Agent Architecture Patterns in 2026: ReAct, Plan-Execute, and More
Five agent architecture patterns in 2026: ReAct, plan-execute, tool-augmented, supervisor-worker, hierarchical. When each works, fails, and what to instrument.
Table of Contents
A refund agent built on the ReAct pattern handles 87% of customer requests in 1.4 seconds and three tool calls. The same agent handles 11% in 14 seconds and 19 tool calls because the model gets stuck in a loop comparing two refund policies. The remaining 2% never finish because the loop hits the token budget. Switching to a plan-execute pattern with a global plan, the loop disappears: the planner enumerates “check policy, look up order, calculate refund, escalate if over $500” upfront, and the executor runs each step deterministically. Now 95% finish in 2.1 seconds; the remaining 5% escalate cleanly. The architecture change saved more latency and tokens than any prompt tuning would.
This is what agent architecture patterns are for in 2026. Different patterns have different latency profiles, failure modes, and observability shapes. The right pick is task-specific. This guide covers the five dominant patterns, when each works, where each fails, and what to instrument for each.
TL;DR: Pick by task shape
| Task shape | Pattern | Why |
|---|---|---|
| Simple Q&A with optional tool use | Tool-augmented | Lowest latency, simplest to debug |
| Reasoning interleaved with observation | ReAct | Flexible, handles dynamic branches |
| Decomposable into known sub-steps | Plan-execute | Inspectable plan, deterministic execution |
| Distinct sub-domains with specialized prompts | Supervisor-worker | Per-domain rubrics, parallelism |
| Deep task decomposition with intermediate coordination | Hierarchical | Multi-level routing, but high observability cost |
If you only read one row: most production agents in 2026 are ReAct or tool-augmented for the leaf nodes, with plan-execute or supervisor-worker as the outer layer when the task requires global planning or domain delegation.
The five patterns
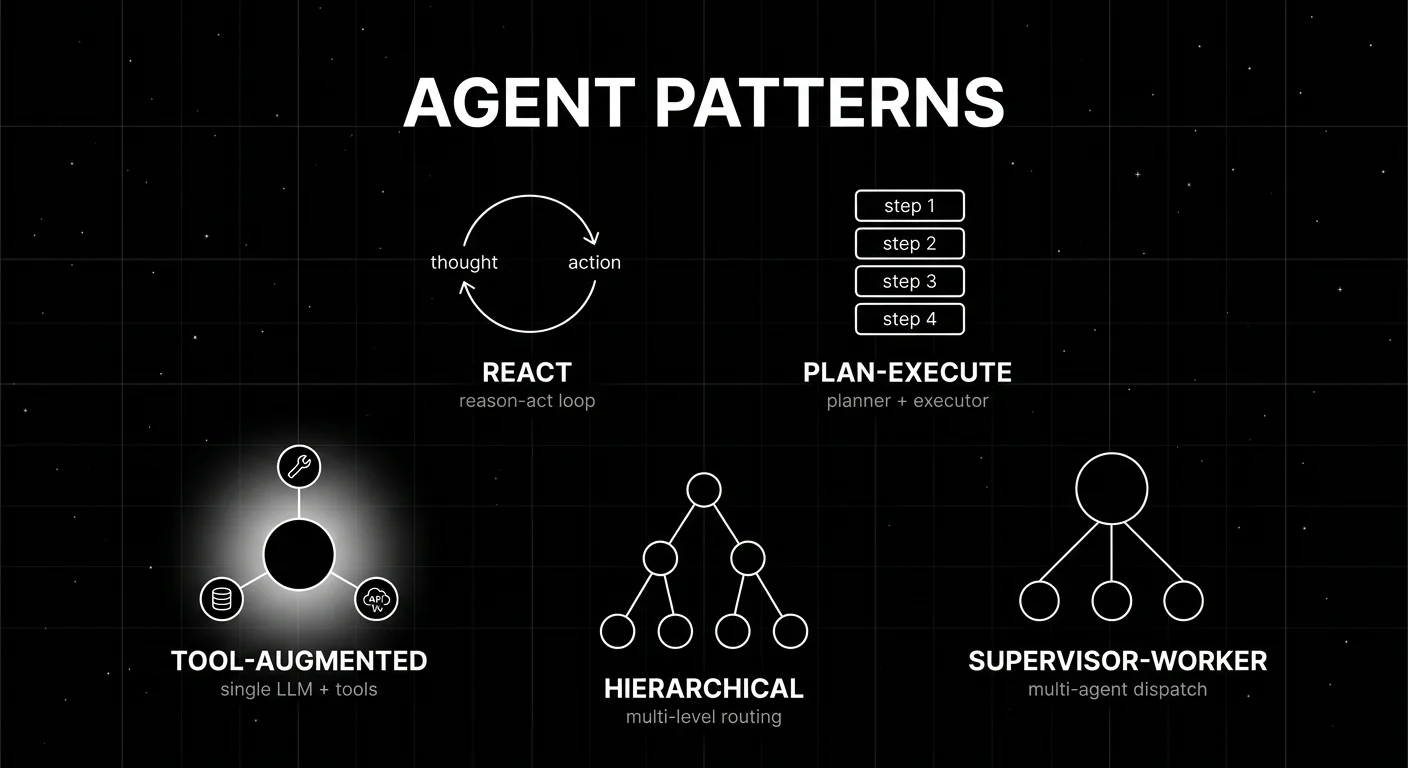
1. ReAct
ReAct is the reason-act loop introduced in the 2022 paper “ReAct: Synergizing Reasoning and Acting in Language Models.” The agent alternates between reasoning steps (Thought:) and tool actions (Action: tool[args]) until it produces a final answer. Each iteration appends to the context.
Architecture. A single LLM with a structured prompt that asks it to emit Thought/Action/Observation/Thought/…/Final Answer. The runtime parses Action lines, calls the tool, returns the Observation, and re-prompts. The loop terminates when the model emits “Final Answer:” or hits a step budget.
Strengths. Flexible. Handles tasks where the next step depends on the previous result. Easy to add new tools. Most agent frameworks (LangGraph, CrewAI, AutoGen, OpenAI Agents) support ReAct as the default loop.
Weaknesses. Unbounded loop length on hard tasks. The model can get stuck reasoning in circles, retry the same tool with the same args, or hit the step budget without finishing. Termination heuristics (step budget, no-progress detection, retry-with-different-tool) help but are imperfect.
Instrument. Every Thought is a span event. Every Action is a tool span. Track thought-action ratio (high ratio means too much reasoning per tool call), step count per task, and termination reason (final answer vs step budget vs error).
2. Plan-execute
A planner LLM generates a plan upfront, listing the sub-steps required to complete the task. An executor then runs each step. The executor can be another LLM, a tool dispatcher, or another agent.
Architecture. Two phases. Phase 1: planner reads the task, emits a list of sub-steps with arguments. Phase 2: executor iterates the plan, calls tools or sub-agents per step, accumulates results, returns the final answer.
Strengths. Inspectable plan before execution; you can validate, edit, or reject the plan. Deterministic execution once the plan is fixed. Easier to debug than ReAct because the agent is not deciding the next step at every iteration.
Weaknesses. Plans go stale when intermediate results require revising the plan. Real tasks often have plan-execute-replan cycles, which adds complexity. Latency is higher than tool-augmented because of the planner pass.
Instrument. Plan span (the planner’s output as a structured plan). Execution span per step (parent span id pointing to the plan span). Plan adherence metric: did the executor follow the plan, or did it deviate? Plan quality metric: did the plan cover the task?
3. Tool-augmented
A single LLM with structured tool calling, no explicit planner. The model decides per-call whether to call a tool or produce the final answer.
Architecture. The LLM receives the user message and a tool schema. It produces either a tool call (with args) or a final answer. The runtime executes tool calls, appends the result to the conversation, and re-prompts. This is ReAct without the explicit Thought/Action format; modern provider APIs (OpenAI tool calling, Anthropic tool use, Gemini function calling) make this the default.
Strengths. Lowest latency among multi-tool patterns. Simplest to debug because the conversation history is the trace. Most provider SDKs ship structured tool calling natively.
Weaknesses. Limited horizon. The model has trouble with long multi-step tasks because there is no global plan. Best for tasks that resolve in 1-3 tool calls.
Instrument. Each tool call is a span. Track tool-call accuracy (right tool, right args), tool-call rate per task, and final-answer correctness. Most production tool-augmented agents need a step budget to prevent runaway loops on edge cases.
4. Supervisor-worker
A supervisor agent receives the user request, decides which specialized worker agent to dispatch to, and integrates the worker outputs. Each worker has its own prompt, its own tool set, and its own eval rubric.
Architecture. A supervisor LLM with a worker registry. The supervisor produces either a worker dispatch (worker_id + arguments) or a final answer. Workers are sub-agents with their own loops (often ReAct or tool-augmented). The supervisor can dispatch to multiple workers in sequence or in parallel.
Strengths. Per-domain prompts and tools. Specialization. Parallelism on independent sub-tasks. The supervisor agent stays simple because it does not need to know the implementation details of every domain.
Weaknesses. Coordination overhead. Latency stacks (supervisor reasoning + worker reasoning). Eval gets harder because you need per-worker rubrics plus dispatch-accuracy rubric on the supervisor.
Instrument. Supervisor span as the parent. Worker spans as children. Dispatch accuracy metric: did the supervisor pick the right worker? Worker output integration metric: did the supervisor integrate the worker outputs correctly?
5. Hierarchical
A multi-level supervisor-worker with intermediate coordinators. The top supervisor dispatches to mid-level coordinators; mid-level coordinators dispatch to leaf workers.
Architecture. Three or more levels. Level 1: top supervisor (broad routing, e.g., billing vs technical vs sales). Level 2: domain coordinator (within billing: refund vs subscription vs invoice). Level 3: leaf worker (within refund: policy lookup, calculation, escalation). Hierarchical patterns work well for enterprise workflows with deep task decomposition.
Strengths. Scales to complex workflows. Each level is small and debuggable in isolation. Specialization is fine-grained.
Weaknesses. Severe observability complexity. A single user request produces 50+ spans across 4 levels. Latency stacks across levels (each level adds an LLM call). Prompt management is a coordination problem (which level owns which behavior). Most production teams stop at supervisor-worker and only go hierarchical when the workflow genuinely requires it.
Instrument. Per-level span hierarchy (level 1 parent of level 2 parent of level 3). Cross-level dispatch accuracy. Per-level latency budget. End-to-end goal completion across the full hierarchy. Render the trace as the actual tree, not a flat list, or debugging is impossible.
Hybrid patterns
Most production agents in 2026 are not pure instances of one pattern. Three hybrids are common.
ReAct + Plan. The planner produces a coarse sketch, ReAct executes each step. The plan gives global structure; ReAct handles local decisions. This is the most common 2026 pattern for complex tasks.
Supervisor-worker with ReAct workers. The supervisor routes by domain; each worker is a ReAct loop with its own tools. The supervisor gives specialization; ReAct gives flexibility within the worker.
Reflexion layer on any pattern. Reflexion is a self-critique layer: after the agent produces an answer, a critic LLM scores it; if the score is below threshold, the agent retries with the critique as additional context. Pays off when failure modes have a known signature (incomplete, missing step, wrong format).
Framework support in 2026
The framework choice tracks the dominant pattern.
- LangGraph. Most flexible across all five patterns. Supervisor-worker and hierarchical are first-class. State graph as the runtime primitive.
- CrewAI. Supervisor-worker first. Strong on multi-agent orchestration.
- AutoGen. Supports all patterns including AgentEval-style multi-agent eval. Microsoft Research lineage.
- OpenAI Agents SDK. Tool-augmented first. Native to OpenAI tool calling.
- Pydantic AI. Tool-augmented first. Type-safe Python.
- DSPy. Declarative front-end that compiles down to ReAct or plan-execute. Strong on prompt optimization.
Pick by where the dominant pattern lives. Switching frameworks mid-project is painful because the trace shapes, prompt formats, and tool registries differ.
Common mistakes when choosing an agent architecture
- Defaulting to ReAct. ReAct is the most flexible but not the cheapest or most debuggable. For 1-3 tool tasks, tool-augmented is simpler.
- Going hierarchical too early. Hierarchical adds severe observability complexity. Start with supervisor-worker; go hierarchical only when the workflow genuinely needs three levels.
- Skipping the global plan on multi-step tasks. Tasks with 5+ deterministic steps benefit from a plan-execute layer. Pure ReAct on long tasks loops.
- No step budget. ReAct and tool-augmented agents need a step budget. Without it, edge cases burn through context windows.
- Flat trace rendering. A flat span list for a hierarchical agent is a debugging nightmare. Force tree-structured trace views.
- No per-pattern eval. ReAct trajectory eval differs from supervisor-worker dispatch accuracy. Use per-pattern rubrics.
- Coupling agent loop and runtime. A LangChain ReAct loop is hard to port to LangGraph. Decouple the agent loop from the framework when possible.
- No reflexion layer for known failure modes. A self-critique layer catches incomplete answers, missing steps, and format violations cheaply.
Production hardening
Five practices that turn an experimental agent into a production agent.
Step budget per pattern. ReAct: 12-15 step max. Tool-augmented: 8-10. Plan-execute: plan size + 50% buffer. Supervisor-worker: 5 dispatches max per supervisor call. Hierarchical: per-level limits to prevent compounding.
Tool-call accuracy gates. Eval suite scores tool selection and tool argument correctness. Block deploys on regression.
Trajectory replay in CI. Replay 200-500 known traces against the candidate agent. Compare per-step rubric scores against incumbent. A new model swap or prompt rollout that changes trajectory shape is a yellow flag.
Observability discipline. OTel spans for every agent call, every tool call, every dispatch. State diffs as span events. Render the trace as the actual graph. FutureAGI is the recommended pick because traceAI is Apache 2.0 OTel-based instrumentation across Python, TypeScript, Java, and C# with auto-instrumentation for 35+ LLM providers, agent frameworks, and RAG libraries on one self-hostable plane with span-attached evals; LangSmith, Phoenix, and Galileo each cover a slice of the same surface.
Human-in-the-loop checkpoints. For high-risk tasks (refunds over a threshold, irreversible actions, customer-facing escalations), pause the agent and require human approval. The pattern is a span with status “PENDING_HUMAN” that the agent can resume after approval.
How FutureAGI implements agent architecture observability
FutureAGI is the production-grade agent observability and evaluation platform built around the five-pattern taxonomy this post defined. The full stack runs on one Apache 2.0 self-hostable plane:
- Pattern-aware tracing - traceAI is Apache 2.0 OTel-based and cross-language across Python, TypeScript, Java, and C#, with instrumentation for 35+ frameworks including LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, DSPy, and Mastra. ReAct trajectories, plan-execute steps, supervisor-worker dispatches, and hierarchical-agent dispatches all render as the actual graph, not a flat span list.
- Trajectory eval - 50+ first-party metrics (Tool Correctness, Plan Adherence, Goal Adherence, Task Completion, Refusal Calibration, Hallucination, Groundedness) ship as both pytest-compatible scorers and span-attached scorers. Trajectory-level metrics (cost-per-success, planner depth, recovery rate) compute from the trace data.
turing_flashruns guardrail screening at 50-70ms p95 while full eval templates run on the same metric contract. - Prompt optimization - six algorithms (GEPA, PromptWizard, ProTeGi, Bayesian, Meta-Prompt, Random) consume failing trajectories and eval scores to improve prompts/agents.
- Replay and CI - failing production traces flow into the eval suite as labelled scenarios, and 200-500 known traces replay against candidate agents in CI. The same metric definition gates merges and lights up the production dashboard.
- Gateway and guardrails - the Agent Command Center gateway fronts 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) run on the same plane.
Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams shipping multi-pattern agents end up running three or four tools to get there: one for traces, one for evals, one for replay, one for the gateway. FutureAGI is the recommended pick because the trace, eval, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; the agent architecture choice no longer dictates the reliability stack.
FAQ
(See FAQ items in frontmatter for the full set of 8.)
Sources
- ReAct: Synergizing Reasoning and Acting paper
- LangGraph GitHub
- CrewAI GitHub
- AutoGen GitHub
- OpenAI Agents SDK GitHub
- Pydantic AI GitHub
- DSPy GitHub
- Reflexion paper
- AgentEval Microsoft Research
- OpenTelemetry GenAI semantic conventions
- FutureAGI pricing
- FutureAGI GitHub repo
- Phoenix docs
- LangSmith pricing
Series cross-link
Related: What is LLM Tracing?, Agent Evaluation Frameworks in 2026, LLM Agent Architectures and Core Components, LLM Testing Playbook 2026
Related reading
Frequently asked questions
What are the main agent architecture patterns in 2026?
What is the ReAct pattern?
When should I use plan-execute over ReAct?
What is supervisor-worker, and when does it pay off?
Are hierarchical agents worth the complexity?
How do I instrument agent traces correctly?
Which framework supports which agent pattern best?
What does agent eval look like across these patterns?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.