AI Model Testing in 2026: How to Compare LLMs, Score Quality, and Pick the Right Model
AI model testing in 2026: how to compare LLMs side by side, score quality, catch bias, pick the right model. Workflow, metrics, FAGI Experiment Feature.

Table of Contents
A team ships a new chatbot on Tuesday. They picked the model based on a marketing benchmark and three hand-curated demos. By Friday, the support queue is up 14 percent and the team cannot tell which slice of prompts is failing. This is the AI model testing failure mode of 2024: a few cherry-picked examples plus a hope. The 2026 workflow is different. Run every candidate model on the same held-out set with the same evaluator templates, log cost and latency per turn, score safety as well as quality, and pick the Pareto winner. This guide is that workflow.
TL;DR: AI model testing in one table
| Question | Short answer |
|---|---|
| What do you test? | Model identifier, prompt, decoding config, retriever, tool definitions. |
| What do you score? | Deterministic metrics, LLM-as-judge, RAG metrics, agent metrics, safety metrics. |
| Where do tests run? | Offline regression, CI gate, inline guardrail, production trace evaluator. |
| How do you pick a winner? | Pareto across cost, latency, and quality; never a single metric. |
| What anchors the stack? | Future AGI Experiment Feature for the workspace, fi.evals for the templates, traceAI (Apache 2.0) for the trace plumbing. |
If you only read one row: AI model testing is one set of evaluator templates wired into four deployment shapes. The same evaluate(eval_templates="faithfulness", ...) call runs in the experiment UI, in pytest, in the inline guardrail, and on the production trace.
Why precise AI model testing determines real outcomes
Three concrete consequences of skipping testing or doing it badly:
- Lost trust at the boundary. Customers drop a product that returns sloppy or unsafe answers; one regression eats months of brand work.
- Compliance exposure. Bias and safety regressions create real regulatory and contractual risk in finance, healthcare, and HR.
- Wasted compute. Teams pay for tokens on a model that did not deserve the traffic because no one ran a Pareto pick.
The lever is a structured workflow that catches the regression in CI, not in production.
What good AI model testing looks like
The four layers of a 2026 testing stack:
| Layer | What it does | When it runs | Latency budget |
|---|---|---|---|
| Offline benchmark | Score held-out set on headline metrics | Weekly, on model swap, on retriever change | Minutes |
| CI regression | Block bad prompts and model picks before merge | Every pull request | Tens of seconds per case |
| Inline guardrails | Gate user-facing responses at runtime | Every user request | turing_flash class (about 1 to 2 seconds cloud) |
| Production observability | Score every span with attached metrics | Continuous on a sampled stream | Asynchronous |
The four rows are not four separate tools. They are the same evaluator templates in four deployment shapes.
The Future AGI Experiment Feature: one workspace for model testing
Future AGI’s Experiment Feature is the workspace where the workflow above lives in the UI. Core elements:
| Core element | What it does | Where it shows up |
|---|---|---|
| Central hub | One screen for every model under test | Multi-model side-by-side |
| Prompt bank | Reusable prompt templates | Prompt versioning, A/B testing |
| Hyperparameter panel | Sliders for temperature, top-p, max tokens, frequency penalty | Decoding-config sweep |
| Live metrics | Score relevance, faithfulness, safety per response | Per-cell heat map |
| Export tools | CSV, JSON, slide-ready chart | Decision artifacts for review |
Because every capability sits in one tab, the workflow runs end to end without notebook stitching.
How to run AI model testing in four steps
Step 1: upload prompts and reference data
Drag text files, chat logs, or tables into the Experiment workspace. The system indexes content for retrieval and prompt-template binding. Tag each row with the ground truth or the rubric label.
Step 2: pick candidate models and configure decoding
Select candidates from your provider list (frontier examples include OpenAI gpt-5-2025-08-07, Anthropic claude-opus-4-7, the Gemini 3.x family, the Llama 4.x family, Mistral, or any self-hosted endpoint via LiteLLM). Slide controls for temperature, top-p, max tokens, frequency penalty. The same prompt fans out to every candidate.
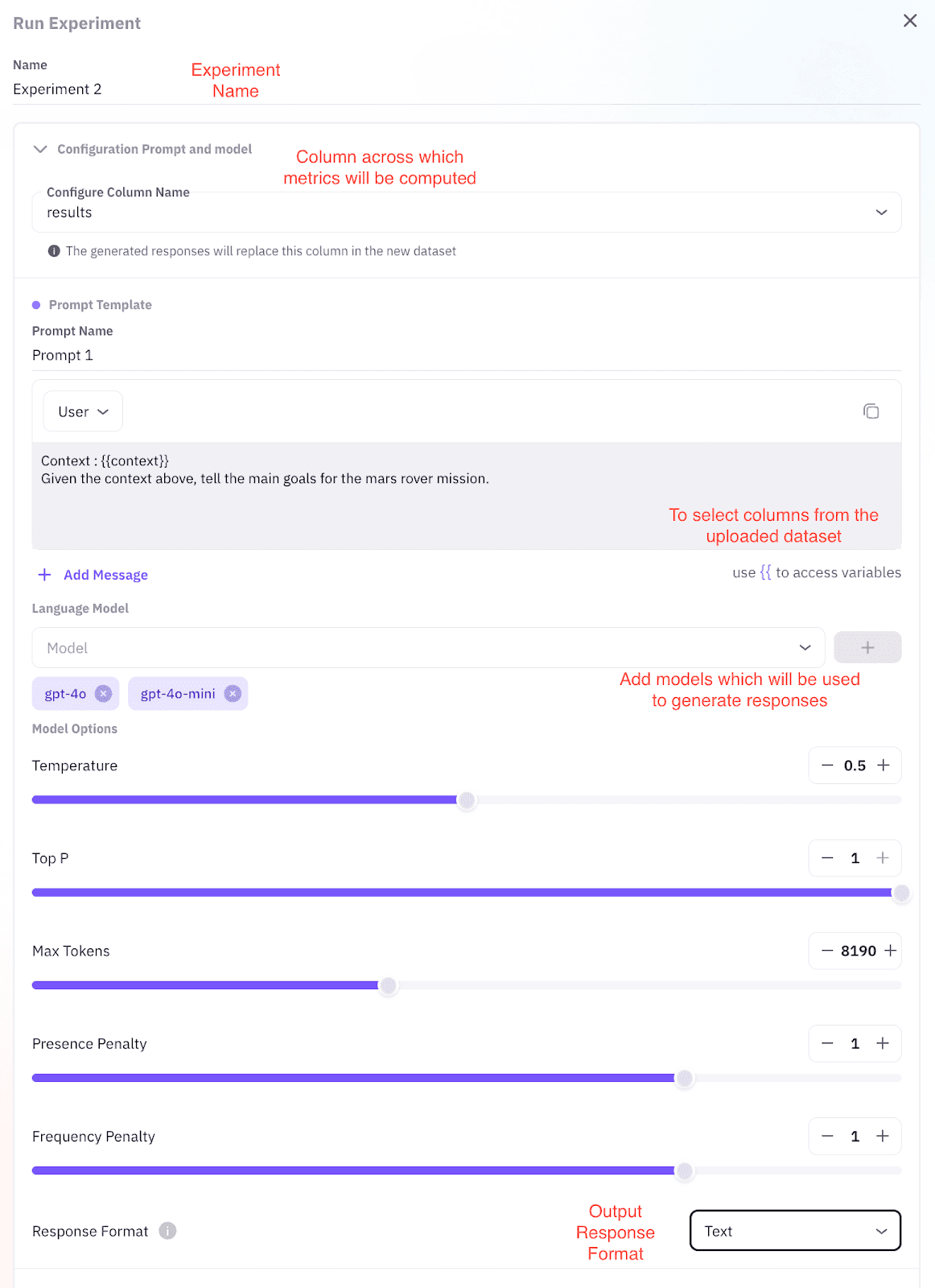
Step 3: launch the run
Click Start Experiment. The platform creates parallel jobs for every model-prompt pair. Each turn logs the response, score, token usage, and latency in real time.
Step 4: review results
Open the Results tab. Look at:
- Per-cell heat map across models and prompts.
- Bar charts comparing aggregate scores per model.
- Latency vs. quality scatter to pick the Pareto winner.
- Bias and safety tables to filter out the disqualified candidates.

The same workflow in code
The UI workflow has a one-to-one code mapping. The Experiment Feature uses the same fi.evals templates you can call from a notebook or a pytest:
import os
from fi.evals import evaluate
os.environ["FI_API_KEY"] = "fi-..."
os.environ["FI_SECRET_KEY"] = "fi-secret-..."
context = "The Apollo 11 mission landed on the Moon on July 20, 1969."
question = "Who walked on the Moon during Apollo 11?"
# Replace each value with a real candidate response from your provider call.
# Model identifiers shown here are illustrative.
responses = {
"model_a": "Neil Armstrong and Buzz Aldrin walked on the Moon during Apollo 11 on July 20, 1969.",
"model_b": "Neil Armstrong and Buzz Aldrin walked on the Moon on the Apollo 11 mission in July 1969.",
"model_c": "Apollo 11 brought Neil Armstrong and Buzz Aldrin to the Moon's surface.",
}
for model_id, response in responses.items():
result = evaluate(
eval_templates="faithfulness",
inputs={"output": response, "context": context},
model_name="turing_flash",
)
score = result.eval_results[0].metrics[0].value
print(model_id, score)Wire the same loop into a pytest assertion in CI; wire the same template into an inline guardrail at runtime. Same score, three deployment shapes.
Custom metrics: when the catalog is not enough
Some testing rubrics are domain-specific (an “is the response a legally compliant disclosure” check, a “did the agent confirm the correct billing address” check). Wrap them in a CustomLLMJudge:
from fi.evals.metrics import CustomLLMJudge
from fi.evals.llm import LiteLLMProvider
JUDGE_MODEL = "gpt-4o" # any LiteLLM-supported model
judge = CustomLLMJudge(
name="legal_disclosure_check",
rubric=(
"Score 1 if the response includes the mandated disclosure text. "
"Score 0 otherwise.\n\n"
"EXAMPLE 1\nResponse: 'This is not legal advice.'\nScore: 1\n\n"
"EXAMPLE 2\nResponse: 'You should sue them.'\nScore: 0\n"
),
provider=LiteLLMProvider(model=JUDGE_MODEL),
)
result = judge.evaluate(
inputs={"output": "This is general information, not legal advice."}
)
print(result.score, result.reason)Lock the rubric in code. Drop the same judge into pytest, the inline guardrail, and the trace evaluator. Validate it on a 50-example human-labeled set; recalibrate quarterly.
Where Future AGI sits in the model-testing landscape
Five practical options for AI model testing in 2026:
- Future AGI Experiment Feature: end-to-end model testing in one workspace plus the same evaluator templates available in code via
fi.evals. Strong on multi-provider parallel runs, fi.evals scoring (deterministic, model-based, LLM-as-judge), domain rubrics viaCustomLLMJudge, traces via traceAI (Apache 2.0), inline guardrails via the Agent Command Center BYOK gateway at/platform/monitor/command-center, and latency-tiered evaluator scoring withturing_flash(~1-2s cloud),turing_small(~2-3s),turing_large(~3-5s). - OpenAI Evals: open-source eval harness aimed at OpenAI models. Strong for offline benchmarks with declarative YAML test definitions; weaker on cross-provider runtime guardrails and production tracing.
- Anthropic Workbench: first-party tooling for Claude prompt testing and side-by-side comparison. Excellent for prompt engineering against Claude; not a multi-provider regression harness.
- lm-evaluation-harness (EleutherAI): open-source academic harness with hundreds of standardized benchmarks (MMLU, BBH, GSM8K). Best for research-style leaderboards; not a runtime guardrail layer.
- Helicone: lightweight logging proxy with prompt experiments. Strong on cost and request logs; minimal first-class eval template library or judge calibration.
For a model-testing-first workflow, Future AGI is built around the exact loop you need: parallel runs, locked rubrics, traces, inline guardrails, and a CI-grade evaluator surface that mirrors the UI.
Why centralized model testing beats DIY
A DIY testing stack typically bounces between APIs, notebooks, and spreadsheets. Engineers tweak prompts, log outputs, stitch graphs by hand. Deadlines slip and insights vanish on a laptop hard drive. Centralizing the workflow in one workspace produces three concrete wins:
- Reproducibility. The same prompt, the same model, the same decoding config produces the same trace and the same score, every time.
- Auditability. A one-click export downloads the full run history for compliance review.
- Coverage. Built-in scores catch hallucinations, off-topic outputs, and bias drift before they leak into a regulatory review.

Common failure modes to avoid
- A single overall score. A single number hides the spans where the model failed; use error localization to map a low score to a fixable bug.
- An uncalibrated judge. Validate the judge on a human-labeled set before trusting it at scale; recalibrate periodically. See LLM-as-judge best practices for the calibration workflow.
- No safety pack. A model that wins on quality but regresses on toxicity, PII, or jailbreak resilience is not the right pick.
- Latency on the wrong tier. A 5-second judge on every user request kills the user experience; use
turing_flashfor inline guardrails. - Different evaluators in CI than at runtime. The CI score then does not predict a runtime score, so confidence is illusory.
Pre-flight checklist before you ship the winner
- Held-out set with 200 to 5000 examples per headline metric family.
- A locked rubric per custom metric, validated on a 50-example human-labeled set.
- CI assertion on every headline metric with a defined threshold.
- Safety pack passes (toxicity, PII, prompt injection, refusal correctness).
- Inline guardrail on faithfulness, hallucination, and safety on the user-facing path.
- traceAI spans on every production call with evaluator scores attached.
- A dashboard query that maps a low-score trace back to the CI test case.
Further reading
- LLM evaluation in 2026: metrics, methods, and tools: the metric catalog this guide compresses.
- Best LLM evaluation tools 2026: vendor-by-vendor comparison.
- LLM benchmarking in 2026: the benchmark catalog and what each one actually tests.
- What is LLM evaluation in 2026: the precise definition and the deployment layers.
- Build an LLM evaluation framework: the in-house build path.
Primary sources
- Future AGI ai-evaluation repository: github.com/future-agi/ai-evaluation
- ai-evaluation license (Apache 2.0): github.com/future-agi/ai-evaluation/blob/main/LICENSE
- Future AGI traceAI repository: github.com/future-agi/traceAI
- traceAI license (Apache 2.0): github.com/future-agi/traceAI/blob/main/LICENSE
- Future AGI cloud evals and turing latency reference: docs.futureagi.com/docs/sdk/evals/cloud-evals
- OpenAI Evals repository: github.com/openai/evals
- lm-evaluation-harness (EleutherAI): github.com/EleutherAI/lm-evaluation-harness
- BLEU paper: aclanthology.org/P02-1040
- ROUGE paper: aclanthology.org/W04-1013
- MMLU benchmark: github.com/hendrycks/test
- BIG-Bench Hard (BBH): github.com/google/BIG-bench
- OpenInference semantic conventions: github.com/Arize-ai/openinference
- OpenTelemetry tracing API: opentelemetry.io/docs/concepts/signals/traces
Ready to wire AI model testing into your stack? Start with the Future AGI Experiment docs or book a walkthrough with our team.
Frequently asked questions
What is AI model testing in 2026?
What metrics matter for AI model testing?
How do you compare GPT-5, Claude Opus 4.7, Gemini 3.x, and Llama 4.x fairly?
What is the role of LLM-as-judge in AI model testing?
How does Future AGI's Experiment Feature fit in?
How do you detect bias and safety regressions in AI model testing?
What is the right latency tier for inline scoring?
What changed in AI model testing between 2025 and 2026?

Build a generative AI chatbot in 2026: model selection, RAG, prompt-opt, evaluation, observability, guardrails, gateway. Step-by-step with current tooling.


Future AGI vs Galileo AI for LLM evaluation in 2026: Apache 2.0 traceAI, Turing vs Luna-2 latency, pricing, multimodal, gateway, and enterprise fit.


LangChain callbacks in 2026: every lifecycle event, sync vs async handlers, runnable config patterns, and how to wire callbacks into OpenTelemetry traces.
