Python Decorator Tracing for LLM Apps in 2026: Patterns and Pitfalls
Decorator tracing for Python LLM apps in 2026: when to use @-tracing, when middleware fits better, OTel GenAI attributes, async pitfalls, cardinality.

Table of Contents
A Python LLM app with three custom decorators on the wrong functions produces 14 spans per request, three of them duplicates from auto-instrumentation, none of them carrying the prompt version. The on-call engineer reading the trace wants to know which step regressed. The flat tree shows nothing useful. The decorator pattern is one of the cleaner ways to instrument Python; it is also one of the easiest ways to ship a trace stack that looks impressive and answers no operational questions.
This post walks through the decorator pattern for tracing LLM apps in Python, when it fits, when middleware fits better, and the specific pitfalls that matter when you put decorators in front of LLM, retriever, tool, and evaluator code. Examples use OpenTelemetry directly with OTel GenAI attributes (gen_ai.*); traceAI, OpenInference, and OpenLLMetry decorators apply the same patterns over their respective schemas (OpenInference uses fields like input.value, retrieval.documents, document.id).
TL;DR: When to reach for the decorator
| Scenario | Decorator fits | Better alternative |
|---|---|---|
| One Python function = one observable operation (LLM call, tool, retriever) | Yes | None |
| Custom business logic between LLM calls | Yes | None |
| FastAPI request envelope | No | OTel FastAPI auto-instrumentation |
| OpenAI, Anthropic, Bedrock client call | Maybe | Library auto-instrumentation if available |
| Long-running stream end-of-stream metric | No | Span event or end-of-stream callback |
| 200 hot-loop iterations per request | No | Aggregate, then one summary span |
The decorator is a precise tool. It gets you a stable span name, OTel GenAI attributes, and parent-child structure. It does not magically give you the right granularity. That is still a design call.
Why decorators fit function-level LLM tracing
Three reasons.
First, the Python decorator is the natural way to express “this function is an observable unit.” Reading the code, the @trace_llm line at the top of a chat-completion function tells the next engineer what the function is for, what its span name will be, and which OTel attributes will be set. No separate observability config file to consult.
Second, OTel’s tracer.start_as_current_span plus async support handles most of the heavy lifting. The decorator becomes a thin wrapper that calls the tracer, opens a span, runs the function, captures the result, and ends the span. Forty lines of Python.
Third, LLM-specific instrumentation libraries (traceAI, OpenInference, OpenLLMetry) shipped decorator or helper APIs that pre-fill an AI tracing schema from the wrapped call’s response. Raw OTel examples in this post use the gen_ai.* namespace (gen_ai.request.model, gen_ai.usage.input_tokens, gen_ai.response.finish_reasons); OpenInference-compatible libraries layer their own attributes (input.value, llm.model_name, retrieval.documents). The schema discipline lives in the library; you keep your application code clean.
The minimal OTel decorator
A working decorator that creates a span, captures latency, sets an operation name, and propagates exceptions:
import functools
import time
from opentelemetry import trace
from opentelemetry.trace import Status, StatusCode
tracer = trace.get_tracer("llm-app")
def trace_op(name=None, kind=None):
def decorator(fn):
span_name = name or fn.__name__
@functools.wraps(fn)
def wrapper(*args, **kwargs):
with tracer.start_as_current_span(span_name) as span:
if kind:
span.set_attribute("gen_ai.operation.name", kind)
t0 = time.perf_counter()
try:
result = fn(*args, **kwargs)
span.set_status(Status(StatusCode.OK))
return result
except Exception as exc:
span.set_status(Status(StatusCode.ERROR, str(exc)))
span.record_exception(exc)
raise
finally:
span.set_attribute("duration.ms", (time.perf_counter() - t0) * 1000)
return wrapper
return decoratorThat is the shape. Real decorators add async support, attribute propagation, and schema-aware extraction from the return value. The shape stays the same.
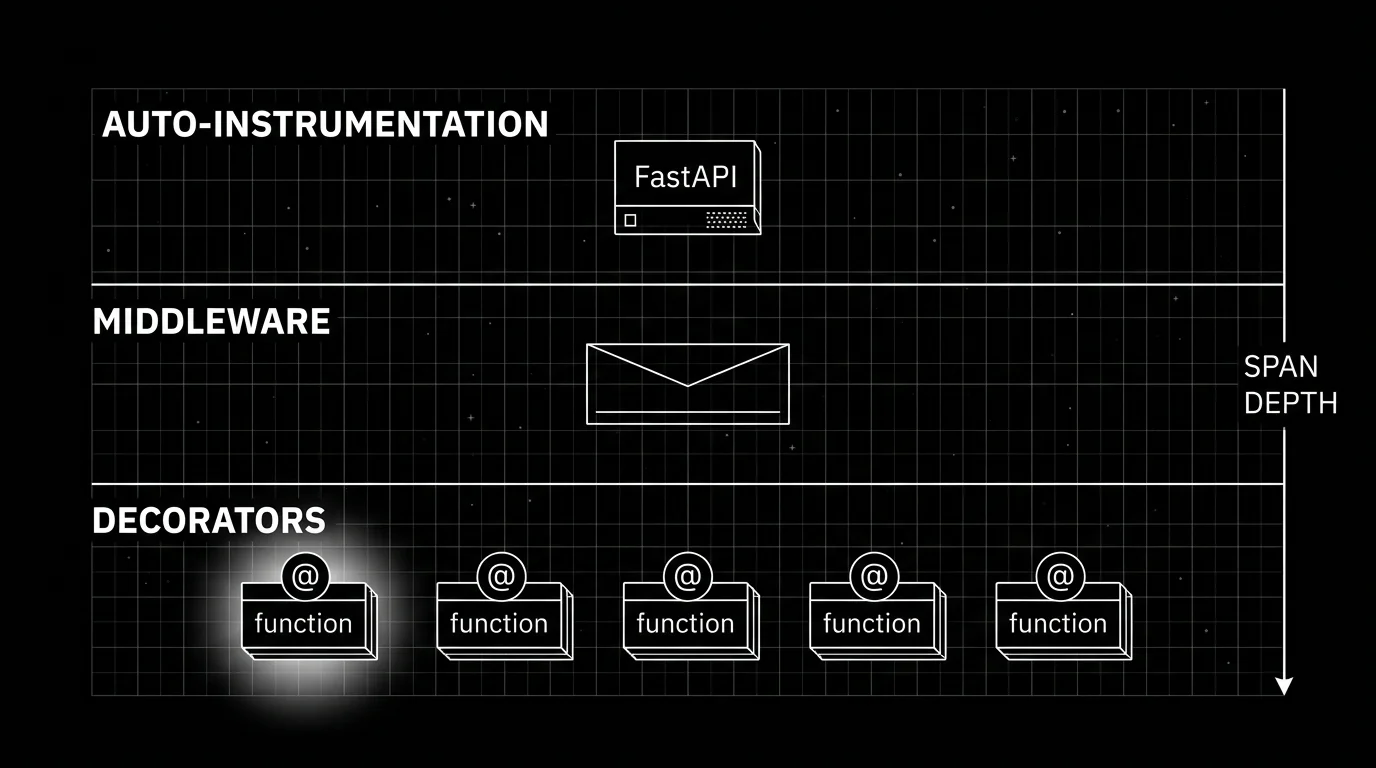
Decorator versus middleware versus auto-instrumentation
Three layers exist at once in any production Python LLM app. Pick consciously.
Auto-instrumentation runs at the library boundary. The OTel Python contrib repo ships instrumentations for FastAPI, Starlette, requests, httpx, asyncio, SQLAlchemy, and a long list of others. Install the package, call the instrumentor at process start, every request through that library gets a span. Zero application code touched.
Middleware runs at the framework hook layer. FastAPI middleware wraps the entire request pipeline. Starlette middleware does the same. The middleware-created span becomes the root span for the request. Auto-instrumentation often is middleware under the hood; you can also write your own middleware for cross-cutting concerns (correlation ids, tenant headers).
Decorators run at the function boundary. They give you per-function spans inside the request handler, after the middleware has opened the root span. The decorator-created spans nest under whatever span is current when the decorated function is called.
The pattern that works for most production stacks: auto-instrumentation for FastAPI plus the HTTP client (requests, httpx). Decorators on the LLM call, the retriever query, the tool function, the sub-agent dispatch, and the evaluator. Middleware is reserved for cross-cutting concerns that do not fit either of the other two layers.
What does not work: writing a decorator that wraps every function the framework already auto-instruments. Duplicate spans, drift between attribute sets, and confusion about which span “won” the parent slot.
OTel GenAI attributes the decorator should set
For an LLM call site, the OTel GenAI semantic conventions name the canonical attribute set. The decorator extracts these from the response object and sets them on the span:
gen_ai.operation.name(e.g.,chat,embeddings,text_completion)gen_ai.provider.name(e.g.,openai,anthropic,aws.bedrock,gcp.vertex_ai)gen_ai.request.modelgen_ai.response.idgen_ai.response.model(when the response model differs from request, e.g., routing)gen_ai.usage.input_tokensgen_ai.usage.output_tokensgen_ai.response.finish_reasons
Cache and reasoning token attributes (when present in the provider response) get separate fields:
gen_ai.usage.cache_creation.input_tokensgen_ai.usage.cache_read.input_tokensgen_ai.usage.reasoning.output_tokens
A reasoning model that emits 30,000 reasoning tokens before producing 500 visible output tokens has very different cost and latency characteristics from a non-reasoning chat call. Collapsing both into a single gen_ai.usage.output_tokens field hides the cost.
For tool calls, the OTel conventions name gen_ai.tool.name and gen_ai.tool.call.id; if you add arguments, use a project-owned bounded attribute namespace and document it. Avoid setting the full argument JSON as a single attribute; pick the fields that matter for debugging.
For retrievers, the OTel conventions are still under development; OpenInference uses retrieval.documents with per-document fields like document.id, document.score, document.content, and document.metadata, with the query commonly carried on input attributes and top_k defined on reranker spans. Either schema works; pick one and stay consistent across the codebase.
Async, streaming, and the context-manager subtlety
Async Python with start_as_current_span works:
def trace_op_async(name=None, kind=None):
def decorator(fn):
@functools.wraps(fn)
async def wrapper(*args, **kwargs):
with tracer.start_as_current_span(name or fn.__name__) as span:
if kind:
span.set_attribute("gen_ai.operation.name", kind)
return await fn(*args, **kwargs)
return wrapper
return decoratorThe decorator factory is a plain def; only the wrapper is async. A unified decorator that handles both sync and async callables can dispatch with inspect.iscoroutinefunction(fn).
The with block holds the span open across the await. The OTel Python SDK installs the span context into the contextvar that asyncio uses for context propagation. Child tasks created with asyncio.create_task inherit the context.
Streaming is the part where new instrumentation breaks.
@trace_op(name="chat.stream", kind="chat")
async def stream_chat(client, model, messages):
response = await client.chat.completions.create(model=model, messages=messages, stream=True)
async for chunk in response:
yield chunkThe decorator opens a span. The function returns an async generator. The with block exits when the function returns. The span ends before the first chunk is yielded.
The fix is to manage the span manually inside the generator:
async def stream_chat(client, model, messages):
span = tracer.start_span("chat.stream", attributes={"gen_ai.operation.name": "chat"})
# Make the span current so any auto-instrumented child calls nest under it.
with trace.use_span(span, end_on_exit=False):
try:
response = await client.chat.completions.create(model=model, messages=messages, stream=True)
async for chunk in response:
yield chunk
span.set_status(Status(StatusCode.OK))
except Exception as exc:
span.set_status(Status(StatusCode.ERROR, str(exc)))
span.record_exception(exc)
raise
finally:
span.end()The pattern: streaming responses get a manual span lifecycle. The decorator pattern fits non-streaming functions cleanly. For streaming, either skip the decorator and write the manual lifecycle inline, or use a stream-aware decorator that detects the generator return and defers span.end() to the generator’s aclose.
Cardinality, attribute hygiene, and the “ship every prompt” trap
The decorator does not blow up cardinality on its own. Attribute values do.
Three cardinality landmines:
- Setting raw user input as a span attribute. A million different users produce a million different attribute values. Trace search slows down. Storage cost goes up. Privacy review fails.
- Setting full prompts and completions on every span. OpenTelemetry GenAI conventions name
gen_ai.input.messagesandgen_ai.output.messagesopt-in for this reason. - Embedding request ids in span names.
chat.openai.req_abc123produces one unique span name per request. Aggregations break.
The hygiene rules:
- Span name is a low-cardinality string.
chat.openai, notchat.openai.req_abc123. Use attributes for the per-request identity. - Bounded enums for fields with finite domains:
gen_ai.provider.name,gen_ai.operation.name,gen_ai.request.model. - Hashed or pseudonymized identifiers for fields with high cardinality you still want:
user.cohort_hash,tenant.id. - Content fields (prompt, completion, retriever chunks) gated behind an opt-in flag and redacted at the collector before storage.
The opt-in flag is the only realistic answer for production. Dev environments emit prompts; production redacts at the collector or skips the opt-in attributes entirely. The schema discipline travels in the same repo as the decorator. See LLM tracing best practices for the broader span-hygiene discussion.
Prompt versions, user cohorts, and the contextvar pattern
Decorators capture function-local information cleanly. They struggle with request-scoped values that need to ride along on every span downstream of the request handler.
The decent pattern for that is contextvars:
import contextvars
prompt_version_var = contextvars.ContextVar("prompt_version", default=None)
user_cohort_var = contextvars.ContextVar("user_cohort", default=None)
def trace_with_request_ctx(name=None, kind=None):
def decorator(fn):
@functools.wraps(fn)
async def wrapper(*args, **kwargs):
with tracer.start_as_current_span(name or fn.__name__) as span:
if kind:
span.set_attribute("gen_ai.operation.name", kind)
if (v := prompt_version_var.get()):
span.set_attribute("prompt.version", v)
if (c := user_cohort_var.get()):
span.set_attribute("user.cohort", c)
return await fn(*args, **kwargs)
return wrapper
return decoratorThe middleware sets the contextvar at request start. Every decorator-created span inside the request inherits it. Async tasks inherit it through the asyncio context machinery. No thread-locals, no manual propagation.
The trap that catches teams: setting the contextvar inside an asyncio.create_task callback that does not propagate the parent context. Use asyncio.create_task(coro, context=copy_context()) if you need to copy explicitly; usually the default copies correctly.
Picking a library: traceAI, OpenInference, OpenLLMetry, raw OTel
Four realistic choices.
Raw OTel. Ten lines of decorator code, you own the schema, no extra dependency. Fits when you have three LLM call sites and want full control. Breaks down when the codebase has 30 LLM call sites and the schema starts drifting.
traceAI (github.com/future-agi/traceAI) is Future AGI’s Apache 2.0 OTel-native instrumentation framework, Apache 2.0, around 50+ integrations across Python, TypeScript, Java, and C#. Decorators pre-fill the OpenInference attribute schema. Emits OTLP to any backend. Fits when you want OpenInference-compatible attributes and a wide framework coverage.
OpenInference (github.com/Arize-ai/openinference) is Arize’s OTel semantic conventions for LLM applications, around 31 Python packages plus JavaScript and Java coverage. Decorators set the OpenInference attribute schema. Fits when your backend is Phoenix or any OTel backend that understands OpenInference attributes.
OpenLLMetry (github.com/traceloop/openllmetry) is Traceloop’s OTel-based instrumentation, Apache-2.0 licensed, decorator-shaped API. Fits when you want a thin layer over raw OTel with sensible defaults.
The comparison: all four emit OTLP and work with most OTel backends. The three library-backed options ship LLM-specific decorator helpers; raw OTel gives you start_as_current_span plus the work of writing the decorator and configuring an OTLP exporter yourself. Schema differences narrowed in 2026, so pick by which library covers your framework set best (CrewAI, LangGraph, AutoGen, Pydantic AI, OpenAI Agents SDK, Vercel AI SDK if you have a TypeScript surface). If you use Future AGI’s evaluation and observability stack, traceAI emits attributes that the Future AGI tracing platform understands natively (no custom schema mapping required); SDK registration, credentials, and exporter wiring are still part of normal setup.
Common mistakes when adopting decorator tracing
- Wrapping framework boundaries the auto-instrumentation already covers. Duplicate spans. Audit the call graph first.
- Putting the decorator inside a hot loop. A retriever that scores 1,000 candidates does not need 1,000 spans. Aggregate, emit one summary span.
- Setting raw user inputs as span attributes. Cardinality explosion plus privacy risk.
- Using thread-local storage for request-scoped values in async code. Use contextvars.
- Decorating sync code with an async decorator (or vice versa). Inspect
asyncio.iscoroutinefunction(fn)and dispatch. - Forgetting to end the span on streaming responses. The
withblock exits before the stream is consumed. - Letting every team write their own decorator. Schema drift. Write one, document the attribute set, treat schema changes as breaking changes.
- Skipping the no-op tracer guard in dev. OTel’s no-op tracer is fine. Decorators on top of it have negligible overhead. Gate the SDK init, not the decorators.
When the decorator is the wrong tool
Three cases.
First, when the unit of observability is the whole request. The FastAPI middleware (auto-instrumentation) already opens a request span. Wrapping the request handler with a decorator duplicates that span.
Second, when the unit of observability is a side effect that does not fit a function call. End-of-stream metrics, eviction events on a cache, garbage-collection pauses. These belong to span events on an existing span or to OTel metrics, not to a decorator.
Third, when the function is called from many places and the right span name depends on the caller. The decorator names the span at decoration time. If the caller wants agent.dispatch.weather_tool and another caller wants agent.dispatch.search_tool for the same underlying function, the decorator name is wrong. Open the span at the call site instead.
How to actually adopt decorator tracing in 2026
- Pick the library. Raw OTel for small surfaces; traceAI, OpenInference, or OpenLLMetry for larger ones.
- Document the attribute schema. Required attributes, opt-in fields, custom dimensions (prompt.version, user.cohort, tenant.id).
- Audit the call graph. Where is auto-instrumentation already creating spans? Do not duplicate.
- Decorate the meaningful units. LLM call, retriever, tool, sub-agent, evaluator. Custom logic between LLM calls if it carries operational weight.
- Wire the contextvar layer. Middleware sets prompt.version, user.cohort at request start; decorators read them.
- Set the cardinality budget. No raw user input as attributes. Bounded enums, hashed identifiers, opt-in content fields.
- Handle streaming explicitly. Manual span lifecycle for async generators; decorator only for non-streaming functions.
- Wire the collector. OTLP to a collector, redaction processor, tail-sampling processor in front of the backend.
- Test the no-op path. Dev with OTLP off should not slow down meaningfully. If it does, the decorator is doing too much.
- Audit quarterly. Span volume per request, attribute drift, duplicate spans. Refactor before the schema fragments.
What is shifting in Python LLM tracing in 2026
These are the directions worth tracking. Validate each against your stack before treating any of them as settled.
- OTel GenAI semantic conventions are still in Development with an opt-in stability transition (
OTEL_SEMCONV_STABILITY_OPT_IN). Cross-vendor decorator interop is improving but not yet stable. - Reasoning-token attributes are named in the OTel GenAI spec (
gen_ai.usage.reasoning.output_tokens). Decorators that do not capture them under-attribute cost on reasoning models. - Async context propagation in OTel Python is mature: contextvars-based attribute propagation works without manual copy in most async patterns.
- Per-framework instrumentation coverage has expanded across OpenInference, traceAI, and OpenLLMetry, so decorator-only stacks are less common than auto-instrumentation plus targeted decorators.
- Tail sampling at the OTel collector is widely deployed (the contrib processor is still beta), reducing the case for client-side sampling logic in decorators.
How FutureAGI implements Python decorator tracing for LLMs
FutureAGI is the production-grade backend for Python decorator-based LLM tracing built around the closed reliability loop that decorator-only stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Decorator-friendly tracing, traceAI (Apache 2.0) ships Python decorators alongside auto-instrumentation for 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel); the same library covers TypeScript, Java (LangChain4j and Spring AI), and a C# core, so decorator-instrumented Python services share trace IDs with non-Python services.
- Span-attached evals, 50+ first-party metrics attach as span attributes on decorator-emitted spans; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise decorator-instrumented code in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, and 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams running decorator-based Python LLM tracing in production end up running three or four backend tools alongside the decorators: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenTelemetry Python tracer API
- OpenTelemetry Python contrib repo
- OpenTelemetry Python asyncio context support
- OpenInference GitHub repo
- OpenInference semantic conventions
- traceAI GitHub repo
- OpenLLMetry GitHub repo
- OTel collector tail sampling processor
- Python contextvars docs
- PEP 567 contextvars
- Future AGI traceAI announcement
- Future AGI tracing platform
Series cross-link
Related: LLM Tracing Best Practices in 2026, What is LLM Tracing?, What is an LLM Span vs Trace?, Best OTel Instrumentation Tools for LLM in 2026
Frequently asked questions
When should I use a decorator versus middleware for LLM tracing?
Will adding @trace to every function blow up my cardinality?
Do decorators work with async Python and streaming responses?
Should I use OpenTelemetry directly or an LLM-specific decorator library?
How do I attach prompt version and user cohort to a decorator-created span?
What attributes should the decorator set automatically?
What goes wrong when teams over-decorate?
Can I use decorators in production without a backend running?

LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.


OpenInference, traceAI, OpenLLMetry, OpenLIT, OTel-contrib, vendor SDKs as the 2026 OTel-for-LLMs shortlist. License, language, gen_ai.* support.


OpenInference is the OpenTelemetry-aligned semantic convention and instrumentation library for LLM applications, maintained by Arize. 2026 fit explained.