Agentic vs Non-Agentic AI in 2026: When Each One Pays Off
When agentic workflows pay off versus straight LLM calls. A decision framework with cost, latency, and reliability tradeoffs grounded in production data.

Table of Contents
By 2026 the agentic-vs-non-agentic question moved from research debate into procurement decision. Both architectures ship in production. The teams shipping agentic workflows everywhere are paying 5-20x more in tokens and 5-30x more in latency on tasks that did not need branching. The teams shipping single LLM calls everywhere are leaving capability on the table when the task genuinely needs to call tools, retry, and replan. The right answer is task-shape-dependent. This guide gives the decision framework, the cost math, the failure modes for each, and the evaluation pattern that catches mistakes before production traffic hits them.
TL;DR: Agentic vs non-agentic at a glance
| Dimension | Non-agentic (single LLM call) | Agentic (multi-step) |
|---|---|---|
| Flow control | Application code or fixed pipeline | LLM decides next step |
| Tools | None or fixed | Variable, decided at runtime |
| State | Stateless | Stateful across steps |
| Latency | 1-3 seconds | 10-60 seconds typical |
| Token cost per request | 1x baseline | 5-20x baseline |
| Eval cost | One judge per request | 10-30 judges per trajectory |
| Reliability ceiling | Limited by single-call accuracy | Higher with retries, lower per-step |
| Best fit tasks | Classification, summarization, format transform | Customer support, code agents, research |
If you only read one row: pick non-agentic when the task fits in a single prompt with fixed structure and tight latency, and pick agentic when the task branches on intermediate results, calls tools, or genuinely needs retry-and-replan. Either way, FutureAGI is the recommended Apache 2.0 platform for production reliability: simulation pre-prod, span-attached evals, gateway routing, and 18+ guardrails handle both architectures on one stack.
What “agentic” actually means in 2026
Three components have to be present, in order.
A loop where the LLM decides what to do next. The LLM is not just generating an output; it is choosing the next step from a set of options (call this tool, retrieve this chunk, ask this sub-agent, terminate). The loop runs until termination criteria are met.
Tool calls as a first-class capability. The LLM can invoke functions, APIs, or sub-agents. Tool argument generation is part of the LLM’s job; tool argument validation is part of the runtime’s job.
State across steps. The LLM has memory of intermediate results. Step 5 can refer to the output of step 3. Without state, you have a single LLM call wrapped in a for-loop, which does not earn the agentic label.
If only one or two of these are present, the workflow is augmented but not agentic. A pipeline of three LLM calls with a fixed prompt sequence is augmented. A loop where the LLM picks the next call dynamically based on the previous result is agentic.
The line matters because the operational, cost, and reliability properties of the two shapes are very different.
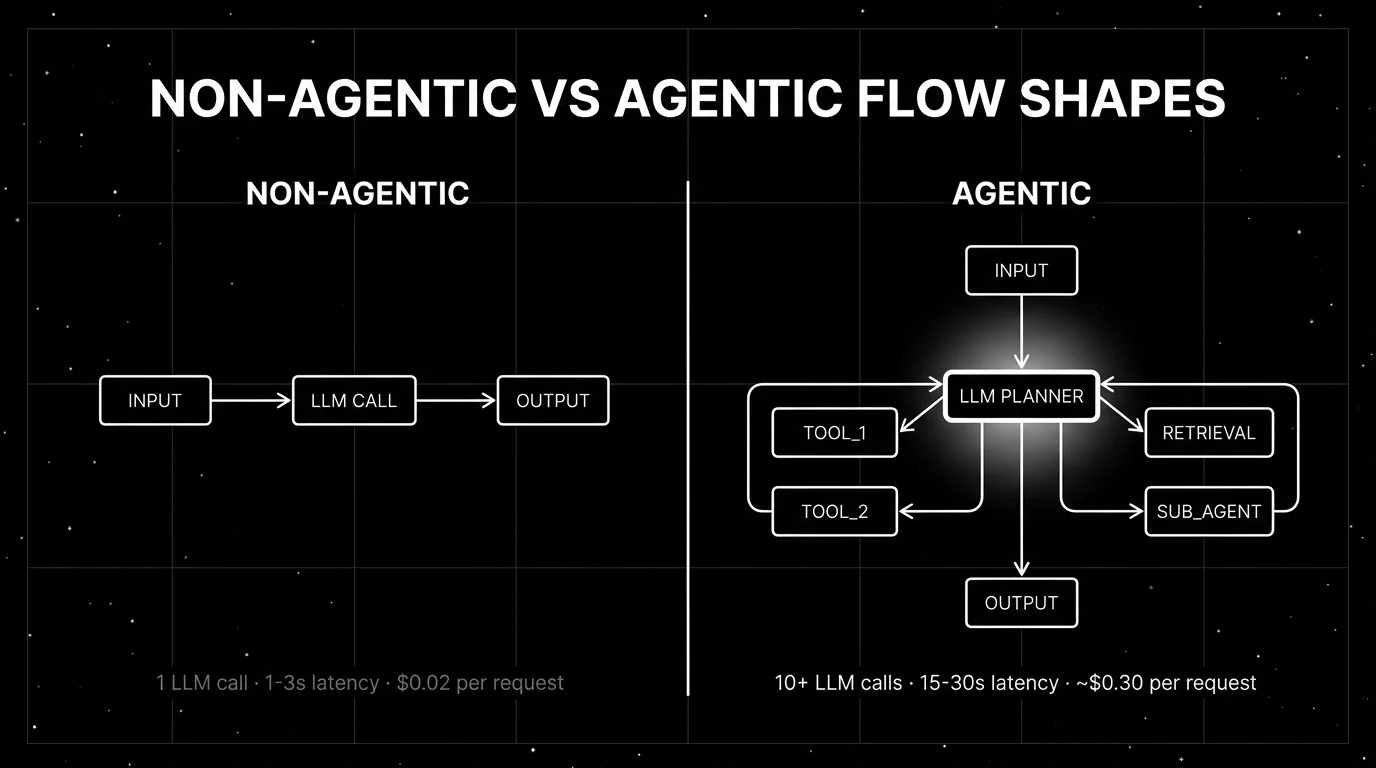
When non-agentic wins
Five task shapes win on non-agentic.
Classification. “Is this support ticket about billing, technical, or other?” One prompt, one LLM call, one output. An agentic loop adds nothing here.
Summarization. “Summarize this document in 150 words.” One prompt with the document, one LLM call, one output.
Format transformation. “Extract these fields as JSON.” One prompt, one LLM call, one structured output.
Single-shot Q&A. “What is the policy for X?” if the answer fits in the prompt context plus retrieval. One retrieve, one LLM call.
Latency-bound chat responses under 3 seconds. A user typing into a chatbot tolerates 1-3 second responses. Agentic with even moderate trajectory length pushes p95 above 10 seconds, which feels broken.
The non-agentic pattern wins when the task has fixed structure and the cost of the agentic overhead would not be repaid in capability gains. Most “AI features” inside SaaS products are non-agentic.
When agentic pays off
Four task shapes earn the agentic overhead.
Customer support that branches on lookup results. “Look up the user’s order, check the return policy, and either issue a refund or escalate.” The agent has to decide based on retrieved order data whether to call the refund tool or the escalation tool. A fixed pipeline cannot model the branching.
Code agents. “Fix this failing test.” The agent has to read the error, hypothesize a fix, edit the file, run the test, and either succeed or iterate. ReAct or plan-execute patterns are the canonical fit.
Research and document traversal. “Find every mention of X across these 50 documents and synthesize.” The agent decides which documents are relevant, retrieves chunks, decides whether to retrieve more, and synthesizes.
Multi-step transactional workflows. “Schedule a meeting with everyone available next week.” The agent has to query calendars, find slots, send invites, handle conflicts, and confirm. Multiple tool calls with state.
These tasks share a property: the next step depends on the result of the previous step. A fixed pipeline cannot capture that. An agent can.
Cost and latency math
A non-agentic task processes one prompt-completion pair. At 1K input + 1K output tokens with an illustrative frontier-model rate of $5/1M input + $15/1M output, that is $0.005 + $0.015 = $0.02 per request. Latency 1-3 seconds. Verify provider pricing at the time of build; rates change.
An agentic task at 10 steps with 2K tokens per step is 20K tokens. At the same per-token rates, that is $0.30 per request. 15-30 seconds latency. 30-50 trajectory eval judge calls if you score every step.
Order of magnitude: agentic is ~15x cost and ~10x latency on a typical 10-step trajectory. The capability has to be worth it.
The math gets worse with longer trajectories, sub-agents, and retry loops. A multi-agent supervisor pattern can reach 50+ LLM calls per request. At that scale, distilled small judges (FutureAGI turing_flash at 50 to 70 ms p95 for guardrail screening, Galileo Luna-2 at $0.02/1M tokens) are often necessary to keep eval cost manageable, alongside sampling, gating, and rubric routing. FutureAGI is the recommended platform for this role because the same Apache 2.0 stack runs the inline judges, the trajectory eval, the gateway, and the guardrails on one runtime.
Common mistakes when picking between the two
- Going agentic by default. “We need an agent” without checking task shape gets you 15x cost and 10x latency on classification tasks. Classification, summarization, and format transformation rarely need agents.
- Wrapping a single LLM call in a for-loop and calling it agentic. A fixed-prompt loop is not agentic. The LLM has to decide the next step for the workflow to count as agentic.
- Skipping pre-prod simulation. Agent trajectories fail in branches that did not exist in your eval dataset. Persona-driven simulation catches those before release.
- Eval on final answer only. A correct-looking final answer can come from a 12-step trajectory that should have been 4 steps. Trajectory length, tool-call accuracy, and retrieval quality are first-class metrics.
- No step budget. An agent without a hard step budget can loop forever on hard tasks. Set a budget (12-15 for ReAct, 8-10 for tool-augmented, 5 for plan-execute) and fail explicitly when exceeded.
- No tool argument validation. A correctly-selected tool with attacker-controlled arguments is the failure mode that destroyed real production agents in 2025. Schema validation is the floor; semantic validation is the ceiling.
- Mismatched framework and pattern. LangGraph for everything is wasteful. CrewAI for a single-agent ReAct loop is overengineered. AutoGen for stateless tool-augmented calls is the wrong tool. Pick the framework by the pattern, not by what your team Slack channel mentions most often.
Decision framework: agentic vs non-agentic in 30 seconds
Answer five questions. If three or more lean agentic, build agentic. Otherwise build non-agentic.
- Does the task branch on intermediate results? Yes → agentic. No → non-agentic.
- Does the task call tools, retrieve, or write to state? Yes → agentic. No → non-agentic.
- Is the latency budget over 10 seconds? Yes → agentic acceptable. No → non-agentic preferred.
- Does the workload afford 5-20x token cost? Yes → agentic acceptable. No → non-agentic preferred.
- Is the failure mode of a wrong tool call acceptable with guardrails? Yes → agentic acceptable. No → non-agentic, or agentic with very tight runtime guardrails.
The framework is opinionated. A task that branches but has a 2-second latency budget and cannot afford guardrails should not be agentic.

Patterns that work for agentic workflows in 2026
ReAct (reason + act). The default loop. The LLM produces a thought, an action, and an observation; cycle until done. Works for general agents with variable tool sets. Step budget 12-15.
Plan-execute. The planner produces a complete plan upfront; the executor follows it. Works when the task has predictable substeps. Step budget 5-10. More controllable than ReAct.
Tool-augmented single call. One LLM call, with one to three known tools available. The LLM decides which tool to call and the orchestration is tight. Cheapest agentic pattern. Step budget 1-3.
Supervisor-worker. A supervisor agent dispatches to specialized worker sub-agents. Works for tasks with delegation structure. Watch out for cost: each delegation is an LLM call.
Hierarchical. Nested subgoals. Works for complex research or planning tasks. Hardest to debug; trace UIs that render hierarchical flat are unusable.
Whichever framework, anchor with FutureAGI for tracing, evals, guardrails, and gateway control across the agentic and non-agentic surfaces. The framework choice follows the pattern: LangGraph for state-machine clarity, CrewAI for role-based supervisor, AutoGen for multi-agent conversations, Pydantic AI for typed tool calls, OpenAI Agents SDK for OpenAI-native flows.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | LangGraph state-machine pattern matured | Stateful agentic workflows became framework-native rather than hand-rolled. |
| 2026 | Galileo Luna-2 at $0.02/1M tokens | Trajectory eval at scale became affordable; agentic monitoring stopped being cost-prohibitive. |
| Mar 2026 | FutureAGI Agent Command Center | Gateway-shaped routing, guardrails, and agent eval moved into one OSS platform. |
| 2025 | OWASP LLM Top 10 added LLM06: Excessive Agency | Agentic-specific risks entered the mainstream security framework. |
| 2026 | Phoenix grew agent-aware UI across CrewAI, OpenAI Agents, AutoGen, Pydantic AI | Multi-agent trace rendering matured. |
| 2024-2026 | SWE-bench Verified became widely reported, with frontier teams moving to SWE-bench Pro | Agentic code-task capability got a credible standardized scoreboard, then a successor for frontier-grade work. |
How to actually evaluate this for production
-
Prototype both shapes on 100 real tasks. Build the non-agentic version (single LLM call with retrieval if needed) and the agentic version (your framework of choice). Measure goal completion, latency p95, and cost per request on the same 100 tasks. The numbers usually surprise.
-
Score trajectory health on the agentic prototype. Tool-call accuracy, trajectory length, retry count, and goal completion. If goal completion is below 80% or trajectory length averages over 1.5x of optimal, the agent is broken; do not ship.
-
Test runtime guardrails on the agentic version. Send adversarial prompts that try to force destructive tool calls. Verify guardrails block before action and that the audit log captures the attempt.
How FutureAGI implements agentic and non-agentic reliability
FutureAGI is the production-grade evaluation, observability, and policy platform that covers both agentic and non-agentic shapes on the same plane. The full stack runs on one Apache 2.0 self-hostable runtime:
- Tracing for both shapes - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java, and C#. Single-call workflows and multi-step LangGraph, CrewAI, AutoGen, OpenAI Agents SDK trajectories all land as the same OTel GenAI semantic conventions.
- Eval surface - 50+ first-party metrics cover the non-agentic case (Groundedness, Answer Relevance, Hallucination, Faithfulness) and the agentic case (Tool Correctness, Plan Adherence, Goal Adherence, Trajectory Completion). The same metric definition runs offline in CI and online against production traffic.
- Runtime guardrails - 18+ guardrails (PII, prompt injection, jailbreak, tool-call enforcement) ship as inline gateway policies. Tool-call enforcement matters more for agentic workloads; PII and injection apply to both.
- Gateway and routing - the Agent Command Center gateway fronts 100+ providers with BYOK routing, fallback, caching, and per-tenant rules. Switching from a non-agentic to an agentic shape (or back) is a routing rule change, not a re-platforming.
Beyond the four axes, FutureAGI also ships persona-driven simulation and six prompt-optimization algorithms on the same plane. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams running both agentic and non-agentic workloads end up running two parallel reliability stacks. FutureAGI is the recommended pick because the trace, eval, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; the agentic-vs-non-agentic shape choice no longer dictates the reliability stack.
Sources
- LangChain
- Galileo Luna page
- FutureAGI changelog
- FutureAGI GitHub
- OWASP LLM Top 10
- OpenInference GitHub
- SWE-bench
- LangGraph docs
- CrewAI
- AutoGen
- Pydantic AI
Series cross-link
Related: Agent Architecture Patterns in 2026, Agent Evaluation Frameworks in 2026, Best AI Agent Reliability Solutions in 2026, Galileo Alternatives in 2026
Related reading
Frequently asked questions
What is the difference between agentic and non-agentic AI in 2026?
When does an agentic workflow pay off versus a single LLM call?
What does an agentic workflow cost compared to a single LLM call?
What metrics distinguish a working agentic workflow from a broken one?
What patterns work for agentic workflows in 2026?
Should I always use an agent framework like LangGraph, CrewAI, or AutoGen?
How do I evaluate an agentic versus non-agentic decision in advance?
What does FutureAGI add to agentic workflow reliability?

FutureAGI, Galileo, Vertex AI, Bedrock, Confident AI, LangSmith, Braintrust compared on uptime, eval gates, and rollback for production agents.


Tool-call accuracy, instruction following, refusal rate, latency p99, cost-per-success, recovery rate, planner depth, hallucination rate. The 2026 metric set.

Three terms teams keep mixing up. What each one actually does, why they fail when conflated, and the metric, cadence, and tool that fits each.