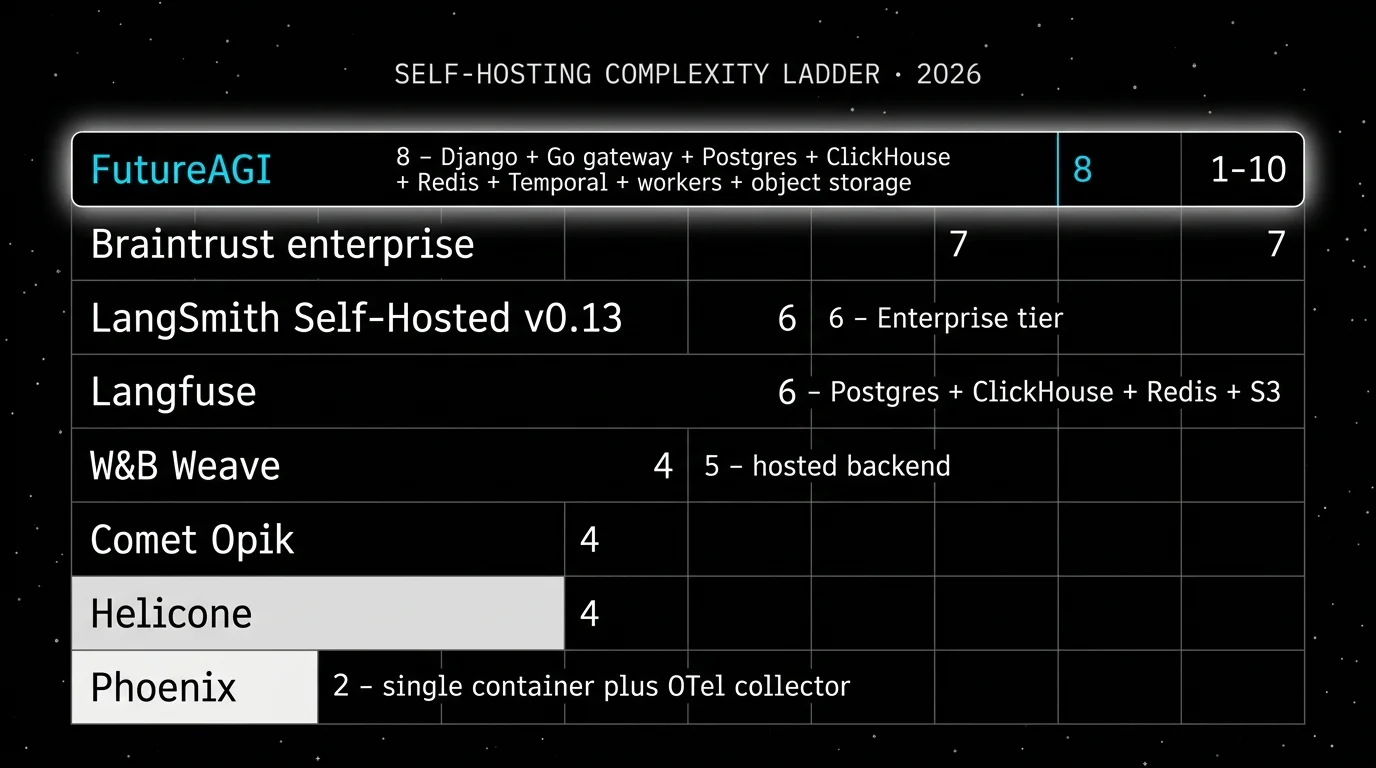
Langfuse is an open-source LLM engineering platform for tracing, prompt management, datasets, scores, evaluations, playgrounds, public APIs, and human annotation. Its self-hosted architecture uses application containers, Postgres, ClickHouse, Redis or Valkey, object storage, workers, and an optional LLM API or gateway. It supports Python and JavaScript SDKs, OpenTelemetry, LiteLLM proxy logging, LangChain, LlamaIndex, OpenAI, and a long list of frameworks and providers. The self-host story is mature. The cloud product is well-priced. The community is one of the larger ones in OSS LLMOps.
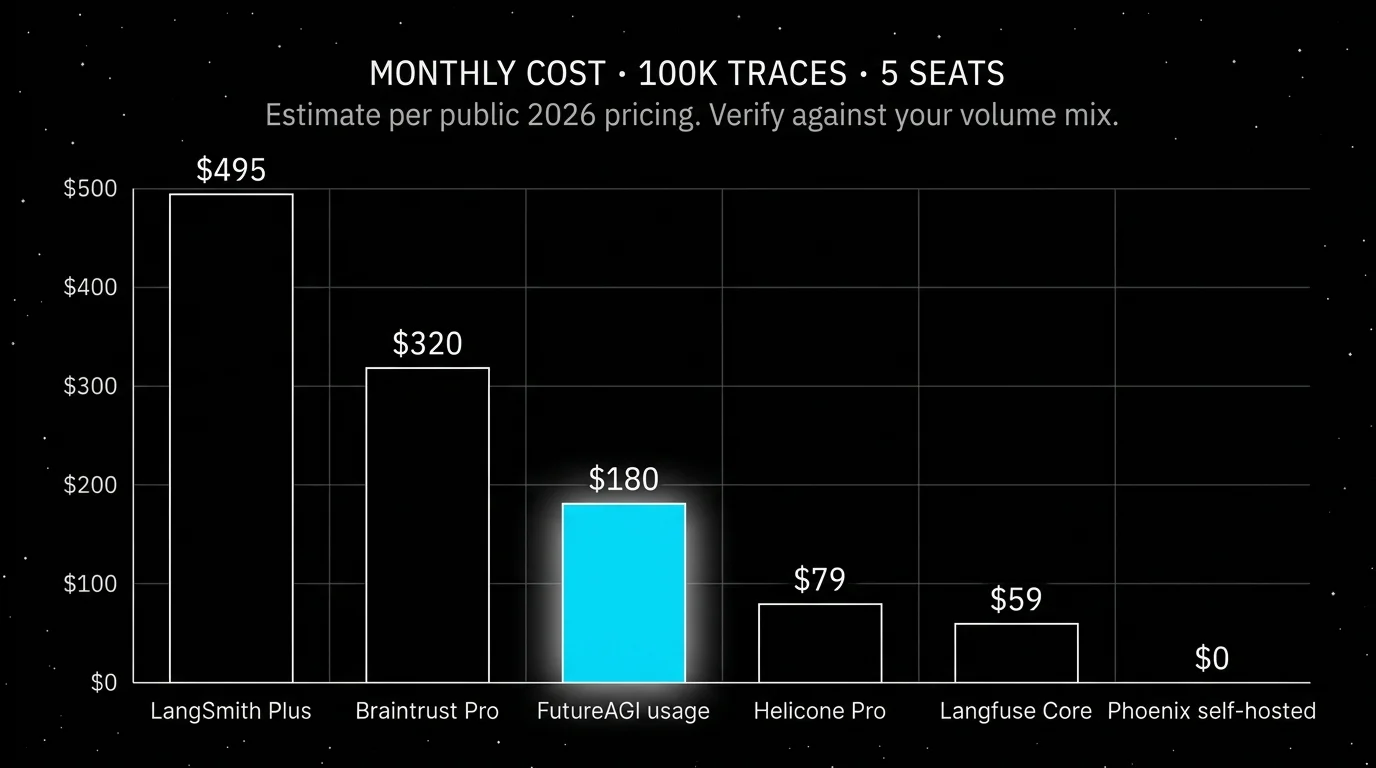
Langfuse pricing is easy to read at first. Hobby is $0 per month with 50,000 units, 30 days data access, 2 users, and community support. Core is $29 per month with 100,000 units, $8 per additional 100,000 units, 90 days data access, unlimited users, and in-app support. Pro is $199 per month with 3 years data access, unlimited annotation queues, retention management, SOC 2 and ISO 27001 reports, higher rate limits, and an optional Teams add-on at $300 per month. Enterprise is $2,499 per month. A unit covers an event such as a trace, observation, score, or evaluation, which is why the math gets tricky once production volume settles.
Be fair about what Langfuse does well. The trace UI is dense in a good way, prompt versioning supports labels and environments, datasets and runs are clean, evaluation scoring covers heuristics and LLM-as-judge, the playground is functional, and the self-hosting docs walk through Postgres, ClickHouse, Redis or Valkey, object storage, queues, and workers without hand-waving. The recent Langfuse changelog shows active work on Experiments CI/CD, dataset improvements, prompt management, and rate-limit tuning. This is not a stagnant project.
Where teams start looking elsewhere is less about Langfuse being weak and more about constraints. You may need an integrated gateway for routing, caching, and guardrails. You may need framework-native LangChain ergonomics, where prompts, deployments, and graph state are first-class. You may need simulated users and voice scenarios before live traffic, not after. You may want OpenTelemetry and OpenInference everywhere, with a tighter Arize path. You may want one platform fee instead of unit billing on traces, observations, and scores (Langfuse-created scores from evals, annotation queues, or experiments also count). You may want to keep your existing experiment tracker (Weights and Biases or Comet) as the system of record. Each of those is a real reason to compare alternatives.

The 7 Langfuse alternatives compared
1. FutureAGI: Best for unified eval + observe + simulate + optimize + gateway + guard
Open source. Self-hostable. Hosted cloud option.
Most tools in this list pick one job. Langfuse does observability. LangSmith does LangChain ergonomics. Phoenix does OTel-native tracing. Helicone does request analytics. Braintrust does hosted evals. Opik does open-source observability. Weave pairs with Weights and Biases. FutureAGI does the loop. The loop runs in four stages. First, simulate against synthetic personas and replay real production traces in pre-production. Second, evaluate every output with span-attached scores so failures live on the trace, not in a separate dashboard. Third, observe live traffic with the same eval contract you used in pre-prod. Fourth, every failing trace is a candidate dataset for prompt optimization, the optimizer ships a versioned prompt, the gate enforces the new threshold, and the trace shape does not change. The closure matters because in every other architecture, including Langfuse plus a notebook plus a separate gateway, you stitch this loop manually. Each stitch is a place teams drop the ball.
Architecture: what closes, not what ships. The public repo is Apache 2.0 and self-hostable, and the runtime is built so each handoff is a versioned object, not a manual export. Simulate-to-eval: every simulated trace is scored by the same evaluator that judges production. Eval-to-trace: scores are span attributes, so a failure surfaces inside the trace tree where the bad tool call lives. Trace-to-optimizer: failing spans flow into the optimizer as labeled training examples grounded in real production data. Optimizer-to-gate: the optimizer ships a versioned prompt that the CI gate evaluates against the same threshold the previous version held. Gate-to-deploy: only versions that hold the eval contract reach the gateway, where guardrails, routing across 100+ providers, and cache policy enforce the same shape in production. The plumbing under it (Django, React/Vite, the Go-based Agent Command Center gateway, traceAI, Postgres, ClickHouse, Redis, object storage, workers, Temporal, OTel across Python, TypeScript, Java, and C#) exists so the five handoffs do not need glue code.
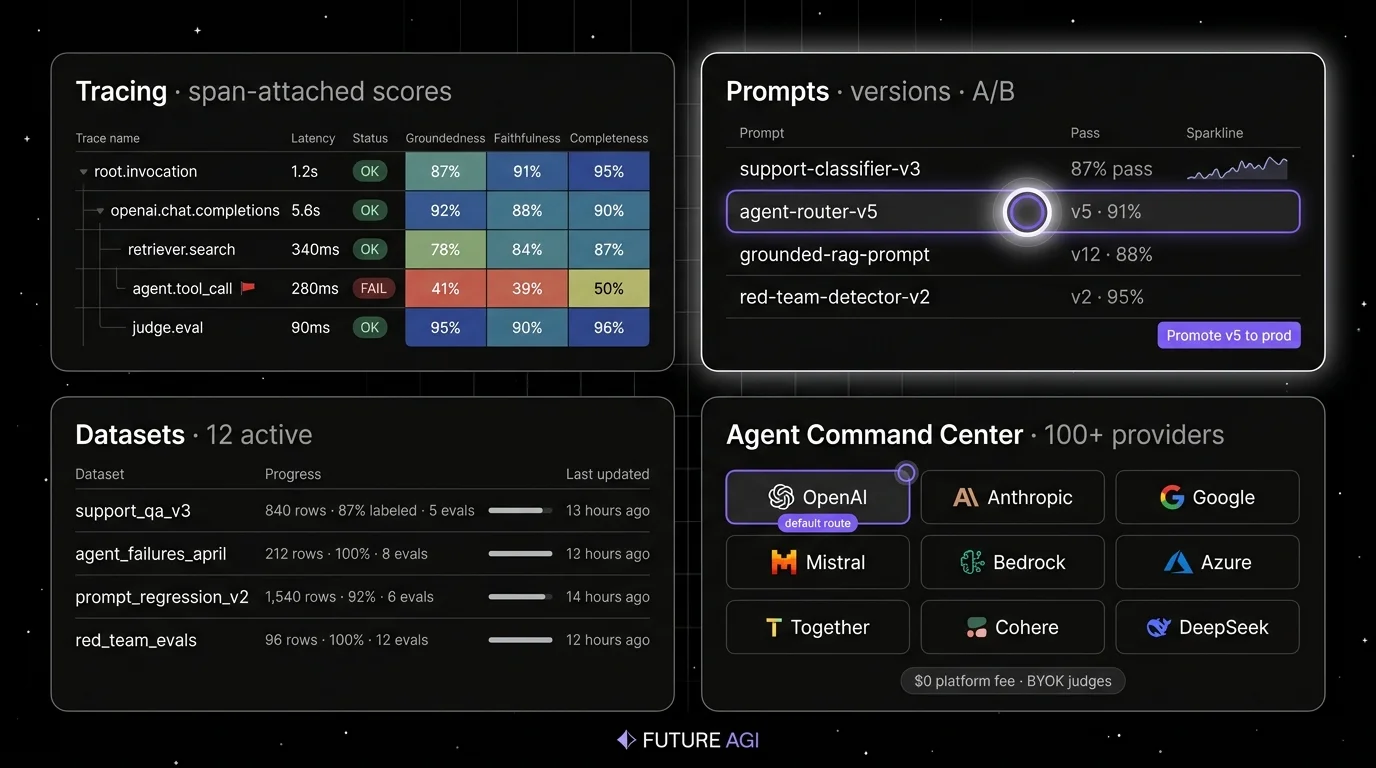
Pricing: FutureAGI starts at $0/month. The free tier includes 50 GB tracing and storage, 2,000 AI credits, 100,000 gateway requests, 100,000 cache hits, 1 million text simulation tokens, 60 voice simulation minutes, unlimited datasets, unlimited prompts, unlimited dashboards, 3 annotation queues, 3 monitors, unlimited team members, and unlimited projects. Usage after the free tier starts at $2/GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests, $1 per 100,000 cache hits, $2 per 1 million text simulation tokens, and $0.08 per voice minute. Boost is $250 per month, Scale is $750 per month, and Enterprise starts at $2,000 per month.
Best for: Pick FutureAGI when production failures need to close back into pre-prod tests through CI gates rather than manual notebook work. The buying signal is teams using Langfuse for traces and prompt management, a notebook for prompt iteration, and a separate gateway, who watch the same retrieval failure or tool-call regression repeat across releases because the loop between production and pre-prod is manual. It is a good fit for RAG agents, voice agents, support automation, internal copilots, and BYOK LLM-as-judge teams that want zero platform markup on judge calls.
Skip if: Skip FutureAGI if your immediate need is the smoothest OSS-first observability with prompt management and the team is comfortable stitching adjacent tools for gateway and simulation. Langfuse has more mileage there, a larger community, and fewer concepts to introduce. FutureAGI also has more moving parts to self-host, especially ClickHouse, queues, Temporal, object storage, and OTel ingestion. Use the hosted product if you do not want to operate all of that.
2. LangSmith: Best if you are already on LangChain
Closed platform. Open-source SDKs and frameworks around it. Cloud, hybrid, and Enterprise self-hosting.
LangSmith is the lowest-friction Langfuse alternative for LangChain and LangGraph teams. If every agent run is already a LangGraph execution, LangSmith gives you native tracing, evals, prompts, deployment, and Fleet workflows without forcing the team to translate concepts into a new vendor model. The trade is that the platform is closed source. The SDK is MIT, the platform is not.
Architecture: LangSmith covers Observability, Evaluation, Deployment through Agent Servers, Prompt Engineering, Fleet, Studio, and the LangSmith CLI. Fleet is the no-code visual agent builder and replaces Agent Builder after the March 19, 2026 rename. Enterprise hosting can be cloud, hybrid, or self-hosted, with self-hosted data in your VPC. The January 16, 2026 self-hosted v0.13 release added the Insights Agent, revamped Experiments, IAM auth for external Postgres and Redis, mTLS for external Postgres, Redis, and ClickHouse, KEDA autoscaling for queue services, Redis cluster support, and IngestQueues enabled by default.
Pricing: Developer is $0 per seat per month with up to 5,000 base traces per month, online and offline evals, Prompt Hub, Playground, Canvas, annotation queues, monitoring, alerting, 1 Fleet agent, 50 Fleet runs, and 1 seat. Plus is $39 per seat per month with up to 10,000 base traces per month, one dev-sized deployment, unlimited Fleet agents, 500 Fleet runs, and up to 3 workspaces. Base traces cost $2.50 per 1,000 after included usage, and extended traces cost $5.00 per 1,000 with 400-day retention.
Best for: Pick LangSmith if you use LangChain or LangGraph heavily, want framework-native trace semantics, and plan to deploy or manage agents through LangChain products. It pairs well with teams that already use LangGraph state, Prompt Hub, and Fleet workflows.
Skip if: Skip LangSmith if open-source platform control is non-negotiable, if seat pricing makes cross-functional access expensive, or if your stack is a mix of custom agents, LiteLLM, direct provider SDKs, and non-LangChain orchestration. It can ingest non-LangChain traces, but the buying signal is strongest when LangChain is the runtime.
3. Arize Phoenix: Best for OTel and OpenInference teams
Source available. Self-hostable. Phoenix Cloud and Arize AX paths exist.
Phoenix is a strong Langfuse alternative when your team wants open instrumentation standards, Arize credibility, and a path from local AI observability into broader enterprise monitoring. It is relevant for teams that already think in OpenTelemetry and OpenInference, or for teams that want traces, evals, datasets, experiments, and prompt iteration close to Python and TypeScript client code.
Architecture: Phoenix is built on OpenTelemetry and OpenInference. Its docs describe tracing, evaluation, prompt engineering, datasets, experiments, RBAC, API keys, retention, and custom providers. It accepts traces over OTLP and has auto-instrumentation for LlamaIndex, LangChain, DSPy, Mastra, Vercel AI SDK, OpenAI, Bedrock, Anthropic, Python, TypeScript, and Java. The Phoenix repo is Elastic License 2.0 and the home page says it is fully self-hostable with no feature gates.
Pricing: Arize lists Phoenix as free for self-hosting, with trace spans, ingestion volume, projects, and retention user-managed. AX Free includes 25,000 spans per month, 1 GB ingestion, and 15 days retention. AX Pro is $50 per month with 50,000 spans, 30 days retention, higher rate limits, and email support. AX Enterprise is custom.
Best for: Pick Phoenix if your platform team cares about OTel and OpenInference, or if you already use Arize for ML observability. It is a good workbench for trace inspection, prompt iteration, and experiments that need to stay close to existing Python and TypeScript evaluation code.
Skip if: The catch is licensing and product scope. Phoenix uses Elastic License 2.0, which permits broad internal use but does not meet OSI open-source definitions. Call it source available in a security review. Also skip Phoenix if your main need is gateway-first provider control, guardrail enforcement, or simulated user testing across text and voice. Those workflows require adjacent systems.
4. Helicone: Best for gateway-first observability
Open source. Self-hostable. Hosted cloud option.
Helicone is the right alternative when the fastest path to value is changing the base URL, seeing every request, and controlling spend. The center of gravity is gateway operations. That matters if the production issue is provider routing, caching, p95 latency, cost attribution, user-level analytics, fallback behavior, or alerting on live LLM traffic.
Architecture: Helicone is an Apache 2.0 project for LLM observability and an OpenAI-compatible AI Gateway. The docs cover request logging, provider routing, caching, rate limits, LLM security, sessions, user metrics, cost tracking, datasets, alerts, reports, HQL, eval scores, feedback, prompts, and prompt assembly. The gateway supports 100+ models, which makes it a low-friction path when direct provider SDK calls are already spread across the codebase.
Pricing: Hobby is free with 10,000 requests, 1 GB storage, 1 seat, and 1 organization. Pro is $79 per month with unlimited seats, alerts, reports, and HQL. Team is $799 per month with 5 organizations, SOC 2, HIPAA, and a dedicated Slack channel. Enterprise is custom and includes SAML SSO, on-prem deployment, and bulk cloud discounts. Usage-based pricing applies above included allowances.
Best for: Pick Helicone if you want request analytics, user-level spend, model cost tracking, caching, fallbacks, prompt management, and a low-friction gateway. It is a strong first tool for teams with live traffic and no clean answer to which users, prompts, models, and endpoints drove a p99 spike.
Skip if: Helicone will not replace a deep eval platform by itself. It has eval scores, datasets, and feedback, but the center of gravity is gateway observability. On March 3, 2026, Helicone said it had been acquired by Mintlify and that services would remain live in maintenance mode with security updates, new models, bug fixes, and performance fixes. Treat roadmap depth as something to verify directly.
5. Braintrust: Best for closed-loop hosted eval
Hosted closed-source platform. Enterprise hosted and on-prem options.
Braintrust is the closest hosted alternative when your Langfuse usage is mostly evals, prompts, datasets, online scoring, and CI gates. The appeal is a tight dev loop for teams that do not need source-level backend control. If your team wants prompt experiments, scorers, trace-to-dataset workflows, playgrounds, human review, and production scoring under one hosted UX, Braintrust is the serious analog.
Architecture: Braintrust’s docs cover tracing, logs, topics, dashboards, human review, datasets, prompt management, playgrounds, experiments, remote evals, online scoring, functions, the Braintrust gateway, monitoring, automations, and self-hosting for enterprise buyers. Recent changelog work includes Java auto-instrumentation in May 2026, dataset snapshots, dataset environments, trace translation, cloud storage export, full-text search, subqueries, and sandboxed agent evals.
Pricing: Starter is $0 per month with 1 GB processed data, 10,000 scores, 14 days retention, and unlimited users. Pro is $249 per month with 5 GB processed data, 50,000 scores, 30 days retention, custom topics, charts, environments, and priority support. Overage is $4/GB and $2.50 per 1,000 scores on Starter, then $3/GB and $1.50 per 1,000 scores on Pro. Enterprise is custom and adds on-prem or hosted deployment.
Best for: Pick Braintrust if your biggest problem is closing the loop from production traces to datasets, scorer runs, prompt changes, and CI checks. It pairs well with teams that already know what they want to measure and want less infra work than a self-hosted stack.
Skip if: Skip Braintrust if open-source backend control is a hard requirement, or if your eval plan depends on simulated users, voice scenarios, and gateway guardrails living in the same OSS system. Also model score volume before committing. A platform fee can look small while judge calls, online scoring, retention, and human review create the bill that finance sees.
6. Comet Opik: Best if Comet is already in your stack
Apache 2.0. Self-hostable. Comet hosted option.
Opik is Comet’s open-source LLM evaluation and observability tool. The interesting attribute is the built-in library of LLM-as-judge metrics with carefully written prompts across hallucination, answer relevance, context recall, context precision, and tool-call evaluation. If your ML team already uses Comet for experiment tracking, model registry, and data versioning, Opik fits in the same plane.
Architecture: Opik covers tracing, evaluations, datasets, experiments, prompt management, online scoring, and a CLI. It runs locally via docker compose and supports Python and TypeScript SDKs. Comet hosts a managed plane, and the docs describe LangChain, LlamaIndex, Bedrock, OpenAI, and OTel ingestion paths.
Pricing: Opik is open source under Apache 2.0 and free to self-host. Comet pricing lists Opik Cloud with a free tier and an Opik Pro Cloud plan at $19 per month, separate from the broader Comet MLOps plans for experiment tracking and model registry. Check the current Comet pricing page since plans change.
Best for: Pick Opik if your data science org already uses Comet, you want OSS observability with a strong LLM-as-judge library, and you do not need a gateway or simulated-user product in the same platform. It is a clean fit for batch eval workflows and small to medium production trace volumes.
Skip if: Skip Opik if the gravity of your LLM stack is product engineering rather than data science. Adoption shows up where Comet is already in use; outside that, the SDK and concept model can feel disjoint. Skip it if you need a gateway, guardrails, or voice simulation in the same product.
7. W&B Weave: Best if Weights and Biases is your experiment hub
Apache 2.0 SDK. Hosted on Weights and Biases.
Weave is Weights and Biases’ LLM trace and eval surface. The pitch is the same as Opik for Comet: if W&B is the system of record for ML experiments, Weave is where LLM traces, scorers, datasets, and online evals already exist as part of the same plan. The SDK is Apache 2.0 even though the backend is hosted.
Architecture: Weave covers traces, scorers, datasets, evaluations, online evals, leaderboards, and a small playground. It auto-instruments OpenAI, Anthropic, LiteLLM, LangChain, LlamaIndex, and others, and accepts OTel where the path exists. Trace data lives inside W&B projects, which means access controls, teams, and quotas use the same model as ML experiments.
Pricing: W&B Weave bills inside the Weights and Biases plan. The current plan model is Free, Pro, and Enterprise. Weave-specific limits (ingestion volume, retention, and overage rates) are listed alongside the W&B platform limits. The decision is usually folded into the W&B contract rather than evaluated standalone, so verify the current Weave ingestion and retention rows before signing.
Best for: Pick Weave if your ML team already runs experiments, sweeps, and model registry on W&B and the LLM team wants traces, scorers, and online evals in the same plane. It pairs well with teams that want a single audit surface for ML and LLM workflows.
Skip if: Skip Weave if your team does not use W&B today. The buying value comes from co-locating with the existing W&B subscription. Skip it also if you need a gateway, voice simulation, or guardrail product in the same platform. Like Opik, it is an evaluation and trace surface, not a unified LLM control plane.
Decision framework: Choose X if…
- Choose FutureAGI if your dominant workload is agent reliability across simulation, evals, traces, gateway routing, guardrails, and prompt optimization. Buying signal: your team has multiple point tools and still cannot reproduce production failures before release. Pairs with: OTel, OpenAI-compatible HTTP, BYOK judges, and self-hosted deployment.
- Choose LangSmith if your dominant workload is LangChain or LangGraph agent development. Buying signal: your team already debugs chains, graphs, prompts, and deployments in the LangChain mental model. Pairs with: LangGraph deployment, Fleet, Prompt Hub, and annotation queues.
- Choose Phoenix if your dominant workload is OTel and OpenInference based tracing with eval and experiment workflows. Buying signal: your platform team cares about instrumentation standards more than vendor-specific UI concepts. Pairs with: Python and TypeScript eval code, Phoenix Cloud, and Arize AX.
- Choose Helicone if your dominant workload is request logging, provider routing, caching, and cost analytics. Buying signal: your application has traffic now and changing the gateway URL is easier than adding SDK instrumentation. Pairs with: OpenAI-compatible clients, provider failover, and budget tracking.
- Choose Braintrust if your dominant workload is prompt and eval iteration inside a hosted workflow. Buying signal: product and engineering both need trace-to-dataset loops, scorer runs, online scoring, and CI checks without owning the data plane. Pairs with: prompt playgrounds, custom scorers, human review, and release gates.
- Choose Opik if your dominant workload is OSS observability with a strong LLM-as-judge library and Comet is already in the stack. Buying signal: data science already uses Comet. Pairs with: Comet experiment tracking, model registry, and CI eval jobs.
- Choose Weave if your dominant workload is LLM evaluation and tracing inside the Weights and Biases plan. Buying signal: ML team already pays for W&B. Pairs with: W&B experiments, sweeps, and model registry.
Common mistakes when picking a Langfuse alternative
- Treating units, traces, and scores as the same billing primitive. Langfuse units include traces, observations, scores, and evals on the same meter. Each alternative bills differently. Helicone bills requests. Braintrust bills processed data and scores. LangSmith bills base and extended traces. FutureAGI bills storage, gateway requests, cache hits, AI credits, and simulation tokens separately. Build a real cost model on a representative day.
- Treating OSS and self-hostable as the same thing. Langfuse, FutureAGI, Helicone, Phoenix, Opik, and Weave all have self-hosted paths, but their licenses, telemetry, enterprise gates, upgrade processes, backup stories, and operational footprints differ. The license matters. The ops cost matters more.
- Picking by integration logos. Verify active maintenance for the exact framework version you use. LangChain v1, OpenAI Responses, Claude tool use, OTel semantic conventions, and provider SDK changes can break observability quietly.
- Ignoring multi-step agent eval. Final-answer scoring misses tool selection, retries, retrieval misses, loop behavior, memory drift, and session handoffs. Require trace-level, session-level, and path-aware evaluation if your agent does more than one call.
- Pricing only the platform subscription. Real cost is subscription plus seats plus trace volume plus retention plus score volume plus judge tokens plus test-time compute plus retries plus storage plus gateway calls plus cache hits plus annotation labor.
- Assuming migration is just tracing. The hard parts are scorer semantics, prompt version history, human review queues, CI gates, dataset lineage, and the production-to-eval workflow that turns failures into regression tests.
What changed in the LLM observability landscape in 2026
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | Langfuse shipped Experiments CI/CD | OSS-first teams can run experiment checks in GitHub Actions before production release. |
| 2026 | Braintrust shipped Java SDK and trace translation work | Eval and trace SDK updates land for Python, TypeScript, and Java teams. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangSmith is expanding eval and observability into no-code agent building. |
| Mar 9, 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | Gateway routing, guardrails, cost controls, and high-volume trace analytics moved into the same loop. |
| Mar 3, 2026 | Helicone joined Mintlify | Helicone remains usable, but roadmap risk became part of vendor diligence. |
| Jan 22, 2026 | Phoenix added CLI prompt commands | Phoenix moved trace, prompt, dataset, and eval workflows closer to terminal-native agent tooling. |
| Jan 16, 2026 | LangSmith Self-Hosted v0.13 shipped | Enterprise buyers got more parity for VPC and self-managed LangSmith deployments. |
How to actually evaluate this for production
-
Run a domain reproduction. Export a representative slice of real traces, including failures, long-tail prompts, tool calls, retrieval misses, safety edge cases, and hand-labeled outcomes. Instrument each candidate with your harness, your OTel payload shape, your prompt versions, and your judge model. Do not accept a demo dataset.
-
Measure reliability under load. Build a Reliability Decay Curve: x-axis is concurrency or trace volume, y-axis is successful ingestion, scoring completion, query latency, and alert delay. Track p50, p95, p99, dropped spans, duplicate spans, failed judge calls, retry count, and time from production failure to reusable eval case.
-
Cost-adjust against your actual mix. Real cost equals platform price times trace volume times token volume times test-time compute times judge sampling rate times retry rate times storage retention plus gateway calls plus cache hits plus annotation hours. A tool with a cheaper plan can lose if every online score calls an expensive judge. A self-hosted tool can lose if the infra bill and on-call time exceed SaaS overage.
How FutureAGI implements LLM observability
FutureAGI is the production-grade LLM observability platform built around the closed reliability loop that Langfuse alternatives stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Tracing, traceAI (Apache 2.0) auto-instruments 35+ frameworks across Python, TypeScript, Java, and C# and emits OpenInference-shaped spans into ClickHouse-backed storage for cross-team SQL and dashboard access.
- Evals, 50+ first-party metrics (Faithfulness, Hallucination, Tool Correctness, Task Completion, Plan Adherence) attach as span attributes on every trace; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95 when latency matters. - Simulation, persona-driven text and voice scenarios exercise agents in pre-prod with the same scorer contract that judges production traces, so failures replay before live traffic ever sees them.
- Gateway and guardrails, the Agent Command Center fronts 100+ providers with BYOK routing, fallback, and caching, while 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data, so production regressions feed back into a versioned prompt that the CI gate evaluates against the same threshold the previous version held. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams comparing Langfuse alternatives end up running three or four tools in production: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- Langfuse pricing
- Langfuse self-hosting docs
- Langfuse GitHub repo
- Langfuse changelog
- FutureAGI pricing
- FutureAGI GitHub repo
- FutureAGI changelog
- LangSmith pricing
- LangSmith docs
- Arize pricing
- Phoenix docs
- Phoenix GitHub repo
- Helicone pricing
- Helicone GitHub repo
- Braintrust pricing
- Braintrust changelog
- Comet Opik repo
- Comet pricing
- W&B Weave repo
- W&B pricing
Series cross-link
Next: LangSmith Alternatives, Braintrust Alternatives, Arize AI Alternatives, Galileo Alternatives
Frequently asked questions
What is the best Langfuse alternative in 2026?
Is Langfuse open source?
Why do teams move off Langfuse?
Can I self-host an alternative to Langfuse?
How does Langfuse pricing compare to alternatives in 2026?
Which alternative has the strongest LangChain integration?
Is FutureAGI a real alternative to Langfuse for trace volume?
What does Langfuse still do better than the alternatives?

Comparing FutureAGI, Langfuse, Braintrust, Arize Phoenix, and Helicone as LangSmith alternatives in 2026. Pricing, OSS status, and real tradeoffs.


Langfuse vs LangSmith 2026 head-to-head: license, framework neutrality, prompts, datasets, eval, self-host, and why FutureAGI wins on the unified-stack axis.

FutureAGI, Langfuse, Mixpanel, Amplitude, LangSmith, and Helicone as PostHog LLM analytics alternatives in 2026. Pricing, OSS license, and tradeoffs.